

激光雷达鲜为人知的主要用途:定位
描述
激光雷达除了感知外,另外一个主要的用途就是定位,目前的无人出租车研发基本都是用激光雷达定位,当然严格地说是融合定位。
首先解释下什么是定位,为什么需要高精度定位。
定位就是无人车知道自己在坐标系中的位置和姿态,这个坐标系可以是一个局部的坐标系,比如一个园区,采集这个园区的一些地图,自由定一个原点,这个局部坐标系便已经建好,相对于这个坐标系来得到车辆的位置和姿态。坐标系也可以是一个全局的坐标系,比如全球坐标系,可以知道一个很精确的位置。这就是常说的经纬度绝对定位。位置对应X,Y,Z,即相当于某个坐标系,汽车的平移是多少。
姿态是三个方向的旋转状态,一般会用欧拉角来表示。包括横滚、俯仰和航向,分别相对于X,Y,Z三个坐标轴。如果本地坐标系已经定义好,现在有一个车上的坐标系,它相对于本地坐标系的变化(即姿态的变化),就可用三个角度来表示,也就是本地坐标系的三个轴和相对坐标系的这三个轴之间的夹角。
除了位置和姿态这两个维度,自定位系统还要输出很多信息。除去速度、加速度和角速度外,基于数学概率算法的相对定位的加入,自定位系统还需要对位置和姿态加上一个置信度,而基于卫星广播的绝对定位准确率达到了99%,一般不需要加置信度。
虽然车辆本身的传感器也能输出速度、加速度和角速度,但是定位系统基于位置的变化输出的信息准确度更高,加速度和角速度是相对于车体本身的,告知车辆当时瞬时的加速度和角速度,对人的驾乘体验非常重要。控制模块根据这些信息做一些控制上的优化,使人的体感更好。
高精度地图自然需要高精度定位,全局规划也需要高精度定位。
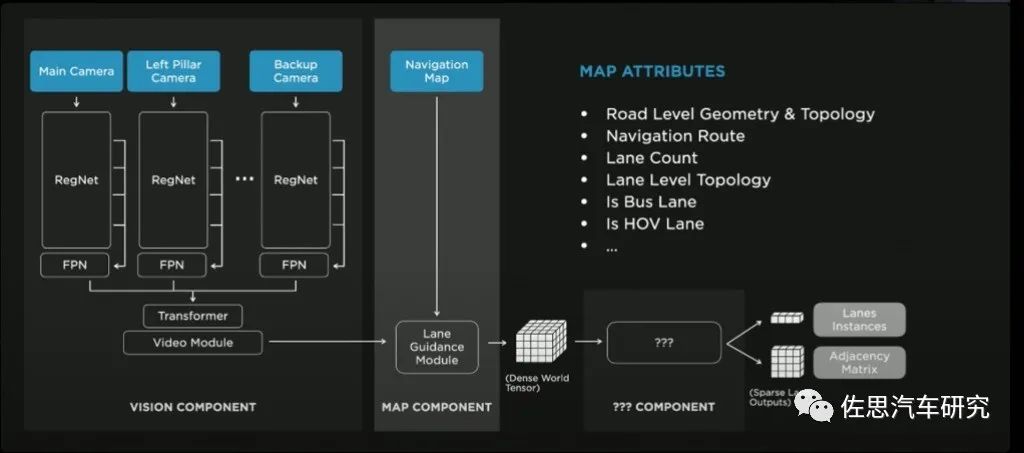
上图是特斯拉2022年AIDAY上的特斯拉未来的FSD Beta版智能驾驶架构图,自然离不开高精度地图,现在的FSD版不需要高精度地图,因为现在的FSD只是L2级辅助驾驶,没有车道级定位,自然也用不上车道级地图。
