

如何应用深度学习领域技术解决网络问题
人工智能
描述
第36届 SIGCOMM 于2022年8月22日-8月26日在荷兰阿姆斯特丹召开。本次会议共收到279篇投稿,接收55篇论文,录取率为19.71%。 厦门大学SNG的同学们按照会议日程对论文内容进行了分期评述,本期介绍session6的论文。 Session 6: Machine Learning
Genet: Automatic Curriculum Generation for Learning Adaptation in Networking
Zhengxu Xia (University of Chicago), Yajie Zhou (Boston University), Francis Y. Yan (Microsoft Research), Junchen Jiang (University of Chicago)
背景
这篇文章来自芝加哥大学,波士顿大学和微软的研究者。它提出了一个针对增强学习的新框架Genet,利用课程学习(curriculum learning)自动搜索会给训练带来实质性改善的环境,逐步提供相对困难的环境以提高学习和训练效果。 目前,增强学习在网络领域的应用已经成为了热点,但在实际应用中仍存在一些限制条件,例如,(1)传统RL训练中通常会从给定的训练范围内均匀地抽取网络环境样本,这使得在狭窄分布上进行训练时泛化性较差(poor generalizability);(2)在训练分布较广的情况下也会出现不容易收敛的情况(poor converged)。因此,需要考虑如何改善RL训练,使学习到的适应策略在广泛的目标网络环境中取得良好的性能。
设计
为了解决上述问题,本文提出使用课程学习(curriculum learning)来改变RL训练环境的分布,引入新环境为模型提供越来越多的学习机会。逐渐增加了训练环境的难度,因此在训练中会看到更多更有可能改进的环境,我们称之为奖励环境(reward environment)。在许多RL的应用中,先前的工作已经显示了课程学习的前景,包括更快的收敛、更高的渐进性能和更好的泛化。 那么,随之需要解决的问题是:我们如何确定哪些环境是对训练更有益的,也就是说如何按顺序排列网络环境,使得优先考虑当前RL策略的回报率高的环境。本文的工作提出这一观点:如果当前的RL模型与基线有很大的差距(gap-to-baseline),即RL策略的性能在环境中落后于传统的基于规则的基线,则认为环境是有价值的。 基于这个观点,设计出Genet这一学习框架。如图所示,通过迭代识别当前RL模型与基线有较大差距的奖励环境,然后将其加入RL训练,从而生成RL训练课程。
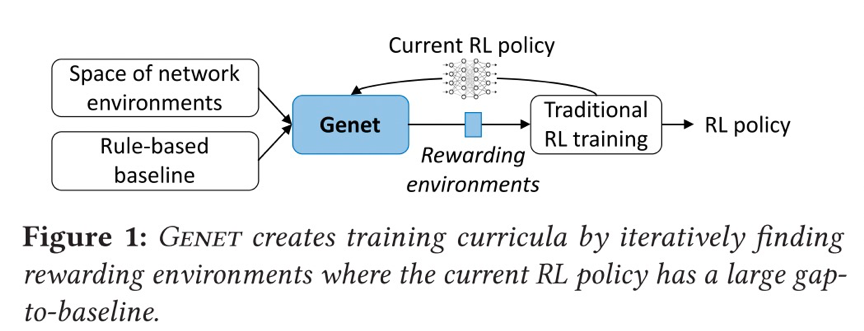
对于每个RL用例,Genet对网络环境空间进行了参数化,使我们能够在综合实例化的环境和跟踪驱动的环境中搜索到有价值的环境。Genet还使用贝叶斯优化(BO)来促进大空间中的搜索。
评估
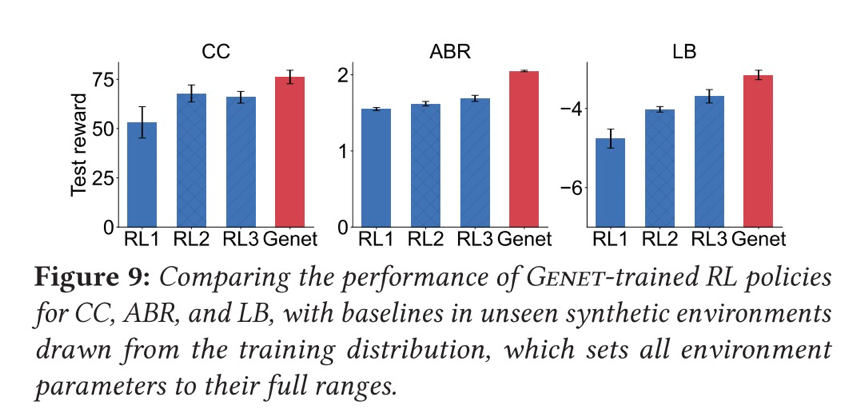
