

为什么需要可预期高性能网络呢?
描述
近日,阿里云智能在SIGCOMM 2022斩获两篇关于“可预期高性能网络”的研究论文“µFAB”和“Solar”。
可预期高性能网络,是阿里云基础设施研发的下一代数据中心网络架构,是一种可以为上层应用提供稳定的可用性、带宽和低延迟保证的网络。作为可预期高性能网络的技术成果之一,本文将对“µFAB”和“Solar”这两篇发表在SIGCOMM 2022的论文进行深度解读。
为什么需要“可预期高性能网络”?
当前的数据中心发展面临重大挑战,无论从硬件更迭、应用规模,还是架构演进都对网络提出了更高的要求。
首先,随着CPU、GPU、TPU、DPU等新型算力硬件的不断推陈出新,大量的数据需要网络进行交互。存储介质的不断推陈出新,使得磁盘处理的时延从毫秒级降低到了微秒级,数据读取的吞吐也得到了极大的提升,从而使得网络逐渐成为端到端性能的短板。
其次,ML/HPC、存储、数据库等大型新型分布式系统和应用,对于性能越来越敏感,作为端到端性能的重要一环,势必要求网络提供极致的网络传输服务:例如,ESSD存储要求百万IOPS和100微秒的访问时延,这种情况下任何网络的抖动都会造成应用性能的下降。另外,分布式机器学习在单集群部署规模已达到10K-100K加速卡的情况下,需要频繁的数据聚合和再分配,依赖网络带宽的保障和微秒级别的网络时延,系统的瓶颈已经逐渐从计算转移到了网络传输。
此外,数据中心的资源池化(包括硬盘、GPU,甚至内存等)已成为主流。资源池化能够带来应用部署的便利,并且不同资源可以独立进行演进升级,更能节省资源降低使用成本。但资源池化对网络有非常苛刻的要求,各种资源至少需要100G以上的接入网络带宽和10us以内甚至2us以内的时延。随着内存池化的研发,对于网络的依赖会更加迫切。
µFAB:Predictable vFabric on Informative Data Plane
今天,随着云计算的不断发展,高性能存储、分布式机器学习、资源池化等应用和架构的变革,对于网络传输的要求也越来越高,即使微秒级别的网络异常也会使得应用受影响。传统的“尽力而为”的网络服务模型已越来越不适应未来应用的需求。
可预期DCN服务模型
