

面向Aspect情感分析的自动生成离散意见树结构
描述
在本文中,我们探索了一种简单的方法,为每个方面自动生成离散意见树结构。用到了RL。
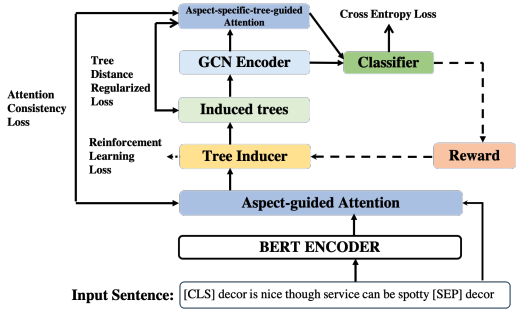
首先为每个方面生成离散意见树,设方面词的位置为[b,e],则首先将方面跨度[b, e]作为根节点,然后分别从跨度[1,b−1]和[e+1, n]构建它的左子节点和右子节点。为了构建左子树或右子树,我们首先选择span中「得分最大的元素」作为子树的根节点,然后递归地对相应的span分区使用build_tree调用。(除了方面词外其他node都是单个词)。
关于得分分数的计算,选择将""作为BERT的输入得到特殊于方面词的句子表达H,然后按照如下计算得分:
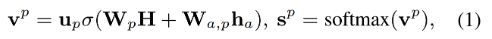
其中h是H中方面词部分的平均池化,构建树的这部分包含的参数有三个以及BERT参数部分。
构建树的这一部分称为,输入为x和a(用于打分),输出为一棵树,参数 ϕ 包括上述参数。这一部分参数使用RL进行更新而不是最终损失函数的反向传播。
生成树以后开始正式执行预测任务,模型非常简单。
将上面得到的树生成邻接矩阵,经过GCN(可能多层),取最后一层GCN的输出结果的方面词部分以及[CLS]这个token的表达之和作为query,与GCN的输入的初始向量特征(也就是原句子经过句子编码器得到的)做注意力机制,用输入去表达最终的方面级分类特征。
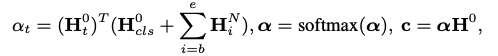
最后输出分类结果
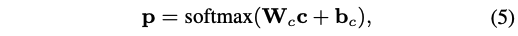
损失函数:
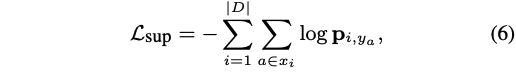
注意这个论文分为两个模块,第一个是生成树,利用得到t;第二部分是预测, ,这里的 θ 包括GCN模块的参数和输出(等式5)的部分,PS注意力模块没有引进参数哦。
第二部分使用上述损失函数进行优化,由于树的采样过程是一个离散的决策过程,因此它是不可微的,第一部分使用的是RL进行优化。
强化学习实现训练部分还没看。
实验效果和分析
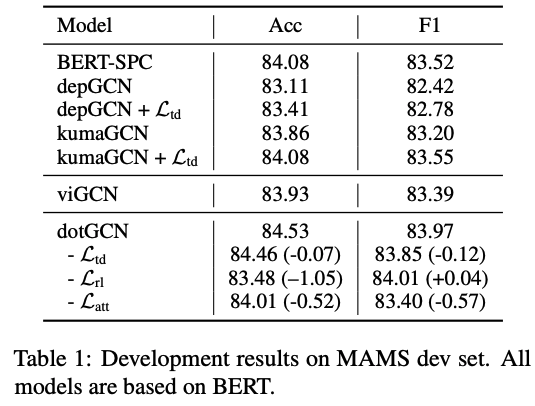
MAMS 开发集效果
