

使用广角镜头边缘进行深度感知和里程测量
描述
论文主要思路
广角相机以小、轻、经济高效的外形提供丰富的信息,是移动机器人的独选。内部和外部的精确标定是使用广角镜头边缘进行深度感知和里程测量的关键先决条件。使用当前最先进的技术标定广角镜头会产生较差的结果,这是由于边缘处的极度失真,因为大多数算法假设镜头的低到中等失真(更接近针孔投影)。
在这项工作中,作者提出了精确广角标定的方法。论文的pipelines生成一个中间模型,并利用它迭代改进特征检测,最终改进相机参数。作者测试了三种利用中间相机模型的关键方法:(1)将图像分解为虚拟针孔相机,(2)将目标重新投影到图像帧中,以及(3)自适应亚像素细化。将自适应子像素细化和特征重投影相结合,可将重投影误差显著提高26.59%,帮助检测到最多42.01%的特征,并提高密集深度映射下游任务的性能。
最后,TartanCalib是开源的,并在一个易于使用的标定工具箱中实现。作者还提供了一个translation 层和其它最先进的工作,允许使用数千个参数回归通用模型或使用更稳健的求解器。为此,TartanCalib是广角标定的首选工具!
带有广角镜头的摄像机以紧凑的外形放大了移动机器人的视野(FOV),由于较大的视野带来更多的视觉特征,因此该功能为关键任务(如视觉里程计和深度mapping)提供了许多好处。然而,为了充分利用具有高失真水平的图像区域,必须仔细标定。通常,通过向相机显示已知的标定目标来获得标定参数,然后将其用于估计相机模型的内参和多相机系统的外参。与普通镜头不同,广角镜头由于图像的高度失真,会带来一些特殊挑战:
(1) 由于极端的透镜畸变,鲁棒且准确地检测标定目标的视觉特征是具有挑战性的;
(2) 可用的相机模型可能不太适合广角镜头,先前的工作主要集中在获得更合适的相机模型[1]、[2]、[3]、[4],或找到更好的程序来拟合相机模型[5]、[6]、[7]、[8]。
因此,大多数公开可用的工具仅在广角透镜的中间区域提供可接受的标定结果,其中畸变适中,使大多数高度畸变的边界区域无法使用。为了使更多的图像区域可用并有效地探索广角镜头边界附近嵌入的视觉信息,我们需要更好的标定,以提供改进的内部和外部参数估计。
主要创新点
这里,论文专注于高失真区域中的精确和鲁棒目标检测,如图1所示,现有技术的目标标定pipelines[10]、[11]、[1]在高失真的情况下出现故障。这些标定pipelines的两个关键程序,目标检测和特征细化,依赖于低到中等失真的假设或接近针孔相机的相机投影。

这些假设在广角镜头的情况下被违反,尤其是在图像边界附近。结果是,许多特征要么没有被检测到,要么没有以准确的方式被检测到。对于那些稀疏检测到的边界特征,由于特征细化方法在高失真区域的性能不佳,它们的像素位置往往不准确。
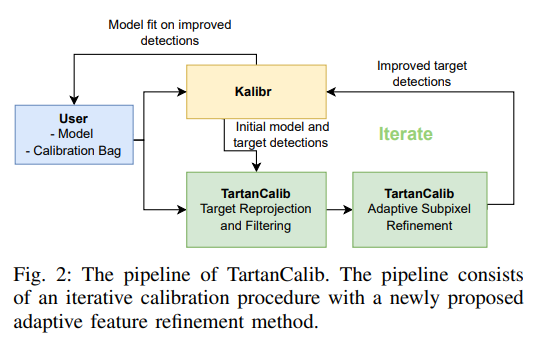
上述问题恶化了估计的相机模型的质量,并限制了广角镜头的边界区域的可用性。在这项工作中,作者提出了一个迭代标定pipelines(图2),它由三个核心元素组成:
(1)原始图像的不失真;
(2)使用中间相机模型将目标重新投影到图像帧中;
(3)基于重新投影的目标尺寸的自适应子像素细化;
对于本文的方法,作者开发了两种新的亚像素特征细化方法,以促进在高度失真区域中的精确目标检测,从而在广角镜头的边界区域中实现更好的整体标定。贡献包括:
1)一种新的广角镜头标定方法,使用迭代目标重投影和自适应亚像素细化;
2)使用传统的质量指标(如再投影误差)以及与移动机器人相关的一些下游任务,展示了pipelines的优势;
3)将论文的pipelines展示为一个开源易用的软件包,称之为“TartanCalib”。
使用论文的方法,发现了高达42.01%的更多特征,并降低了高达26.59%的总体再投影误差。整个pipelines是开源的,可以很容易地集成到Kalibr中!