µFAB的目标,是在云数据中心为租户提供带宽保障、低延迟保障,以及最大化利用网络带宽资源。但在目前的网络架构中,要同时实现这三点是非常困难,主要原因是:之前的工作通常把网络当作一个黑盒,利用时延、探测等一系列的启发式算法来做速率控制和路径选择,这样便造成了需要毫秒级别的收敛时间,难以满足应用日渐增加的对于性能的需求。 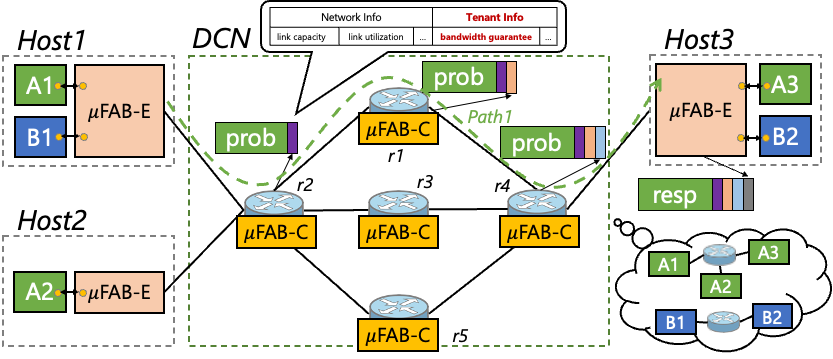
图 | µFAB的服务模型
µFAB的设计理念则恰好相反,其核心思想是网络的透明化和信息化,即利用可编程网络数据平面提供的链路状态和租户信息,并将这些信息反馈到主机侧用于智能的速率控制和路径选择。
上图所示µFAB的服务模型,每个租户会被分配一个虚拟的网络(Virtual Fabric),该虚拟网络为租户提供最小带宽保障、最大化利用资源、低长尾延迟等三个SLA保障。而租户的最小带宽分配遵循云的弹性部署规范,租户总带宽之和不会超过网络物理总带宽。µFAB利用可编程网络提供的精确信息,再通过端网协同的机制达到上述目标。
端网协同的具体工作方式为:一方面,主机侧的µFAB-E模块发送探测包,用以获取网络的信息,从而指导其做“速率控制”和“路径选择”。另一方面,网络交换机上的µFAB-C模块收集链路状态和租户的信息,并将这些信息做聚合,插入到发过来的探测包中,反馈给µFAB-E。
带宽延迟保障算法
有了网络透明化和端网协同,如何才能做到带宽和时延的保障呢? µFAB使用的是按权重分配的做法,这样做的好处是可以很快判断出带宽是否得到了满足。发送窗口的计算方法为: 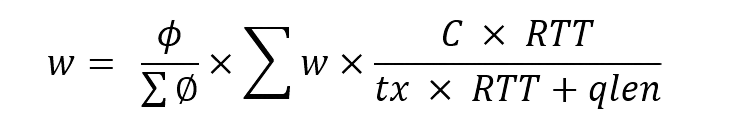
其中,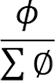 是按租户的权重进行的按权分配,而
是按租户的权重进行的按权分配,而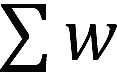 是交换机维护的所有租户的发送窗口之和,
是交换机维护的所有租户的发送窗口之和,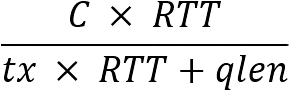 则是根据链路的负载进行的调整,用于最大化链路利用,同时做拥塞避免。
则是根据链路的负载进行的调整,用于最大化链路利用,同时做拥塞避免。 、
、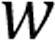 由探测包携带到网络交换机中,
