

聊聊eBPF的超能力
描述
什么是 eBPF
在开始之前,让我们先谈谈什么是 eBPF。该首字母缩写词代表可扩展伯克利包过滤器。我不认为这很有帮助。您真正需要知道的是,eBPF 允许您在内核中运行自定义代码。它使内核可编程。让我们稍作停顿,确保我们都在同一个页面上了解内核是什么。
内核是操作系统的核心部分,分为用户空间和内核。我们通常编写在用户空间中运行的应用程序。每当这些应用程序想要以任何方式与硬件交互时,无论是读取还是写入文件、发送或接收网络数据包、访问内存,所有这些都需要只有内核才能拥有的特权访问权限。用户空间应用程序必须在想要做任何这些事情时向内核发出请求。内核还负责诸如调度这些不同的应用程序之类的事情,以确保多个进程可以同时运行。
通常,我们只能编写在用户空间中运行的应用程序。eBPF 允许我们编写在内核中运行的内核。我们将 eBPF 程序加载到内核中,并将其附加到一个事件中。每当该事件发生时,它将触发 eBPF 程序运行。事件可以是各种不同的事物。这可能是网络数据包的到来。它可能是在内核或用户空间中进行的函数调用。它可能是一个跟踪点。我们可以在很多不同的地方附加 eBPF 程序,这看起来是一个完美的事件。
一个eBPF示例
为了更具体一点,我将在这里展示一个示例。这将是 eBPF 的 Hello World。这是我的 eBPF 程序。实际的 eBPF 程序就是这里的这几行代码。它们是用 C 编写的,我的程序的其余部分是用 Python 编写的。我的 Python 代码实际上将我的 C 程序编译成 BPF 格式。我所有的 eBPF 程序要做的就是在这里写一些跟踪,它会输出 QCon。我将把它附加到执行系统调用的事件中。
Execve 用于运行新的可执行文件。每当一个新的可执行文件运行时,execve 就是它运行的原因。每次在我的虚拟机上启动一个新的可执行文件时,都会导致我的跟踪被打印出来。
如果我运行这个程序,首先,我们应该看到我们不允许加载 BPF,除非我们有一个特权调用 CAP BPF,它通常只保留给 root。我们需要超级用户权限才能运行。让我们用 sudo 试试。我们开始看到很多这些跟踪事件被写出。我正在使用云虚拟机,使用 VS Code 远程访问它。事实证明正在运行相当多的可执行文件。
在不同的 shell 中,让我们运行一些东西,让我们运行 ps。我们可以看到进程 ID 1063059。这是我运行该 ps 可执行文件触发的跟踪行。我们可以在跟踪输出中看到,我们不仅获得了文本,还获得了一些有关触发该程序运行的事件的上下文信息。我认为这是 eBPF 提供给我们的重要部分。

eBPF代码必须是安全的
