

一文搞懂Linux内核链表
嵌入式技术
描述
hello 大家好,今天给大家介绍一下linux 内核链表的分析,在写这篇文章前,笔者自己以前也只是停留在应用层面,没有深究其中的细节,很多也是理解的不是很透彻。写完此文后,发现对链表的理解更加深刻了。很多现代计算机的思想在内核里面都有体现。
在 Linux 内核中使用最多的数据结构就是链表了,其中就包含了许多高级思想。 比如面向对象、类似C++模板的实现、堆和栈的实现。
1. 链表简介
链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连接成一条数据链,是线性表的一种重要实现方式。
优点:相对于数组,链表具有更好的动态性,建立链表时无需预先知道数据总量,可以随机分配空间,可以高效的在链表中的任意位置实时插入或者删除数据。
缺点:访问的顺序性和组织链的空间损失。
组成:通常链表数据结构至少应包括两个域,数据域和指针域。数据域用于存储数据,指针域用于建立与下一个节点的联系。
分类:按照指针域的组成以及各节点的联系形式分为,单链表、双链表、循环链表等多种组织形式。
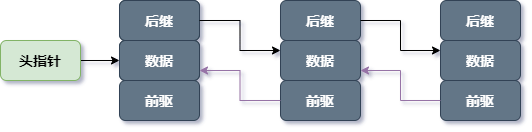
1.1 单链表
如下图,为单链表。它的特点是仅有一个指针域指向后继节点(next)。对单链表的遍历只能从头至尾顺序进行。

1.2 双链表
对比单链表,双链表多了一个指针域。分为前驱(prev)和后继(next)指针。
双链表可以从两个方向遍历,这是它区别于单链表的地方。如果打乱前驱、后继的依赖关系,就可以构成"二叉树";
如果再让首节点的前驱指向链表尾节点、尾节点的后继指向首节点就构成了循环链表;
如果设计更多的指针域,就可以构成各种复杂的树状数据结构。
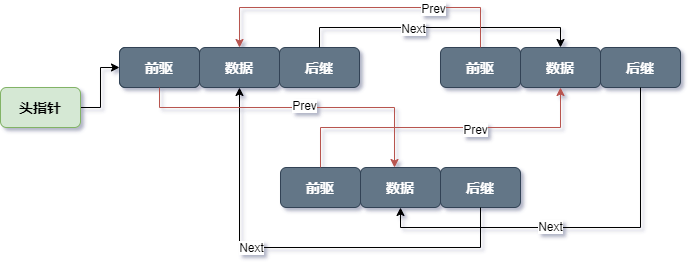
1.3 循环链表
循环链表的特点是尾节点的后继指向首节点。如下图是双循环链表示意图,它的特点是从任意一个节点出发,沿两个方向的任何一个,都能找到链表中的任意一个数据。如果去掉前驱指针,就是单循环链表。
2. 内核链表
在Linux内核中使用了大量的链表结构来组织数据,包括设备列表以及各种功能模块中的数据组织。这些链表大多采用在[include/linux/list.h]实现的一个相当精彩的链表数据结构。事实上,内核链表就是采用双循环链表机制。