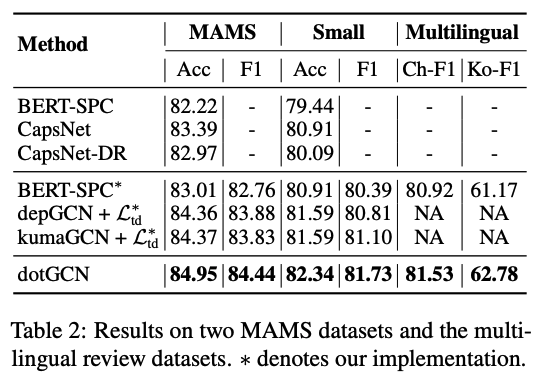
在MAMS数据上和多语言评论数据的结果
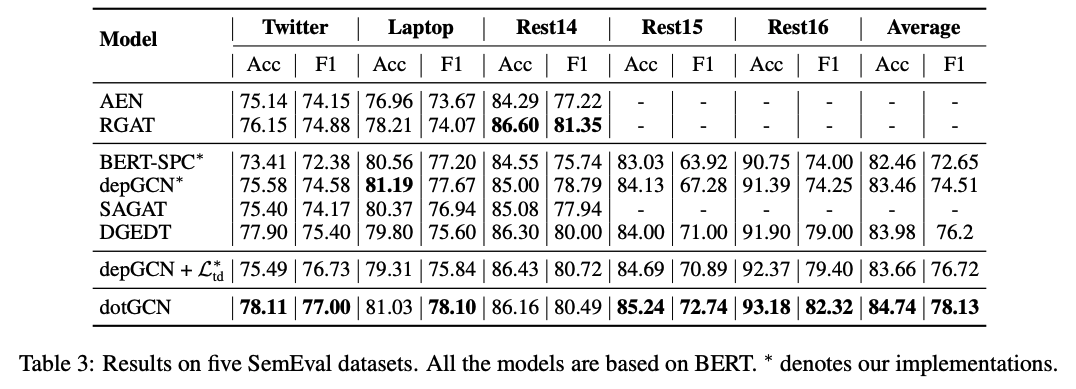
SemEval数据集上的效果
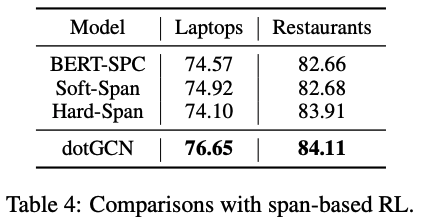
和span-based RL作对比
图3a和图3b分别显示了方面术语“scallops”的induced tree和dependency parse:
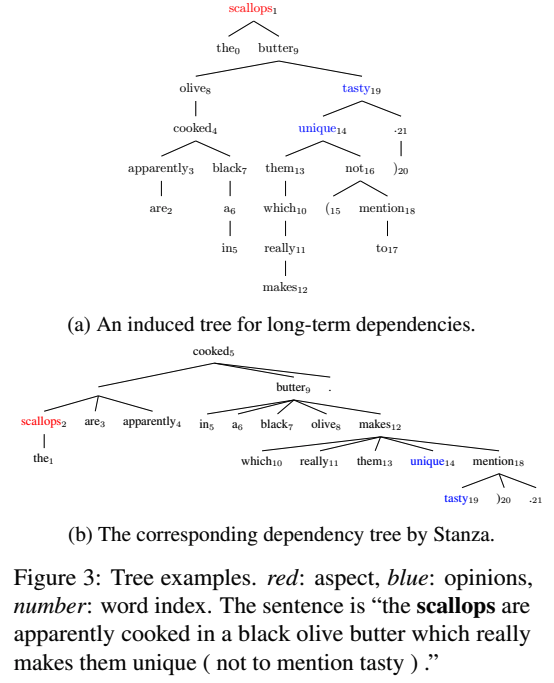
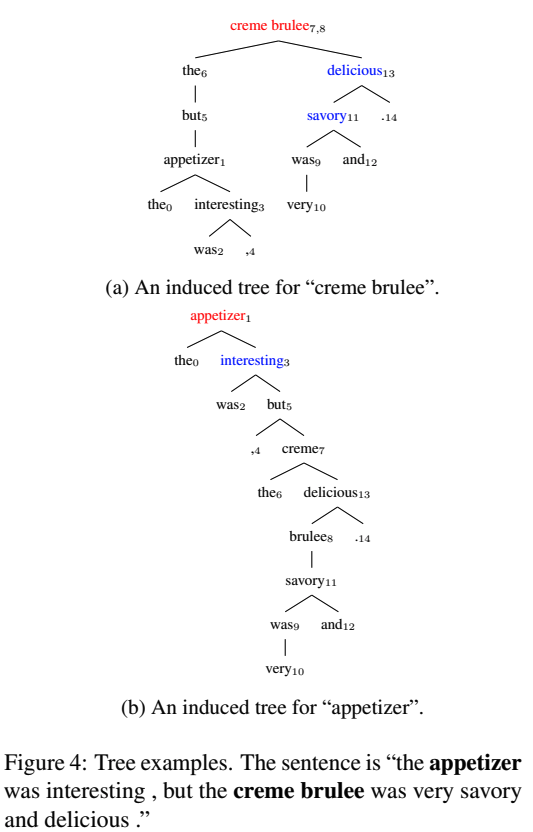
图4a和图4b显示了两个情绪极性不同的方面术语的induced tree:
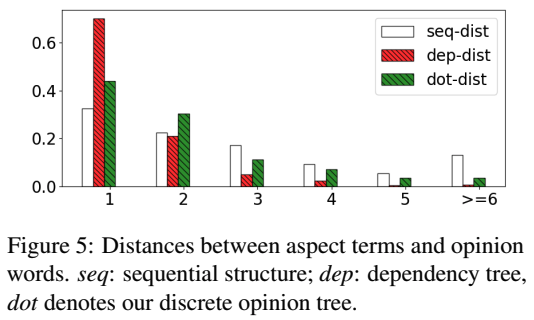
aspect 和 opinion word的距离分析:
基于MAMS的测试集分类精度与训练集中各方面频率的关系:

审核编辑:郭婷
- 相关推荐
- 热点推荐
- 编码器
-
自动化基础--线性离散系统的分析与校正2017-02-24 3379
-
面向对象软件自动生成在检测系统中的应用2009-09-21 574
-
基于分段哈希码的倒排索引树结构2017-11-28 1042
-
基于树结构的回溯异常检测算法2017-12-07 912
-
面向无指导情感分析的层次性生成模型2017-12-17 1151
-
一种细粒度的面向产品属性的用户情感模型2017-12-26 1001
-
主题种子词的情感分析方法2018-01-04 1445
-
NLP:面向方面级情感分类的注意力转移网络2021-02-10 3855
-
基于Aspect、Target等医疗领域情感分析的应用场景2021-05-08 4124
-
面向用户评论的方面级情感分析技术综述2021-05-29 954
-
面向意图性的篇章话题结构分析2021-06-07 606
-
自然语言处理之情感分析2022-05-21 6528
-
一种简单而有效的转换方法来降低预测情感标签的难度2022-09-20 1988
-
图模型在方面级情感分析任务中的应用2022-11-24 3263
-
时钟树是什么?介绍两种时钟树结构2023-12-06 3895
全部0条评论

快来发表一下你的评论吧 !