本文使用跟踪驱动的模拟和真实世界的测试相结合,跨越三个用例(ABR、CC、LB),结果表明Genet与传统的RL训练方法相比,ABR的渐进性能提高了8-25%,CC提高了14-24%,LB提高了15%。
个人观点
在增强学习逐步成为解决网络领域重要问题的有效手段的背景下,本文工作者研究如果有效提升增强学习训练的效果,重点关注了训练环境对训练效果产生的影响,是一个具有实际意见的研究点,创新点在于利用课程学习的方法为训练不断更新合适的环境。但如同在本文讨论部分中提到的问题:gap-to-baseline值高或者低的环境是否总是意味着RL模型在对其进行训练时有小或者大的改进?本文在这一问题上所进行的论证或者实验不是非常充分。
LiteFlow: Towards High-performance Adaptive Neural Networks for Kernel Datapath
Junxue Zhang, Chaoliang Zeng (Hong Kong University of Science and Technology), Hong Zhang (UC Berkeley), Shuihai Hu, Kai Chen (Hong Kong University of Science and Technology)
背景
自适应神经网络在变化的环境中可以实现超高性能,所以在操作系统kernel数据路径中部署这些网络表现出流行趋势。然而,现有的部署方法存在局限性。一种部署的方法是部署在user-space,然而,这样的方法导致很高的cross-space 通信开销和低响应,极大影响了函数性能;另一种方法是部署到纯kernel-space,但这种方法会导致很大的性能下降,因为典型的模型微调的算法的计算逻辑十分复杂,干扰了正常的datapath的执行性能。模型推理要求快速执行,适合kernel-space,模型微调要求高精度和大量的计算,适合部署在user-space。
设计
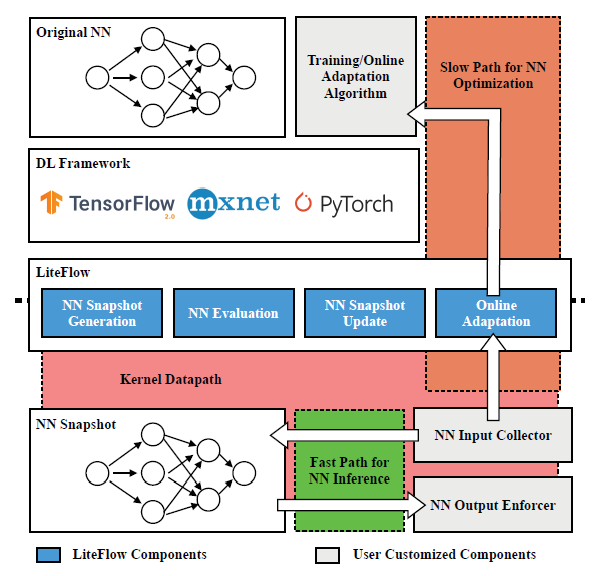
基于以上的观察,一种符合直觉的方法是解耦自适应神经网络的控制路径:模型推理放到kenel-space,模型微调放到user-space。 然而,实现这个思路有3个挑战:1. 这样的设计要求两个目标:既兼容kenel-space,又兼容user-space,要求大量的开发和debug;2.kernel-space的神经网络不能及时体现神经网络微调的结果;3.在user-space训练要求从kernel-space的数据传输,导致性能下降。 为了解决这些挑战,作者提出LiteFlow。LiteFlow将自适应神经网络的控制路径解耦为:为高效模型推理的kernel space快速路径,为有效模型微调的user space慢速路径。设计框架上,Lite Flow是一个混合框架,它包括user-space的组件和kernel-space的组件。给定一个user-space的神经网络,LiteFlow首先生成神经网络快照,该快照将被部署到kernel-space以实现快速推理。同时,LiteFlow也收集该快照的输入和输出数据来进一步微调user-space的神经网络。在训练几批数据后,LiteFlow将评估是否需要更新快照。
评估
