

Xilinx,Intel和Lattice的三者FPGA对比
可编程逻辑
描述
在过去的一个月中,FPGA市场蓬勃发展。在本文中,我们将简要研究Xilinx,Intel和Lattice的三款最新发布的FPGA。
这些FPGA中的每一个都专注于提高性能的不同方面:Xilinx VU57P试图绕过要求苛刻的应用程序中的存储器带宽挑战。英特尔Stratix 10 NX FPGA集成了AI优化的DSP模块,可帮助以低延迟实现大型AI模型。而且,莱迪思Nexus FPGA试图重新定义低功耗,小尺寸的FPGA。
Xilinx VU57P FPGA —高带宽存储器
在过去的十年中,许多应用领域的计算带宽呈指数增长。例如,赛灵思FPGA为机器学习应用提供的DSP切片的数量已从最大的Virtex 6 FPGA的约2,000个切片增加到现代Virtex UltraScale +器件的约12,000个切片。如下所示,在其他应用领域(如网络技术和视频应用)中也观察到了类似的趋势。
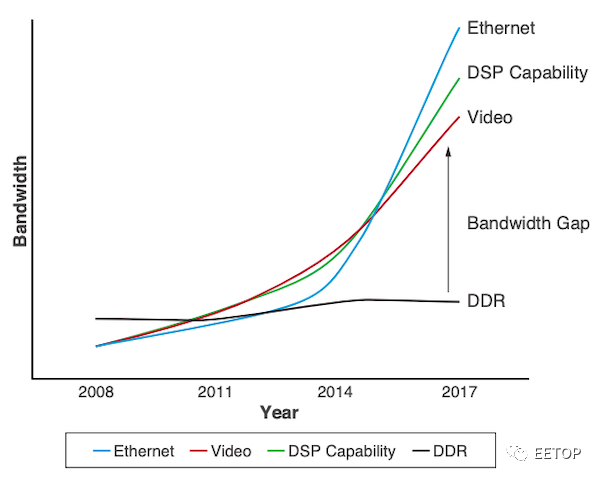
对内存带宽的要求
上图显示,在过去十年中,DDR技术的内存带宽仅略有增加-从DDR3到DDR4大约增加了2倍。(值得注意的是,从DDR4到DDR5的飞跃可能更具影响力。)
图中的带宽差距意味着FPGA和存储器之间有限的数据传输速率是这些应用中的瓶颈。为了解决这个问题,设计人员通常会并行使用多个DDR芯片来增加内存带宽(不一定是内存容量)。但是,由于功耗高,外形尺寸和成本问题以及PCB设计挑战,这种方法在内存带宽大于约85GB/s时变得无法使用。
另外,内存带宽问题的有效解决方案是一种基于DRAM的内存类型,称为高带宽内存(简称HBM)。在这种情况下,可以利用硅堆叠技术在同一封装中同时实现DRAM存储器和FPGA,如下图所示。
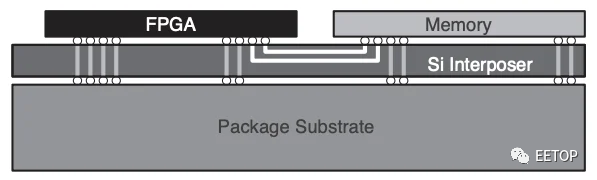
硅堆叠有助于并行实现DRAM存储器和FPGA
HBM技术使我们能够消除将DDR芯片连接到FPGA的相对较长的PCB走线。使用带有大量引脚的集成HBM接口可以显着提高存储带宽,其延迟类似于基于DDR的技术。
Xilinx 最近发布了VU57P FPGA(来自Virtex UltraScale +系列),该FPGA集成了16 G HBM和高达460GB/s的存储器带宽。该设备采用了集成的AXI端口交换机,使我们能够从任何内存端口访问任何HBM内存位置。
除了上面讨论的节能计算功能和大内存带宽外,VU57P还提供了高速接口,例如带有RS-FEC的100G以太网,150G Interlaken和PCIe Gen4。新设备的58G PAM4收发器支持与最新光学标准的连接。这在不同的应用程序中很有用,例如下一代防火墙以及具有QoS的交换机和路由器。
