

SpringBoot利用ThreadPoolTaskExecutor批量插入百万级数据实测!
电子说
1.4w人已加入
描述
前言
- 开发目的: 提高百万级数据插入效率。
-
采取方案: 利用
ThreadPoolTaskExecutor多线程批量插入。 - 采用技术: springboot2.1.1+mybatisPlus3.0.6+swagger2.5.0+Lombok1.18.4+postgresql+ThreadPoolTaskExecutor等。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://gitee.com/zhijiantianya/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
具体实现细节
application-dev.properties添加线程池配置信息
> 基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
>
> * 项目地址:
> * 视频教程:
spring容器注入线程池bean对象
@Configuration
@EnableAsync
@Slf4j
public class ExecutorConfig {
@Value("${async.executor.thread.core_pool_size}")
private int corePoolSize;
@Value("${async.executor.thread.max_pool_size}")
private int maxPoolSize;
@Value("${async.executor.thread.queue_capacity}")
private int queueCapacity;
@Value("${async.executor.thread.name.prefix}")
private String namePrefix;
@Bean(name = "asyncServiceExecutor")
public Executor asyncServiceExecutor() {
log.warn("start asyncServiceExecutor");
//在这里修改
ThreadPoolTaskExecutor executor = new VisiableThreadPoolTaskExecutor();
//配置核心线程数
executor.setCorePoolSize(corePoolSize);
//配置最大线程数
executor.setMaxPoolSize(maxPoolSize);
//配置队列大小
executor.setQueueCapacity(queueCapacity);
//配置线程池中的线程的名称前缀
executor.setThreadNamePrefix(namePrefix);
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//执行初始化
executor.initialize();
return executor;
}
}
创建异步线程 业务类
@Service
@Slf4j
public class AsyncServiceImpl implements AsyncService {
@Override
@Async("asyncServiceExecutor")
public void executeAsync(List logOutputResults, LogOutputResultMapper logOutputResultMapper, CountDownLatch countDownLatch) {
try{
log.warn("start executeAsync");
//异步线程要做的事情
logOutputResultMapper.addLogOutputResultBatch(logOutputResults);
log.warn("end executeAsync");
}finally {
countDownLatch.countDown();// 很关键, 无论上面程序是否异常必须执行countDown,否则await无法释放
}
}
}
创建多线程批量插入具体业务方法
@Override
public int testMultiThread() {
List logOutputResults = getTestData();
//测试每100条数据插入开一个线程
List> lists = ConvertHandler.splitList(logOutputResults, 100);
CountDownLatch countDownLatch = new CountDownLatch(lists.size());
for (List listSub:lists) {
asyncService.executeAsync(listSub, logOutputResultMapper,countDownLatch);
}
try {
countDownLatch.await(); //保证之前的所有的线程都执行完成,才会走下面的;
// 这样就可以在下面拿到所有线程执行完的集合结果
} catch (Exception e) {
log.error("阻塞异常:"+e.getMessage());
}
return logOutputResults.size();
}
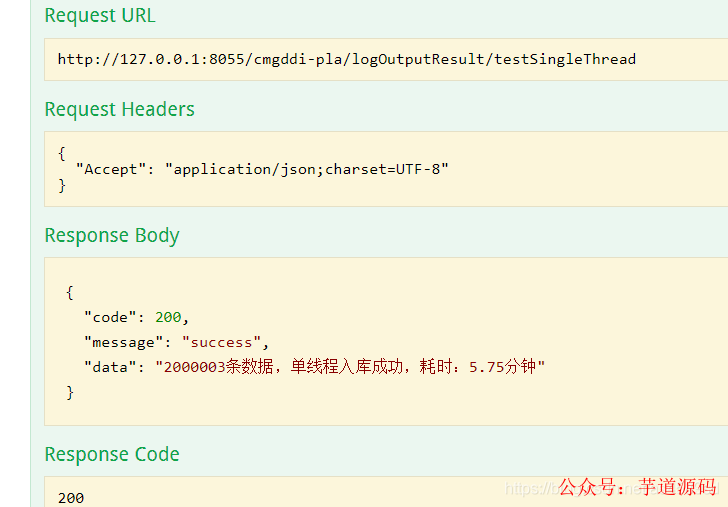
模拟2000003 条数据进行测试