作者在congestion control(Aurora和MOCC模型),flow scheduling(FFNN模型)和path selection(MLP模型)任务中评估了LiteFlow的效果。在congestion control中,神经网络的输入是RTT,ECN等这些拥塞信号,输出是流的发送速率。Aurora使用强化学习算法,利用2层全连接层;MOCC使用多目标强化学习,用2层全连接层,提升了Aurora的设计。对比方法选择的是纯user-space发布,传统在kernel-space发布。实验结果显示,LiteFlow可以实现更高的有效吞吐量,分别超出44.4%和26.6%,此外,吞吐量的标准差也更小,说明LiteFlow缓解了cross-space通信。为了测试在线自适应能力,作者禁用LiteFlow的神经网络自适应功能,实验结果表明goodput显著下降。 在开销方面,使用LiteFlow部署的性能和kernel-space的相近,超出user-space的性能,表明缓解cross-space的开销是重要的。为了理解批数据不同传输间隔的影响,作者也进行相关实验,结果表明所花费的时间不超过14.1%。 此外,LiteFlow在高吞吐量时性能下降不超过5%。 在flow scheduling场景中,作者对比了FFNN在user-space和LiteFlow的FFNN,预测延迟和flow completion time的实验结果表明,LiteFlow的延迟更低,在flow completion time上表现更优。 在load balancing上,作者使用的神经网络是MLP,对比的方法是user-space方式和禁止更新的LiteFlow,结果表明LiteFlow在短流和长流上都超出对比方法。
总结
LiteFlow通过将kernel-space、user-spcae与inference、training分别对齐,实现了自适应神经网络的高性能推理、基于反馈更新。实验结果证明了方法有效。
个人观点
神经网络的推理引擎已经有很多,比如mnn等。然而,考虑到在线学习维度,当前的推理引擎和训练引擎都不能很好满足。这篇论文分析了神经网络训练和推理的特点、user-sapce和kernel-sapce的特点,然后设计LiteFlow将之对齐,弥补了之前的研究空白。
Multi-Resource Interleaving for Deep Learning Training
Yihao Zhao, Yuanqiang Liu (Peking University), Yanghua Peng, Yibo Zhu (ByteDance Inc.), Xuanzhe Liu, Xin Jin (Peking University)
背景
训练深度学习模型正在成为计算集群的重要负载之一。该训练过程需要多种资源,包括CPU,GPU,存储IO,网络IO。在典型的多任务场景下,如何为不同作业分配合适的资源是一个经典调度问题。然而,现有的深度学习调度器聚焦在GPU分配上,忽视了其他类型资源的调度。
设计
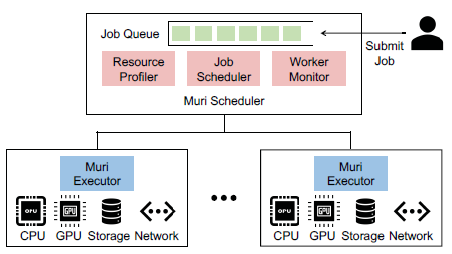
