

Python数据可视化:类别比较图表可视化
电子说
描述
在学习本篇博文之前请先看一看之前发过的关联知识:
Python数据可视化:如何选择合适的图表可视化?
根据表达数据的侧重内容点,将图表类型分为6大类:类别比较图表、数据关系图表、数据分布图表、时间序列图表、局部整体图表和地理空间图表(有些图表也可以归类于两种或多种图表类型)。
本篇将介绍类别比较图表的可视化方法。
类别比较型图表的数据一般分为:数值型和类别型两种数据类型,主要包括:柱形图、条形图、雷达图、词云图等,通常用来比较数据的规模。如下所示:

1
柱状图
柱形图是一种以长方形的长度为变量的统计图表。柱形图用于显示一段时间内的数据变化或显示各项之间的比较情况。
在柱形图中,类别型或序数型变量映射到横轴的位置,数值型变量映射到矩形的高度。控制柱形图的两个重要参数是:“系列重叠"和“分类间距”。
-
“分类间距"控制同一数据系列的柱形宽度;
-
“系列重叠"控制不同数据系列之间的距离。
下图为常见的柱形图类型:单数据系列柱形图、多数据系列柱形图、堆积柱形图和百分比堆积柱形图。
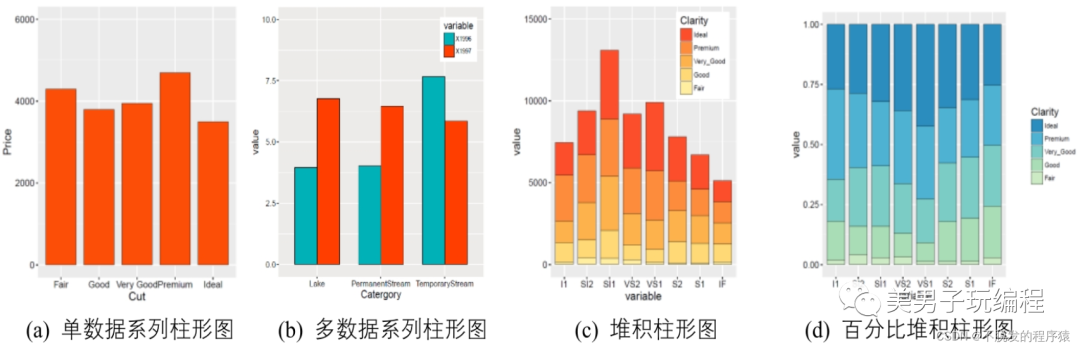
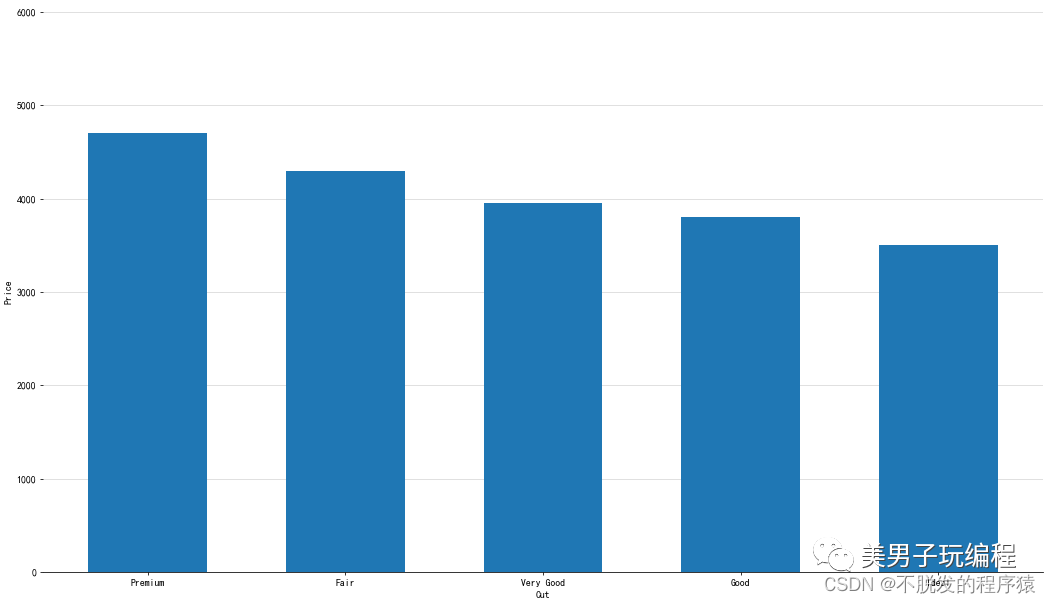
1.1、单数据系列柱形图
通过一个示例了解单数据系列柱形图的使用,实现代码如下所示:
mydata = pd.DataFrame({'Cut': ["Fair", "Good", "Very Good", "Premium", "Ideal"],
'Price': [4300, 3800, 3950, 4700, 3500]})
Sort_data = mydata.sort_values(by='Price', ascending=False)
fig = plt.figure(figsize=(6, 7), dpi=70)
plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1)
