

IPMT:用于小样本语义分割的中间原型挖掘Transformer
描述
本文简要介绍发表在NeurIPS 2022上关于小样本语义分割的论文《Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation》。该论文针对现有研究中忽视查询和支持图像之间因类内多样性而带来的类别信息的差距,而强行将支持图片的类别信息迁移到查询图片中带来的分割效率低下的问题,引入了一个中间原型,用于从支持中挖掘确定性类别信息和从查询中挖掘自适应类别知识,并因此设计了一个中间原型挖掘Transformer。文章在每一层中实现将支持和查询特征中的类型信息到中间原型的传播,然后利用该中间原型来激活查询特征图。借助Transformer迭代的特性,使得中间原型和查询特征都可以逐步改进。相关代码已开源在:
https://github.com/LIUYUANWEI98/IPMT
一、研究背景
目前在计算机视觉取得的巨大进展在很大程度上依赖于大量带标注的数据,然而收集这些数据是一项耗时耗力的工作。为了解决这个问题,通过小样本学习来学习一个模型,并将该模型可以推广到只有少数标注图像的新类别。这种设置也更接近人类的学习习惯,即可以从稀缺标注的示例中学习知识并快速识别新类别。
本文专注于小样本学习在语义分割上的应用,即小样本语义分割。该任务旨在用一些带标注的支持样本来分割查询图像中的目标物体。然而,目前的研究方法都严重依赖从支持集中提取的类别信息。尽管支持样本能提供确定性的类别信息指导,但大家都忽略了查询和支持样本之间可能存在固有的类内多样性。
在图1中,展示了一些支持样本原型和查询图像原型的分布。从图中可以观察到,对于与查询图像相似的支持图像(在右侧标记为“相似支持图像”),它们的原型在特征空间中与查询原型接近,在这种情况下匹配网络可以很好地工作。然而,对于与查询相比在姿势和外观上具有较大差异的支持图像(在左侧标记为“多样化支持图像”),支持和查询原型之间的距离会很远。在这种情况下,如果将支持原型中的类别信息强行迁移到查询中,则不可避免地会引入较大的类别信息偏差。