绝对定位离不开卫星或RTK系统,姿态则主要依靠IMU,相对定位基于环境特征匹配,常见的视觉和激光雷达定位就是如此。姿态很多时候可以叫航迹推算,航迹推算就是根据上一时刻的“位置”和“姿态”,叠加一些测量信息可以知道现在的“位置”和“姿态”。IMU是惯性测量单元,包含了加速度计和陀螺仪,其中加速度计会输出加速度的信息,同时还包含重力加速度;陀螺仪是一个旋转,即是前面所讲到三个轴上的一个旋转。要做到无人车10秒单点水平精度1.41米的IMU,这与军事用途的IMU要求是同一级别,价格近20万人民币。
视觉定位置信度很低,顶多可以做个辅助,核心还是激光雷达,视觉对光线变化非常敏感,而室外状态下,光线每时每刻都在变化,例如这次跑过去的光照度和下次跑过去的光照度不一样,上次检测到的特征就无法检测到,典型SIFT特征或者别的特征就会造成定位的失败。但是有一些特征具有明显Semantic意义,比如车道线或者旁边立的这些柱子,红绿灯的柱子或者红绿灯本身或者一些交通标志之类的,对于定位而言非常有用。
这里说一下SLAM(即时定位与地图构建),无人车的定位任务可以看做轻量级SLAM,SLAM原本用于机器人领域,SLAM成熟算法都是采用激光雷达,极少用视觉。
SLAM分类
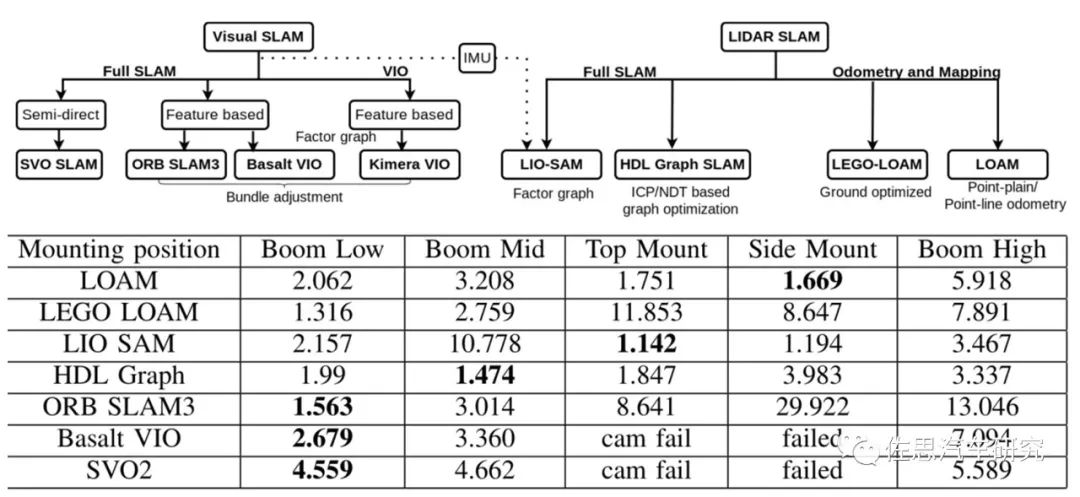
上表出自2022年8月论文《Evaluation and comparison of eight popular Lidar and Visual SLAMalgorithms》,毫无疑问视觉SLAM精度与激光雷达差距巨大,则极容易失败。量产项目没有用视觉SLAM的例子。
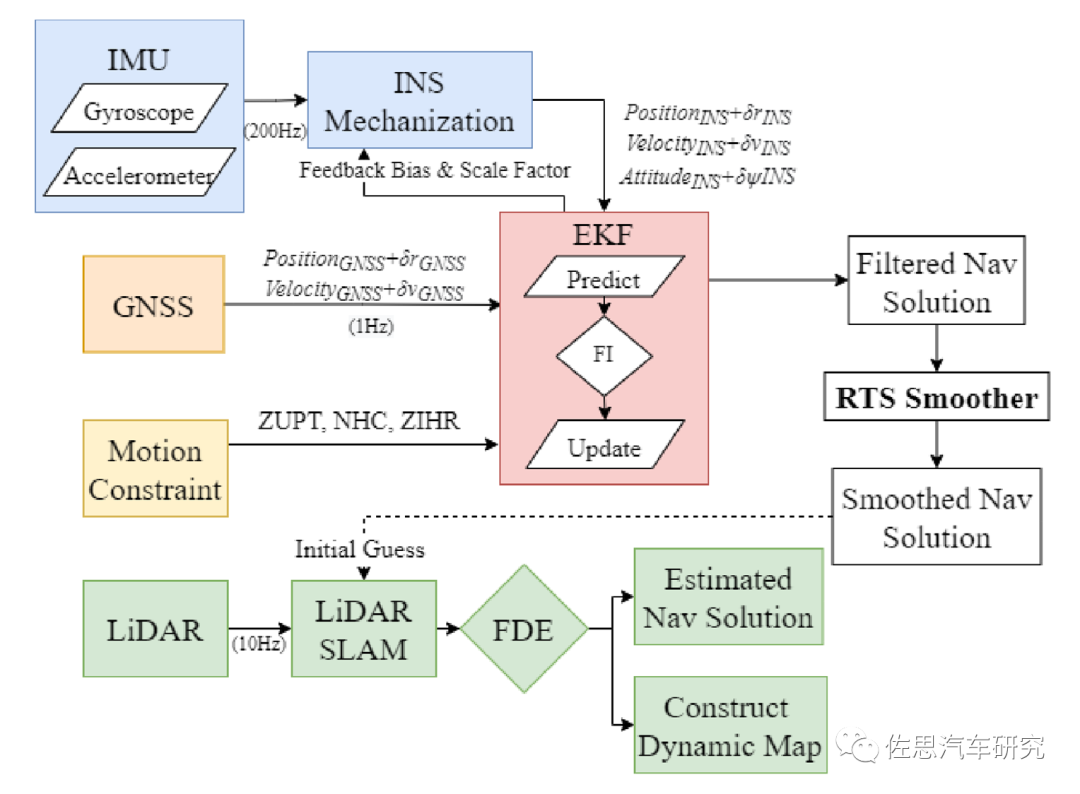
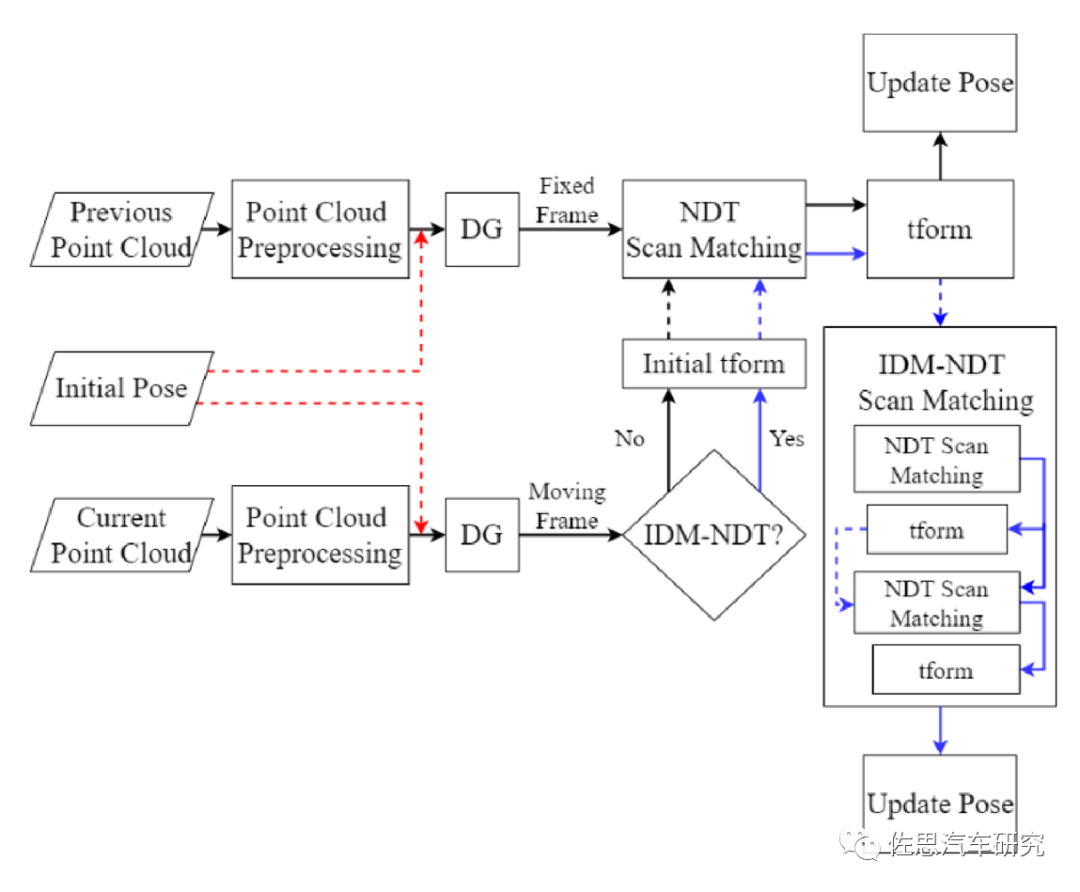