plt.grid(axis="y", c=(217/256, 217/256, 217/256))
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_color('none')
plt.bar(Sort_data['Cut'], Sort_data['Price'],
width=0.6, align="center", label="Cut")
plt.ylim(0, 6000)
plt.xlabel('Cut')
plt.ylabel('Price')
plt.show()
效果如下所示:
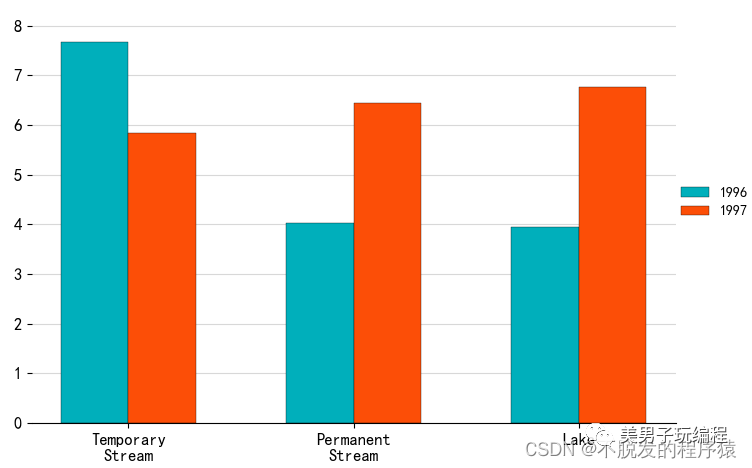
1.2、多数据系列柱形图
通过一个示例了解多数据系列柱形图的使用,实现代码如下所示:
x_label = np.array(df["Catergory"])
x = np.arange(len(x_label))
y1 = np.array(df["1996"])
y2 = np.array(df["1997"])
fig = plt.figure(figsize=(5, 5))
plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1) # 设置绘图区域大小位置
plt.bar(x, y1, width=0.3, color='#00AFBB', label='1996', edgecolor='k',
linewidth=0.25) # 调整y1轴位置,颜色,label为图例名称,与下方legend结合使用
plt.bar(x+0.3, y2, width=0.3, color='#FC4E07', label='1997',
edgecolor='k', linewidth=0.25) # 调整y2轴位置,颜色,label为图例名称,与下方legend结合使用
plt.xticks(x+0.15, x_label, size=12) # 设置x轴刻度,位置,大小