领域背景
Camera Models
典型的标定程序需要为镜头选择参数化或通用相机模型,并在标定过程中估计模型参数。有许多模型是专门为广角镜头设计的,因为它们的投影与低失真相机有很大不同。一些更常见的模型是双球体模型[2]、Kannala Brandt模型[4]和视场模型[3]。参数化模型通常只有几个自由度,与一般模型相比,它们的参数更容易估计,但在精度上提供了折衷。
通用模型有更多的参数,旨在更准确地表示透镜几何结构,已经表明,这些模型具有显著更低的再投影误差[1]。可以区分非中心通用模型和通用模型。中心通用模型[12]、[13]假设所有观测线都在投影中心相交,而非中心通用模型则不作此假设[14]、[15]。
通常,非中心通用模型表现更好,但部署起来可能更复杂(例如,在不知道像素深度的情况下,不可能对针孔图像进行失真)。论文的工具箱TartanCalib支持参数化和通用相机模型,以实现最佳标定。
Calibration Toolboxes
由于几何相机标定是许多机器视觉应用的重要先决条件,因此开发了许多标定工具箱([8], [16], [17])。著名的计算机视觉软件包OpenCV[18]有自己的广角镜头标定支持,并支持棋盘目标。OcamCalib[8]是另一个众所周知的工具箱,专门使用(精度较低的[10],[19])棋盘靶进行标定。
最近,BabelCalib[5]被提出,其鲁棒优化策略是关键优势。然而,最常用的标定工具箱是Kalibr[9],它易于使用,可以检索具有多种相机模型和目标的多个相机的内参和外参。在这项工作中,TartanCalib作为一个易于使用的工具箱集成到Kalibr[9]中。除了Kalibr,TartanCalib还支持使用BabelCalib作为求解器,以及通常更精确的通用模型[1]。
模式设计与特征检测
目标检测是标定pipelines的关键功能之一,到目前为止,最常用的标定目标是棋盘[18]、点图案[20]和AprilTags[10]。点图案容易受到透视和镜头畸变的影响,而棋盘格在仅部分观察时往往会失败,这使得标定广角镜头极为困难。一些研究人员建议使用新的模式,如三角形特征[19]、[1]来增加梯度信息,但这些模式通常对广角(鱼眼)镜头边缘的高失真不够鲁棒。
在[1]中,作者使用单个AprilTag来确定自定义目标的姿态,并假设单应性作为相机模型,将目标重新投影到图像帧上。对于高失真广角镜头,这种方法有三个基本问题:(1)使用单个AprilTag不够稳健;(2)使用单应性作为目标重投影的相机模型会产生重投影误差,从而无法恢复真实的目标位置;(3) 所使用的细化方法对于AprilTags(和棋盘)是不稳定的。
受[1]的启发,我们提出了一种为AprilTags网格设计的pipelines,TartanCalib采用迭代过程,这使得可以使用相对精确的中间相机模型而不是单应性,将目标点重新投影到图像帧中,此外,作者提出了两种新的自适应亚像素细化方法,以优异的亚像素精度获得更多检测到的特征!