英特尔Stratix 10 NX FPGA — AI优化的DSP模块
数字信号处理(DSP)的许多常规应用都需要高精度算术。这就是FPGA通常具有带高精度乘法器和加法器的DSP模块的原因。例如,XC7A50T(Xilinx)和5CGXC4(Intel)分别具有120和140个18×18的乘法器。
事实证明,可以使用较少的位数来实现许多深度学习应用,而不会显著牺牲准确性。较低精度的近似值会减少计算资源的数量以及所需的内存带宽。
降低位宽的另一个优点是,由于精度较低的计算和每个内存事务需要传输的位数较少,因此可以节省功耗。实际上,根据UC Davis研究人员的说法,在许多深度学习应用中,INT8甚至更低的精度计算都可以得出可接受的结果。
在英特尔的Stratix 10 NX的FPGA是从英特尔首款AI优化的FPGA。这些器件集成了称为AI Tensor Blocks的算术块,其中包含密集的低精度乘法器阵列。这些块的基本精度是INT8和INT4,尽管它们通过共享指数支持硬件支持FP16和FP12数值格式。
与标准Intel Stratix 10 FPGA的DSP模块相比,AI Tensor模块(在Stratix 10 NX FPGA中使用)可以将INT8吞吐量提高15倍。AI Tensor Block的高层框图如下所示。
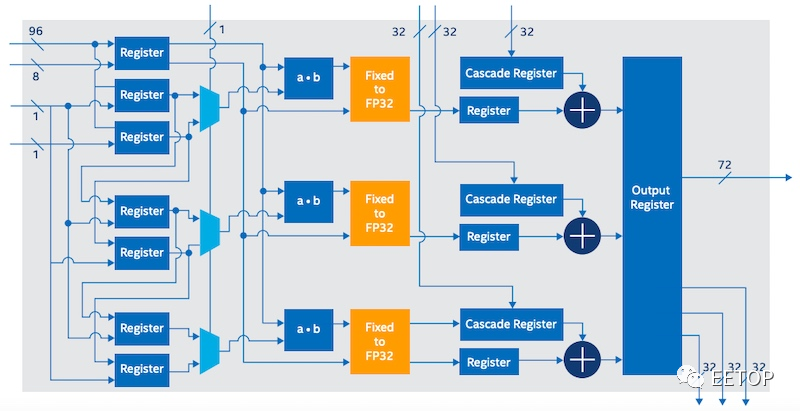
AI Tensor Block的框图
英特尔Stratix 10 NX FPGA最显著的特点是由AI优化的计算块提供的高计算密度。然而,新器件还集成了另外两个功能,进一步帮助设计人员以低延迟的方式实现它的大型AI模型:它支持丰富的近似计算内存(集成HBM)和高带宽网络(高达57.8 G的PAM4收发器)。
Lattice Nexus — 低功耗,小尺寸FPGA
莱迪思半导体最近发布了其 Certus-NX FPGA系列,该系列使用28nm的全耗尽型绝缘体上硅(FD-SOI)工艺技术。FD-SOI最初由三星公司开发,与传统的CMOS工艺有点相似。但是,如下图所示,它可为大部分晶体管提供可编程偏置。
莱迪思半导体公司最近发布了其Certus-NX FPGA系列,该系列采用了28纳米完全耗尽绝缘体上硅(FD-SOI)工艺技术。FD-SOI最初是由三星开发的,有点类似于传统的CMOS工艺;然而,它可以为大部分晶体管提供可编程的偏置,概念性说明如下。
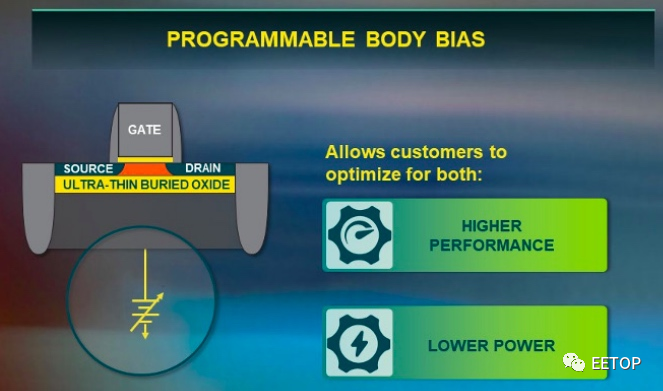
Lattice Nexus平台的电路架构