当我们将 eBPF 程序加载到内核中时,它的安全运行至关重要。如果它崩溃,那将导致整台机器瘫痪。为了确保它是安全的,有一个称为验证的过程。当我们将程序加载到内核中时,eBPF 验证器会检查程序是否将运行完成。它永远不会取消引用空指针。它将执行的所有内存访问都是安全且正确的。
这确保了我们正在运行的 eBPF 程序不会让我们的机器宕机,并且它们可以正确地访问内存。由于这个验证过程,有时 eBPF 被描述为一个沙箱。例如,我确实想明确一点,这是一种与容器化不同的沙盒。
动态改变内核行为
eBPF 允许我们在内核中运行自定义程序。这是我们改变内核的行为方式。这是一个真正的游戏规则改变者。过去,如果要更改 Linux 内核,需要很长时间。它需要内核编程方面的专业知识。如果您对内核进行更改,通常需要几年时间才能从内核进入我们在生产中使用的不同 Linux 发行版。内核中的新功能到达您的生产部署通常需要五年时间。这就是为什么 eBPF 突然成为如此流行的技术的原因。
大约在去年左右,几乎所有生产环境都在运行 Linux 内核,这些内核足够新,可以在其中包含 eBPF 功能。这意味着几乎每个人现在都可以利用 eBPF 并且“ 这就是为什么你突然看到这么多工具在使用它。当然,使用 eBPF,我们不必等待 Linux 内核推出。如果我们可以在 eBPF 程序中创建新的内核功能,我们可以将其加载到机器中。我们不必重新启动机器。我们可以动态地改变机器的行为方式。我们甚至不必停止并重新启动正在运行的应用程序,这些更改会立即影响内核。
动态漏洞修补
我们可以将其用于多种不同的目的,其中之一是动态修补漏洞。我们可以使用 eBPF 让自己对漏洞利用更具弹性。我喜欢这种动态漏洞修补的一个例子是对死亡数据包的弹性。死亡数据包是利用内核漏洞的数据包。随着时间的推移,其中一些内核无法正确处理数据包。
例如,如果您将一个不正确的长度字段放入该网络数据包中,则隧道可能无法正确处理它,并且可能会崩溃或发生坏事。这很容易通过 eBPF 缓解,因为我们可以将 eBPF 程序附加到网络数据包到达的事件上。我们可以看一下包,看看它是否以利用此漏洞的方式形成,即有问题的数据包。难道是死亡之包?如果是,我们可以丢弃该数据包。
eBPF丢包
作为一个简单的例子,我将展示另一个程序示例,该程序将丢弃特定形式的网络数据包。在此示例中,我将查找 ping 数据包。这就是 ICMP 协议。我可以放下它们。这是我的程序。这里的细节不用太担心,我基本上只是在看网络数据包的结构。我确定我找到了一个 ping 数据包。现在,我只允许他们继续。XDP_PASS 意味着继续做你对这个数据包所做的任何事情。这应该发出你得到的任何追踪。这实际上是一个名为 pingbox 的容器。
