

一篇文章讲清楚交叉熵和KL散度
描述
看了很多讲交叉熵的文章,感觉都是拾人牙慧,又不得要领。还是分享一下自己的理解,如果看完这篇文章你还不懂这俩概念就来掐死我吧。
1
『先翻译翻译,什么叫惊喜』
我们用 表示事件 发生的概率。这里我们先不讨论概率的内涵, 只需要遵循直觉: 可以衡量事件 发生时会造成的惊喜(行文需要,请按照中性理解)程度: 概率越低的事件发生所造成的惊喜程度高;概率越高的事件发生所造成的惊喜程度低。 但是概率倒数这一运算的性质不是很好,所以在不改变单调性的情况下,可以将惊喜度(surprisal)定义为:
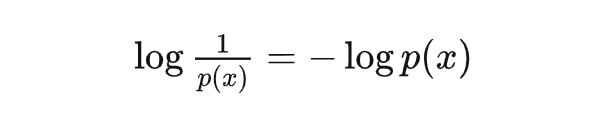
这样定义后产生了另外两个好处: 1. 确定性事件的惊喜度 = 0; 2. 如果有多个独立事件同时发生,他们产生的惊喜度可以直接相加。是的,一个事件发生概率的倒数再取对数就是惊喜。
2
『信息熵,不过只是惊喜的期望』
惊喜度,在大部分文章里,都叫做信息量,但这个命名只是香农根据他研究对象的需要而做的,对于很多其它的场景,要生搬硬套就会变得非常不好理解了。 信息量 = 惊喜度,那么信息熵呢?看看公式不言自明:
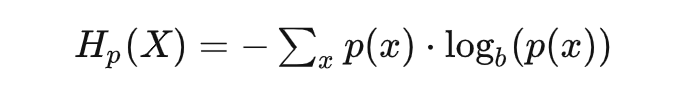
或是连续形式:
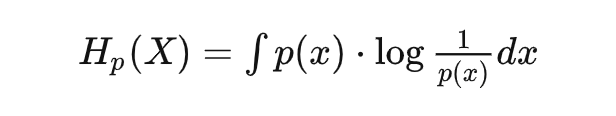
这不就是惊喜度的期望吗? 换句话说,信息熵描述的是整个事件空间会产生的平均惊喜。 什么情况下,平均惊喜最低呢?确定事件。以某个离散随机分布为例,整个分布在特定值 为 1,其它处均为 0,此时的信息熵/平均惊喜也为 0。 什么情况下产生的平均惊喜最高呢?自然是不确定越高平均惊喜越高。对于给定均值和方差的连续分布,正态分布(高斯分布)具有最大的信息熵(也就是平均惊喜)。所以再想想为什么大量生活中会看到的随机事件分布都服从正态分布呢?说明大自然有着创造最大惊喜的倾向,或者说,就是要让你猜不透。这也是理解热力学中的熵增定律的另一个角度。
3
『交叉熵,交叉的是古典和贝叶斯学派』
对于概率,比较经典的理解是看做是重复试验无限次后事件频率会逼近的值,是一个客观存在的值;但是贝叶斯学派提出了另一种理解方式:即将概率理解为我们主观上对事件发生的确信程度。针对同一个随机变量空间有两个分布,分别记作 和 ; 是我们主观认为 会发生的概率,下标 代表 subjective; 是客观上 会发生的概率,下标 ○ 代表 objective。 这种情况下,客观上这个随机事件 会给我们造成惊喜的期望应该是:
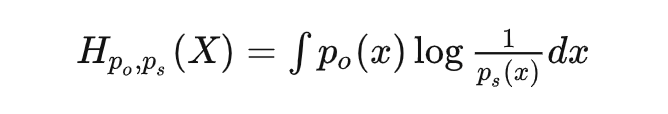
这个量 is a.k.a 交叉熵。 再翻译一下,交叉熵是什么?可以理解为:我们带着某个主观认知去接触某个客观随机现象的时候,会产生的平均惊喜度。 那什么时候交叉熵(也就是我们会获得的平均惊喜度)会大?就是当我们主观上认为一个事情发生的概率很低很大),但是客观上发生概率很高很大) 的时候,也就是主观认知和客观现实非常不匹配的时候。机器学习当中为啥用交叉熵来当作损失函数应该也就不言自明了。
4
『相对熵,K-L散度』
交叉熵可以衡量我们基于某种主观认识去感受客观世界时,会产生的平均惊喜。但是根据上面的分析,即使主观和客观完全匹配,这时交叉熵等于信息熵,只要事件仍然随机而非确定,就一定会给我们造成一定程度的惊喜。那我们要怎么度量主观认识和客观之间差异呢?可以用应该用以当前对“世界观”产生的惊喜期望和完全正确认识事件时产生的惊喜期望的差值来衡量,这个就是相对熵(常称作 KL-散度),通常写作:
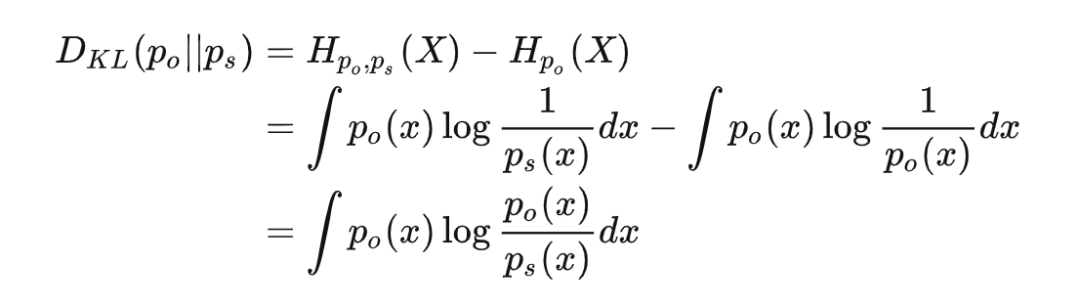
当我们的主观认知完全匹配客观现实的时候,KL-散度应该等于 0,其它任何时候都会大于 0。由于存在恒为正这一性质,KL-散度经常用于描述两个分布是否接近,也就是作为两个分布之间“距离”的度量;不过由于运算不满足交换律,所以又不能完全等同于“距离”来理解。 机器学习中通常用交叉熵作为损失函数的原因在与,客观分布并不随参数变化,所以即使是优化 KL-散度,对参数求导的时候也只有交叉熵的导数了。
审核编辑 :李倩
-
什么是交叉熵?2019-03-21 2315
-
交叉熵的作用原理2019-06-03 1555
-
基于KL散度和近邻点间距离的球面嵌入算法2017-12-05 1000
-
终于有人讲清楚了树莓派是什么2018-01-22 341487
-
KL散度在各领域不同的使用情况2018-05-14 27946
-
程序员怎样讲清楚技术方案2019-01-03 2358
-
一个简单例子讲清楚指针的应用2021-02-10 3029
-
酷狗耳机将“把话讲清楚”推到新高度 构建跨品牌营销闭环2021-05-07 2091
-
一文讲清楚 “电路反馈”2023-06-17 3261
-
一篇文章讲清楚HDMI 2.1的一切2024-11-28 16068
-
别再迷糊了!Linux交叉编译到底是个啥?一文讲清楚2025-12-03 1467
-
企业为什么开始换用 RFID智能硬盘柜?选型标准一次讲清楚2025-12-10 438
-
一篇讲清楚 Claude 的三种使用模式:Chat、Cowork、Code 到底有啥区别?2026-05-18 452
全部0条评论

快来发表一下你的评论吧 !
