

说透游戏中常用的两种随机算法
描述
没事儿的时候我喜欢玩玩那些经典的 2D 网页小游戏,我发现很多游戏都要涉及地图的随机生成,比如扫雷游戏中地雷的位置应该是随机分布的:

再比如经典炸弹人游戏,障碍物的位置也是有一定随机性的:
这些 2D 游戏相较现在的大型 3D 游戏虽然看起来有些简陋,但依然用到很多有趣算法技巧,本文就来深入研究一下地图的随机生成算法。
2D 游戏的地图肯定可以抽象成一个二维矩阵,就拿扫雷举例吧,我们可以用下面这个类表示扫雷的棋盘:
class Game {
int m, n;
// 大小为 m * n 的二维棋盘
// 值为 true 的地方代表有雷,false 代表没有雷
boolean[][] board;
}
如果你想在棋盘中随机生成k个地雷,也就是说你需要在board中生成k个不同的(x, y)坐标,且这里面x, y都是随机生成的。
对于这个需求,首先一个优化就是对二维矩阵进行「降维打击」,把二维数组转化成一维数组:
class Game {
int m, n;
// 长度为 m * n 的一维棋盘
// 值为 true 的地方代表有雷,false 代表没有雷
boolean[] board;
// 将二维数组中的坐标 (x, y) 转化为一维数组中的索引
int encode(int x, int y) {
return x * n + y;
}
// 将一维数组中的索引转化为二维数组中的坐标 (x, y)
int[] decode(int index) {
return new int[] {index / n, index % n};
}
}
这样,我们只要在[0, m * n)中选取一个随机数,就相当于在二维数组中随机选取了一个元素。
但问题是,我们现在需要随机选出k个不同的位置放地雷。你可能说,那在[0, m * n)中选出来k个随机数不就行了?
是的,但实际操作起来有些麻烦,因为你很难保证随机数不重复。如果出现重复的随机数,你就得再随机选一次,直到找到k个不同的随机数。
如果k比较小m * n比较大,那出现重复随机数的概率还比较低,但如果k和m * n的大小接近,那么出现重复随机数的概率非常高,算法的效率就会大幅下降。
那么,我们有没有更好的办法能够在线性的时间复杂度解决这个问题?其实是有的,而且有很多种解决方案。
洗牌算法
第一个解决方案,我们可以换个思路,避开「在数组中随机选择k个元素」这个问题,把问题转化成「如何随机打乱一个数组」。
现在想随机初始化k颗地雷的位置,你可以先把这k颗地雷放在board开头,然后把board数组随机打乱,这样地雷不就随机分布到board数组的各个地方了吗?
洗牌算法,或者叫随机乱置算法就是专门解决这个问题的,我们可以看下力扣第 384 题「打乱数组」:

这个shuffle函数是算法的关键,直接看解法代码吧:
class Solution {
private int[] nums;
private Random rand = new Random();
public Solution(int[] nums) {
this.nums = nums;
}
public int[] reset() {
return nums;
}
// 洗牌算法
public int[] shuffle() {
int n = nums.length;
int[] copy = Arrays.copyOf(nums, n);
for (int i = 0 ; i < n; i++) {
// 生成一个 [i, n-1] 区间内的随机数
int r = i + rand.nextInt(n - i);
// 交换 nums[i] 和 nums[r]
swap(copy, i, r);
}
return copy;
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
洗牌算法的时间复杂度是 O(N),而且逻辑很简单,关键在于让你证明为什么这样做是正确的。排序算法的结果是唯一可以很容易检验的,但随机乱置算法不一样,乱可以有很多种,你怎么能证明你的算法是「真的乱」呢?