由探测包携带到网络交换机中,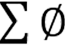 、由交换机维护的租户信息的聚合,而tx、qlen是交换机维护的网络链路信息。
、由交换机维护的租户信息的聚合,而tx、qlen是交换机维护的网络链路信息。
那么,当多个租户同时有流量请求的时候,是不是大家一起发流量就会造成网络拥塞,从而导致长尾时延呢?µFAB在解决这个问题同时保障长尾低时延的做法是:允许租户无论何时都可以按照最小带宽保障发送,只有在网络有剩余带宽的情况下,才会逐渐增大发送速率。这么做的原理是,最小带宽是租户的SLA保障必须满足,而尽可能地提高发送速率则是额外的奖励,时效性要求相对较低。这样既满足了租户对于随时获取最小带宽的承诺,又使得在有多租户突发流量的冲突的时候,依然能够保障网络的长尾时延。
另一个重要的点是,µFAB能够充分利用整个网络的带宽资源,当一个路径上的带宽资源已经被分配完时,能够快速地进行路径切换,从而使用多个路径的网络带宽资源。在路径切换时,需要考虑两种场景:一是当前路径的带宽已经不满足租户SLA,这种情况需要立刻进行路径切换,但也要注意不要过于频繁地连续切换。二是发现有路径的更多带宽资源的时候,这种情况的路径切换是一种最大化利用网络资源的行为,但相对来说没有紧迫的时间需求,因此不用做得过于频繁。
理论分析和硬件实验 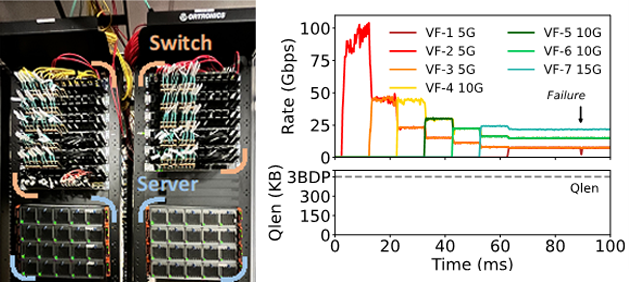
图 | 测试环境和硬件测试结果
µFAB的理论分析表明:µFAB具备快速收敛,带宽和时延保障等特性,即使在路径切换中也能做到快速收敛而不会造成网络震荡。我们分别在FPGA和SOC的硬件网卡和Tofino交换机上做了相应的算法实现,并在三层fat-tree的网络拓扑上做了网络层验证和应用层验证。实验表明,µFAB能提供给租户最小带宽保障和长尾低延迟,同时提供最大化地网络带宽利用,即使面对网络故障的场景下,依然能够快速收敛。 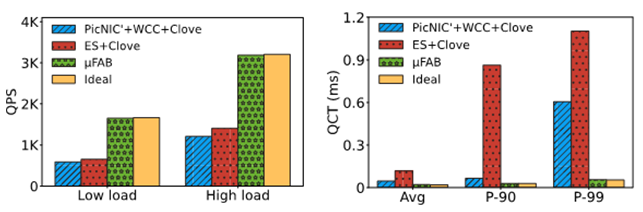
图 | 应用层实测结果 为了验证µFAB对于应用的实际增益,我们将一个租户运行时延敏感型的Memcached,另一个租户运行大带宽的MongoDB应用进行对比实验。实验表明,µFAB能实现接近于理想状态下的QPS(Query Per Second)和QCT(Query Completion Time)。这是因为µFAB总是能正确的选择流量路径,从而实现性能的隔离,以及快速的响应网络拥塞。上图可以看出µFAB能为应用等提供2.5倍的QPS提升、21倍的长尾延迟下降。