# 显示图例,loc图例显示位置(可以用坐标方法显示),ncol图例显示几列,默认为1列,frameon设置图形边框
plt.legend(loc=(1, 0.5), ncol=1, frameon=False)
plt.yticks(size=12) # 设置y轴刻度,位置,大小
plt.grid(axis="y", c=(217/256, 217/256, 217/256)) # 设置网格线
# 将y轴网格线置于底层
# plt.xlabel("Quarter",labelpad=10,size=18,) #设置x轴标签,labelpad设置标签距离x轴的位置
# plt.ylabel("Amount",labelpad=10,size=18,) #设置y轴标签,labelpad设置标签距离y轴的位置
ax = plt.gca()
ax.spines['top'].set_color('none') # 设置上‘脊梁’为无色
ax.spines['right'].set_color('none') # 设置右‘脊梁’为无色
ax.spines['left'].set_color('none') # 设置左‘脊梁’为无色
plt.show()
效果如下所示:
1.3、堆积柱形图
通过一个示例了解堆积柱形图的使用,实现代码如下所示:
# -*- coding: utf-8 -*-
# %%
import pandas as pd
import numpy as np
from plotnine import *
mydata = pd.DataFrame(dict(Name=['A', 'B', 'C', 'D', 'E'],
Scale=[35, 30, 20, 10, 5],
ARPU=[56, 37, 63, 57, 59]))
# 构造矩形X轴的起点(最小点)
mydata['xmin'] = 0
for i in range(1, 5):
mydata['xmin'][i] = np.sum(mydata['Scale'][0:i])
# 构造矩形X轴的终点(最大点)
mydata['xmax'] = 0