分析洗牌算法正确性的准则:产生的结果必须有n!种可能。这个很好解释,因为一个长度为n的数组的全排列就有n!种,也就是说打乱结果总共有n!种。算法必须能够反映这个事实,才是正确的。
有了这个原则再看代码应该就容易理解了:
对于nums[0],我们把它随机换到了索引[0, n)上,共有n种可能性;
对于nums[1],我们把它随机换到了索引[1, n)上,共有n - 1种可能性;
对于nums[2],我们把它随机换到了索引[2, n)上,共有n - 2种可能性;
以此类推,该算法可以生成n!种可能的结果,所以这个算法是正确的,能够保证随机性。
水塘抽样算法
学会了洗牌算法,扫雷游戏的地雷随机初始化问题就解决了。不过别忘了,洗牌算法只是一个取巧方案,我们还是得面对「在若干元素中随机选择k个元素」这个终极问题。
要知道洗牌算法能够生效的前提是你使用数组这种数据结构,如果让你在一条链表中随机选择k个元素,肯定不能再用洗牌算法来蒙混过关了。
再比如,假设我们的扫雷游戏中棋盘的长和宽非常大,已经不能在内存中装下一个大小为m * n的board数组了,我们只能维护一个大小为k的数组记录地雷的位置:
class Game {
// 棋盘的行数和列数(非常大)
int m, n;
// 长度为 k 的数组,记录 k 个地雷的一维索引
int[] mines;
// 将二维数组中的坐标 (x, y) 转化为一维数组中的索引
int encode(int x, int y) {
return x * n + y;
}
// 将一维数组中的索引转化为二维数组中的坐标 (x, y)
int[] decode(int index) {
return new int[] {index / n, index % n};
}
}
这样的话,我们必须想办法在[0, m*n)中随机选取k个不同的数字了。
这就是常见的随机抽样场景,常用的解法是水塘抽样算法(Reservoir Sampling)。水塘抽样算法是一种随机概率算法,会者不难,难者不会。
我第一次见到这个算法问题是谷歌的一道算法题:给你一个未知长度的单链表,请你设计一个算法,只能遍历一次,随机地返回链表中的一个节点。
这里说的随机是均匀随机(uniform random),也就是说,如果有n个元素,每个元素被选中的概率都是1/n,不可以有统计意义上的偏差。
一般的想法就是,我先遍历一遍链表,得到链表的总长度n,再生成一个[0,n-1)之间的随机数为索引,然后找到索引对应的节点。但这不符合只能遍历一次链表的要求。
这个问题的难点在于随机选择是「动态」的,比如说你现在你已经遍历了 5 个元素,你已经随机选取了其中的某个元素a作为结果,但是现在再给你一个新元素b,你应该留着a还是将b作为结果呢?以什么逻辑做出的选择,才能保证你的选择方法在概率上是公平的呢?
先说结论,当你遇到第i个元素时,应该有1/i的概率选择该元素,1 - 1/i的概率保持原有的选择。看代码容易理解这个思路:
/* 返回链表中一个随机节点的值 */
int getRandom(ListNode head) {
Random r = new Random();
int i = 0, res = 0;
ListNode p = head;
// while 循环遍历链表
while (p != null) {
i++;
// 生成一个 [0, i) 之间的整数
// 这个整数等于 0 的概率就是 1/i
if (0 == r.nextInt(i)) {
res = p.val;
}
p = p.next;
}
return res;
}
对于概率算法,代码往往都是很浅显的,但是这种问题的关键在于证明,你的算法为什么是对的?为什么每次以1/i的概率更新结果就可以保证结果是平均随机的?