为了实现多种资源的高效调度,作者提出了深度学习训练作业的key observations:训练深度学习模型表现出明显的阶段性,这样的阶段迭代进行。这个现象为时间上细粒度的多资源交替使用创造了条件。比如,深度学习训练的每个阶段包括数据加载、预处理、前向和反向传播、梯度同步操作。每个子阶段都高度使用一种资源,这使不同作业的不同阶段在资源集合上交替执行成为可能。 作者提出Muri。Muri的核心思想是调度多个作业对资源的交替使用来最大化资源利用率或作业完成时间。Muri把交替作业调度问题建模为k维最大带权匹配问题,采用Blossom算法为单个GPU作业在两种资源类型之间找到最佳组合计划,并且使用多轮方法来处理超过两种资源的情况。 在架构上,Muri包括3个组件:resource profiler,job scheduler、worker monitor。 resource profiler负责测量每个job对每种资源的利用情况,并估计不同作业交替时的效率;job scheduler维护一个job queue,当job到达或job完成时,基于不同job group的交替效率和resource profiler的信息,job scheduler使用多轮job 聚类算法来决定哪些job组成群体来共享资源,从而实现资源利用最大化;worker monitor负责收集每台机器的资源信息并跟踪每个job的训练进度。最后,基于job scheduler生成的策略,每台机器上会配备Muri executor,它负责将策略具体执行。
评估
作者建立了Muri原型,并集成到PyTorch中。实验评估选择在一个8台机器,每台机器配备8个GPU、2个Xeon Platinum、256GB内存、1个Mellanox CX-5单口网卡的集群上进行。作者使用了Microsoft的trace。在作业时间已知时,选择SRSF和2D-LAS作为对比方法;在作业时间未知时,选择Tiresias,AntMan和Themis作为对比方法。实验结果表明,和现有的深度学习调度器相比,Muri在JCT方面提升3倍,在makespan上提升1.6倍。
总结
作者观察到深度学习作业存在阶段迭代特征,联系到这些作业的训练会使用多种类型资源,因此提出使用多资源交替来提升集群和作业效率。作者首先把调度问题建模为k维最大带权匹配问题,然后使用Blossom算法求解最佳组合计划。实验效果验证了该方法可以提升资源效率和作业完成时间。
个人观点
尽管作者在文中做了大量努力来区分Muri与pipeline,但本人觉得Muri可以看作是pipeline扩到到multi-job时的调度问题,因此研究问题的价值有限。会议上,有人问到的2个问题:一是关于multi-job的交替执行安全性问题,二是关于profiler准确性问题。和提问者一样,个人对这2点也持保留意见,作者在会议上的答复并不令人信服。
DeepQueueNet: Towards Scalable and Generalized Network Performance Estimation with Packet-level Visibility