可编程的buck电压使芯片面积和功耗大大降低。与具有类似逻辑单元数量的其他FPGA相比,Certus-NX的功耗最多降低了四倍。
由于采用了FD-SOI技术,因此新器件的尺寸可小至6mm x 6mm,与类似的FPGA相比,每mm2的 I/O多达两倍。下表将Certus-NX-40与Intel和Xilinx的类似产品进行了比较。
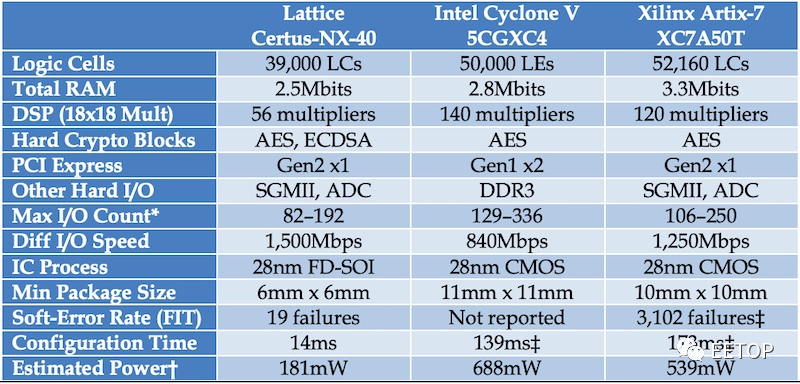
三种用于PCIe设计的流行FPGA的比较
需要注意的是,新设备支持用于批量加密的AES和用于身份验证的椭圆曲线(ECDSA)。因此,它可以为联网设备提供更高的安全性。此外,它还具有较高的抗软误差能力,这使得该装置适合于航空航天应用。
FPGA发展趋势
通过研究Xilinx,Intel和Lattice Semiconductors的这些最新发布的FPGA,我们可以更清楚地了解FPGA的发展方式-集中于更高的存储器带宽、AI优化、低功耗和小尺寸。
编辑:黄飞
-
Altera、Lattice、Xilinx角逐低成本FPGA市场2012-07-29 2153
-
[分享]长期供应xilinx、lattice u***下载线2009-07-03 5073
-
DAQmx VISA ,生产者与消费者模式这三者之间的作用是什么,三者之间有什么联系2015-09-14 3598
-
Lattice被收购 FPGA市场再次洗牌2016-12-07 6651
-
勇敢的芯伴你玩转Altera FPGA连载5: Altera、Xilinx和Lattice2017-09-27 5262
-
MCU、DSP与FPGA三者之间有何关系2021-09-24 2058
-
UART SPI IIC的详解及三者的区别和联系2021-12-13 1493
-
论无人机三者险的重要性,万一下次是豪车呢? 什么是无人机三者险?2021-12-30 1570
-
开口管式极板电池、AGM电池、GEL电池三者的对比2009-11-06 9390
-
Lattice半导体被中资机构收购,国产FPGA出路何在?2016-11-04 1859
-
Actel、Altera、Lattice和Xilin四大FPGA供应商专家谈FPGA设计诀窍2018-10-26 1764
-
英特尔、FPGA、重庆这三者到底能产生怎样的火花2018-12-21 4861
-
Lattice被收购后,国产FPGA的出路在哪2019-10-22 15341
-
Lattice被收购,FPGA行业又将走向何方?2020-11-04 7020
-
市值仅为62亿美元的Lattice,凭啥三年涨了693%2021-05-18 4225
全部0条评论

快来发表一下你的评论吧 !