内核链表有别于传统链表就在节点本身不包含数据域,只包含指针域。故而可以很灵活的拓展数据结构。
2.1 神奇的结构:list_head
要了解内核链表,就不得不提 list_head。这个结构很有意思,整个结构没有数据域,只有两个指针域。
这个结构本身意义不大,不过在内核链表中,起着整个衔接作用,可以说是内核链表的核心不为过。
struct list_head {
struct list_head *next, *prev;
};
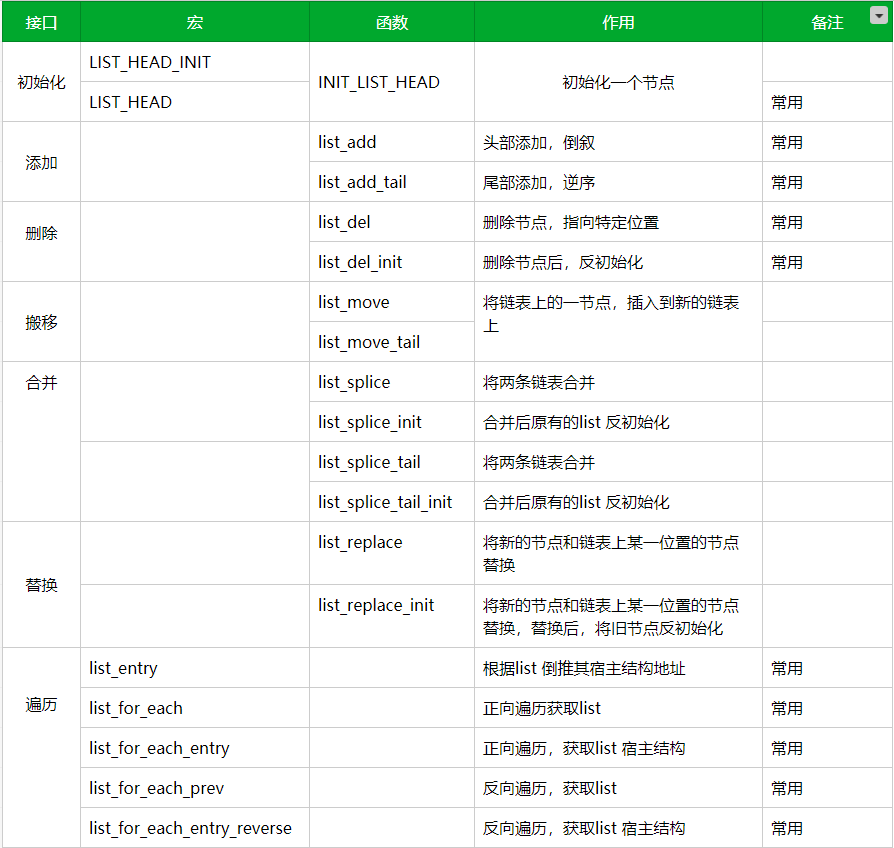
2.2 链表初始化
内核提供多种方式来初始化链表:宏初始化和接口初始化。
宏初始化
LIST_HEAD_HEAD_INIT 宏 设计的很精妙。这个宏本身不包含任何数据类型,也就是说没有限定唯一的数据类型,这就使得整个链表足够灵活。是不是有点C++模板的意思?
对于任意给定的结构指针,将【前驱】和【后继】指针都指向自己,作为链表头指针。
LIST_HEAD 宏 本质就是赋予了 name 于 【struct list_head】 属性,由于 list_head 本身不包含数据域,所以搭配 LIST_HEAD_HEAD_INIT 宏,就使得整个链表上的数据更加灵活。具备通用性。
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name)
struct list_head name = LIST_HEAD_INIT(name)
接口初始化
接口操作就比较直接明了,基本上和宏实现的意图一样。直接将链表头指针的前驱和后继都指向自己
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
我们以示例来补充说明,这样有助于大家辅助理解:
// 1. 链表节点初始化,前驱和后继都指向自己(初始化) struct list = LIST_HEAD(list);
前面说了 list_head 只有指针域,没有数据域,如果只是这样就没有什么意义了。所以我们需要创建一个宿主结构,然后再再此结构包含 list 字段,宿主结构,也有其他字段(进程描述符,页面管理结构等都是采用这种方法创建链表的)。假设定义如下:
struct my_data_list {
int data ;
