

在 NVIDIA NGC 上搞定模型自动压缩,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
描述
PaddleSlim 发布 AI 模型自动压缩的工具,带来全新升级 AI 模型一键自动压缩体验。欢迎广大开发者使用 NVIDIA 与飞桨联合深度适配的 NGC 飞桨容器在 NVIDIA GPU 上体验!
PaddleSlim 自动压缩工具,
30+CV、NLP 模型实战
众所周知,计算机视觉技术(CV)是企业人工智能应用比重最高的领域之一。为降低企业成本,工程师们一直在探索各类模型压缩技术,来产出“更准、更小、更快”的 AI 模型部署落地。而在自然语言处理领域(NLP)中,随着模型精度的不断提升,模型的规模也越来越大,例如以 BERT、GPT 为代表的预训练模型等,这成为企业 NLP 模型部署落地的拦路虎。
针对企业落地模型压缩迫切的需求,PaddleSlim 团队开发了一个低成本、高收益的 AI 模型自动压缩工具(ACT, Auto Compression Toolkit),无需修改训练源代码,通过几十分钟量化训练,保证模型精度的同时,极大的减小模型体积,降低显存占用,提升模型推理速度,助力 AI 模型的快速落地!
使用 ACT 中的基于知识蒸馏的量化训练方法训练 YOLOv7 模型,与原始的 FP32 模型相比,INT8 量化后的模型减小 75%,在 NVIDIA GPU 上推理加速 5.90 倍。
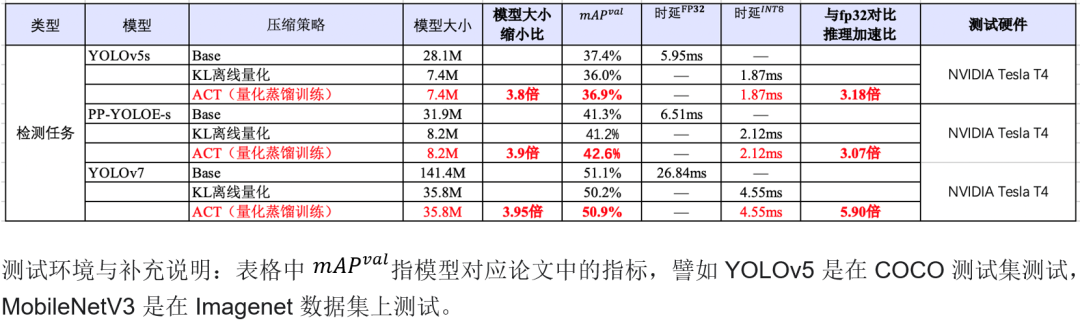 表1 自动压缩工具在 CV 模型上的压缩效果和推理加速
表1 自动压缩工具在 CV 模型上的压缩效果和推理加速使用 ACT 中的结构化稀疏和蒸馏量化方法训练 ERNIE3.0 模型,与原始的 FP32 对比,INT8 量化后的模型减小 185%,在 NVIDIA GPU 上推理加速 6.37 倍。

