

 NVIDIA“全堆栈计算”策略应对AI加速计算时代挑战
NVIDIA“全堆栈计算”策略应对AI加速计算时代挑战
描述
在神经网络和机器学习技术的推动下,特别是2016年谷歌的AlphaGo在多次与人类顶尖围棋棋手的对战中大获全胜后,给全世界做了一次人工智能(AI)科普,人工智能的新一波发展浪潮开始了。
“计算技术正在蓬勃发展,推动这枚火箭的引擎是加速计算,而燃料则是 AI。” NVIDIA 创始人兼首席执行官黄仁勋在2022秋季GTC 大会主题演讲中表示。也就是说AI加速计算时代已经悄然来临。
近10年来,数据量和数据处理方式都发生了很大的改变。大量的数据不再是人类事件生成,而是各种类型的传感器和设备所生成,数据量正在呈指数级在往上增长。比如说,智能手表会收集用户运动健身和健康状况相关的详细数据,自动驾驶汽车在行驶过程中会不断收集周围环境的信息,据统计一辆汽车一小时就可以生成5TB的数据,未来随着自动驾驶汽车数量的持续增长,将会产生庞大的数据量。
随着数据量的爆炸式增长,人们开始使用AI来分析数据,因为AI不仅能够分辨出语音和视频模式,强化学习技术,还能够从大量的可能性中识别出最佳结果,从而为使用者提供最有价值的分析。而NVIDIA在AI加速计算领域这几年一路狂奔,取得亮眼成绩。
谈到原因,黄仁勋认为这与NVIDIA这些年来持续推行“全堆栈计算”策略是分不开的。“为了在加速计算领域取得成功,我们不再只是做别人曾经做的事情,而是把它整合成一家纵向一体化的公司。”在他看来,“在AI加速计算领域,如果不垂直整合,就不会成功。因为没有人会专门为你写操作系统,在云端、超级计算和企业中,也没有人会开发你的分布式操作系统,而没有完整的堆栈,用户就无法使用你的平台,所以你别无选择,只能自己动手。”
黄仁勋认为,客户要购买的不是NVIDIA的芯片,而是NVIDIA的计算堆栈。他同时强调,NVIDIA的全堆栈,主要包括四大平台,即NVIDIA RTX、NVIDIA HPC、NVIDIA AI和NVIDIA Omniverse。
NVIDIA RTX:推出全新架构RTX 40系列GPU
NVIDIA RTX是NVIDIA在Siggraph 2018上推出的全新GPU架构,通过两个全新处理器来扩展可编程着色器。RT Core 用于加速实时光线追踪,Tensor Core 用于处理矩阵运算,这是深度学习的核心。
在2022 秋季 GTC 大会上,NVIDIA宣布推出其第3代RTX架构------Ada Lovelace,这代 RTX 以数学家 Ada Lovelace 的名字命名,她被公认为世界上第一位计算机程序员。

图:NVIDIA Racer RTX 是利用 GeForce RTX 40 系列 GPU 和 NVIDIA DLSS 3 创建未来游戏内容的例子