for i in range(0, 5):
mydata['xmax'][i] = np.sum(mydata['Scale'][0:i+1])
mydata['label'] = 0
for i in range(0, 5):
mydata['label'][i] = np.sum(mydata['Scale'][0:i+1])-mydata['Scale'][i]/2
base_plot = (ggplot(mydata) +
geom_rect(aes(xmin='xmin', xmax='xmax', ymin=0, ymax='ARPU', fill='Name'), colour="black", size=0.25) +
geom_text(aes(x='label', y='ARPU+3', label='ARPU'), size=14, color="black") +
geom_text(aes(x='label', y=-4, label='Name'), size=14, color="black") +
scale_fill_hue(s=0.90, l=0.65, h=0.0417, color_space='husl') +
ylab("ARPU") +
xlab("scale") +
ylim(-5, 80) +
theme( # panel_background=element_rect(fill="white"),
#panel_grid_major = element_line(colour = "grey",size=.25,linetype ="dotted" ),
#panel_grid_minor = element_line(colour = "grey",size=.25,linetype ="dotted" ),
text=element_text(size=15),
legend_position="none",
aspect_ratio=1.15,
figure_size=(5, 5),
dpi=100
))
print(base_plot)
2
条形图
条形图与柱形图类似,几乎可以表达相同多的数据信息。
在条形图中,类别型或序数型变量映射到纵轴的位置,数值型变量映射到矩形的宽度。条形图的柱形变为横向,从而导致与柱形图相比,条形图更加强调项目之间的大小对比。尤其在项目名称较长以及数量较多时,采用条形图可视化数据会更加美观、清晰,如下图所示:
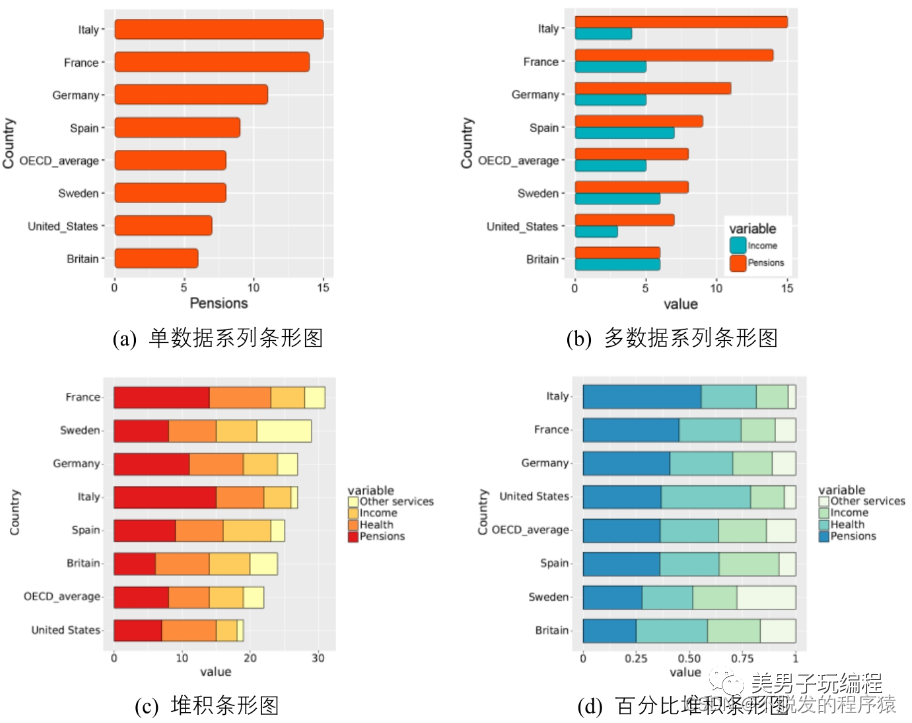
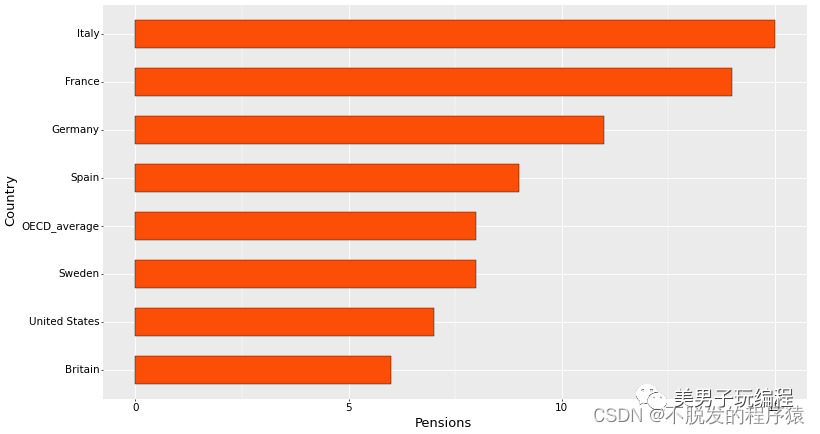
2.1、单数据系列条形图
通过一个示例了解单数据系列条形图的使用,实现代码如下所示:
df = pd.read_csv('Stackedbar_Data.csv')
df = df.sort_values(by='Pensions', ascending=True)
df['Country'] = pd.Categorical(df['Country'], categories=df['Country'], ordered=True)
df
# %%
base_plot = (ggplot(df, aes('Country', 'Pensions')) +
# "#00AFBB"
geom_bar(stat="identity", color="black", width=0.6, fill="#FC4E07", size=0.25) +
实现效果如下所示:
2.2、多数据系列条形图
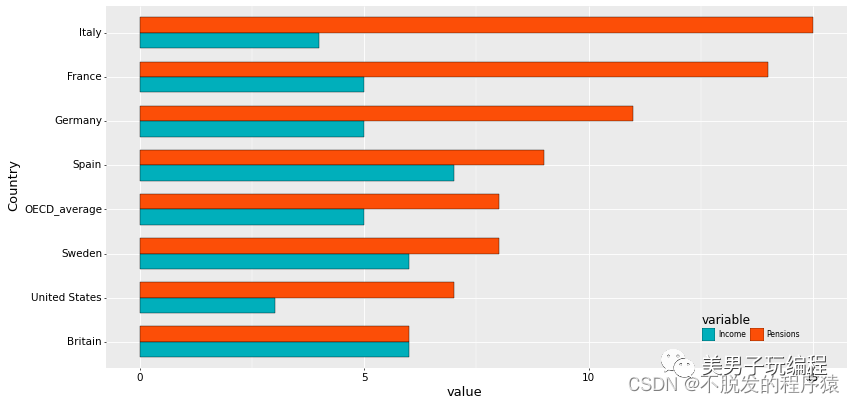
通过一个示例了解多数据系列条形图的使用,实现代码如下所示:
df = pd.read_csv('Stackedbar_Data.csv')
效果如下所示:
2.3、堆积条形图
通过一个示例了解堆积条形图的使用,实现代码如下所示:
df = pd.read_csv('Stackedbar_Data.csv')
Sum_df = df.iloc[nonedisplay: none;'>