struct list_head list; /* list head , 这个至关重要,后期遍历通过container_of 解析my_data_list 地址 */
};
创建一个节点:
struct my_data_list first_data =
{
.val = 1,
/* 这里有点绕,事实上就是将first_data.list , 前驱和后继都指向自己进行初始化 */
.list = LIST_HEAD_INIT(first_data.list),
};

这里 list 的 prev 和 next 都指向list 自己了,并且list 属于 my_data_list 的成员。只需要遍历到lst 节点就能根据 前面讲的 container_of 推导得到其宿主结构的地址,从而访问val值,如果有其他方法,也可访问。
分析到这里,应该逐渐明晰,为何list_head 设计很有意思?为什么链表本身不包含数据域,却能衍生出无数数据类型,不受特定的数据类型限制。
2.3 添加节点
内核相应的提供了添加节点的接口:
list_add
list_add 如下,最终调用的是__list_add 函数,根据注释可知,list_add 是头部插入,总是在链表的头部插入一个新的节点。
list_add
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
__list_add
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
我们再以示例补充说明:
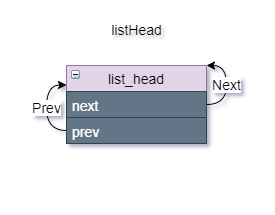
首先创建一个链表头:listHead
LIST_HEAD(listHead);
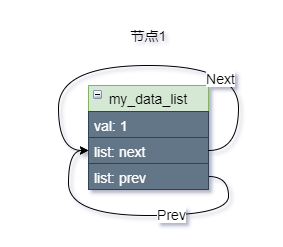
然后再创建第一个链表节点:
struct my_data_list first_data =
{
.val = 1,
.list = LIST_HEAD_INIT(first_data.list),
};
接着 把这个节点插入到 listHead 后
list_add(&frist_data.list, &listHead);
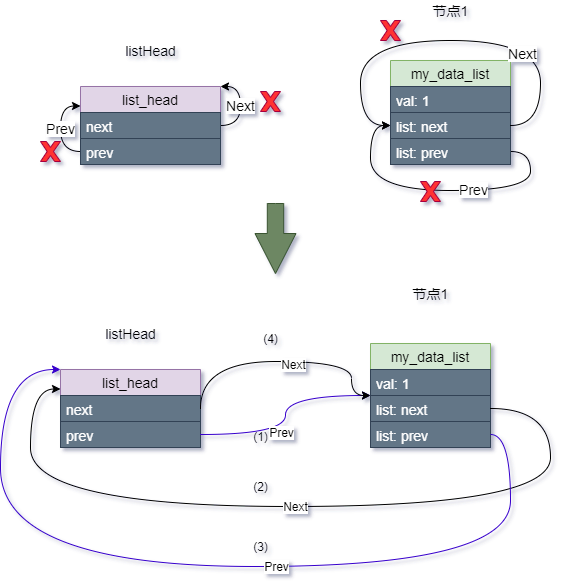
紧接着我们再创建第二个节点:
struct my_data_list second_data =