我将开始向该地址发送 ping,并且他们正在得到响应。我们可以看到这里的序列号很好。眼下,我的 eBPF 程序没有加载。我将运行一个 makefile 来编译我的程序,清理之前连接到这个网络接口的所有程序,然后加载我的程序。有make运行编译,然后在这里附加到网络接口eth0。您立即看到它开始追踪,得到 ICMP 数据包。这并没有影响行为,我的序列号仍然像以前一样滴答作响。
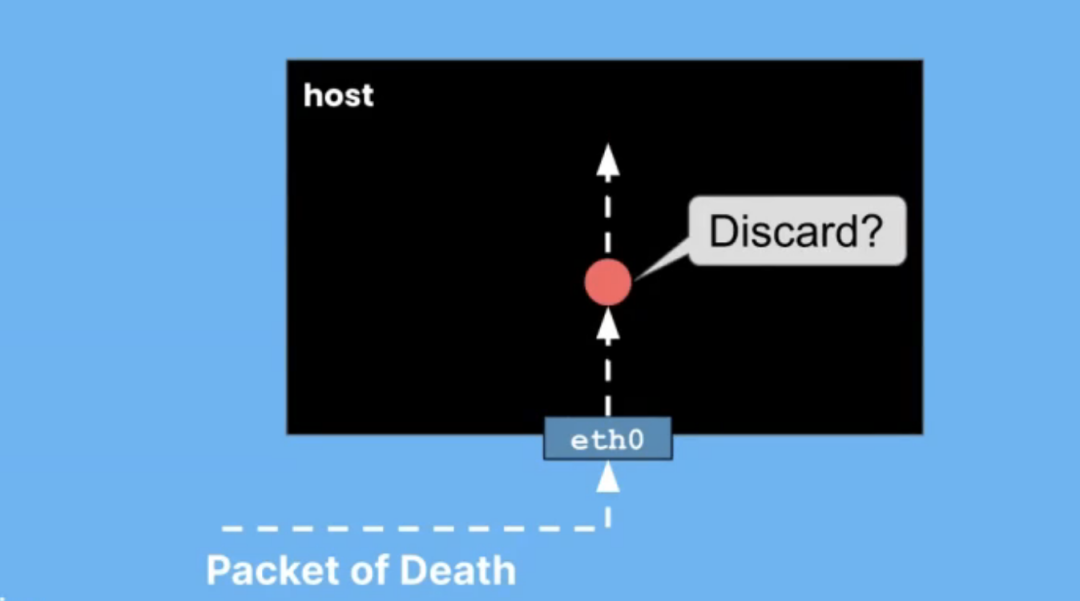
让我们把它改成,丢弃。我们应该看到的是这里的跟踪仍在生成中。它继续接收那些 ping 数据包。这些数据包正在被丢弃,因此它们永远不会得到响应。在这边,序列号已经停止上升,因为我们没有收到回复。让我们把它改回PASS,然后再做一次。
我们应该看到,有我的序列号,有 40 个左右的数据包丢失了,但现在它又可以工作了。我首先想说明的是,如何连接到网络接口并处理网络数据包。此外,我们可以动态地改变这种行为。我们不必停下来开始 ping。我们不必停下来开始任何事情。我们所做的只是改变内核的行为。我正在说明这一点,以说明如何处理死亡场景包。
抵御漏洞利用
使用 BPF Linux 安全模块,我们可以对许多其他不同的漏洞利用具有弹性。您可能遇到过 Linux 安全模块,例如 AppArmor 或 SELinux。内核中有一个 Linux 安全模块 API,它为我们提供了许多不同的事件,例如 AppArmor 可以查看并确定该事件是否符合策略,并允许或禁止该特定行为继续进行。例如,允许或禁止文件访问。
我们可以编写附加到同一个 LSM API 的 BPF 程序。这给了我们更多的灵活性,更多的动态安全策略。例如,有一个名为 Tracee 的应用程序,它是由我在 Aqua 的前同事编写的,它将附加到 LSM 事件并决定它们是否符合策略。
故障恢复能力 - 负载均衡
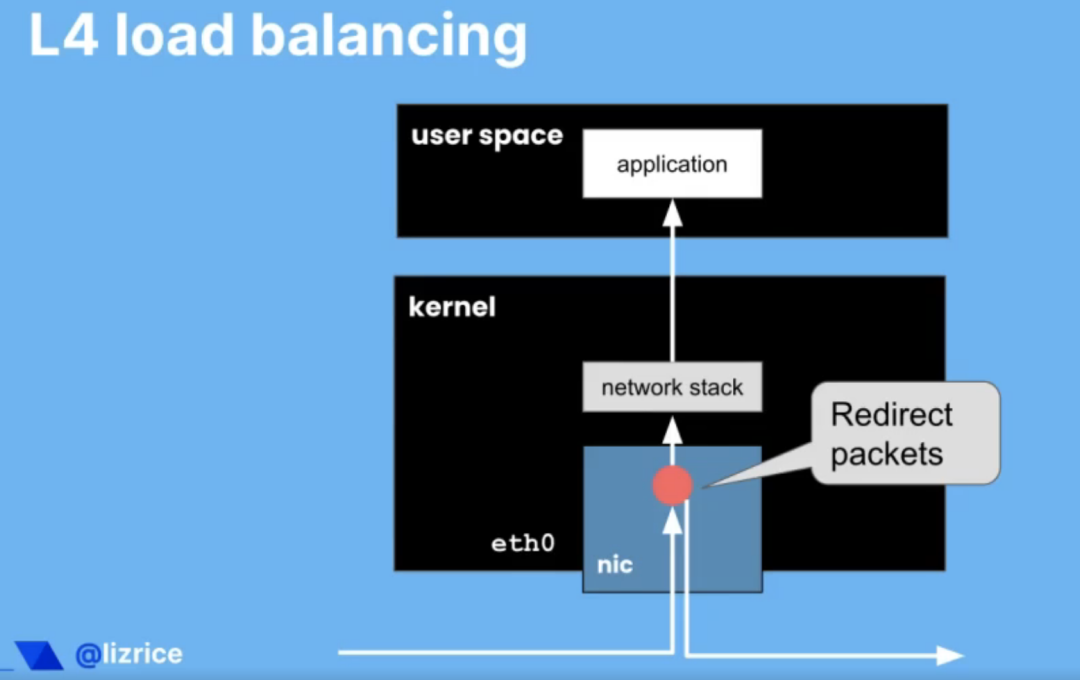
我们可也可以通过 eBPF 实现哪些其他类型的弹性?另一个例子是负载均衡。负载均衡可用于跨多个不同后端实例扩展请求。我们经常这样做不仅是为了扩展,而且是为了实现故障恢复和高可用性。我们可能有多个实例,因此如果其中一个实例以某种方式失败,我们仍然有足够的其他实例来继续处理该流量。
在前面的示例中,我向您展示了一个连接到网络接口的 eBPF 程序,或者更确切地说,它连接到称为网络接口的 eXpress 数据路径的东西。在我看来,eXpress 数据路径非常酷。您可能有 也可能没有允许您实际运行 XDP 程序的网卡,所以在网络接口卡的硬件上运行 eBPF 程序。XDP 尽可能接近网络数据包的物理到达运行。如果你的网卡支持,可以直接在网卡上运行。在这种情况下,内核的网络堆栈甚至永远不会看到该数据包。它的处理速度非常快。