From Luna to Solar:The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud
与传统的“尽力而为(best effort)”的网络设计理念不同,可预期高性能网络利用软硬结合、跨层设计和端网协同的理念,可提供微秒级别的带宽、延迟保障。
计算存储分离架构 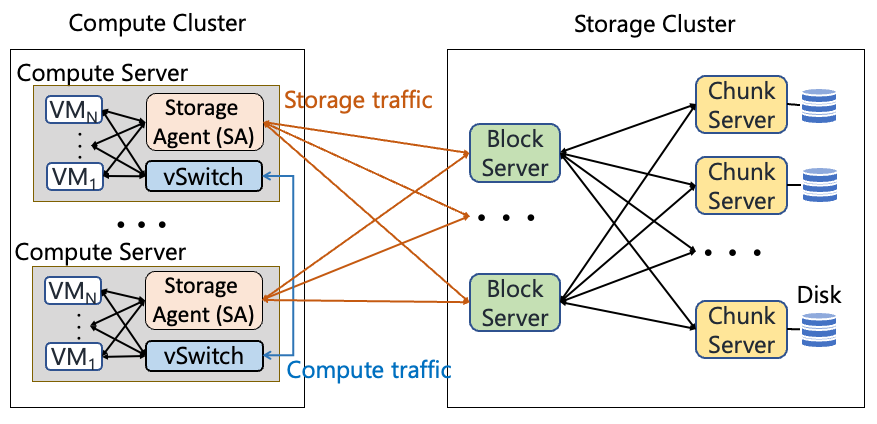
图 | 计算存储分离架构
在计算存储分离架构下,所有的存储I/O都需要网络传递,因此网络成为存储应用的重要瓶颈。而存储流量本身占了整个DCN的60%左右,大量的流量都是很多的小流组成的,例如40%的流量都不超过4KB。因此,存储的流量对于带宽和时延都有极高的要求。
Luna用户态TCP协议
在应对SSD介质带来的低时延同时,传统内核态的tcp协议已然成为端到端性能的瓶颈。与存储内部网络使用RDMA来提高性能不同,计算到存储网络由于它的特殊要求,例如,需要支持十万个连接这个规模,同时需要很高的互通性,而选择了截然不同的协议。
2018年,阿里云在计算到存储部署了用户态tcp协议luna,实现了网络到存储的零拷贝和无锁、零共享等机制,长尾延迟降低了80%。支持了新发布的ESSD产品,实现百万IOPS和100微秒的I/O时延。
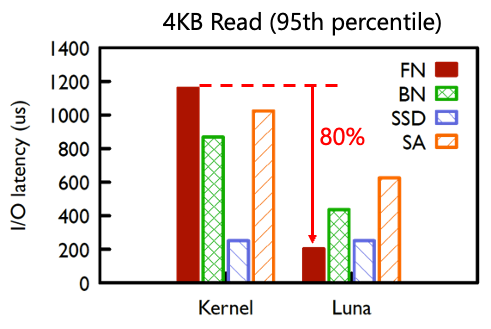
图 | luna的长尾性能收益
裸金属下的存储挑战
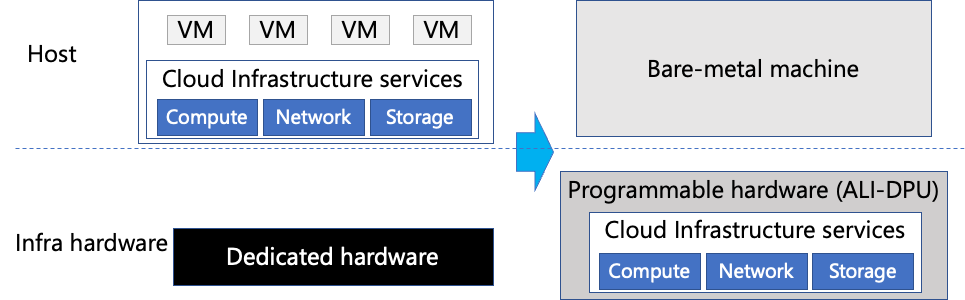
图 | 裸金属云的部署 裸金属云为租户提供整个物理主机,这样租户不仅可以灵活地定制机型和虚拟化平台,快速上云,还能提供安全和性能的保障。例如,租户在使用裸金属服务器时,可以运行自定义的虚拟化平台(如VMware cloud)或完成多云部署,甚至可以调用硬件底层API功能(如Intel RDT)。
但裸金属云在提供给租户更多可能的同时,也面临自身性能和成本的挑战。因为在将整个物理服务器交付给租户的同时,裸金属也不得不将云基础设施软件运行在“非侵入式”的硬件中,通常是网络设备,如智能网卡、DPU、IPU、交换机等等。这样的部署面临着以下两大挑战:
● 资源受限:相对于物理服务器,这些网络设备通常面临更少的资源和更低的功耗限制。在这种条件下,要实现相同甚至更好的云服务性能变得极具挑战;
● 带宽受限:与传统的虚拟化部署中,hypervisor和租户使用内存拷贝交互数据不同,裸金属场景下的虚拟化和数据交互需要经过智能网卡的缓存、处理和转发,在单个方向上数据会两次通过智能网卡内的PCIe拷贝,数据在网卡中的双向拷贝造成带宽减半。
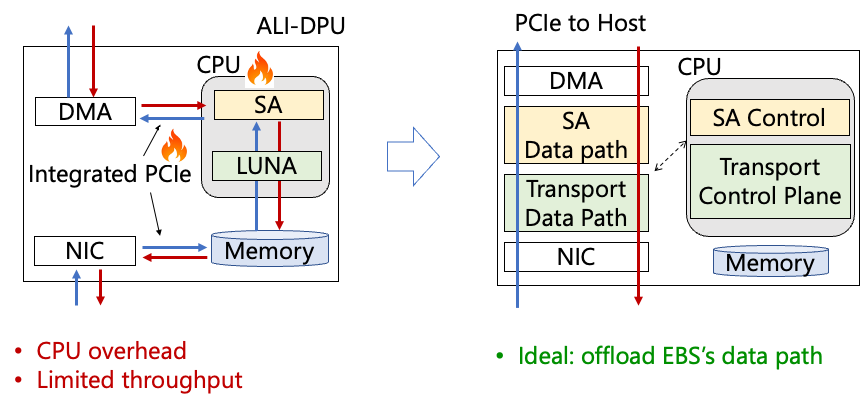
图 | 裸金属下存储前端的挑战 带宽减半原因如上图所示。当租户发送数据→数据通过主机PCIe到达智能网卡→通过智能网卡内部PCIe到达网卡CPU(一次拷贝)→网卡CPU处理→再通过智能网卡内部PCIe发到网口(二次拷贝),再从网口中发出。同理,租户从网络中接收数据也要经历2次拷贝,例如,当网口提供双向100Gb/s吞吐时候,租户实际能获得的带宽只有双向50Gb/s。
理想情况下,我们希望数据平面能够直达主机PCIe,不用经历智能网卡内部PCIe的中转。
存储与网络融合的Solar协议
Solar的设计目标是:能够极大地卸载存储和网络处理到硬件网卡中,从而降低CPU开销,在提供网络性能的同时规避网络故障。但面临的现实问题是存储和网络的协议处理都非常复杂,且存在大量的状态。尤其在资源受限的智能网卡中,能留给存储使用的资源非常有限。做硬件卸载是非常困难的。
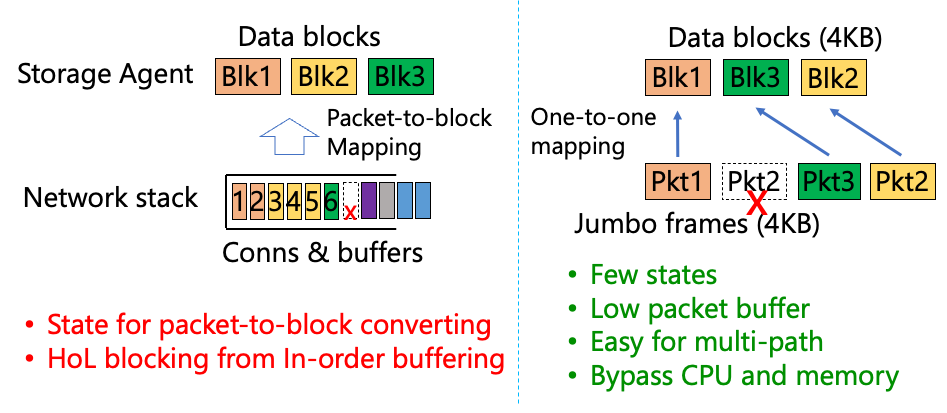
图 | 存储硬件卸载的挑战和解决方案 因此,Solar的设计理念是尽可能地减少协议的复杂度,使得硬件卸载可以非常容易地实现。如上图所示,具体做法是对网络和存储进行跨层融合,利用网络的jumbo frame使得一个网络的数据包就直接等效成一个存储的block。这样协议上就不需要维护数据包到block的映射,也不会有在丢包后出现的队首阻塞问题。更少的状态处理也意味着Solar能够节省CPU开销,以及支持多路径等能力。 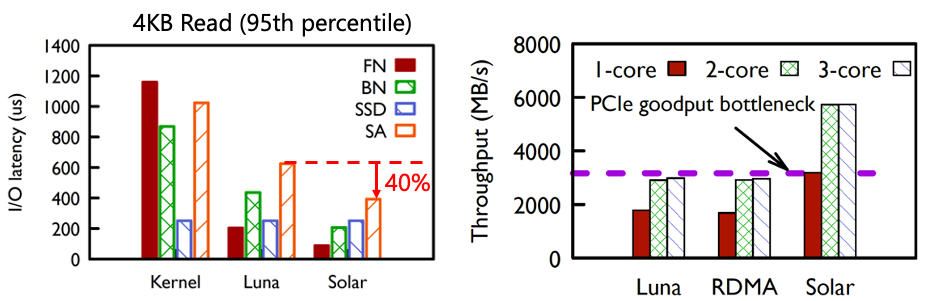
图 | Solar的性能收益 从线上观测看到,在采用Solar之后,计算侧Storage agent(SA)的长尾时延下降了40%,这是因为Solar采用了存储流量的数据平面卸载,这样减少了CPU上的协议处理时延和时延的抖动。同时,由于流量不用经过两次DPU上的PCIe bus,所以网络吞吐能够翻倍。