大部分的无人车导航架构就是上图的架构,核心就是NDT,即点云配准的正态分布变换算法,它可以做图也可以定位。无人车导航近似于机器人的SLAM问题,思路通常都是利用激光雷达配准制图并定位,常见的方法有ICP、NDT、Gaussian fields。还有一些不常用的如Point-based probabilistic registration ,Likelihood-fieldmatching,Quadratic patches。还有基于深度学习的比如蒙特卡洛定位算法(MCL)。这些也可以称之为激光雷达点云扫描配准算法。ICP和NDT都比较消耗CPU资源,而不是GPU或AI资源。NDT是目前最常用的无人车定位算法,在无人车主流操作系统AUTOWARE中直接嵌入了完整的NDT算法。
ICP是早期常用的技术方式,优点是对初始精度要求不高,缺点是首先要剔除不合适的点对(点对距离过大、包含边界点的点对),其次是基于点对的配准,并没有包含局部形状的信息,再次是每次迭代都要搜索最近点,计算代价高昂,ICP有不少变体算法如八叉树或IDC。
通过不断比对实时扫描到的点云和已经建好的全局点云地图,我们就可以持续获得当前的位置。ICP(迭代最近点)等配准算法通过对所有的点或者提取的特征点进行匹配配准以确定当前的位置,但是这样就有一个问题:我们所处的环境是在不断变化的,比如树木的稀疏程度,或者环境中车辆及行人的移动,乃至固有的测量误差,这些都会导致实时扫描到的点云与已建立的点云地图有些许的差别,从而导致较大匹配误差。
而NDT可以在很大程序上消除这种不确定性。NDT没有计算两个点云中点与点之间的差距,而是先将参考点云(即激光雷达先验地图)转换为多维变量的正态分布,如果变换参数能使得两幅激光数据匹配的很好,那么变换点在参考系中的概率密度将会很大。因此,可以考虑用优化的方法比如牛顿法,求出使得概率密度之和最大的变换参数,此时两幅激光点云数据将匹配的最好。
可以这样来做一个通俗的理解:NDT把我们所处的三维世界按照一定长度的立方体(比如30cm*30cm*30cm)进行了划分,类似于一个魔方,网格Grid,与VOXEL近似,每个立方体内并不是存储一个或一些确切的点,而且存储这个立方体被占据的概率密度。当接收到需要匹配的点云时,也按照这样的划分方式进行划分,然后进行配准。