我们来证明一下,假设总共有n个元素,我们要的随机性无非就是每个元素被选择的概率都是1/n对吧,那么对于第i个元素,它被选择的概率就是:
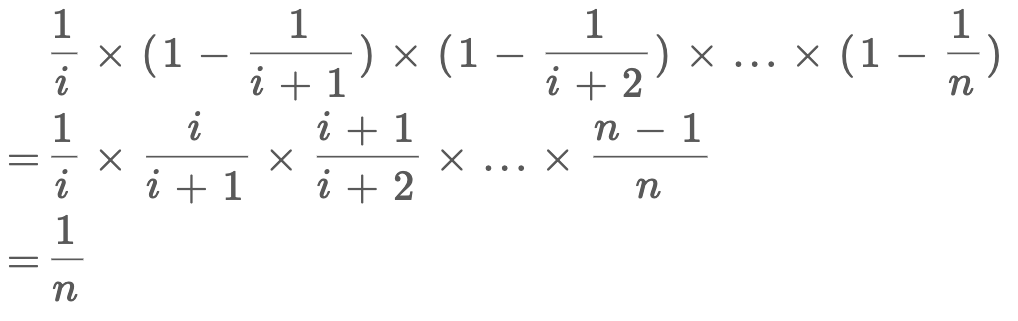
第i个元素被选择的概率是1/i,在第i+1次不被替换的概率是1 - 1/(i+1),在第i+2次不被替换的概率是1 - 1/(i+2),以此类推,相乘的结果是第i个元素最终被选中的概率,也就是1/n。因此,该算法的逻辑是正确的。
同理,如果要在单链表中随机选择k个数,只要在第i个元素处以k/i的概率选择该元素,以1 - k/i的概率保持原有选择即可。代码如下:
/* 返回链表中 k 个随机节点的值 */
int[] getRandom(ListNode head, int k) {
Random r = new Random();
int[] res = new int[k];
ListNode p = head;
// 前 k 个元素先默认选上
for (int i = 0; i < k && p != null; i++) {
res[i] = p.val;
p = p.next;
}
int i = k;
// while 循环遍历链表
while (p != null) {
i++;
// 生成一个 [0, i) 之间的整数
int j = r.nextInt(i);
// 这个整数小于 k 的概率就是 k/i
if (j < k) {
res[j] = p.val;
}
p = p.next;
}
return res;
}
对于数学证明,和上面区别不大:
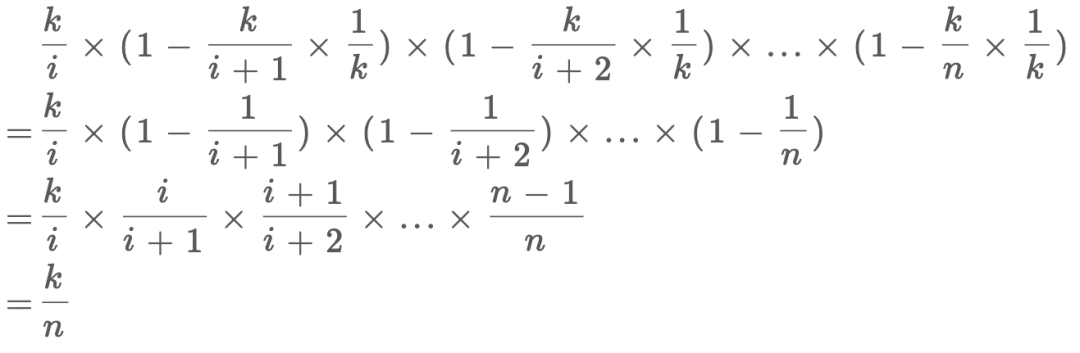
虽然每次更新选择的概率增大了k倍,但是选到具体第i个元素的概率还是要乘1/k,也就回到了上一个推导。
类似的,回到扫雷游戏的随机初始化问题,我们可以写一个这样的sample抽样函数:
// 在区间 [lo, hi) 中随机抽取 k 个数字
int[] sample(int lo, int hi, int k) {
Random r = new Random();
int[] res = new int[k];
// 前 k 个元素先默认选上
for (int i = 0; i < k; i++) {
res[i] = lo + i;
}
int i = k;
// while 循环遍历数字区间
while (i < hi - lo) {
i++;
// 生成一个 [0, i) 之间的整数
int j = r.nextInt(i);
// 这个整数小于 k 的概率就是 k/i
if (j < k) {
res[j] = lo + i - 1;
}
}
return res;
}
这个函数能够在一定的区间内随机选择k个数字,确保抽样结果是均匀随机的且只需要 O(N) 的时间复杂度。
蒙特卡洛验证法
上面讲到的洗牌算法和水塘抽样算法都属于随机概率算法,虽然从数学上推导上可以证明算法的思路是正确的,但如果你笔误写出 bug,就会导致概率上的不均等。更神奇的是,力扣的判题机制能够检测出这种概率错误。
那么最后我就来介绍一种方法检测随机算法的正确性:蒙特卡洛方法。我猜测力扣的判题系统也是利用这个方法来判断随机算法的正确性的。
记得高中有道数学题:往一个正方形里面随机打点,这个正方形里紧贴着一个圆,告诉你打点的总数和落在圆里的点的数量,让你计算圆周率。
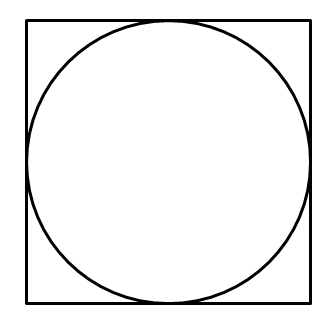
这其实就是利用了蒙特卡罗方法:当打的点足够多的时候,点的数量就可以近似代表图形的面积。结合面积公式,可以很容易通过正方形和圆中点的数量比值推出圆周率的。
当然,打的点越多,算出的圆周率越准确,充分体现了大力出奇迹的道理。