如果网卡不支持它,内核可以再次运行您的 eBPF 程序,在收到该网络数据包后尽可能早地运行。仍然超快,因为数据包不需要遍历网络堆栈,肯定永远不会被复制到用户空间内存中。
我们可以使用 XDP 非常快速地处理我们的数据包。我们可以做出决定,比如我们是否应该重定向那个数据包。我们可以非常快地在内核中进行第 3 层、第 4 层负载平衡,甚至可能在内核中,也可能在网卡上决定我们是否应该将此数据包向上传递到网络堆栈并传递给用户这台机器上的空间。也许我们应该将负载均衡到完全不同的物理机器上。我们可以重定向数据包。我们可以非常快地做到这一点。所以可以将其用于负载平衡。
Kube proxy代理
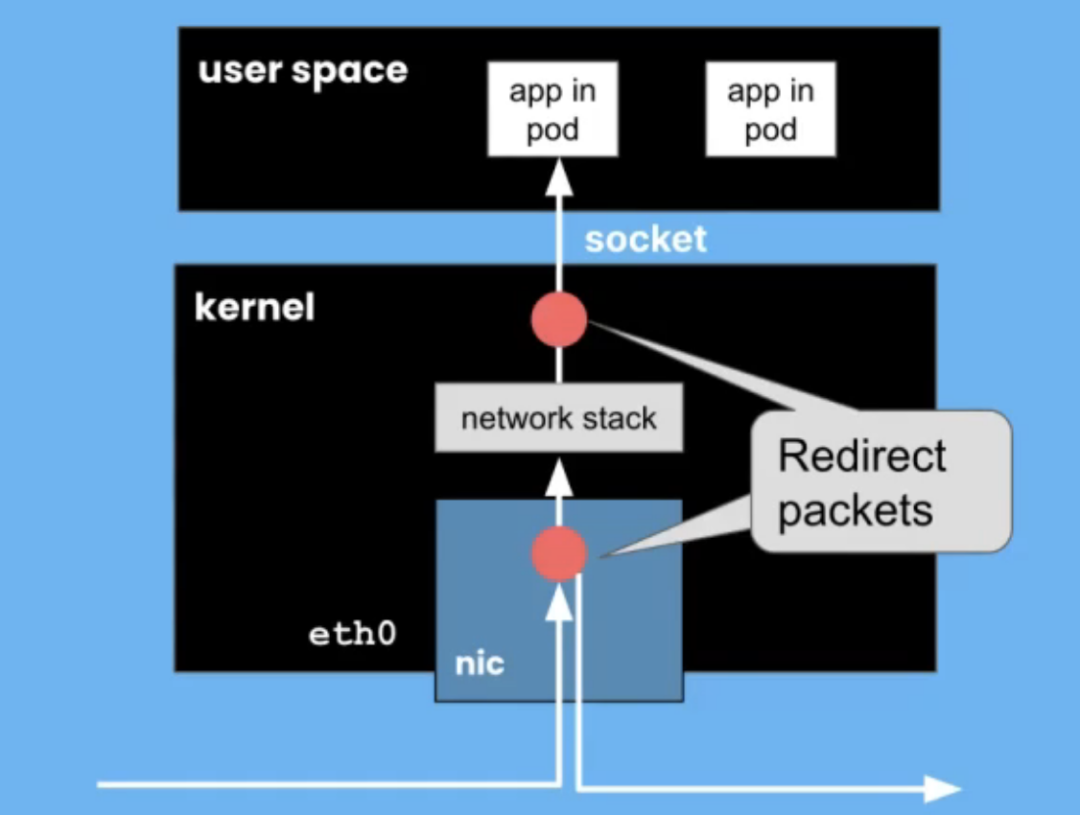
让我们简单地把我们的想法转向 Kubernetes。在 Kubernetes 中,我们有一个称为 kube-proxy 的负载均衡器。kube-proxy 允许负载均衡或告诉 pod 流量如何到达其他 pod。来自一个 pod 的消息如何到达另一个 pod?它充当代理服务。如果本质上不是负载均衡器,什么是代理?使用 eBPF,我们不仅可以选择附加到尽可能靠近物理接口的 XDP 接口。我们也有机会附加到套接字接口上,以便尽可能靠近应用程序。
应用程序通过套接字接口与网络通信。我们可以附加到来自 pod 的消息,并且可能绕过网络堆栈,因为我们想将它发送到不同机器上的 pod,或者我们可以绕过网络堆栈并直接循环回到在同一物理机或同一虚拟机上运行的应用程序。通过尽早拦截数据包,我们可以做出这些决策。我们可以避免遍历整个内核的网络堆栈,它给我们带来了一些令人难以置信的性能改进。与基于 iptables 的 Kube-proxy 相比,Kube-proxy 的替换性能可以显着提高。
高效支持K8S的感知网络
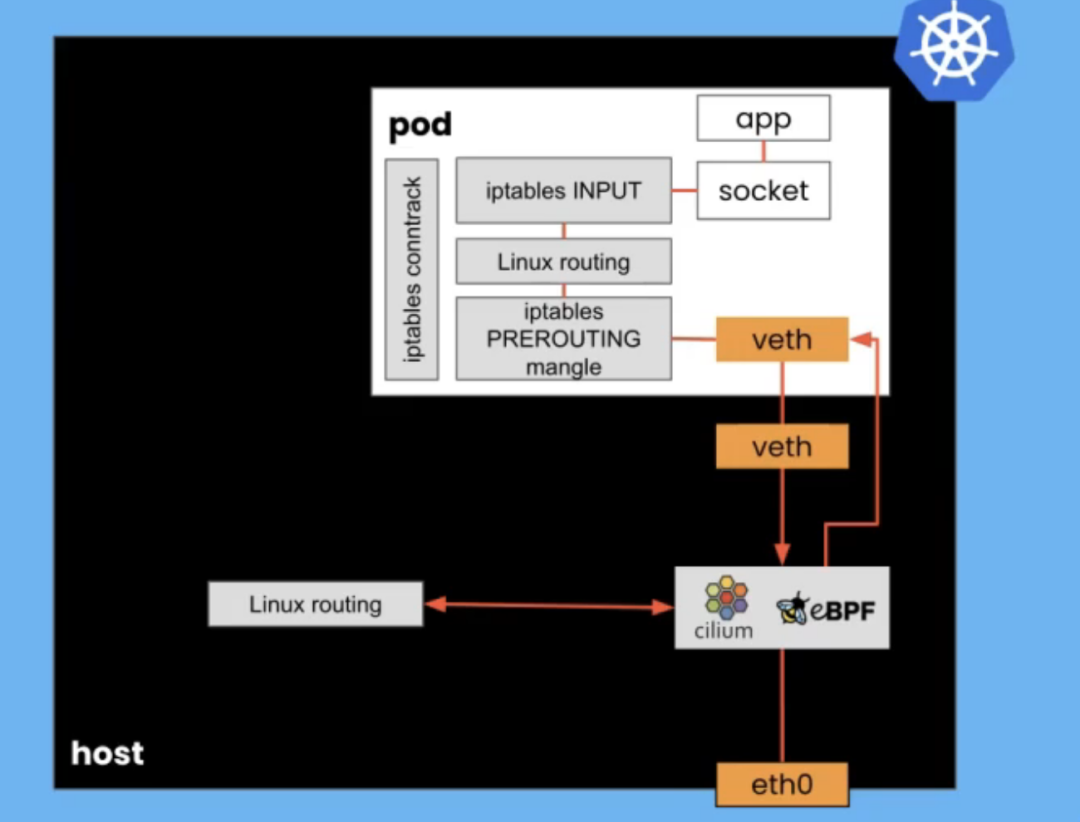
我现在想更深入地探讨一下为什么 eBPF 可以启用这种真正高效的网络,尤其是在 Kubernetes 中。通常,网络堆栈非常复杂。通过内核网络堆栈的数据包会经历一大堆不同的步骤和阶段,因为内核决定如何处理它。在 Kubernetes 中,我们不仅在主机上拥有网络堆栈,而且我们通常为每个 pod 运行一个网络命名空间。通过拥有自己的网络命名空间,每个 pod 都必须运行自己的网络堆栈。
想象一个到达物理 eth0 接口的数据包。它遍历整个内核的网络堆栈,以到达它注定要去的 pod 的虚拟以太网连接。然后它穿过 POD 网络堆栈通过套接字访问应用程序。如果我们使用 eBPF,特别是如果我们知道 Kubernetes 身份和地址,我们可以绕过主机上的那个堆栈。