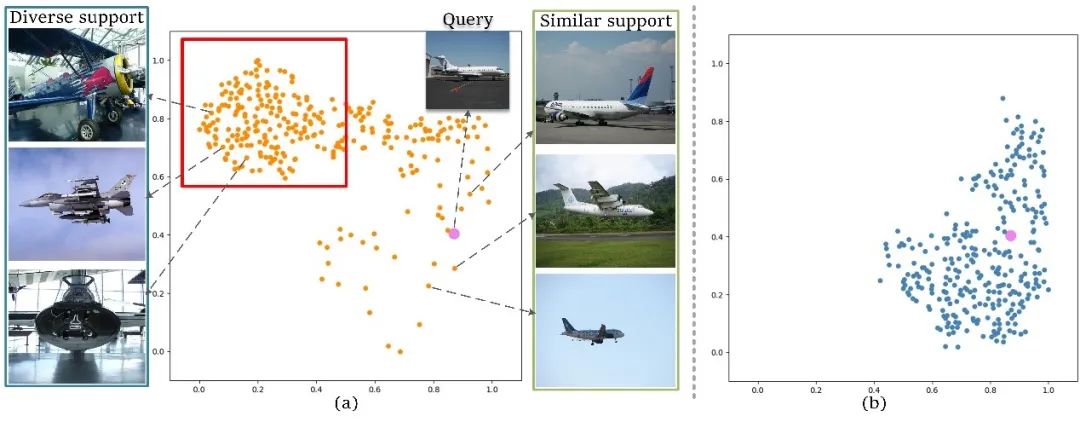
图1 支持样本原型与查询图像原型分布图
因此,本文在通过引入一个中间原型来缓解这个问题,该原型可以通过作者提出的中间原型挖掘Transformer弥补查询和支持图像之间的类别信息差距。每层Transformer由两个步骤组成,即中间原型挖掘和查询激活。在中间原型挖掘中,通过结合来自支持图像的确定性类别信息和来自查询图像的自适应类别知识来学习中间原型。然后,使用学习到的原型在查询特征激活模块中激活查询特征图。此外,中间原型挖掘Transformer以迭代方式使用,以逐步提高学习原型和激活查询功能的质量。
二、方法原理简述
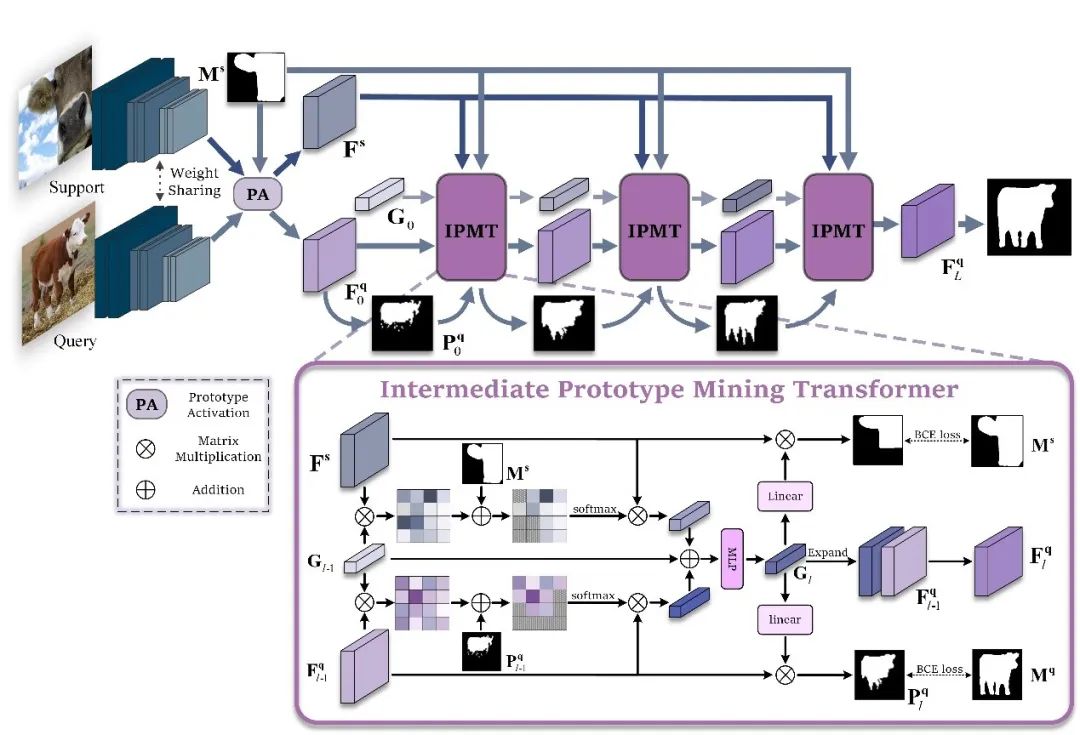
图2 方法总框图
支持图像和查询图像输入到主干网络分别提取除支持特征和查询特征。查询特征在原型激活(PA)模块中经过简单的利用支持图像原型进行激活后,分割成一个初始预测掩码,并将该掩码和激活后的查询特征作为中间原型挖掘Transformer层的一个输入。同时,将支持特征、支持图片掩码和随机初始化的一个中间原型也做为第一层中间原型挖掘Transformer的输入。在中间原型挖掘Transformer层中,首先进行掩码注意力操作。具体来说,计算中间原型与查询或支持特征之间的相似度矩阵,并利用下式仅保留前景区域的特征相似度矩阵:
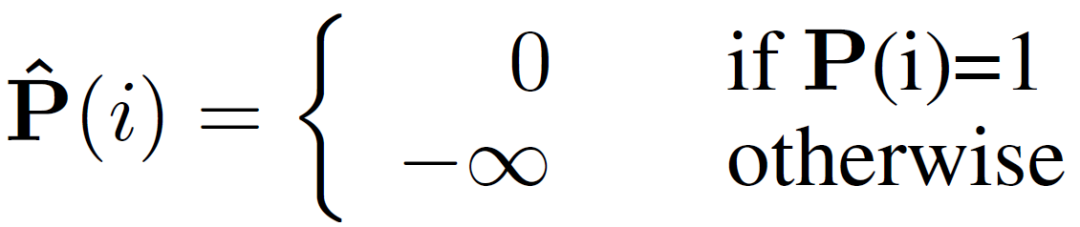
处理后的相似度矩阵作为权重,分别捕获查询或支持特征中的类别信息并形成新的原型。
