

详细介绍一些CNN模型的设计理论和关键设计点
描述

卷积神经网络设计史上的主要里程碑:模块化、多路径、因式分解、压缩、可扩展
一般来说,分类问题是计算机视觉模型的基础,它可以延申解决更复杂的视觉问题,例如:目标检测的任务包括检测边界框并对其中的对象进行分类。而分割的任务则是对图像中的每个像素进行分类。
卷积神经网络(CNNs)首次被用于解决图像分类问题,并且取得了很好的效果,所以在这个问题上,研究人员开始展开竞争。通过对ImageNet Challenge中更精确分类器的快速跟踪研究,他们解决了与大容量神经网络的统计学习相关的更普遍的问题,导致了深度学习的重大进展。
在本文中我们将整理一些经典的CNN模型,详细介绍这些模型的设计理论和关键设计点:
VGGNet
我们介绍的第一个CNN,命名是为VGGNet[2]。它是AlexNet[3]的直接继承者,AlexNet[3]被认为是第一个“深度”神经网络,这两个网络有一个共同的祖先,那就是Lecun的LeNet[4]。
我们从它开始,尽管它的年代久远,但是由于VGGNet的特殊性,,直到今天仍然站得住脚(这是极少数的DL模型能够做到的)。第一个介绍VGGNet还有一个原因是它还建立了后续cnn所采用的通用组件和结构。
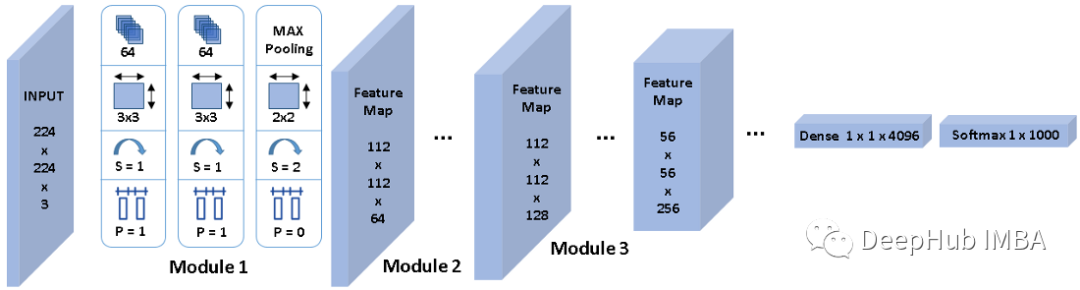
如上图1所示,卷积神经网络从一个输入层开始,它与输入图像具有相同的尺寸,224x224x3。
然后,VGGNet堆叠第一个卷积层(CL 1),其中包括64个大小为3x3的核,输出一个224x224x64的张量。
接下来,它在具有相同配置的64个通道上堆叠使用相同大小的3x3核的CL 2,生成相同尺寸的特征映射。
然后,使用filter size为2x2、填充和步幅为2的最大池化来降低特征映射的空间分辨率,从224x224x64降低到112x112x64。最大池并不影响特性映射深度,因此通道的数量仍然是64。
这里我将这三层之上称作module 1,一般情况下也被称作stem,可以理解为它提取的是最基本的线条特征。我们将其称为module 被是因为它定义为以一定分辨率操作的处理单元。所以我们可以说VGGNet的module 1以224x224分辨率工作,并生成分辨率为112x112的特征图,后面的module 2继续在其上工作。
类似地,module 2也有两个带有3x3核的CLs,用于提取更高级别的特征,其次是最大池化,将空间分辨率减半,但核的数量乘以2,使输出特征映射的通道数量翻倍。
每个module 处理输入特征映射,将通道加倍,将空间分辨率除以2,以此类推。但是不可能一直这样做,因为module 6的空间分辨率已经是7x7了。
因此,VGGNet包括一个从3D到1D的展平(flatten)操作,然后应用一个或两个稠密层,最后使用softmax计算分类概率(这里是1000个标签)。
让我们总结一下VGGNet引入的设计模式,以在准确性方面超越所有以前的研究:
模块化架构允许卷积层内的对称性和同质性。通过构建具有相似特征的卷积层块,并在模块之间执行下采样有助于在特征提取阶段保留有价值的信息,使用小核,两个 3x3 核的卷积的感知范围可以等效于单个 5x5 的感知范围。级联的小核卷积也增强了非线性,并且可以获得比具有一层更大核的更好的精度。小核还可加快 Nvidia GPU 上的计算速度。
与平均池化或跨步卷积(步幅大于 1)相比,最大池化操作是一种有效的下采样方法。最大池化允许捕获具有空间信息的数据中的不变性。因为图像分类任务需要这种空间信息减少才能达到类别分数的输出,而且它也被“流形假设”证明是合理的。在计算机视觉中,流形假设指出 224x224x3 维度空间中的真实图像表示非常有限的子空间。
将整体下采样与整个架构中通道数量的增加相结合形成金字塔形结构。通道的倍增补偿了由于学习到的特征图的空间分辨率不断降低而导致的表征表达能力的损失。在整个层中,特征空间会同步变窄和变深,直到它准备好被展平并作为输入向量发送到全连接层。每个特征都可以看作一个对象,其存在将在整个推理计算过程中被量化。早期的卷积层捕获基本形状,因此需要的对象更少。后面的层将这些形状组合起来,创建具有多种组合的更复杂的对象,所以需要大量的通道来保存它们。
Inception
接下来介绍与VGGNet[2]同年出现但晚一点的第二个CNN,Inception[5]。这个名字的灵感来自克里斯托弗诺兰的著名电影,这个网络引发了关于“寻求更深层次的 CNN”的争论,并很快变成了一个问题。事实上,深度学习研究人员意识到,如果能正确训练更深层次的神经网络,那么获得的准确性就越高,尤其是在涉及 ImageNet 等复杂分类任务时。简而言之,更多的堆叠层提高了神经网络的学习能力,使其能够捕捉复杂的模式并并能在复杂的数据中进行泛化。
但是设法训练更深的网络是非常困难的。堆叠更多层会产生成本,并使训练神经网络变得更加困难。这是由于梯度消失问题,当损失梯度通过无数计算层反向传播,并逐渐收敛到几乎为零的微小的值时,就会发生这种情况。因此训练网络的早期层(距离输入近的层)变得很复杂,这些层无法执行特征提取并将提取的信息传递给后续层。
在Inception中,研究人员在一个深度级别上模拟了几个层。这样既增强了神经网络的学习能力,又扩大了神经网络的参数空间,避免了梯度的消失。

上图 2 是这个多尺度处理层的内部视图结构。关注蓝色
审核编辑:刘清
-
PID设计理论2011-06-15 3062
-
【好资料系列】电路设计理论大全2017-09-23 20397
-
大家是怎么压榨CNN模型的2019-05-29 1434
-
一文详解CNN2023-08-18 1296
-
如何处理实际布线中的一些理论冲突的问题2009-03-20 816
-
高质量PCB设计理论2009-04-15 1314
-
满意PID控制设计理论与方法2016-04-01 1027
-
关于红外通信的一些问题知识点2016-05-05 1106
-
SNMP常用的一些OID详细例表说明2019-08-08 1834
-
变压器的设计理论资料免费下载2019-07-31 1533
-
DSP入门学习必看的一些知识点详细概述2019-11-01 1942
-
电脑的一些硬件问题讲解2020-10-20 1119
-
APT触摸布局的一些建议详细说明2020-10-27 1533
-
介绍一些基础的电力知识点2023-08-15 2852
-
cnn常用的几个模型有哪些2024-07-11 3291
全部0条评论

快来发表一下你的评论吧 !