Qing-Qing Yang, Xi Peng (Huawei Theory Lab), Li Chen (Zhongguancun Laboratory), Libin Liu (Shandong Computer Science Center), Jingze Zhang, Hong Xu (Chinese University of Hong Kong), Baochun Li (University of Toronto), Gong Zhang (Huawei Theory Lab)
这篇工作来自华为理论实验室,中关村实验室,香港中文大学,山东省计算机科学中心和多伦多大学的多位研究者。通过将基于可扩展DNN的连续仿真与离散事件仿真相结合,提出了一种可扩展的、可推广的、具有包级可见性的网络性能估计器DeepQueueNet。
背景
网络模拟器是网络操作人员理解实际应用任务网络的重要工具,可以帮助完成容量规划、拓扑设计和参数调优等任务。目前,主流的模拟器都是基于离散事件模拟的,它们的性能无法适应现代网络的规模。同时,随着基于深度学习的技术被引入来解决可扩展性问题,本文工作者通过实验表明它们的模拟结果的可见性很差,并且不能推广到不同的场景。因此,我们需要一个具有更好的通用性,更高的可扩展性,并且在数据包级别具有可见性的网络模拟器。
设计
本文结合了离散事件模拟 (DES) 和连续模拟,提出了一个高层次的设计方法:首先建立一个理论基础来尽可能多地表达我们对网络的先验知识,然后识别数学上难以处理或计算量大的部分,最后将这些部分替换为可以使用真实数据跟踪训练的 DNN。按照这一思路,本文缩小 DNN 在端到端性能评估器 (EPE) 中的应用范围——从网络/集群规模到设备规模,仅使用 DNN 来对设备本地交通管理 (TM) 机制进行建模。本文使用两个子模型组成设备模型:数据包级转发模型(PFM)和数据包级 TM 模型(PTM)。PFM 指定转发行为,可以使用给定路由表的张量乘法来明确描述。PTM 预测每个数据包经历多少延迟。 如图所示为DeepQueueNet的架构,由五个核心组件组成:(1)设备模型实用程序 (DUtil) 生成经过训练的设备模型;(2)设备模型库 (DLib) 存储和索引经过训练的设备模型,包括交换机、路由器和链路;(3)流量生成实用程序 (TGUtil) 根据用户规范创建流量生成器 (TGen);(4)模拟设置模块 (SInit) 解析用户输入并设置模拟;(5)模拟执行模块 (SRun) 运行模拟。与现有 DES 实现的工作流程相同类似,DeepQueueNet 通过以下步骤完成任务:准备模拟设置(拓扑、设备配置和流量生成器)、运行模拟、收集数据包跟踪以及通过将任意度量应用于结果进行分析。
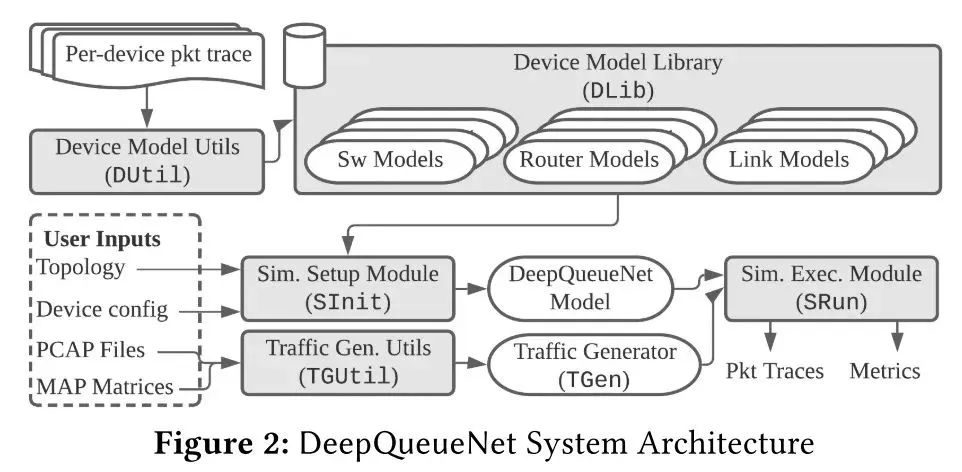
评估
1)准确性:与最先进的基于 DNN 的 EPE相比,DeepQueueNet 在所有场景中的平均和第 99 个百分位往返时间 (RTT) 均实现了卓越的准确性。 2)泛化性:通过大量实验表明,DeepQueueNet 关于归一化 wasserstein distance的估计精度在拓扑、TM配置和流量生成模型的变化中仍然很高,无需重新训练模型。 3)可扩展性:展示了DeepQueueNet可以使用多个GPU 并行加速。本文在4-GPU集群上部署DeepQueueNet,它展示了随着 GPU 数量的近线性加速。