同时,NVIDIA还推出了基于Ada Lovelace架构的RTX 40系列GPU,该系列GPU采用了TSMC的4N工艺,可集成760亿个晶体管和超过16000个CUDA核心。其主要技术创新包括:
- 流式多处理器具有高达83 TFLOPS 的着色器能力,吞吐量超过上一代产品2倍。
- 第三代RT Core的有效光线追踪计算能力达到191 TFLOPS,是上一代产品2.8倍。
- 第四代Tensor Core具有高达1.32 Petaflops 的 FP8 张量处理性能,超过上一代使用 FP8 加速性能的5倍。
- 着色器执行重排序(SER)通过即时重新安排着色器负载来提高执行效率,从而更好地利用 GPU 资源。作为与 CPU 的乱序执行一样的重大创新,SER 为光线追踪带来最高可达3倍的性能提升,整体游戏性能提升可高达25%。
- Ada光流加速器带来2倍的性能提升,使 DLSS 3 能够预测场景中的运动,使神经网络能够在保持图像质量的同时提高帧率。
- 架构上的改进,与 TSMC 4N 定制工艺技术紧密结合,实现了高达2倍的性能功耗比飞跃。
- 双NVIDIA编码器(NVENC)将输出时间至多缩短一半,并支持 AV1。OBS、Blackmagic Design DaVinci Resolve、Discord 以及更多的公司都已在采用 NVENC AV1 编码器。
在产品方面,NVIDIA推出了首款基于Ada Lovelace架构的工作站显卡NVIDIA RTX 6000,该工作站显卡具有142个第三代RT Core、568个第四代Tensor Core、18,176个CUDA核心,以及48GB显存,可为工程师、设计师和科学家提供助力,满足在虚拟世界中构建世界所需的苛刻的内容创建、渲染、人工智能和模拟工作负载的需求。
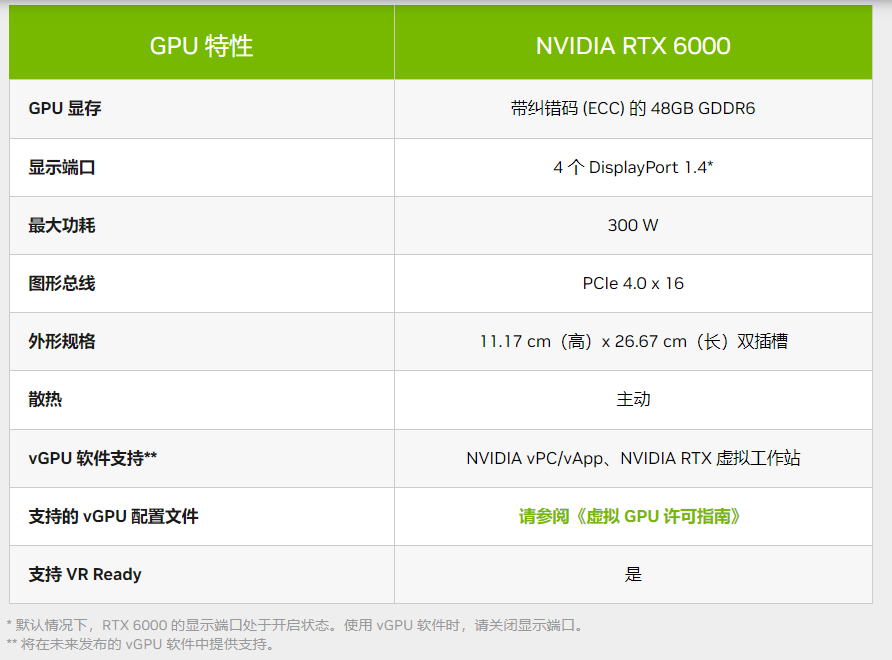
图:NVIDIA RTX 6000具体参数(来源:NVIDIA官网)
据NVIDIA介绍,与其前代产品相比,全新的RTX 6000可在企业环境中提供2~4倍的性能提升,包括最多2倍的光追性能、AI训练性能、及单精度浮点性能等。NVIDIA还为其配备了48GB支持ECC的GDDR6显存,以支持最大体积的3D模型渲染或AI计算。此外,该RTX 6000采用了PCIe 4×16接口,整卡最大功耗为300W。
值得注意的是,全新的RTX 6000的开始出货时间应该是今年12月。
NVIDIA HPC:具有AI支持的全堆栈科学计算