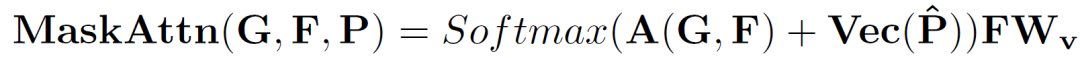
查询特征新原型、支持特征新原型和原中间原型结合在一起形成新的中间原型,完成对中间原型的挖掘。
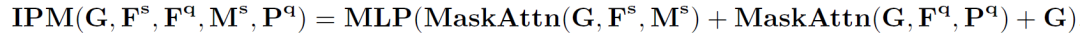
而后,新的中间原型在查询特征激活模块中对查询特征中的类别目标予以激活。
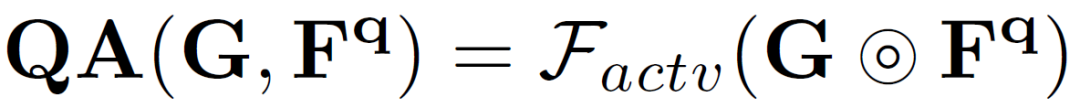
为了便于学习中间原型中的自适应类别信息,作者使用它在支持和查询图像上生成两个分割掩码,并计算两个分割损失。
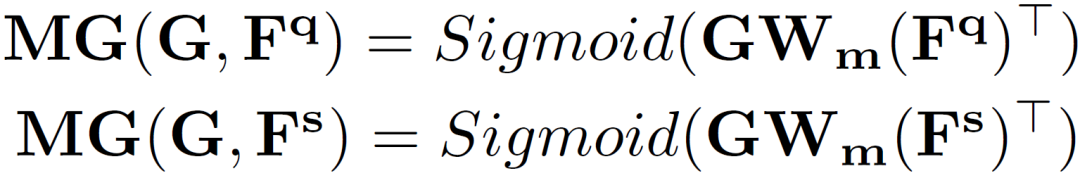
并设计双工分割损失(DSL):
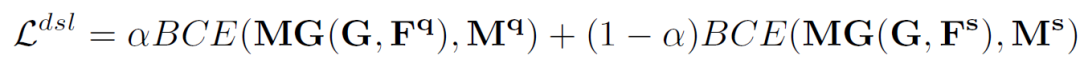
由于一个中间原型挖掘Transformer层可以更新中间原型、查询特征图和查询分割掩码,因此,作者通过迭代执行这个过程,得到越来越好的中间原型和查询特征,最终使分割结果得到有效提升。假设有L 层,那么对于每一层有:
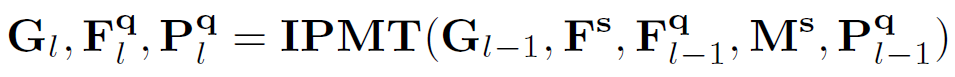
上式中具体过程又可以分解为以下环节:
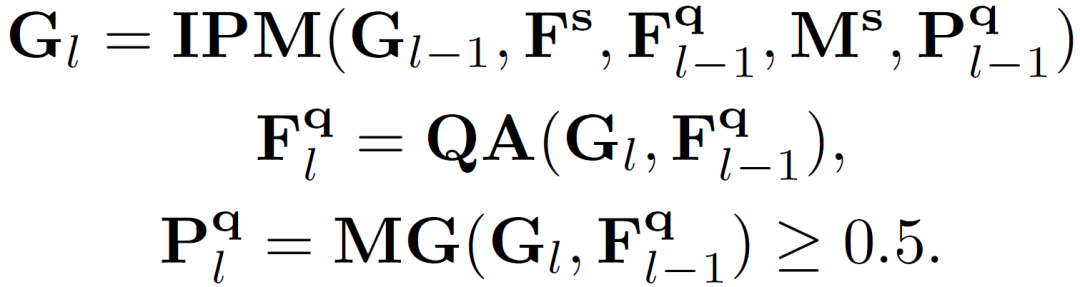
三、实验结果及可视化

图3 作者提出方法的结果的可视化与比较
在图3中,作者可视化了文章中方法和仅使用支持图像的小样本语义分割方法[1]的一些预测结果。可以看出,与第 2 行中仅使用支持信息的结果相比,第3行中的结果展现出作者的方法可以有效地缓解由固有的类内多样性引起的分割错误。
表4 与先前工作在PASCAL-5i[2]数据集上的效果比较
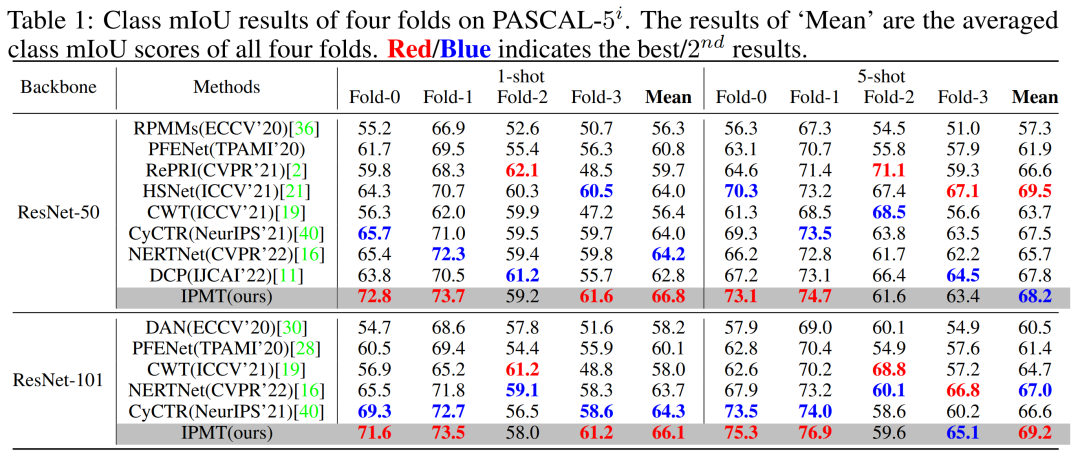