个人观点
这篇论文的工作量十分扎实,提出的DeepQueueNet系统框架的建模也较为复杂。创新地将主流的网络模拟器从离散事件拓展到基于DNN的连续模拟与离散事件模拟相结合,基于先验知识缩小DNN的应用范围。这些方法较为新颖,但是由于个人水平有限,对于整个系统的设计细节还未有更深入的理解,期待看到这个工作在更多评估实验和实际应用中的性能测试。
Practical GAN-based Synthetic IP Header Trace Generation using NetShar
Yucheng Yin, Zinan Lin, Minhao Jin, Giulia Fanti, Vyas Sekar (Carnegie Mellon University)
本文来自卡内基·梅隆大学的研究者,它探索了使用生成对抗网络 (GAN) 自动学习生成模型以生成用于网络任务(例如遥测、异常检测、配置)的数据包和流级别的标头跟踪(Packet- and flow-level header traces)的可行性,并开发出一个端到端框架NetShare
背景
数据包和流级别的标头跟踪对于许多网络管理工作流至关重要。它们用于指导网络监控算法的设计和开发,开发新型异常检测和指纹识别以及用于基准测试去检验新的硬件和软件功能。由于隐私性等问题,我们无法直接访问此类痕迹。往往通过合成痕迹(synthetic traces)来实现。目前,存在通过模拟驱动方法(simulation-driven)、模型驱动方法(model-driven)和机器学习模型(machine learning models)的方法生成合成痕迹的工作,但这些方法都各自存在问题:比如说基于模拟和模型驱动的方法需要大量的领域知识和人力来确定关键的工作负载特性和配置生成参数,同时不能很好地跨应用程序进行泛化。基于机器学习的方法容易泛化,但无法捕获特定领域的属性。 因此在这项工作中,研究者探索了使用生成式对抗网络生成基于ML的合成包头和流头跟踪的可行性,并设计出NetShare用来产生合成痕迹从而解决上述问题。
设计
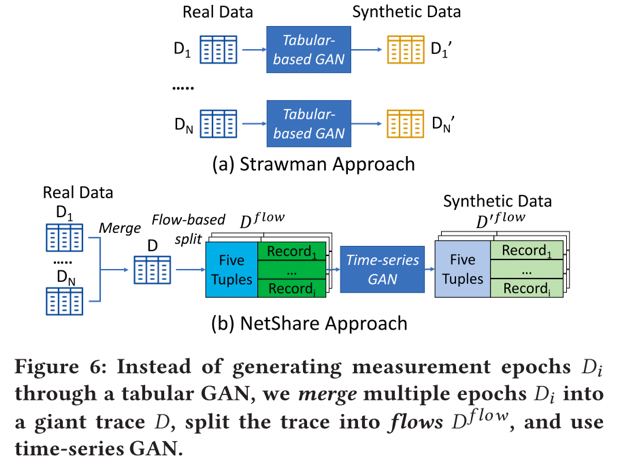
1)本文将标头跟踪生成(header trace generation)重新表述为一个时间序列生成问题,即生成整个跟踪的流量记录,而不是每个epoch的表格方法。
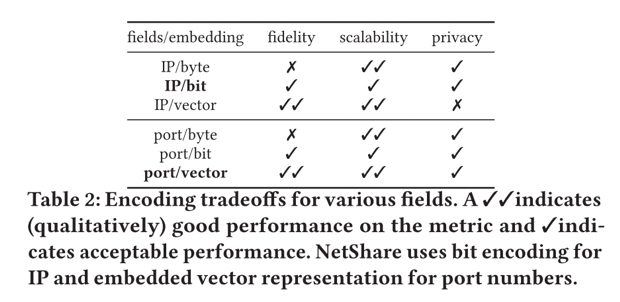
2)本文使用领域知识和机器学习的细致组合来告知标头字段的表示,以平衡保真度-隐私-可扩展性的权衡。 本文不是在原始数据表示上训练GAN,而是使用领域知识将某些领域转换为更易于 GAN 处理的格式。对于具有数字语义的字段,例如每个流的数据包/字节数,我们使用对数转换。对于 IP 地址/端口号/协议等分类字段,使用 IP 地址的按位编码,使用 IP2Vec 对端口号和协议进行编码。表格显示了针对 IP/端口的不同嵌入选择在保真度、可扩展性和隐私性方面的定性分析。
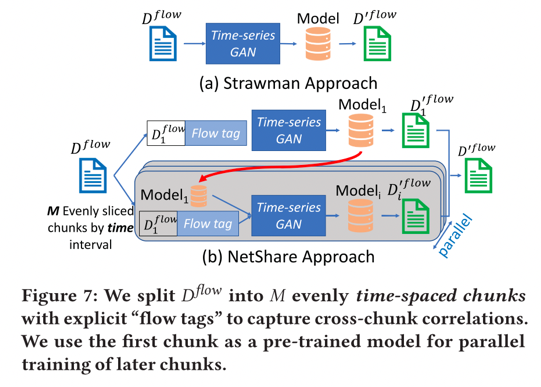