表2 自动压缩工具在 NLP 模型上的压缩效果和推理加速
支持如此强大功能的核心技术是来源于 PaddleSlim 团队自研的自动压缩工具。自动压缩相比于传统手工压缩,自动化压缩的“自动”主要体现在 4 个方面:解耦训练代码、离线量化超参搜索、算法自动组合和硬件感知。
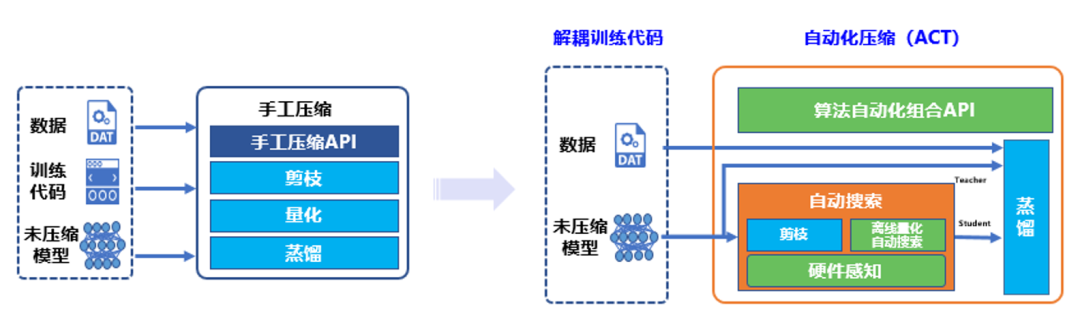
图1 传统手工压缩与自动化压缩工具对比
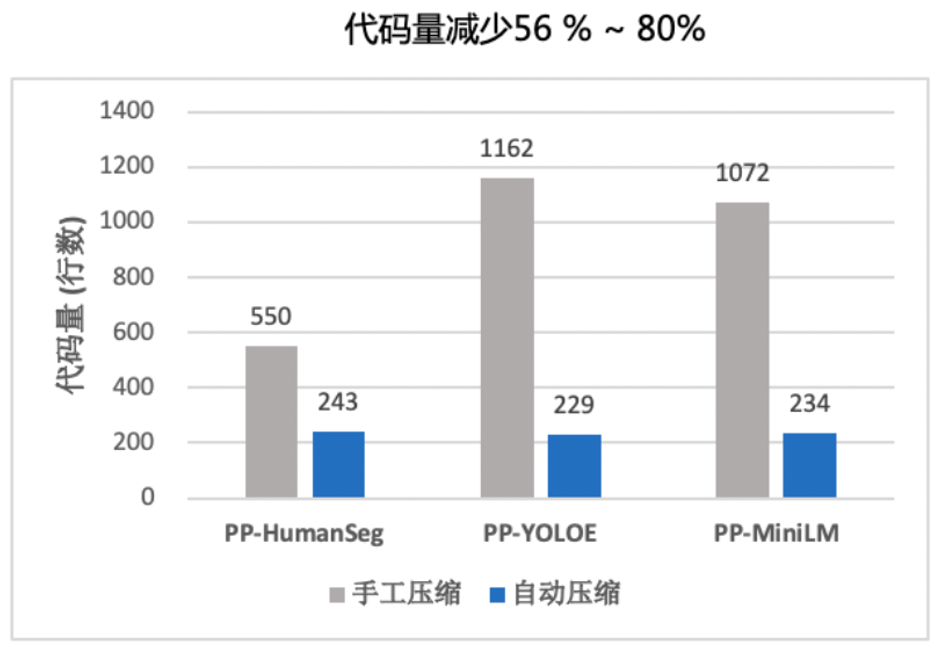
图2 传统手工压缩与自动化压缩工具代码量对比
更多详细文档,请参考:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
PaddleSlim 研发团队详解自动压缩工具 CV 模型和NLP模型两日课回放,可以扫描下方二维码,加入自动压缩技术官方交流群获取。除此之外,入群福利还包括:深度学习学习资料、历届顶会压缩论文、百度架构师详解自动压缩等。