NVIDIA HPC是NVIDIA的科学计算堆栈,在AI的支持下,其GPU、CPU、DPU和软件将共同帮助数据中心扩大规模,为量子计算、分子动力学、流体动力学、气候研究等科学研究做出支持。
NVIDIA HPC包括了HOLOSCAN(边缘计算和人工智能平台可捕获和分析来自医疗设备和科学仪器的数据)、MODULUS、CUQANTUM(量子计算)等数据中心工作负载和技术。
具体来看,针对HPC的HOLOSCAN SDK可以帮助科学家和研究人员加速科学仪器应用的相关发现。该SDK引入了用于创建管道流边缘的高性能框架,允许用户用C++,Python和jax开发应用程序。而且后续还会推出更多的功能。

NVIDIA Modulus是用于开发基于物理学的机器学习神经网络模型的平台。它允许用户以治理偏微分方程或PDES的形式融合物理学的力量。用数据建立高保真的参数化代用模型,具有近乎实时的延时。它可以支持处理AI驱动的物理问题以及复杂的非线性多物理系统设计数字孪生模型等工作。而且,它在提供相同准确性的同时,比单独的模拟快了110万倍。
在量子计算方面,已经有25个国家级的量子计划在运作了,过去12个月有超过2100篇量子计算相关的文章得到了发布。而且,目前已经出现了超过250家量子计算初创企业。NVIDIA也在2022 秋季 GTC 大会上推出了由优化库和工具优化构建的SDK------cuQuantum和混合量子经典应用开发平台QODA。
其中,cuQuantum可用于量子电路模拟开发,借助cuQuantum,一台32个节点的DGX Pod,可以模拟一台40量子位的量子计算机。目前,cuQuantum得到广泛运用,包括AWS、Google、IBM、Oracle以及很多初创公司和超算中心都在采用该SDK,比如Oracle正在为OCI云构建量子模拟虚拟机;AWS将cuQuantum集成到其Braket量子计算服务中,实现了900倍的加速和3.5倍的成本缩减。
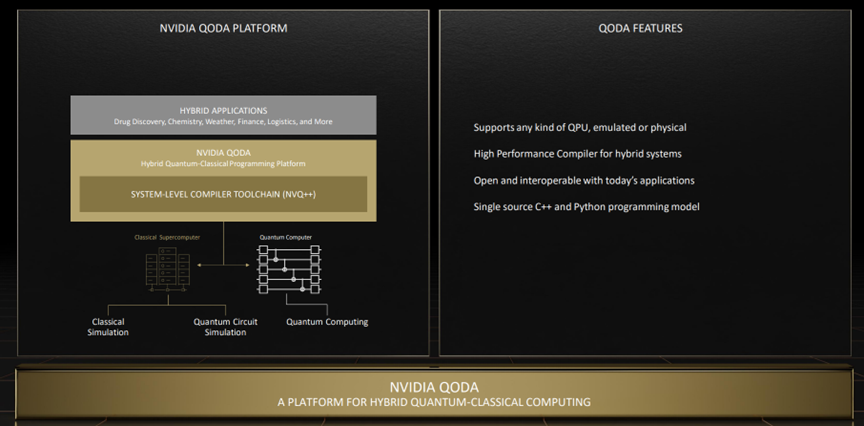
而QODA是一个开放的,与处理器无关的量子平台,适用于混合量子加速计算,它为研究人员提供了量子加速计算的编程模型。
NVIDIA AI:本质上是现代AI的操作系统
在黄仁勋看来,NVIDIA AI本质上是现代AI的操作系统,它从数据采集、数据处理,发展到深度学习,再到如今的的图表分析和图表学习系统,再到推论工具Triton,不断在向前演化。“所以这个端到端平台是NVIDIA人工智能的一部分。如果你在任何地方做机器学习或任何类型的人工智能模型,你都可以使用NVIDIA AI。”他表示。
据他介绍,NVIDIA通过550个SDK和AI模型为约3000个应用提供加速。在过去12个月中对超过100个SDK进行了更新,并推出了25个新SDK,且每次更新都会提高计算机组合的性能和吞吐量。