预备工作
相机模型
相机模型通常由投影和反投影函数组成。投影函数π:Ω → Θ将3D点投影到图像坐标,它的反投影函数:将图像坐标反投影到单位球体上,3D点的投影可以描述为π(x,i),其中x是3D空间中的点,i是相机模型的参数集。类似地,反投影函数表示为,其中u是图像空间中的坐标。
标定方法
TartanCalib(图2)背后的高级思想是通过利用中间相机模型来改进目标检测,迭代优化相机模型,迭代包括几个关键组件,将在下面的部分中详细介绍。这些组件包括无失真、目标重投影,角点滤波和亚像素细化。标定目标的视觉特征表现为corner 特征,可以互换地将corners称为目标特征。
undistortion
在广角相机标定中改进目标检测的一种直观方法是将图像分解为多个针孔重投影,这种方法应该可以消除高度失真目标造成的一些困难。为了消除图像失真,论文对一个虚拟针孔相机进行建模,它有四个参数i=[fx,fy,cx,cy],投影函数定义为:
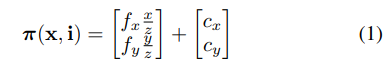
其中fx和fy是焦距,cx和cy是主点的像素坐标。通过首先将针孔像素坐标反投影到S^2空间,然后将这些点重新投影回扭曲的图像帧,可以创建虚拟针孔相机。查询扭曲帧中该位置的像素位置,并将其替换回针孔图像,以获得未失真的图像。
目标重新投影
虽然undistortion 减少了镜头失真,但由于透视失真和其它视觉伪影(如运动模糊),可能仍然无法检测到目标。如[1]所述,可以重新投影已知目标坐标返回到图像帧中,而没有实际检测到目标。作者表明,单应性可以用于此目的,等式2显示了如何使用相机模型将点从目标坐标(xt)重新投影到图像坐标(ut)。
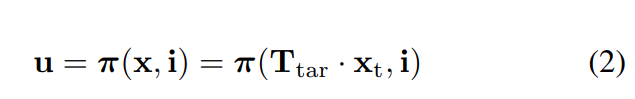
这里,Ttar是从目标帧到相机帧的变换,xt是目标帧中的坐标,x是相机帧中的向量。
Corner Filtering
虽然使用中间相机模型将目标重新投影到图像帧中可能会产生一些精确的估计,但不确定是否所有目标都在帧中可见。因此,需要一个过滤策略,只保留框架中出现的特征(角点),论文通过以下步骤实现稳健过滤:
1)在所有检测到的四边形(检测到的正方形)上循环;
2)检查每个四边形的所有4个角是否都接近重新投影的目标corner;
3)对所有corner执行亚像素细化;
亚像素细化
需要亚像素细化来将使用中间模型重新投影的特征转换为与图像中所见的角点实际匹配的特征,论文提出了两种算法:1) 对OpenCV的cornerSubPix()函数的简单修改[21],以及2) 一种专门为高失真透镜设计的基于对称的细化方法。
