

统计机器学习方法:基于HMM的中文词性标注
人工智能
描述
前言
最近在重刷李航老师的《统计机器学习方法》尝试将其与NLP结合,通过具体的NLP应用场景,强化对书中公式的理解,最终形成「统计机器学习方法 for NLP」的系列。这篇将介绍隐马尔可夫模型HMM(「绝对给你一次讲明白」)并基于HMM完成一个中文词性标注的任务。
HMM是什么
「隐马尔可夫模型(Hidden Markov Model, HMM)」 是做NLP的同学绕不过去的一个基础模型, 是一个生成式模型, 通过训练数据学习隐变量 和观测变量 的联合概率分布 。
HMM具有「两个基本假设」:
齐次马尔可夫性假设: 时刻的隐变量 只跟前一个时刻的隐变量 有关
观测独立性: 任意时刻的观测变量 只与该时刻的隐变量 有关。所以可以构成下面一个有向图, 从而 可以分解成图上边的概率乘积。
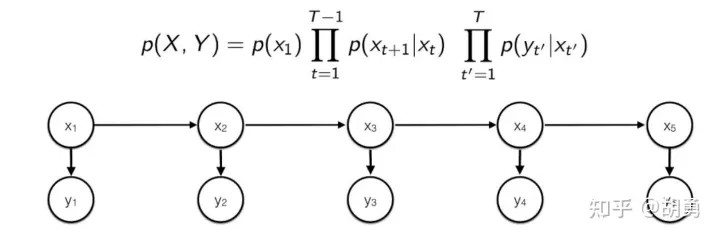
「训练阶段」:通过对训练数据进行极大似然估计, 得到HMM模型的参数:初始概率向量 (对应图中的 ),隐变量之间的转移概率矩阵 (对应图中的 ,隐变量到观测变量之前的转移概率矩阵 ((对应图中的 。
「预测阶段」: 给定观测变量 ,解出使 概率最大的隐变量。因为HMM是一个生成模型, 所以模型在预测阶段需要从全部可能的隐变量 中找到使得 最大的那个 。然而假设步长为 , 对于每一步 ,隐变量 可能的取值有 个, 那么全部可能的隐变量 个数为 , 这是一个指数级的时间复杂度,穷 举 肯 定 是 不 现 实 的 。 所 以 就 引 入 了 维 特 比 算 法(Viterbi algorithm)进行剪枝。
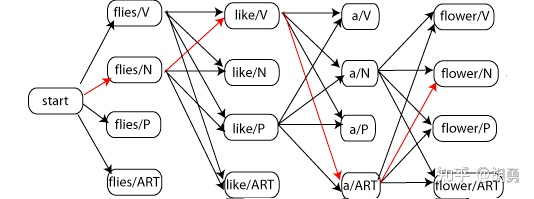
维特比算法的简单的说就是「提前终止了不可能路径」。具体而言, 在每一步遍历全部的 个节点,对于每一个节点继续遍历可能来源于上一步的 个节点, 只保留上一步 () 个节点中概率最大的路径, 裁剪其余的 条路径。所以时间复杂度降低到 , 相比指数级的暴力枚举, 这是可接受的。
值得注意的是现在在深度学习在解码阶段基本不用「维特比算法」解码而更多的是使用「beam search」解码。这是因为「维特比算法」需要一个很强的假设:当前节点只与上一个点有关, 这也正是齐次马尔可夫性假设, 所以路径整体概率才可以表示成各个子路径相乘的形式。但是深度学习时代的解码则不满足这个假设, 即, 而需要整体考虑, 所以beam search始终保留「整体最优」的个结果。
基于HMM的词性标注
词性标注是指给定一句话(已经完成了分词),给这个句子中的每个词标记上词性,例如名词,动词,形容词等。这是一项最基础的NLP任务,可以给很多高级的NLP任务例如信息抽取,语音识别等提供有用的先验信息。