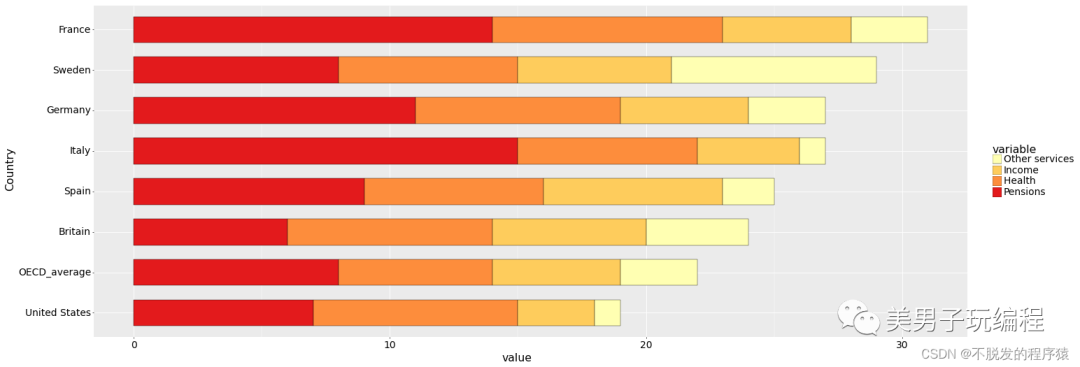
2.4、百分比堆积条形图
通过一个示例了解百分比堆积条形图的使用,实现代码如下所示:
df = pd.read_csv('Stackedbar_Data.csv')
效果如下所示:
4
词云图
词云图通过使每个字的大小与其出现频率成正比,显示不同单词在给定文本中的出现频率,这会过滤掉大量的文本信息,使浏览者只要一眼扫过文本就可以领略文本的主旨。
词云图会将所有的字词排在一起,形成云状图案,也可以任何格式排列:水平线、垂直列或其他形状,也可用于显示获分配元数据的单词。如下图所示:
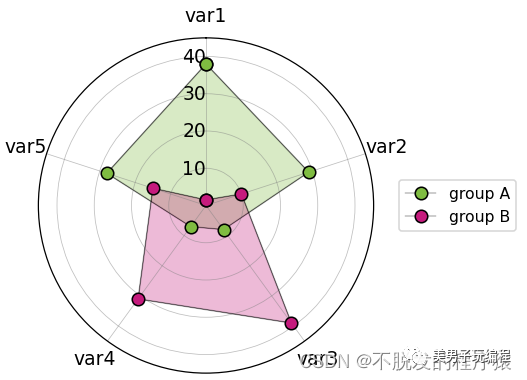
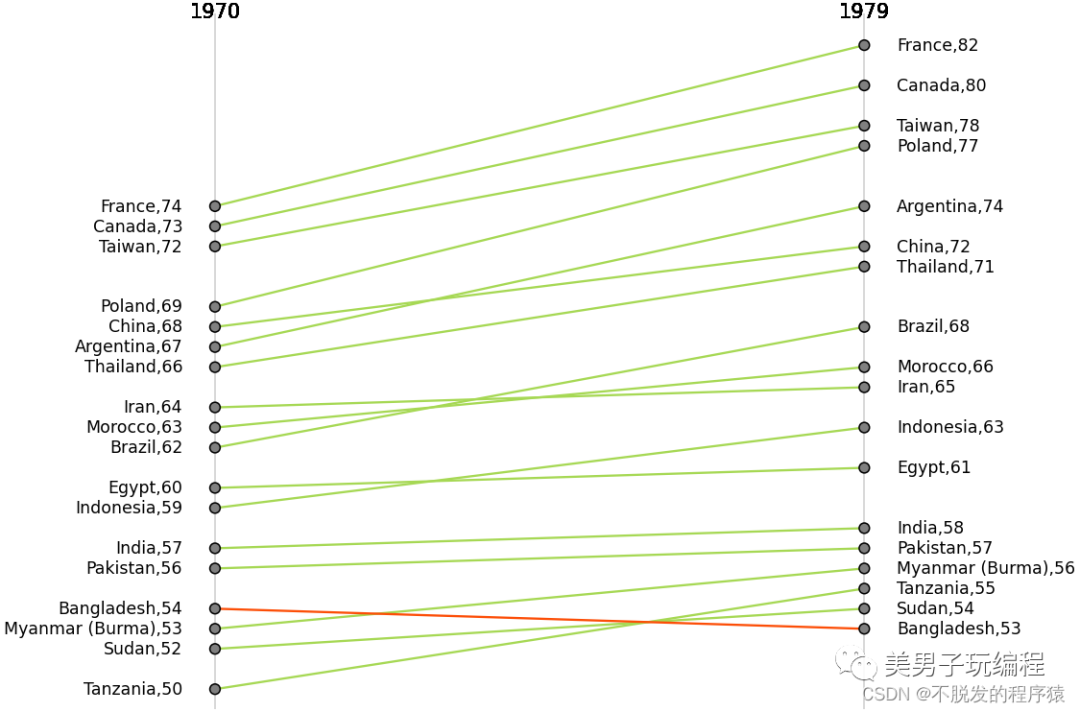 每个圆圈表示一个数值刻度,而径向分隔线(从中心延伸出来的线)则用于区分不同类别或间隔(如果是直方图)。刻度上较低的数值通常由中心点开始,然后数值会随着每个圆形往外增加,但也可以把任何外圆设为零值,这样里面的内圆就可用来显示负值。条形通常从中心点开始向外延伸,但也可以以别处为起点,显示数值范围(如跨度图)。
每个圆圈表示一个数值刻度,而径向分隔线(从中心延伸出来的线)则用于区分不同类别或间隔(如果是直方图)。刻度上较低的数值通常由中心点开始,然后数值会随着每个圆形往外增加,但也可以把任何外圆设为零值,这样里面的内圆就可用来显示负值。条形通常从中心点开始向外延伸,但也可以以别处为起点,显示数值范围(如跨度图)。
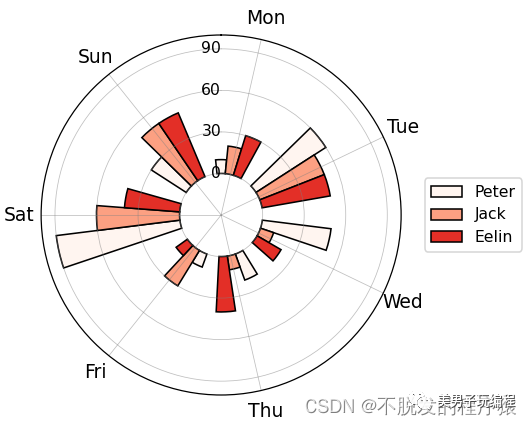
此外,条形也可以如堆叠式条形图般堆叠起来,如下图所示:
8
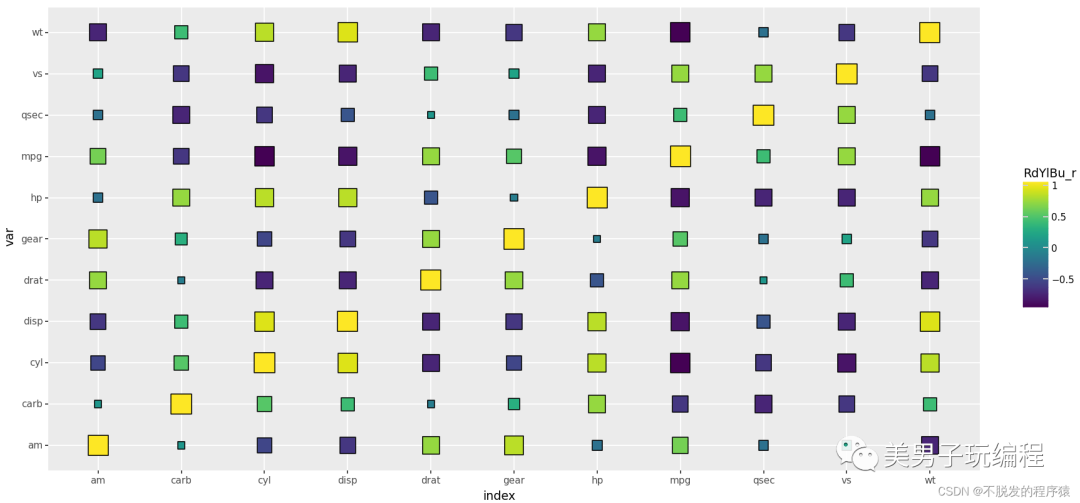
热力图
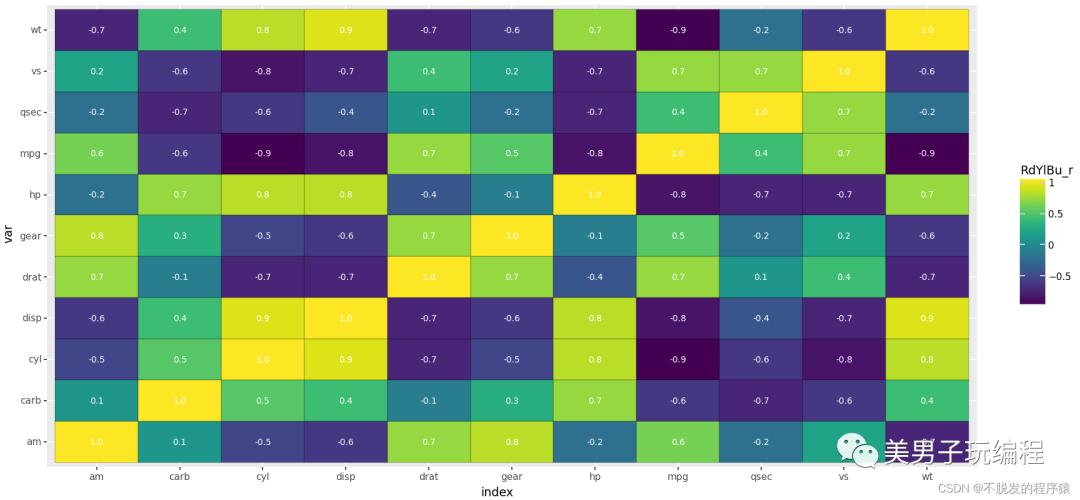
热力图是一种通过对色块着色来显示数据的统计图表,绘图时需指定颜色映射的规则。例如,较大的值由较深的颜色表示,较小的值由较浅的颜色表示;较大的值由偏暖的颜色表示,较小的值由较冷的颜色表示等。