下面看看几个比较典型的NVIDIA AI应用:
Forecast net:以前所未有的需求和准确性预测极端天气。Forecast net在不到两秒钟的时间内就能生成一个星期的预报,比欧洲中程天气预报中心的综合预报系统(一种最先进的数值天气预报模型)快了几个数量级。而且它的准确度相当或更好。
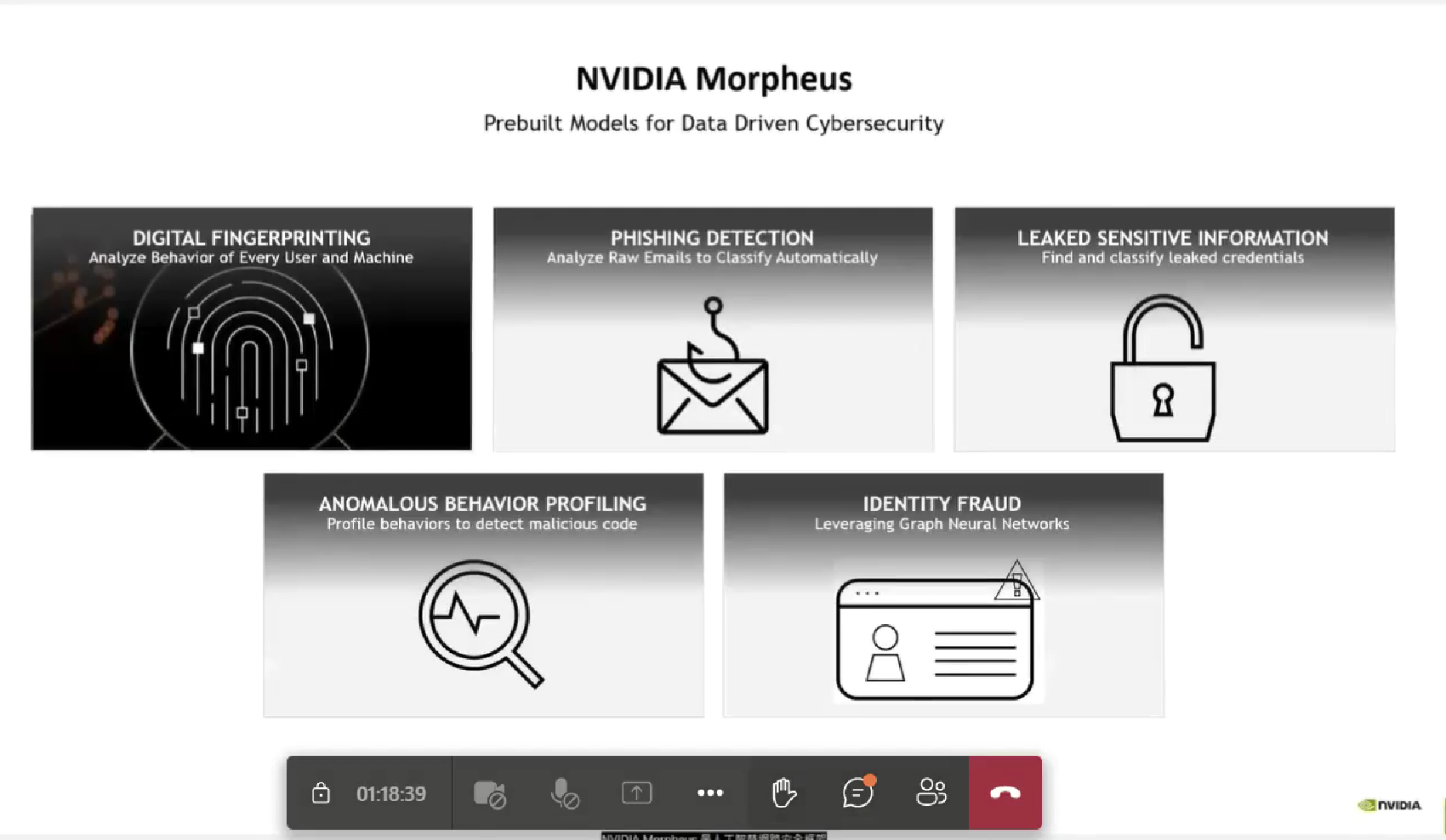
Morpheus:它是AI网络安全框架,旨在使整个安全数据推断更容易、更快、更强大。它由许多模块组成,可以以各种方式连接,允许开发人员创建整个潜能。在输入方面,Morpheus与数据无关。它提供了以下预先训练好的模型,以简化实施并加快它们的模型性能。
1.数字指纹识别——识别凭证使用行为的变化,将其归类为人类与机器的互动和机器与机器的互动;
2.钓鱼网站检测——分析整个原始电子邮件,将其分类为挂垃圾邮件或钓鱼网站;
3.泄露的敏感数据分类——发现泄露的凭证钥匙、密码、信用卡号码、银行账户号码等的分类。
4.异常行为分析检测——以检测像加密恶意软件这样的东西;
5.基于图形神经网络的欺诈检测——帮助你用以前所需的一小部分标记数据获得高准确率的结果。
Triton推理服务器:Triton 是一款开源的推理服务软件,可助力团队从任何框架、本地存储或从任何基于 GPU 或 CPU 的基础架构、云、数据中心或边缘的 Google Cloud 平台或 AWS S3 中部署经过训练的 AI 模型。据悉,Triton的下载量已超过300万次,比去年增加了300%。Triton可以在所有主要公有云中使用,并可集成到领先的MLOps平台中。目前已受到超过35000家公司的青睐。
cuOPT:它是建立在RAPIDS之上的最新库之一。cuOPT是一个AI物流软件应用程序,可以实现近乎实时的路由优化。与最先进的CPU解决方案相比,它的速度提高了100倍以上,在300个humberger基准问题中的190个问题上的准确度创下了世界纪录,并且可以扩展到数万个地点,cuOPT极大地方便了物流和运筹学开发人员。
NVIDIA Omniverse:构建和运行元宇宙应用的平台
Omniverse是一个实时的大型3D数据库,基于USD构建的网络,连接3D世界。同时它也是是一个计算平台,该平台适用于从产品设计和造型,到工程策划、制造、营销和运营的整个产品生命周期。
在2022秋季GTC 大会上,NVIDIA宣布了Omniverse的重大更新:
- 支持 Ada Lovelace GPU,在光线追踪和大型场景性能方面实现巨大飞跃;
- 基于 GAN 和扩散模型的新型神经渲染工具;
- OmniGraph 是一个图形执行引擎,可通过程序化的方式控制行为、动作和行动;