1) Adaptive cornerSubPix():cornerSubPix()计算搜索窗口内的图像梯度,以便向corner迭代收敛。为此,搜索窗口的大小是一个关键的超参数:如果 搜索窗口太小,算法可能永远找不到角点,而大窗口会产生不准确的结果,甚至会收敛到另一个角点。窗口大小通常是一个固定的参数,对于不同的图像分辨率或失真级别不会改变,图1展示了当窗口大小选择不当时产生的问题。在这项工作中,论文介绍了cornerSubPix()的自适应版本,它根据图像帧中的标签外观来更改窗口大小。
等式3显示了如何确定调整大小窗口的大小,该算法将所有目标特征重新投影到图像帧中,并针对每个特征在图像帧中找到其最近的邻居。然后,根据等式3,我们使用该信息来缩放搜索窗口。
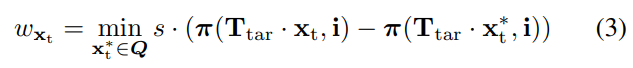
2)基于对称的细化:[1]的作者首次提出通过优化基于对称的成本函数来细化标定目标检测,原始成本函数如等式4所示:
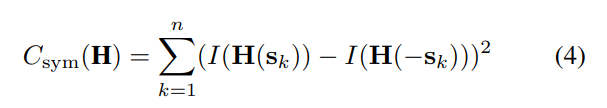
这里H是从目标帧到图像帧的单应性,其中目标帧中的中心是正在细化的特征,sk和−sk是目标帧中的两个样本,其被定义为使得原点对应于特征位置。然后,作者使用Levenberg-Marquardt方法优化H,以最小化Csym。作者表明,使用deltille网格、棋盘格及其自定义目标,该方法是最精确的细化方法。
他们的自定义目标由单个AprilTag组成,以确定目标平面和图像平面之间的单应性,图像平面由多个星形特征点包围。使用单个AprilTag确定的单应性用于对每个特征进行单应性的初始猜测,因此,重要的是,被标定的相机的行为与针孔相机的行为有些接近。
因此,这种方法对于低失真到中等失真是有效的,因为投影接近单应性。然而,对于真正的超宽镜头,所提出的方法失败有两个原因:(1)未检测到单个AprilTag,以及(2)单应性假设导致细化过程失败,作者提出了一个改进的版本,优化了一个修改的基于对称的目标函数,如等式5所示:
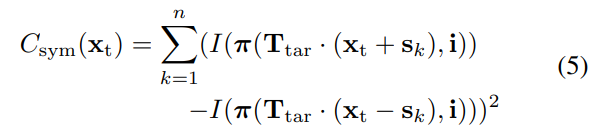
这里,xt是特征在目标空间中的位置,即使用Ttar变换到相机帧,并使用投影函数π投影到图像帧。该方程中的所有步骤都是可微的,论文使用它直接优化目标帧中的特征位置,由此,利用中间模型来检索更高质量的对称样本和更好的初始估计。
Results
评估Metrics
在本节中,作者评估了一些指标,以便将TartanCalib与其它最先进的特征检测和几何相机标定方法进行比较。评估几何相机标定具有挑战性,因为特征检测和相机几何不存在gt。传统上用于几何相机标定的度量是重投影误差,尤其是在比较不同模型或优化例程时。
当特征相同时,这只是一个合适的度量,因为不同的特征分布会产生完全不同的优化问题。后面将看到,TartanCalib在整个图像中带来了更多检测到的特征,特别是在高度失真的区域,实现了其设计目的。如果相机模型不够复杂,无法拟合畸变区域中所有检测到的特征,则重投影误差可能更高。