从表4中可以发现,作者的方法大大超过了所有其他方法,并取得了新的最先进的结果。在使用 ResNet-50 作为主干网络时, 在 1-shot 设置下与之前的最佳结果相比,作者将 mIoU 得分提高了 2.6。此外,在使用 ResNet-101作为主干网络时,作者方法实现了 1.8 mIoU(1-shot)和 2.2 mIoU(5-shot )的提升。
表5 各模块消融实验
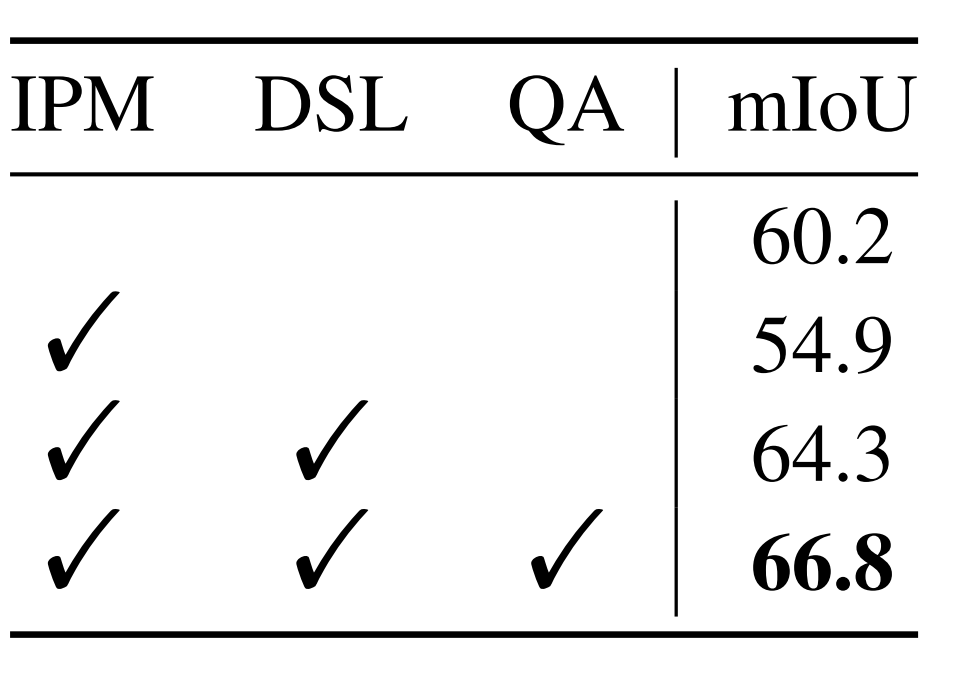
表5中指出,当仅使用 IPM 会导致 5.3 mIoU 的性能下降。然而,当添加 DSL 时,模型的性能在baseline上实现了 4.1 mIoU 的提升。作者认为这种现象是合理的,因为无法保证 IPM 中的可学习原型将在没有 DSL 的情况下学习中间类别知识。同时,使用 QA 激活查询特征图可以进一步将模型性能提高 2.5 mIoU。这些结果清楚地验证了作者提出的 QA 和 DSL 的有效性。
表6 中间原型Transformer有效性的消融研究
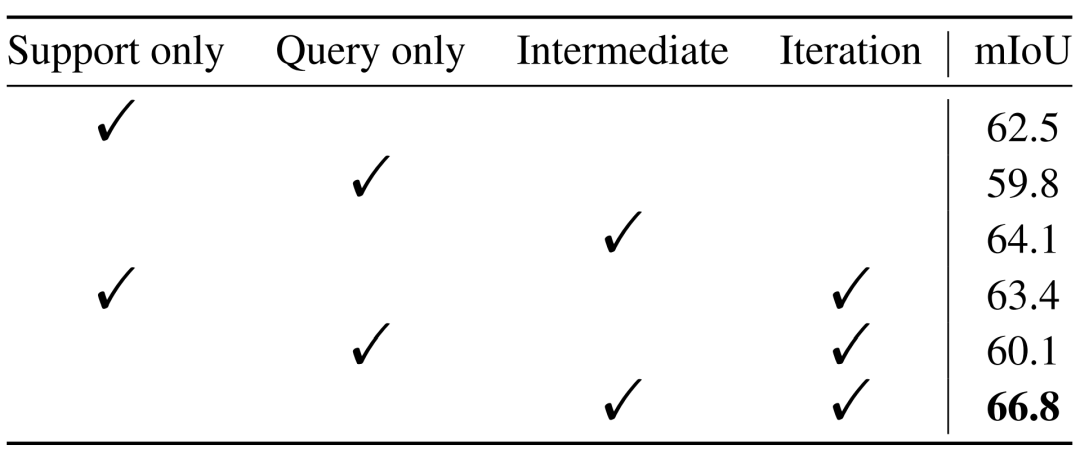
在表6中,作者对比了仅使用support或者query提供类别信息时,和是否使用迭代方式提取信息时的模型的性能情况。可以看出,借助中间原型以迭代的方式从support和query中都获取类型信息所取得的效果更为出色,也验证了作者提出方法的有效性。
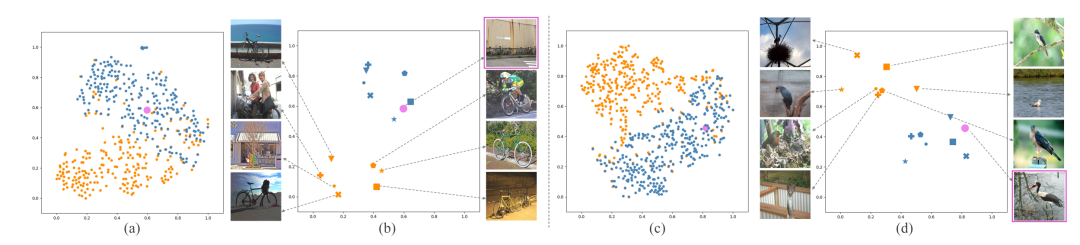
图7 支持原型和中间原型分别的可视化比较
如图7所示,作者将原本的支持原型可视化为橘色,学习到的中间原型可视化为蓝色,查询图像原型可视化为粉色。可以看到,在特征空间中,中间原型比支持原型更接近查询原型,因此验证了作者的方法有效地缓解了类内多样性问题并弥补了查询和支持图像之间的类别信息差距。
四、总结及结论
