

Wishbone II交易总线:速度的另一个等级
描述
OpenCore和Silicore的Wishbone规范,旨在提供标准的IP核互连方案,以满足现代片上系统(SoC)设计的要求,包括CPU,DMA引擎,内存接口,外设接口等。
andEuros公司自成立以来一直使用Wishbone规范,并开发了Wishbone总线的改进版本,称为Wishbone II,以提出一种先进的流水线架构,其中读写事务是分开的,总线充当事务总线。通过这种方式,可以同时进行多个事务,通过采用新的每单元锁定概念,消除路径上的所有延迟并停止 RMW 周期。当然,最终的好处是最终总线吞吐量已增加到最大。
大规模FPGA/ASIC SoC设计的设计和开发迫使设计人员实现具有标准化模块接口的模块化架构,该接口以任何可能的配置连接各种IP模块。OpenCores发布了最流行的互连架构之一,称为Wishbone B.3总线。以类似的方式,Altera引入了自己的互连方案,称为Avalon Bus,SOPC Builder和Nios(II)系统就是围绕该方案制造的。Xilinx 还推出了自己的总线,称为片上外设总线与处理器本地总线 相结合。
这些互连架构是面向单事务主/从的,这意味着只要没有收到该字,从给定地址请求单词的 CPU 就会停止自身和到目标的路径(总线)。以这种方式丢失了大量总线周期,尽管系统总线频率相对较高,但实际数据吞吐量仍低于预期。即使特殊信号引入了快速突发读取和写入,总线周期仍然会丢失,直到接收到第一个字,代价是源和目标两端的突发逻辑加倍。当访问具有较大延迟的较慢模块时,总线停滞更为明显。在这些情况下,系统性能会显著下降;例如,100 MHz 系统的吞吐量可能会下降到每秒几 MB。
这就是为什么迫切需要开发采用新概念的总线架构的原因。引入了一些新信号来支持基于 Wishbone B.3 架构的新事务总线概念,克服了延迟问题,同时保持了向后兼容性。
叉骨II交易总线概念
在我们提议的总线中,交易由一个交易向量表示,其中包含:
源(模块)地址
目标(模块)地址
算子
数据
源地址和目标地址定义路径;操作员描述要沿路径和/或目标地址执行的一个或多个操作;某些操作需要提供补充数据才能完成交易。实际实现需要额外的握手信号。
事务向量被放置在事务总线上,将向量从源传输到目标,并根据向量的请求执行面向总线的操作。一旦事务向量被放置(发送),源就没有进一步的责任,事务总线将完全控制它。然后,源已准备好发出下一个事务向量。可以事先发出多个任务或请求,每个总线周期一个,这减少了目标模块上任何预测逻辑的需求,以支持突发读取或写入作为各种突发读取的预测逻辑。
有两种类型的事务:
独立
依赖(当它们的顺序很重要时)
为了支持依赖事务,事务总线绝不能更改已放置事务的顺序。事务总线具有完全确认的机制,用于接受新的事务向量、执行内部转发并传递到目标模块。透明架构将自身反映为一个简单的输入输出黑匣子;但是,该实现基于多管道结构,其中每个 (FIFO) 行包含一个事务向量。
Wishbone II 事务总线仅提供四种基本操作:
单次读取
单次写入
细胞锁
总线锁
单次读取和写入由模块发出,其中单元和总线锁定操作位于事务总线域中。突发读取和突发写入是通过发出读取或写入事务流来完成的。RMW周期通过总线得到支持,甚至更好的是,可以使用新的单元锁定概念来促进它们,该概念不会使整个SoC总线停滞,而是将单个或多个存储单元锁定到给定的所有者。只要未解锁,其他人就无法访问这些单元格。
叉骨II信号
Wishbone II 事务向量由 Wishbone B.3 规范组成,引入了以下新信号:
WB_ACW写入确认
WB_ACR阅读致谢
WB_TGA双向地址标签
WB_ALK地址锁
在进一步的文本中,前缀WB可以更改为WBM表示主接口,WBS表示从接口,也可以留空以描述任何主接口或从接口。输入信号附加在末尾_I,输出信号带有_O。建议的总线丢弃了Wishbone B.3 ACK信号,因为它的功能现在在ACR和ACW信号之间分配。表1列出了主机和从站的完整基本信号说明。新信号以粗体标记。
叉骨二期巴士交易
写入事务
写入事务几乎与 Wishbone B.3 规范中给出的写入事务相同,除了 Wishbone II 使用 ACW 信号来确认写入周期。读写事务由与写入事务相同的读取请求组成,只是设置了目标操作信号 WE。
读取事务
读取事务由两个事务组成:
源发出的读取请求事务
目标发出的读取响应事务
读取请求由表示源的主模块发送,方法是首先发出一个写入事务,并将目标操作 WE 设置为读取。主机应设置地址标记写入向量以识别读取响应。(如果只有一个主控形状,则不需要这样做。读取请求事务的确认方式与写入事务相同。
目标通过返回由确认信号 ACR 标记的单独读取响应事务并提供有效数据和地址标记读取信息来完成事务。地址标记读取是地址标记写入的副本。