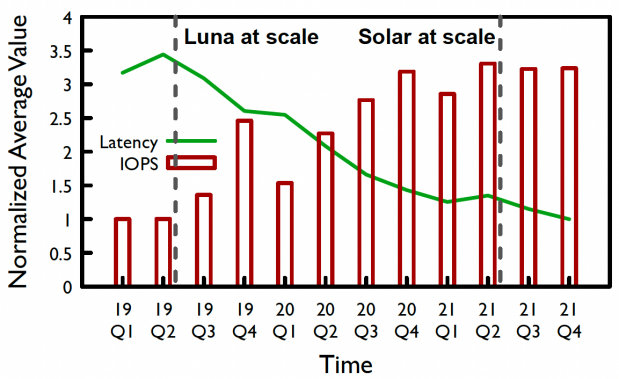
图 | EBS存储的时延和带宽演进 多年的线上实测试数据表明,随着luna和Solar的规模化部署,ebs存储的时延在近几年降低了72%,而IOPS提高了3倍。
结 语
可预期高性能网络,是阿里云基础设施为ML/HPC、高性能存储等新型应用打造的新一代网络架构,其核心目标是“为应用提供微秒级别的时延和带宽保障”。μFAB和Solar分别阐述了实现上述目标的两种重要技术手段:μFAB揭示了端网协同的融合设计,利用可编程网络提供的精细网络信息,在端上智能网卡用于速率控制和路径选择;Solar阐述了应用和网络融合的设计理念,利用数据包和数据块的一一映射,从而极大简化状态处理,提高处理吞吐、降低时延。这些设计的部署,极大地提升了网络传输的服务质量,也给云上客户以及未来算力融合带来了持续价值。
审核编辑:刘清
-
Xilinx FPGA在高性能SDN对的应用2019-06-20 3611
-
如何利用FPGA开发高性能网络安全处理平台?2019-08-12 3905
-
安捷伦N5222A高性能微波网络分析仪2019-12-26 766
-
开发QorIQ T2080的高性能网络控制设备2020-04-29 2856
-
高度集成的SoC用于开发高性能网络控制设备2020-05-15 2765
-
可扩展的高性能RISC-V 内核IP2020-08-13 2823
-
怎么用高性能的FPGA器件设计符合自己需要的DDS电路?2021-04-08 1163
-
如何去实现一种高性能网络接口设计?2021-05-20 1469
-
可满足高性能数字接收机动态性能要求的ADC和射频器件有哪些?2021-05-28 1859
-
AutoKernel高性能算子自动优化工具2021-12-14 1514
-
怎么把电源计划设置为高性能呢2021-12-31 2375
-
高性能CPU时钟网络设计2011-12-27 1240
-
高性能CPU的时钟网络设计2017-10-30 1153
-
同步网络高性能线卡的应用2022-11-01 748
-
面向高性能和可扩展计算系统的IBM b-type网络2023-08-28 452
全部0条评论

快来发表一下你的评论吧 !