这一观察表明,使用再投影误差作为度量是不合适的。尽管如此,给出了重投影误差以供参考,而论文使用其它定量度量,以显示来自TartanCalib的检测特征的准确性和覆盖率具有更高的质量。

Feature Detection
考虑的第一个指标是检测到的特征数量及其在球坐标中的覆盖范围。在本节中,我们将去畸变和目标重投影视为检索更多特征的方法,并将其与AprilTag检测的最新方法进行比较。
1)去畸变:在广角相机标定中改进目标检测的直观方法是将图像undistortion为多个针孔投影,这个想法是通过迭代地将图像分解为五个针孔投影来评估的。第一个平面指向相机框架的正z方向(主轴),而其它投影指向90°的极角。方位角从零开始,每个平面递增90°,五个平面一起形成一个立方体。与图2相对应,未失真的针孔投影用于迭代改进相机模型,为了量化未失真的效果,将之前收集的Lensagon BF5M图像进一步采样为包含100帧的子集。然后,使用TartanCalib将广角图像迭代地undistortion为针孔投影,在这个实验中,undistortion产生了额外的5%-10%的特征。
2)重投影:虽然多了5%-10%的特征是一个显著的改进,但它并不能解决镜头边缘特征太少的问题。将特征从目标帧重新投影到图像帧中,如第IV-B节所述!对于本实验,使用了第V-B节中描述的数据集,每次评估500张图像,图4显示了所考虑的各种方法检测到的特征的分布。

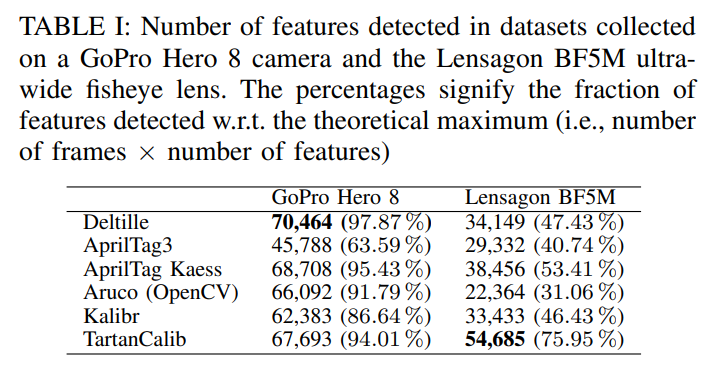
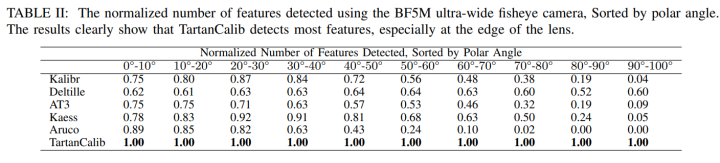
TartanCalib与其它最先进的AprilTag检测器进行了比较,分别是:(1)Kalibr,(2)Deltille[19],(3)AprilTag3(AT3)[10],[22],AprilTags的C++实现,最初由Michael Kaess博士编写,以及(4)ArUco标签检测器[23],[24],[25]。表I显示了使用每种方法检测到的特征的数量,而表II显示了按polar angle排序的检测到特征的数量。
结果表明,TartanCalib对镜头畸变最为鲁棒,在Lensagon BF5M鱼眼镜头的边缘记录了更多的特征。GoPro(图中未显示)的结果显示检测到的特征在所有模型中大致相同。作者将其原因归结为,使用较小的视场进行标定挑战性小得多。
亚像素细化
在本节中,作者比较了两种新颖的亚像素细化策略,并表明基于对称的细化对于AprilTags的网格来说太不稳定了。[1]的作者部署了低到中等失真的透镜,并在deltille网格和棋盘上测试了基于对称的细化,特别是在高失真区域,细化似乎与特征不对齐。图5显示了为什么对称性不适合使用AprilTags进行特征细化。