NGC 飞桨容器介绍
如果您希望体验自动压缩工具的新特性,欢迎使用 NGC 飞桨容器。NVIDIA 与百度飞桨联合开发了 NGC 飞桨容器,将最新版本的飞桨与最新的 NVIDIA 的软件栈(如 CUDA)进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
最佳的开发环境搭建工具 - 容器技术。
-
容器其实是一个开箱即用的服务器。极大降低了深度学习开发环境的搭建难度。例如你的开发环境中包含其他依赖进程(redis,MySQL,Ngnix,selenium-hub 等等),或者你需要进行跨操作系统级别的迁移。
-
容器镜像方便了开发者的版本化管理
-
容器镜像是一种易于复现的开发环境载体
-
容器技术支持多容器同时运行
最好的 PaddlePaddle 容器
NGC 飞桨容器针对 NVIDIA GPU 加速进行了优化,并包含一组经过验证的库,可启用和优化 NVIDIA GPU 性能。此容器还可能包含对 PaddlePaddle 源代码的修改,以最大限度地提高性能和兼容性。此容器还包含用于加速 ETL(DALI,RAPIDS)、训练(cuDNN,NCCL)和推理(TensorRT)工作负载的软件。
PaddlePaddle 容器具有以下优点:
-
适配最新版本的 NVIDIA 软件栈(例如最新版本 CUDA),更多功能,更高性能。
-
更新的 Ubuntu 操作系统,更好的软件兼容性
-
按月更新
-
满足 NVIDIA NGC 开发及验证规范,质量管理
通过飞桨官网快速获取
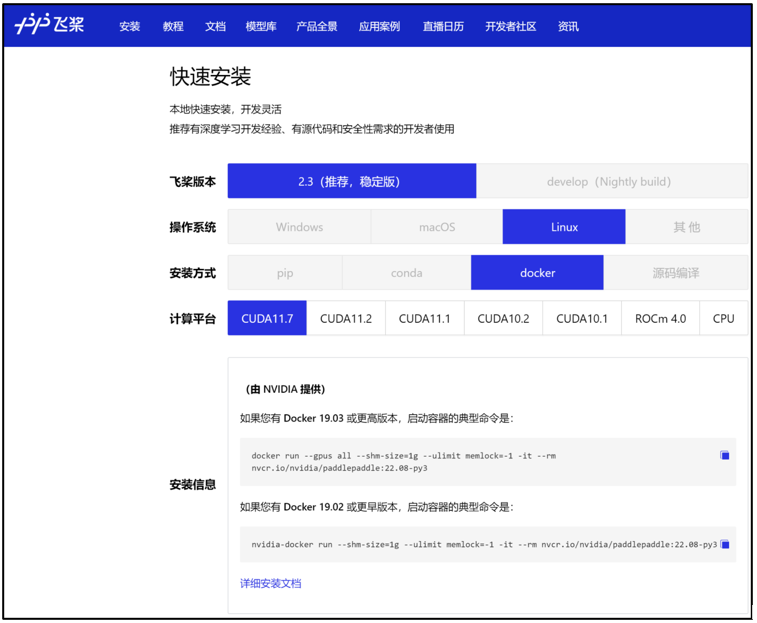
环境准备
使用 NGC 飞桨容器需要主机系统(Linux)安装以下内容:
-
Docker 引擎
-
NVIDIA GPU 驱动程序
-
NVIDIA 容器工具包
有关支持的版本,请参阅 NVIDIA 框架容器支持矩阵和 NVIDIA 容器工具包文档。
不需要其他安装、编译或依赖管理。无需安装 NVIDIA CUDA Toolkit。
NGC 飞桨容器正式安装:
要运行容器,请按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container 一章中的说明发出适当的命令,并指定注册表、存储库和标签。有关使用 NGC 的更多信息,请参阅 NGC 容器用户指南。如果您有 Docker 19.03 或更高版本,启动容器的典型命令是:

*详细安装介绍 《NGC 飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
*详细产品介绍视频
【飞桨开发者说|NGC 飞桨容器全新上线 NVIDIA 产品专家全面解读】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
原文标题:在 NVIDIA NGC 上搞定模型自动压缩,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 英伟达
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 2986
-
无法使用MYRIAD在OpenVINO trade中运行YOLOv7自定义模型怎么解决?2023-08-15 641
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 2239
-
YOLOv7训练自己的数据集包括哪些2023-05-29 2444
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 2960
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2850
-
模型压缩技术,加速AI大模型在终端侧的应用2023-04-24 4148
-
yolov7 onnx模型在NPU上太慢了怎么解决?2023-04-04 1198
-
ERNIE 3.0 Tiny新模型,压缩部署“小”“快”“灵”!欢迎在 NGC 飞桨容器中体验 PaddleNLP 最新版本2023-02-22 2649
-
在 NGC 上玩转新一代推理部署工具 FastDeploy,几行代码搞定 AI 部署2022-12-13 2582
-
深度解析YOLOv7的网络结构2022-09-14 8952
-
YOLOv5s算法在RK3399ProD上的部署推理流程是怎样的2022-02-11 3629
-
Tengine 支持 NPU 模型部署-YOLOv5s2022-01-25 814
-
NVIDIA加速计算平台:更强大的GPU加速,更简化的部署流程2019-05-16 4340
全部0条评论

快来发表一下你的评论吧 !