3)本文可以通过微调和并行训练来提高可扩展性和保真度的权衡。 首先,本文工作者从 ML文献中借用微调的想法,即:使用预训练模型作为“热启动”来为未来模型进行种子训练。具体来说,使用第一个块作为“种子”块来进行热启动,随后的块使用从第一个块训练的模型进行微调,这允许跨块进行并行训练。同时本文们将“flowtags”附加到每个flowheader以捕获块间的相关性,用0-1标志注释每个流标头,表示它是否从“this”块开始,还在标志之后附加一个0-1向量,其长度等于块的总数,每个位指示流标头是否出现在该特定块中。
4)本文可以通过谨慎使用公共数据集来改善隐私-保真度的权衡。在 NetShare 中,研究者利用以下观察结果:通过在相关公共数据集上预训练 NetShare,可以减少达到固定保真度水平所需的 DP-SGD 轮数;然后,再从公共数据集中获取学习参数,并使用 DP-SGD 3 这些在私有数据集上进行微调。这样做可以减少了所需的 DP-SGD 迭代次数。
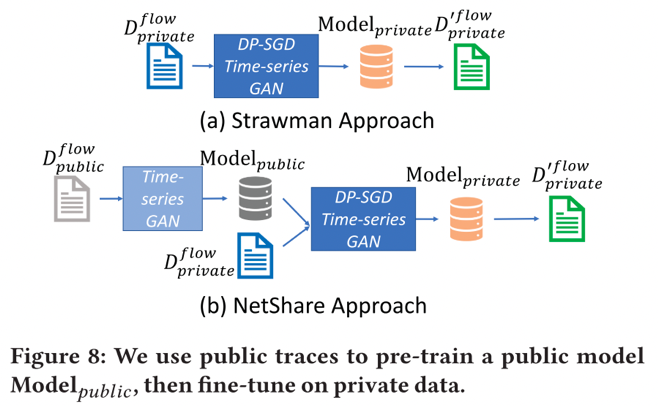
评估
我们在六个不同的数据包头跟踪上评估 NetShare,结果表明 : 1) 在所有的分布指标和跟踪中,NetShare比使用不同生成式建模技术的基线方法的准确率高出46%。 2) NetShare满足了用户对下游任务的要求,保持了算法的准确性和有序性。 3) NetShare实现了比基线更好的可扩展性-保真度权衡。 4) 与基线方法相比,NetShare可以产生更高质量的差异化的私有痕迹。
个人观点
这也是一篇应用深度学习领域技术解决网络问题的工作,创新点在于提出使用GAN来生成数据包和流级别的标头跟踪,是一个值得深入研究的方向。在本文中,针对生成的标头跟踪在实际网络任务中的实验结果不是很多,并且对于提出的端到端框架NetShare的可拓展性缺乏说明。
- 相关推荐
- 热点推荐
- 深度学习
-
深度学习与卷积神经网络的应用2024-07-02 2413
-
详解深度学习、神经网络与卷积神经网络的应用2024-01-11 4192
-
基于深度学习的语音合成技术的进展与未来趋势2023-09-16 2604
-
深度学习是什么领域2023-08-17 3939
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2202
-
深度学习DeepLearning实战2021-01-09 19161
-
什么是深度学习,深度学习能解决什么问题2020-11-05 5581
-
轻量级深度学习网络是什么2020-04-23 3177
-
FPGA在深度学习领域的应用2019-06-28 7913
-
深度学习在各个领域有什么样的作用深度学习网络的使用示例分析2018-11-25 9531
-
MATLAB机器学习与深度学习核心技术应用培训班2018-10-23 3595
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 4428
-
2017全国深度学习技术应用大会2017-03-22 4166
全部0条评论

快来发表一下你的评论吧 !