多线程 测试 2000003 耗时如下:耗时1.67分钟
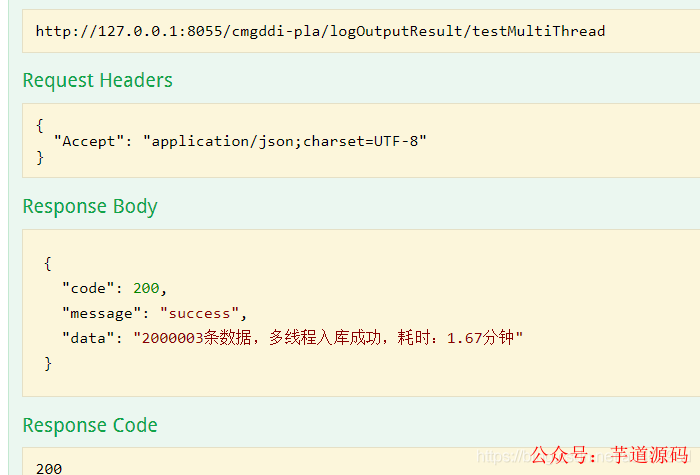

本次开启30个线程,截图如下:
单线程测试2000003 耗时如下:耗时5.75分钟

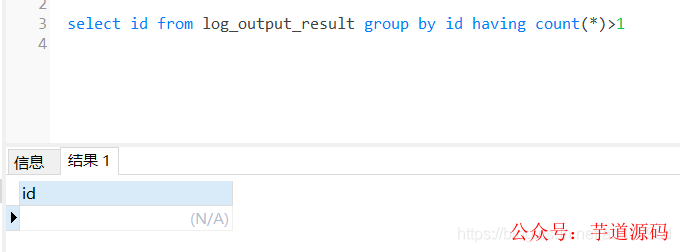
检查多线程入库的数据,检查是否存在重复入库的问题:
根据id分组,查看是否有id重复的数据,通过sql语句检查,没有发现重复入库的问题
检查数据完整性:通过sql语句查询,多线程录入数据完整
测试结果
不同线程数测试:


总结
通过以上测试案列,同样是导入2000003 条数据,多线程耗时1.67分钟,单线程耗时5.75分钟。通过对不同线程数的测试,发现不是线程数越多越好,具体多少合适,网上有一个不成文的算法:
CPU核心数量*2 +2 个线程。
附:测试电脑配置

审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- SQL
- 多线程
- spring
- SpringBoot
-
SpringBoot中的Druid介绍2019-05-07 2924
-
SpringBoot知识总结2019-08-01 1981
-
SpringBoot项目多数据源配置数据库2020-06-05 1345
-
几种数据库的大数据批量插入解决方法2020-11-04 2079
-
springboot集成mqtt2021-07-16 964
-
怎样去使用springboot呢2021-10-25 1138
-
如何利用大数据实现加速和最佳化芯片设计2017-12-20 4707
-
百万级数字电能表2021-05-17 848
-
MySQL 批量插入不重复数据的解决方法2021-07-02 2959
-
百万量级数据不要怕,一招教你精准锁定2021-09-27 1153
-
MyBatis批量插入数据的3种方法你知道几种2021-12-08 5176
-
利用JAVA向Mysql插入一亿数量级数据—效率测评2022-05-24 4005
-
MySQL批量插入数据的四种方案(性能测试对比)2022-10-28 3595
-
MySQL在执行批量操作的时候一次插入多少数据才合适呢?2023-01-31 8523
-
什么是 SpringBoot?2023-04-07 2477
全部0条评论

快来发表一下你的评论吧 !