当我们在那个 eth0 接口上接收到一个数据包时,如果我们已经知道该 IP 地址是否与特定的 pod 相关联,我们基本上可以进行查找并将该数据包直接传递给 pod,然后通过 pod 的网络堆栈,但不必经历主机网络堆栈上发生的所有复杂性。
使用像 Cilium 这样为 Kubernetes 启用 eBPF 的网络接口,我们可以启用此网络堆栈快捷方式,因为我们知道 Kubernetes 身份。我们知道哪些 IP 地址与哪些 pod 相关联,也知道哪些 pod 与哪些服务相关联,以及命名空间。有了这些知识,我们就可以构建这些服务地图,显示集群内不同组件之间的流量是如何流动的。eBPF 让我们可以看到数据包。我们可以看到,不仅仅是目标 IP 地址和端口,我们还可以通过代理路由来找出它是什么 HTTP 请求类型。我们可以将该数据流与 Kubernetes 身份相关联。
在 Kubernetes 网络中,IP 地址一直在变化,Pod 来来去去。IP 地址一分钟可能意味着一件事,两分钟后,它意味着完全不同的事情。IP 地址对于理解 Kubernetes 集群中的流量并没有太大帮助。Cilium 可以将这些 IP 地址映射到正确的 pod、任何给定时间点的正确服务,并为您提供更多可读信息。它明显更快。无论您是使用 Cilium 还是其他 eBPF 网络实现,在主机上获取网络堆栈的能力都为我们带来了可衡量的性能改进。
我们可以在这里看到,左边的蓝线是每秒请求数的请求-响应率,我们可以在没有任何容器的情况下实现,只是直接在节点之间发送和接收流量。我们可以获得几乎与使用 eBPF 一样快的性能。中间的黄色和绿色下方的条向我们展示了如果我们不使用 eBPF 会发生什么,并且我们使用通过主机网络堆栈的传统主机路由方法,它明显变慢了。
eBPF网络决策
我们还可以利用 Kubernetes 身份和丢弃数据包的能力来构建非常有效的网络策略实施。你看到丢包是多么容易。与其只是检查数据包并确定它是 ping 数据包,不如将数据包与策略规则进行比较并决定是否应该转发它们。这是我们拥有的非常好的工具。
你可以在 networkpolicy.io 上找到它来可视化 Kubernetes 网络策略。我们讨论了负载均衡,以及如何在 Kubernetes 集群中以 kube-proxy 的形式使用负载均衡。毕竟,Kubernetes 为我们提供了巨大的弹性。如果pod中的应用程序崩溃,它可以在没有任何操作员干预的情况下动态重新创建。我们可以自动扩展而无需操作员干预。
故障恢复能力 ClusterMesh
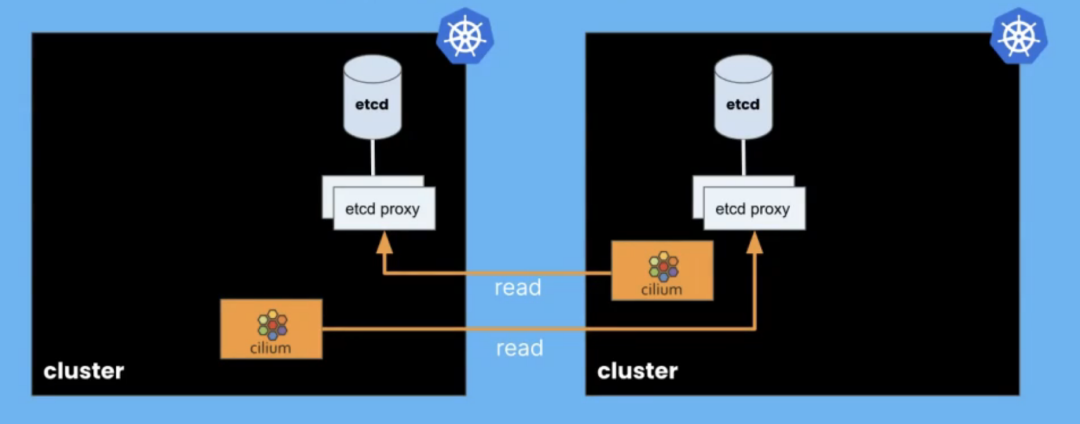
如果您的集群在特定数据中心运行并且您失去与该数据中心的连接,那么集群作为一个整体的弹性会怎样?通常,我们可以使用多个集群。我想展示 eBPF 如何使多个集群之间的连接变得非常简单。在 Cilium 中,我们使用一个称为 ClusterMesh 的功能来做到这一点。使用 ClusterMesh,我们有两个 Kubernetes 集群。