通过一个示例了解热力图的使用,实现代码如下所示:
import numpy as np
import pandas as pd
from plotnine import *
from plotnine.data import mtcars
mat_corr = np.round(mtcars.corr(), 1).reset_index()
mydata = pd.melt(mat_corr, id_vars='index', var_name='var', value_name='value')
mydata
# %%
base_plot = (ggplot(mydata, aes(x='index', y='var', fill='value', label='value')) +
geom_tile(colour="black") +
geom_text(size=8, colour="white") +
scale_fill_cmap(name='RdYlBu_r') +
coord_equal() +
theme(dpi=100, figure_size=(4, 4)))
print(base_plot)
# %%
mydata['AbsValue'] = np.abs(mydata.value)
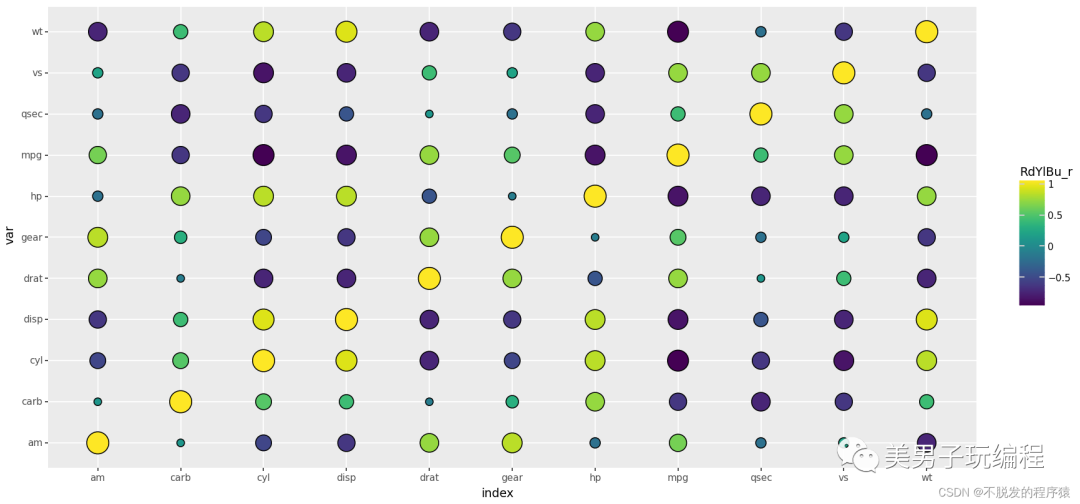
base_plot = (ggplot(mydata, aes(x='index', y='var', fill='value', size='AbsValue')) +
geom_point(shape='o', colour="black") +
# geom_text(size=8,colour="white")+
scale_size_area(max_size=11, guide=False) +
scale_fill_cmap(name='RdYlBu_r') +
coord_equal() +
theme(dpi=100, figure_size=(4, 4)))