- Omniverse Physics 的重大更新,用来处理复杂的多连接部件对象的运动情况;
- 全新的 Cloud XR,支持在 VR 中实现 Ada 强大的光线追踪功能;
- 首个用于合成数据生成和数字孪生模拟的 SimReady 素材库;
- Replicator 是备受青睐的 Omniverse 应用之一,用来生成合成数据,从而训练自动驾驶汽车、机器人和各种计算机视觉模型。
- 新的 Omniverse JT 连接器 则是一款大型应用,Siemens 发明了 JT,这是产品生命周期管理的行业标准语言,也是 NX、Creo、Catia 和 Inventor 等 CAD 系统的互操作格式,JT 连接器使得工业和制造业可以运用 Omniverse。目前,Omniverse已拥有150个连接器,这些都是全球市值 100 万亿美元的产业所使用的工具和平台。这些连接器将 Omniverse 的应用范围拓展到各种公司,覆盖零售、交通、电信、制造、媒体和娱乐、消费品和奢侈品,以及供应链和物流等大型行业领域。
其实,Omniverse 是一个新的计算平台,需要采用新的计算系统,Omniverse 计算平台由三部分构成:RTX 计算机(供创作者、设计师和工程师使用)、OVX 服务器(用来托管与 Nucleus 数据库的连接并运行虚拟世界模拟),以及第三部分:NVIDIA GDN(进入 Omniverse 的门户)。
通过 GeForce Now,NVIDIA构建了一个全球图形交付网络(即 GDN),该网络覆盖 100 个地区,为之提供响应灵敏的超快 RTX 图形内容交付网络 (CDN)。通过 NVIDIA RTX PC、云端的 NVIDIA GPU 和 NVIDIA GDN,NVIDIA打造了一个覆盖全球的 Omniverse 计算平台。
在今年9月20日,NVIDIA宣布推出第二代NVIDIA OVX,该系统基于Ada Lovelace GPU 架构的 NVIDIA® L40 GPU,能够为构建复杂的工业数字孪生提供强大的算力和性能支持。
L40 GPU 包含第三代 RT Core 和第四代 Tensor Core,能够为在 OVX 系统上运行的 Omniverse 工作负载提供强大功能,包括加速的光线追踪和路径追踪材质渲染、物理级精确的模拟以及逼真的 3D 合成数据生成。L40 也会在主要 OEM 厂商的 NVIDIA 认证系统服务器中提供,以驱动数据中心的 RTX 工作负载。