每个集群中运行的 Cilium 代理会读取一定量的关于该 ClusterMesh 中其他集群状态的信息。每个集群都有自己的配置和状态数据库存储在 etcd 中。我们运行一些 etcd 代理组件,使我们能够找出我们需要的多集群特定信息,以便所有集群上的 Cilium 代理可以共享该多集群状态。
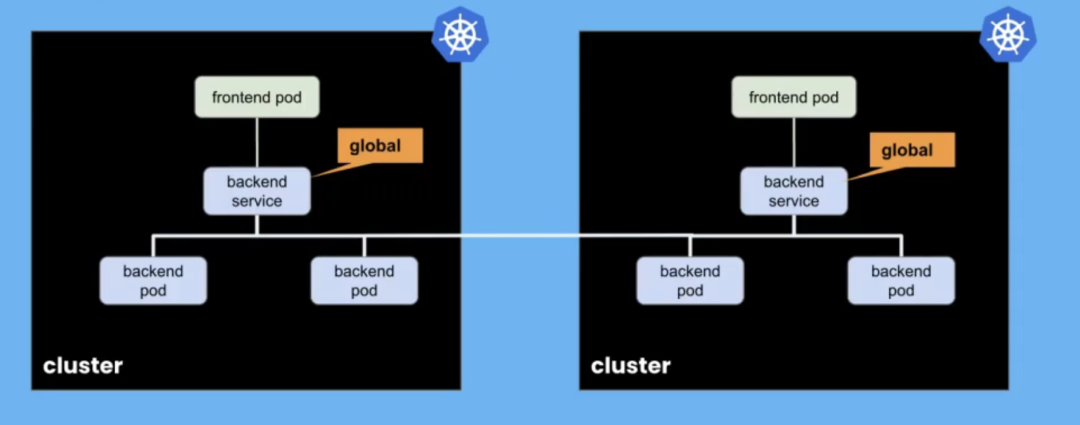
多集群状态是什么意思?通常,这将是关于创建高度可用的服务。我们可能会在多个集群上运行一个服务的多个实例,以使它们具有高可用性。使用 ClusterMesh,我们只需将服务标记为全局,并将它们连接在一起,以便访问该全局服务的 pod 可以在其自己的集群上访问它,或者在需要时在不同的集群上访问它。
我认为这是 Cilium 的一个非常好的功能,并且非常容易设置。如果一个集群上的后端 pod 因某种原因被破坏,或者整个集群出现故障,我们仍然可以将来自该集群上其他 pod 的请求路由到另一个集群上的后端 pod。它们可以被视为一项分布式集群服务。
我想我有一个例子。我有两个集群。我的第一个集群启动了,我们可以看到 cm-1(代表 ClusterMesh 1)和第二个集群 cm-2。他们都在运行一些 pod。我们经常在 Cilium 做一些星球大战主题的演示。在这种情况下,我们有一些希望能够与 Rebel 基地通信的X-wings战斗机。我们在第二个集群上也有一些类似的 X-wings 和 Rebel 基地。
让我们看一下服务。实际上,我们来描述一下 Rebel base,service rebel-base。你可以看到它被 Cilium 注释为一项全球服务。作为配置的一部分,我已对其进行了注释,说我希望这是一项全球服务。如果我查看那里的第二个集群,情况也是如此。它们都被描述为全球性的。这意味着,我可以从任一集群上的 X-wing 发出请求,它会收到来自这两个不同集群、这两个不同集群后端的负载平衡的响应。
让我们试试看。让我们循环运行它。让我们执行 X-wings。不过哪个 X-wings并不重要。我们想向 Rebel 基地发送消息。希望我们应该看到的是,我们有时会从集群 1 中随机获得响应,有时是集群 2。
如果其中一个集群上的 Rebel 基地 pod 发生了不好的事情怎么办?让我们看看代码上有哪些节点。让我们删除集群 2 上的 Pod。实际上,我将删除 Rebel 基于第二个集群的整个部署。我们应该看到的是,所有请求现在都由集群 1 处理。确实,您可以看到,集群 1 已经有一段时间了。我们实际上只需将我们的服务标记为全球性的弹性,它是实现多集群高可用性的一种非常强大的方式。