因此,NDT具有以下的特征:支持更大的地图,更稠密的点云,相较于ICP等基于点的匹配算法,速度更快且更加容忍环境的细微变化。
NDT流程
NDT,Normal Distributions Transform正态分布变换算法的简称,其是一种统计学模型。如果一组随机向量满足正态分布,那么它的概率密度函数为:
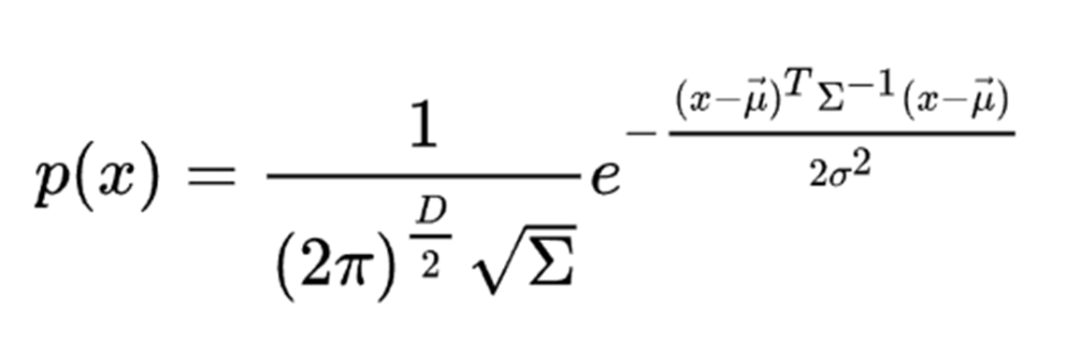
其中D表示维度,表示均值向量,表示随机向量的协方差矩阵。由于扫描得到的激光点云数据点是三维空间点坐标,所以需要采用三维正态分布。NDT能够通过概率的形式描述点云的分部情况,这有利于减少配准所需要的时间。
审核编辑 :李倩
-
激光雷达分类以及应用2017-09-19 8730
-
常见激光雷达种类2017-09-25 13816
-
激光雷达的核心重要指标到底是什么?2018-02-07 14152
-
激光雷达除了可以激光测距外,还可以怎么应用?2018-05-11 5960
-
AGV激光雷达SLAM定位导航技术2018-11-09 9871
-
机器人和激光雷达都不可或缺2019-02-15 6074
-
微波暗室的主要用途2019-05-30 6858
-
激光雷达2021-01-17 20002
-
电容有什么作用?主要用途是什么?2021-03-17 2105
-
由iphone12说说激光雷达 FMCW激光雷达 精选资料分享2021-07-22 9937
-
LabView主要用途有哪些呢2021-09-27 2142
-
石英砂的主要用途2009-11-17 2452
-
鲜为人知的手机特殊功能2009-12-19 1519
-
IC芯片的常见种类及主要用途2022-01-18 20807
-
一款好的激光雷达,要看哪些指标(一)?2023-02-09 2825
全部0条评论

快来发表一下你的评论吧 !