在文章中,作者关注到查询和支持之间的类内多样性,并引入中间原型来弥补它们之间的类别信息差距。核心思想是通过设计的中间原型挖掘Transformer并采取迭代的方式使用中间原型来聚合来自于支持图像的确定性类型信息和查询图像的自适应的类别信息。令人惊讶的是,尽管它很简单,但作者的方法在两个小样本语义分割基准数据集上大大优于以前的最新结果。为此,作者希望这项工作能够激发未来的研究能够更多地关注小样本语义分割的类内多样性问题。
审核编辑 :李倩
-
高维小样本分类问题中特征选择研究综述2017-11-27 932
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1036
-
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割2019-04-22 3774
-
语义分割算法系统介绍2020-11-05 8020
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1475
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 3278
-
一个具有泛化性的小样本语义分割(GFS-Seg)2022-09-13 3128
-
普通视觉Transformer(ViT)用于语义分割的能力2022-10-31 6640
-
跨域小样本语义分割新基准介绍2022-11-15 2744
-
语义分割数据集:从理论到实践2023-04-23 2004
-
PyTorch教程-14.9. 语义分割和数据集2023-06-05 1541
-
图像分割与语义分割中的CNN模型综述2024-07-09 3477
-
图像语义分割的实用性是什么2024-07-17 1722
全部0条评论

快来发表一下你的评论吧 !