{
.val = 2,
/* 也可以调用接口 初始化*/
.list = LIST_HEAD_INIT(second_data.list),
};
list_add(&second_data.list, &listHead);
示意图如下:
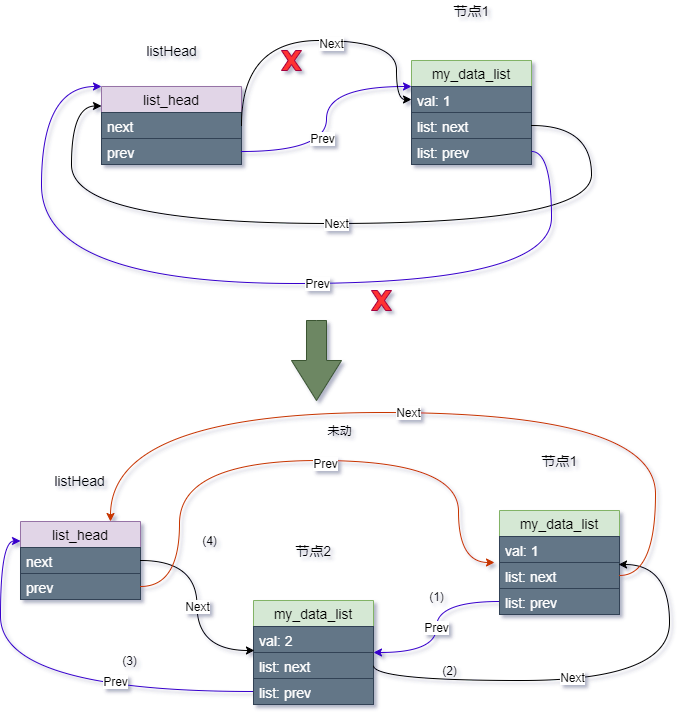
以此类推,每次插入一个新节点,都是紧靠着header节点,而之前插入的节点依次排序靠后,那最后一个节点则是第一次插入header后的那个节点。
可以看出:先来的节点靠后,而后来的节点靠前,符合“先进后出,后进先出”。所以此种结构类似于 stack“栈”, 类似于内核stack中的栈顶指针esp, 它都是紧靠着最后push到栈的元素。
list_add_tail
再看内核另外一种插入方式,本质都是调用__lis_add。不同的是,一个是头部插入,一个是尾部插入。
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
我们还是以示例辅助说明:
首先创建一个链表头:
LIST_HEAD(listHead);
然后创建第一个节点
struct my_data_list first_data =
{
.val = 1,
.list = LIST_HEAD_INIT(first_data.list),
};
插入第一个节点:
list_add_tail(&first_data.list, listHead);
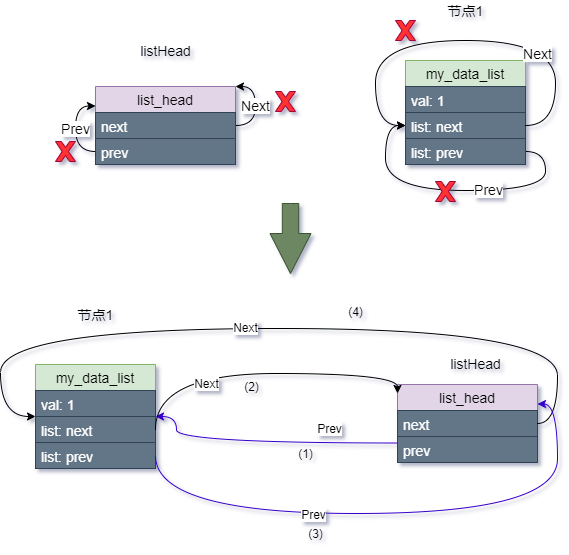
紧接着插入第二个节点:
struct my_data_list second_data =
{
.val = 2,
/* 也可以调用接口 初始化*/
.list = LIST_HEAD_INIT(second_data.list),
};
list_add_tail(&second_data.list, &listHead);
示意图如下:
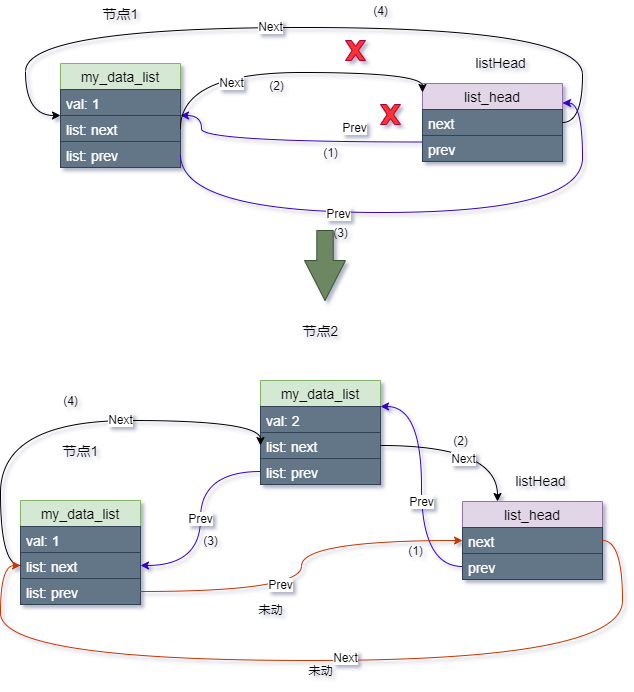
每次插入的新节点都是紧挨着 header 表尾,而插入的第一个节点排在了第一位,第二个排在了第二位。
先插入的节点排在前面,后插入的节点排在后面,“先进先出,后进后出”(First in First out,FIFO)!这不就是队列吗?