该图显示存在许多局部优化,因此需要高质量的初始估计。图像帧中目标位置的初始估计可能相差几个像素(如图1所示),因此可能收敛到局部最优值。因此,生成的特征与模型更好地匹配,但在高失真区域与现实世界中的特征不匹配。因此,论文假设自适应cornerSubPix()产生更稳定的特征,第V-E节对该假设进行了更详细的研究。
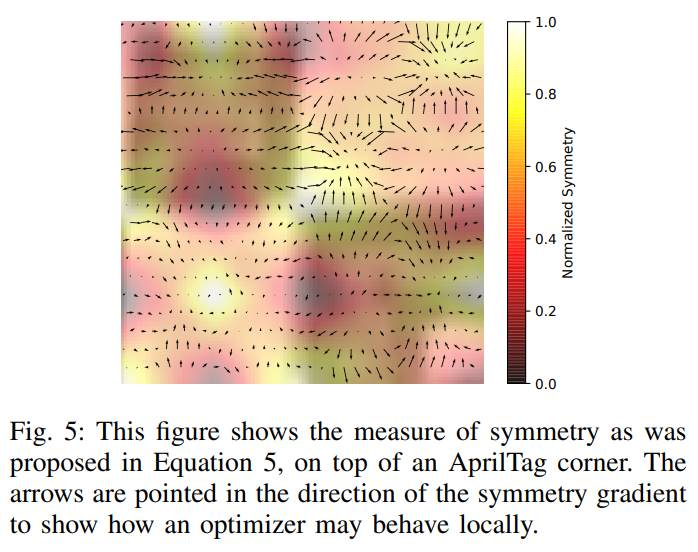
在标定特征上的对比
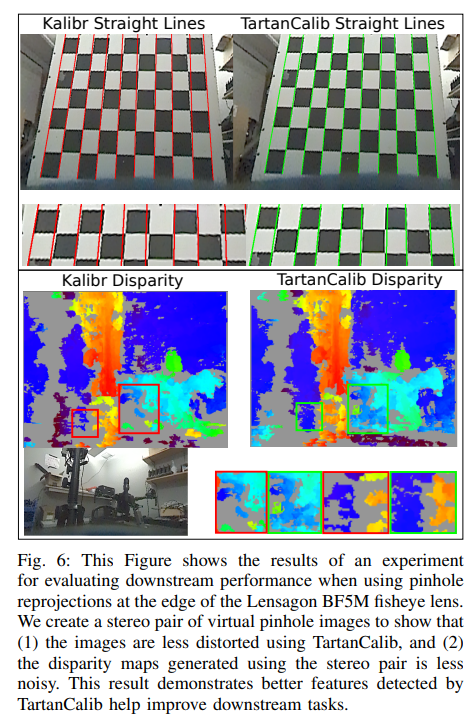
重投影误差
几何相机标定中最广泛使用的误差度量是重投影误差,给定估计的目标姿态和相机模型,可以将特征重新投影回目标帧中,并将其与检测到的corners进行比较。如上所述,这不是一个特别有用的度量,因为不同的方法输出的特征分布基本上不同(例如,TartanCalib在镜头边缘具有更多的特征)。
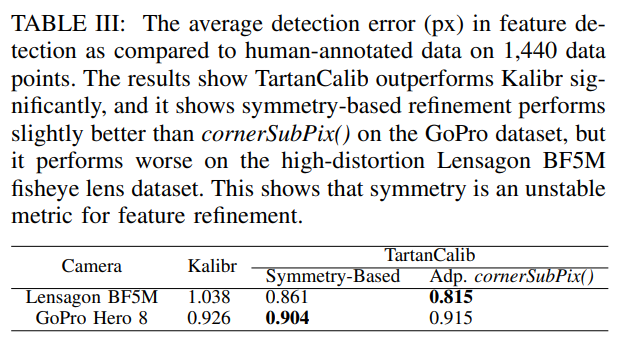
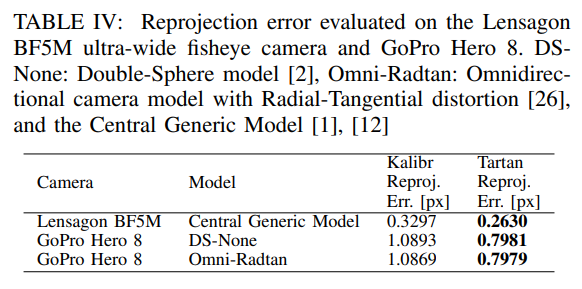
重投影误差不仅是特征的函数,还取决于相机模型拟合镜头几何形状的能力。论文进行了一个简单的实验,以表明TartanCalib可以改善重投影误差,表IV显示了使用TartanCalib时的显著改善。
审核编辑:刘清
-
FLIR 80°广角镜头在工业检测中的应用2025-06-13 1131
-
华为nova10前后置分别搭载6000万超广角镜头与5000万RYYB超感知影像单元2022-07-05 2933
-
iPhone 13将采用改进后的超广角镜头2021-03-04 2551
-
华为释疑:Mate40系列广角镜头从4000万像素缩水至2000万2020-11-01 4205
-
苹果iPhone 12将维持相同设计的超广角镜头2020-03-02 2410
-
realme真我X50 Pro前置摄像头配置公布 采用105°超广角镜头支持UIS Max超级视频防抖2020-02-19 7027
-
荣耀Magic2超广角镜头体验 更具实用性与趣味性2019-04-29 3198
-
Galaxy S10系列手机的三摄规格曝光,加入广角镜头的传闻被证实2018-08-15 4600
-
广角镜头桶形畸变的样条函数修正方法2016-06-15 848
-
短焦投影机镜头2013-07-02 4231
-
松下投影机镜头2013-07-01 2660
-
什么是镜头/广角镜头2010-02-01 695
-
什么是数码相机的广角镜头2010-01-30 1624
-
数码相机广角镜头2009-12-18 851
全部0条评论

快来发表一下你的评论吧 !