这个任务中我们认为隐变量是词性(名词,动词等),观测变量是中文的词语,需要进行的建模。
下面将分为:「数据处理,模型训练,模型预测」 三个部分 来介绍如果利用HMM实现词性标注
数据处理
这里采用「1998人民日报词性标注语料库」进行模型的训练,包括44个基本词性以及19484个句子。具体可以参考这里:https://www.heywhale.com/mw/dataset/5ce7983cd10470002b334de3
PFR语料库是对人民日报1998年上半年的纯文本语料进行了词语切分和词性标注制作而成的,严格按照人民日报的日期、版序、文章顺序编排的。文章中的每个词语都带有词性标记。目前的标记集里有26个基本词类标记(名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习惯用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w)外,从语料库应用的角度,增加了专有名词(人名nr、地名ns、机构名称nt、其他专有名词nz);从语言学角度也增加了一些标记,总共使用了40多个个标记。
2. 模型训练
根据数据估计HMM的模型参数:全部的词性集合,全部的词集合,初始概率向量,词性到词性的转移矩阵 ,词性到词的转移矩阵。 这里直接采用频率估计概率的方法,但是对于会存在大量的0,所以需要进一步采用「拉普拉斯平滑处理」。
# 统计words和tags
words = set()
tags = set()
for words_with_tag in sentences:
for word_with_tag in words_with_tag:
word, tag = word_with_tag
words.add(word)
tags.add(tag)
words = list(words)
tags = list(tags)
# 统计 词性到词性转移矩阵A 词性到词转移矩阵B 初始向量pi
# 先初始化
A = {tag: {tag: 0 for tag in tags} for tag in tags}
B = {tag: {word: 0 for word in words} for tag in tags}
pi = {tag: 0 for tag in tags}
# 统计A,B
for words_with_tag in sentences:
head_word, head_tag = words_with_tag[0]
pi[head_tag] += 1
B[head_tag][head_word] += 1
for i in range(1, len(words_with_tag)):
A[words_with_tag[i-1][1]][words_with_tag[i][1]] += 1
B[words_with_tag[i][1]][words_with_tag[i][0]] += 1
# 拉普拉斯平滑处理并转换成概率
sum_pi_tag = sum(pi.values())
for tag in tags:
pi[tag] = (pi[tag] + 1) / (sum_pi_tag + len(tags))
sum_A_tag = sum(A[tag].values())
sum_B_tag = sum(B[tag].values())
for next_tag in tags:
A[tag][next_tag] = (A[tag][next_tag] + 1) / (sum_A_tag + len(tags))
for word in words:
B[tag][word] = (B[tag][word] + 1) / (sum_B_tag + len(words))
看一下词性转移矩阵
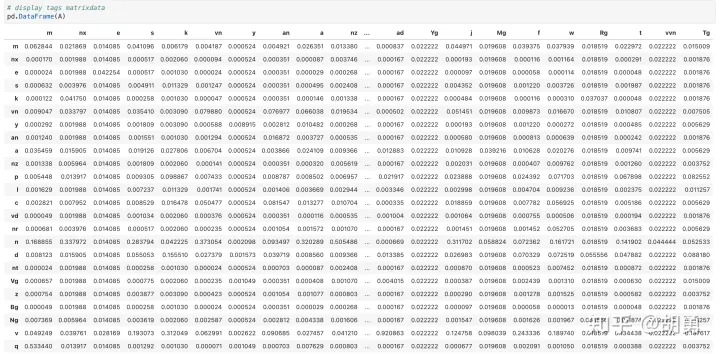
3. 模型预测
在预测阶段基于维特比算法进行解码
def decode_by_viterbi(sentence):
words = sentence.split()
sen_length = len(words)
T1 = [{tag: float('-inf') for tag in tags} for i in range(sen_length)]
T2 = [{tag: None for tag in tags} for i in range(sen_length)]
# 先进行第一步
for tag in tags:
T1[0][tag] = math.log(pi[tag]) + math.log(B[tag][words[0]])
# 继续后续解码
for i in range(1, sen_length):
for tag in tags:
for pre_tag in tags:
current_prob = T1[i-1][pre_tag] + math.log(A[pre_tag][tag]) + math.log(B[tag][words[i]])
if current_prob > T1[i][tag]:
T1[i][tag] = current_prob
T2[i][tag] = pre_tag
# 获取最后一步的解码结果
last_step_result = [(tag, prob) for tag, prob in T1[sen_length-1].items()]
last_step_result.sort(key=lambda x: -1*x[1])
last_step_tag = last_step_result[0][0]
# 向前解码
step = sen_length - 1
result = [last_step_tag]
while step > 0:
last_step_tag = T2[step][last_step_tag]
result.append(last_step_tag)
step -= 1
result.reverse()
return list(zip(words, result))
最后进行简单的测试
decode_by_viterbi('我 和 我 的 祖国')
[('我', 'r/代词'),
('和', 'c/连词'),
('我', 'r'/代词),
('的', 'u'/助词),
('祖国', 'n'/名词)]
decode_by_viterbi('中国 经济 迅速 发展 , 对 世界 经济 贡献 很 大')
[('中国', 'ns/地名'),
('经济', 'n/名词'),
('迅速', 'ad/形容词'),
('发展', 'v/动词'),
(',', 'w/其他'),
('对', 'p/介词'),
('世界', 'n/名词'),
('经济', 'n/名词'),
('贡献', 'n/名词'),
('很', 'd'/副词),
('大', 'a'/形容词)]
可以看到基本都是正确的,根据文献HMM一般中文词性标注的准确率能够达到85%以上 :)
当然「HMM的缺陷也很明显」,主要是两个强假设在实际中是不成立的。因为隐变量不仅仅跟前一个状态的隐变量有关(跟之前全部的隐藏变量和观测变量有关),同时当前观测变量也不仅仅跟当前的隐变量有关(跟之前全部的隐藏变量和观测变量有关),这也是后面深度学习中RNN等模型尝试解决的问题了。
编辑:黄飞
-
【卡酷机器人】——基础学习方法2015-01-09 8955
-
统计学习方法数据挖掘2019-10-29 1688
-
自然语言处理的词性标注方法2020-04-21 2279
-
Python NLTK学习方法2020-05-29 840
-
统计的学习方法2020-07-15 1820
-
基于无向图序列标注模型的中文分词词性标注一体化系统2010-03-06 858
-
深度解析机器学习三类学习方法2018-05-07 15264
-
《统计学习方法》李航详细电子教材免费下载2018-08-22 1485
-
机器学习入门宝典《统计学习方法》的介绍2018-11-25 5757
-
区块链数据集有怎样的机器学习方法2019-11-26 1380
-
深度学习:四种利用少量标注数据进行命名实体识别的方法2021-01-03 11746
-
188万中文词库包括了输入法和机器学习与训练2021-02-26 936
-
基于强化学习的壮语词标注方法2021-05-14 1058
-
联合学习在传统机器学习方法中的应用2023-07-05 1813
-
传统机器学习方法和应用指导2024-12-30 2561
全部0条评论

快来发表一下你的评论吧 !