故障的可见性
以免我给你留下 eBPF 只是关于网络的印象,以及网络的优势,让我也谈谈我们如何使用 eBPF 来实现可观察性。毕竟,如果确实出现问题,这非常重要。我们需要可观察性,以便我们了解发生了什么。在 Kubernetes 集群中,我们有许多主机,而每台主机只有一个内核。
无论我们运行多少用户空间应用程序,无论我们运行多少容器,它们都在每台主机共享一个内核。如果它们在POD中,无论POD有多少,仍然只有一个内核。每当 pod 中的应用程序想要做任何有趣的事情时,比如读取或写入文件,或者发送或接收网络流量,每当 Kubernetes 想要创建一个容器时。任何复杂的事情都涉及内核。
内核对整个主机上发生的所有有趣的事情都有可见性。这意味着如果我们使用 eBPF 程序来检测内核,我们可以了解整个主机上发生的一切。因为我们几乎可以检测内核中发生的任何事情,我们可以将它用于各种不同的指标和可观察性工具、不同类型的跟踪,它们都可以使用 eBPF 构建。
例如,这是一个名为 Pixie 的工具,它是一个 CNCF 沙盒项目。它为我们提供了这个火焰图,关于整个集群中运行的信息。它聚合来自集群中每个节点上运行的 eBPF 程序的信息,以生成整个集群如何使用 CPU 时间的概览,并详细介绍这些应用程序正在调用的特定函数。
真正有趣的是,您无需对应用程序进行任何更改,甚至无需更改配置即可获得此工具。因为正如我们所看到的,当您对内核进行更改时,它会立即影响在该内核上运行的任何内容。我们不必重新启动这些进程或任何东西。
这对于我们所说的边车模型也有一个有趣的含义。在很多方面,与 sidecar 模型相比,eBPF 为我们提供了更多的简单性。在 sidecar 模型中,我们必须将一个容器注入到我们想要检测的每个 pod 中。它必须在 pod 内,因为这是一个用户空间应用程序可以了解该 pod 中发生的其他事情的方式。它必须与该 pod 共享命名空间。我们必须将那个边车注入到每个 pod 中。
为此,需要在该 pod 的定义中引入一些 YAML。您可能不会手动编写该 YAML 来注入 sidecar。它可能是在准入控制中完成的,或者作为 CI/CD 过程的一部分,可能会自动执行注入该 sidecar 的过程。然而它必须注入。
另一方面,如果我们使用 eBPF,我们在内核中运行我们的工具,那么我们不需要更改 pod 定义。我们会自动从内核的角度获得这种可见性,因为内核可以看到该主机上发生的一切。只要我们将 eBPF 程序添加到每个主机上,我们就会获得全面的可见性。这也意味着我们可以抵御攻击。