比如,我们可以这样检验水塘抽样算法sample函数的正确性:
public static void main(String[] args) {
// 在 [12, 22) 中随机选 3 个数
int lo = 12, hi = 22, k = 3;
// 记录每个元素被选中的次数
int[] count = new int[hi - lo];
// 重复 10 万次
int N = 1000000;
for (int i = 0; i < N; i++) {
int[] res = sample(lo, hi, k);
for (int elem : res) {
// 对随机选取的元素进行记录
count[elem - lo]++;
}
}
System.out.println(Arrays.toString(count));
}
这段代码的输出如下:
[300821, 299598, 299792, 299198, 299510, 300789, 300022, 300326, 299362, 300582]
当然你可以做更细致的检查,不过粗略看看,各个元素被选中的次数大致是相同的,这个算法实现的应该没啥问题。
对于洗牌算法中的shuffle函数也可以采取类似的验证方法,我们可以跟踪某一个元素x被打乱后的索引位置,如果x落在各个索引的次数基本相同,则说明算法正确,你可以自己尝试实现,我就不贴代码验证了。
拓展延伸
到这里,常见的随机算法就讲完了,简单总结下吧。
洗牌算法主要用于打乱数组,比如我们在 快速排序详解及运用 中就用到了洗牌算法保证快速排序的效率。
水塘抽样算法的运用更加广泛,可以在序列中随机选择若干元素,且能保证每个元素被选中的概率均等。
对于这些随机概率算法,我们可以用蒙特卡洛方法检验其正确性。
最后留几个拓展题目:
1、本文开头讲到了将二维数组坐标(x, y)转化成一维数组索引的技巧,那么你是否有办法把三维坐标(x, y, z)转化成一维数组的索引呢?
2、如何对带有权重的样本进行加权随机抽取?比如给你一个数组w,每个元素w[i]代表权重,请你写一个算法,按照权重随机抽取索引。比如w = [1,99],算法抽到索引 0 的概率是 1%,抽到索引 1 的概率是 99%,答案见 我的这篇文章。
3、实现一个生成器类,构造函数传入一个很长的数组,请你实现randomGet方法,每次调用随机返回数组中的一个元素,多次调用不能重复返回相同索引的元素。要求不能对该数组进行任何形式的修改,且操作的时间复杂度是 O(1),答案见 我的这篇文章
审核编辑 :李倩
-
PCBA加工中常见的两种焊接方式详解2024-06-14 1660
-
基于Python实现随机森林算法2023-09-21 2697
-
简述游戏中常用的两种随机算法(上)2023-04-12 1684
-
详解PMSM中常用的两种坐标变换2023-01-19 4541
-
智能插座常用的两种通信协议是什么?2021-09-26 1599
-
两种典型的ADRC算法介绍2021-09-07 3624
-
常用的hdl语言有哪两种2020-08-25 10070
-
单片机常用的两种延时控制方式2020-07-17 6887
-
Wincc如何与PLC进行通讯两种常用的方式介绍2019-02-17 32034
-
帕塞瓦定理的两种常见形式2018-04-02 10642
-
LCD显示汉字的两种算法分析2018-02-26 7943
-
基于游戏中NPC路径规划的混合算法2017-11-14 1123
-
网络中常用的队列管理方法比较2009-05-25 634
-
支持QoS的两种新型带宽分配算法2009-03-04 1734
全部0条评论

快来发表一下你的评论吧 !