总结
由于是双循环链表,看起来尾部插入和头部插入是一样的,其实不然。
我们再来对比尾部和头部插入的区别:
头部插入,结构是逆序,属于先进后出,最主要的区别就是头节点的prev指针指向第一个节点。
尾部插入,结构是顺序,属于FIFO结构,最主要的区别就是头节点的next指针指向第一个节点。
list_add:头部插入一个节点
list_add_tail:尾部插入一个节点
2.4 删除节点
内核同样定义了删除节点的接口 list_del
list_del:
static inline void list_del(struct list_head *entry)
{
/* __list_del_entry(entry) 也行*/
__list_del(entry->prev, entry->next);
/* 指向特定的位置,反初始化 */
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
__list_del:这个接口,根据prev/next 删除其节点,删除的节点必须是已知的并且 prev 和 next 不为空
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
__list_del_entry:删除一个节点。
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
/**
* list_del_init - deletes entry from list and reinitialize it.
* @entry: the element to delete from the list.
*/
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
利用list_del(struct list_head *entry) 接口就可以删除链表中的任意节点了,需注意,前提条件是这个节点是已知的,既在链表中真实存在,切prev,next指针都不为NULL。
被剔除下来的 my_data_list.list,prev、next 指针分别被设为 LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问–对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。
与之相对应,list_del_init()函数将节点从链表中解下来之后,调用LIST_INIT_HEAD()将节点置为空链状态。
list_del() 和 list_del_init 是外部接口。__list_del() 和 __list_entry() 是内核内部节点。
list_del() 作用是删除双链表中的一个节点。并将节点的prev和next都指向特定位置,LIST_POSITION1和LIST_POSITION2。
list_del_init() 作用是删除双链表中的一个节点,并将节点的prev和next都指向自己,回到最开始创建节点前的状态。
2.5 搬移
内核提供了将原本属于一个链表的节点移动到另一个链表的操作,并根据插入到新链表的位置分为两类:头部搬移和尾部搬移。搬移的本质就是删除加插入。
头部搬移
/**
* list_move - delete from one list and add as another's head
* @list: the entry to move
* @head: the head that will precede our entry
*/
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del_entry(list);
list_add(list, head);
}
尾部搬移
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del_entry(list);
list_add_tail(list, head);
}
2.6 合并
内核还提供两组合并操作,将两条链表合并在一起。
当 list1 被挂接到 list2 之后,作为原表头指针的 list1 的next、prev仍然指向原来的节点,为了避免引起混乱,Linux提供了一个list_splice_init()函数.该函数在将list合并到head链表的基础上,调用INIT_LIST_HEAD(list)将list设置为空链。
static inline void list_splice(const struct list_head *list, struct list_head *head); static inline void list_splice_init(struct list_head *list, struct list_head *head); static inline void list_splice_tail(const struct list_head *list, struct list_head *head); static inline void list_splice_tail_init(struct list_head *list, struct list_head *head);
示意图如下:
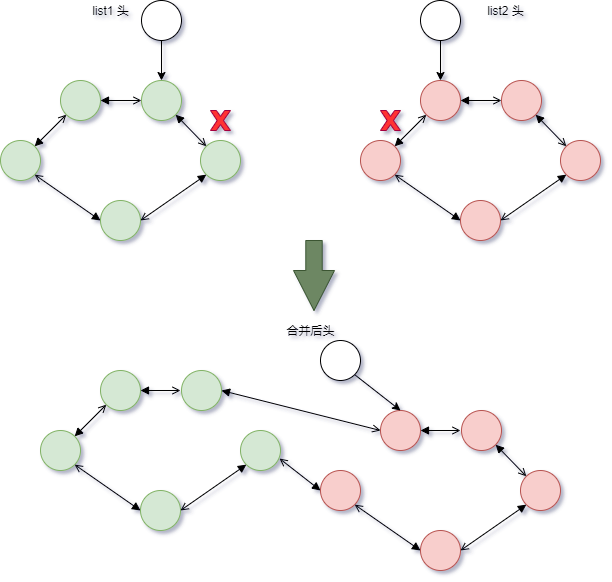
另外一种方式类似,只不过合并时断开的位置有所不同
2.7 替换
内核还提供一组替换链表节点的操作。list_replace:将新的节点替换到旧的节点上。list_replace_init:将新的节点替换到旧的节点上。同时将旧的节点的prev和next指向自己,反初始化
static inline void list_replace(struct list_head *old, struct list_head *new); static inline void list_replace_init(struct list_head *old, struct list_head *new);