print(base_plot)
# %%
base_plot = (ggplot(mydata, aes(x='index', y='var', fill='value', size='AbsValue')) +
geom_point(shape='s', colour="black") +
# geom_text(size=8,colour="white")+
scale_size_area(max_size=10, guide=False) +
scale_fill_cmap(name='RdYlBu_r') +
coord_equal() +
theme(dpi=100, figure_size=(4, 4)))
print(base_plot)
效果如下所示:
-
可视化MES系统软件2018-11-30 3455
-
数据可视化之Python-matplotlib概述2019-07-22 1766
-
python数据可视化的方法和代码2019-10-14 1771
-
Python数据可视化专家的七个秘密2020-05-15 2662
-
python数据可视化之画折线图2020-05-27 1647
-
Python数据可视化2020-07-19 3414
-
三维可视化的应用和优势2020-12-02 2808
-
一般图表做不了的分析,BI数据可视化图表可以2021-01-15 1875
-
怎么做以中国地图为底图的数据可视化报表?2021-07-06 8708
-
新手必看:数据可视化图表的选择技巧2022-09-29 51275
-
经验分享|BI数据可视化报表布局——容器2023-03-15 4487
-
Python拉勾网数据采集与可视化2018-03-13 3996
-
使用Python可视化数据,机器人开发编程2018-03-15 10158
-
Python数据可视化编程实战2021-06-01 1130
-
什么是大屏数据可视化?特点有哪些?2024-12-16 1443
全部0条评论

快来发表一下你的评论吧 !