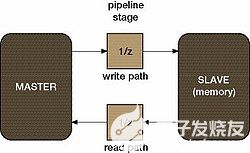
图1显示了一个示例系统,在源(主)和目标(从)设备之间的写入(输入)和读取(输出)路径上有一个流水线级。该系统在两个方向上都有 1 个循环方向;因此,请求-响应循环至少需要 2 个等待周期。从属(内存)还可以执行一些内部管理,如刷新,这增加了等待状态的总数。
图1
您可以看到,图 2 描述了给定示例的事务总线数据流图,其中主站放置的三个读取请求事务为 AD0、AD1 和 AD2,以及关联的返回读取响应事务为 DO0、DO1 和 DO2。假设所有三个事务的信号 WE 都被清除,以指示读取操作。事务 AD0 和 AD1 是突发事务,这意味着 AD1 = AD0 + 1,而 AD2 是同时触发的独立事务,可能是加载其中断向量的外部中断的原因,依此类推。
图2
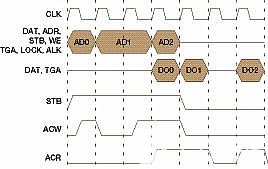
每个读取请求事务由 ACW 信号确认,返回的读取响应事务由 ACR 信号标记(确认)。请注意,由于其他更高优先级的主节点或内存刷新函数等原因,延迟顺序可能不同。在前面的示例中,AD0 会立即得到确认,但需要 3 个等待周期才能返回 DO0;AD1 在 1 个周期后得到确认,而 DO1 仅在 2 个等待周期内返回,DO2 再次需要 3 个等待周期。所有三笔交易都在 9 个周期内完成;理论上,如果不添加两个说明性等待周期,它们只会在 7 个周期内完成。使用 Wishbone B.3 规范时,图 3 显示了相同的场景。
图3
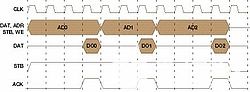
AD0和AD1再次为突发,AD1 = AD0 + 1,AD2为独立请求。所有三个事务都在 12 个周期内完成,性能降低了 41%(在 Wishbone II 中至少 7 个周期),即使额外的硅成本,这是源和目标两端的内存突发逻辑实现。
想象一下,当系统中共存多个主站以发出第一个单词时,连续突发 Wishbone II 将在从属端执行 0 个等待周期(完全消除延迟)并且绝对没有损失(再次是 0 个等待周期)。对于以 150 MHz 运行的系统来说,更能说明问题,固定延迟为 2 个周期的长突发将产生 150 M 字的 Wishbone II 带宽,而 Wishbone B.3 仅产生 50 Mwords 的带宽。
读写周期和专用总线/地址锁定
可以使用总线 LOCK 信号进行读-修改-写循环,方法是发出读取请求和 LOCK 信号集,等待读取响应,然后进行写入,最后释放 LOCK。为了不使整个总线失速,Wishbone II 引入了使用 ALK 信号的每单元内存锁定功能,该功能的使用方式与 Wishbone LOCK 信号几乎相同,只是它不会停止整个总线,而是授予对由源 TGA 区分的给定模块的独占权限。
叉骨II驶向未来
Wishbone II 总线为 FPGA 和 ASIC 的 SoC 设计提出了一种面向事务总线的高级架构,其中架构写入和读取操作作为单独的写入和读取事务处理。每个事务都存储在一行中,多管道架构充当 FIFO 缓冲区,从多个源模块和目标模块传输多个事务。先进的锁定机制使用临时的每单元锁定机制,防止整个总线因 RMW 周期而失速。通过这种方式,整体设计数据吞吐量提高到最大,同时设计成功集成了慢速和高速、低延迟和高延迟外设和 CPU。
审核编辑:郭婷
-
当一个电源的正接到另一个电源的负会怎样?为什么?2024-01-16 8496
-
将数据从一个云迁移到另一个云的有效工具2023-01-30 2250
-
打开虚拟机电源提示“正在处理另一个任务”解决方法2022-01-11 1581
-
可靠性:选择 DC/DC 稳压器时的另一个参数2021-03-18 743
-
如何将数据从一个总线传输到另一个总线?2019-11-06 1564
-
稳定币EURS又达到了另一个里程碑2019-04-04 1050
-
一个简单的Wishbone从设备的RTL代码2018-07-31 5237
-
Wishbone一般总线规范的共同特点2018-07-06 3626
-
基于AMBA与WISHBONE的SoC总线桥KBar控制器的设计2017-03-19 1005
-
怎样将一个CAD图插到另一个CAD图中?2012-10-24 25595
-
基于FPGA的SDX总线与Wishbone总线接口设计2012-01-11 955
-
基于WISHBONE总线的通用接口控制器2011-09-21 983
-
基于WISHBONE总线的FLASH闪存接口设计2011-06-23 954
-
基于Wishbone片上总线的IP核的互联2010-01-13 679
全部0条评论

快来发表一下你的评论吧 !