具体规格方面,每个OVX 服务器节点带有8个NVIDIA L40 GPU和3个ConnectX-7 网卡,可提供100/200/400G网络速率。如果 Omniverse工作负载对性能和规模提出更高要求,这些服务器可以通过 NVIDIA Spectrum™-3以太网平台部署在NVIDIA OVX POD和 SuperPOD配置上。
黄仁勋认为,Omniverse是用来构建和运行元宇宙应用的平台,无论是数字世界和现实世界在何处教会,Omniverse都能发挥作用。此外,Omniverse还有一项重要的用途就是机器人开发,而机器人将会是AI的新一波浪潮。
结语
此外, NVIDIA在2022秋季GTC 大会上还带来了新的边缘AI计算平台IGX平台,IGX平台由NVIDIA IGX Orin超级计算机驱动,能更简便的为制造、物流、医疗等安全敏感行业带来了安全的工作环境;史诗级的超级芯片DRIVE Thor(雷神),这款SoC将于2025年上市,其AI性能高达2000TOPS;以及Jetson Orin Nano,它可运行NVIDIA Isaac机器人堆栈,并具有ROS 2 GPU加速框架,速度比之前大受欢迎的Jetson Nano快80倍等产品更新。
-
NVIDIA Jetson介绍2021-12-14 3174
-
NVIDIA加速计算平台:更强大的GPU加速,更简化的部署流程2019-05-16 4313
-
NVIDIA携手奔驰共同打造革命性的车载计算系统与AI计算基础架构2020-07-20 3131
-
NVIDIA的加速计算平台将用于构建世界上最快的AI超级计算机2020-10-17 3001
-
NVIDIA DRIVE OS 5.2.6 Linux SDK发布 为加速计算和AI而设计2021-09-03 8579
-
NVIDIA DGX系统助力加速量子计算工作2021-11-15 2213
-
NVIDIA 携手微软打造大规模云端 AI 计算机2022-11-17 1359
-
HPC China 2022 | 相聚云端,NVIDIA 加速高性能计算分论坛邀请函2022-12-12 1606
-
NVIDIA 招聘 | NVIDIA 最新热招岗位!一起迎接未来加速计算!2023-06-14 1816
-
SC23 | 新型加速节能 AI 系统开创超级计算的新时代2023-11-15 1572
-
NVIDIA在加速计算和生成式AI领域的创新2024-09-09 1577
-
NVIDIA加速计算如何推动医疗健康2024-11-20 1231
-
利用NVIDIA DPF引领DPU加速云计算的未来2025-01-24 1820
-
NVIDIA助力解决量子计算领域重大挑战2025-03-27 1536
-
NVIDIA加速计算平台助力从地球到太空的AI应用2026-03-18 700
全部0条评论

快来发表一下你的评论吧 !