2.8 遍历操作
内核提供了一组宏进行遍历操作。经过一系列的增删减改操作,我们终于到了遍历的时候。
list_entry 宏
重头戏来了,遍历的关键就是这个list_entry 宏。本质就是container_of 宏。
具体分析见上一篇文章。这个宏的主要作用就是获取宿主结构的指针地址。
前文提到,我们是以list 指针为节点组成的一条双链表,遍历的过程中只能得到list的地址,那么对于其所有者地址就是通过这个宏获取的。
/** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_struct within the struct. */ #define list_entry(ptr, type, member) container_of(ptr, type, member)
/* 根据list 倒推 my_list_data*/ list_entry(&my_list_data.list, typeof(&my_list_data), list)
list_for_each
list_for_each 它实际上是一个for循环,利用传入的pos作为循环变量,从表头head开始,逐项向后(next方向)移动pos,直至又回到head
/** * list_for_each - iterate over a list * @pos: the &struct list_head to use as a loop cursor. * @head: the head for your list. */ #define list_for_each(pos, head) for (pos = (head)->next; pos != (head); pos = pos->next)
list_for_each_entry
遍历每一个list,然后获取其宿主结构地址.
/** * list_for_each_entry - iterate over list of given type * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_struct within the struct. */ #define list_for_each_entry(pos, head, member) for (pos = list_entry((head)->next, typeof(*pos), member); &pos->member != (head); pos = list_entry(pos->member.next, typeof(*pos), member))
list_for_each_prev
反向遍历得到list.
/** * list_for_each_prev - iterate over a list backwards * @pos: the &struct list_head to use as a loop cursor. * @head: the head for your list. */ #define list_for_each_prev(pos, head) for (pos = (head)->prev; pos != (head); pos = pos->prev)
list_for_each_entry_reverse
反向遍历得到list,然后获取其宿主结构地址。
/** * list_for_each_entry_reverse - iterate backwards over list of given type. * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_struct within the struct. */ #define list_for_each_entry_reverse(pos, head, member) for (pos = list_entry((head)->prev, typeof(*pos), member); &pos->member != (head); pos = list_entry(pos->member.prev, typeof(*pos), member))
3. 总结
本文详细分析了 linux 内核 中的双链表结构,以图文的方式旨在帮助大家理解。
当然还有很多接口限于篇幅没有介绍,本文只列出了常用了接口,相信只要理解了前面双链表的组成和插入过程,后面的删除和遍历就自然而然通了。
审核编辑:汤梓红
-
Linux内核中使用的数据结构2023-11-09 1353
-
Linux内核的链表数据结构2023-03-24 1590
-
【Linux高级编译】list.h的高效应用—双向链表的实现2022-09-15 3742
-
【Linux高级编译】list.h的高效应用—单向链表的实现2022-09-12 3405
-
关于llist.h文件中的链表宏讲解2022-07-01 2098
-
linux内核中llist.h文件中的链表宏讲解2022-05-23 2784
-
一文详解Linux内核源码组织结构2022-05-10 6913
-
驱动之路-内核链表的使用2019-05-15 1642
-
你知道Linux内核数据结构中双向链表的作用?2019-05-14 2206
-
了解Linux通用的双向循环链表2019-05-07 953
-
详细介绍Linux内核链表2019-04-28 861
-
Linux内核的链表操作2017-08-29 3347
-
Linux内核链表详讲(1)2017-07-10 2384
-
深入浅出linux内核源代码之双向链表list_head说明文档2016-07-20 950
全部0条评论

快来发表一下你的评论吧 !