如果我们的主机以某种方式受到威胁,如果有人设法逃离容器并进入主机,或者即使他们以某种方式运行单独的 pod,您的攻击者可能不会费心使用您的可观察性工具来检测他们的进程和他们的 pod。如果您的可观察性工具在内核中运行,那么无论如何都会看到它们。你无法躲避那些' s 在内核中运行。这种在没有 sidecar 的情况下运行检测的能力正在创建一些非常强大的可观察性工具。
弹性、安全、可观察性、无sidercar部署
它还让我们想到了无边服务网格的想法。服务网格具有弹性、可观察性和安全性。现在有了 eBPF,我们可以在不使用 sidecar 的情况下实现服务网格。我在图表之前展示了我们如何使用 eBPF 绕过主机上的网络堆栈。对于服务网格,我们可以更进一步。 在传统的 sidecar 模型中,我们在希望成为服务网格一部分的每个 pod 中运行一个代理,也许是 Envoy。该代理的每个实例都有路由信息,每个数据包都必须通过该代理。您可以在此图的左侧看到,网络数据包的路径非常曲折。它基本上经历了五个网络堆栈实例。我们可以用 eBPF 大大缩短它。我们不能总是避免代理。 如果我们在第 7 层做某事,我们需要那个代理,但我们可以避免在每个 pod 中都有一个代理实例。我们可以通过少得多的路由信息和配置信息副本来提高可扩展性。我们可以通过网络堆栈内 XDP 层或套接字层的 eBPF 连接绕过许多这些网络步骤。 eBPF 将为我们提供资源消耗更少、效率更高的服务网格。我希望这能体现出我认为 eBPF 围绕网络、可观察性和安全性实现的一些东西,这将为我们提供更具弹性和可扩展性的部署。我们可以通过少得多的路由信息和配置信息副本来提高可扩展性。我们可以通过网络堆栈内 XDP 层或套接字层的 eBPF 连接绕过许多这些网络步骤。eBPF 将为我们提供资源消耗更少、效率更高的服务网格。 我希望这能体现出我认为 eBPF 围绕网络、可观察性和安全性实现的一些东西,这将为我们提供更具弹性和可扩展性的部署。我们可以通过少得多的路由信息和配置信息副本来提高可扩展性。我们可以通过网络堆栈内 XDP 层或套接字层的 eBPF 连接绕过许多这些网络步骤。eBPF 将为我们提供资源消耗更少、效率更高的服务网格。我希望这能体现出我认为 eBPF 围绕网络、可观察性和安全性实现的一些东西,这将为我们提供更具弹性和可扩展性的部署。
总结
到目前为止,我几乎一直在谈论 Linux。它也将出现在 Windows 中。微软一直致力于 Windows 上的 eBPF。他们与 Isovalent 和许多其他对大规模可扩展网络感兴趣的公司一起参与其中。我们共同组建了 eBPF 基金会,它是 Linux 基金会下的一个基金会,真正负责跨不同操作系统的 eBPF 技术。
我希望这能说明为什么 eBPF 如此重要,它对于软件的弹性部署如此具有革命性,尤其是在云原生空间中,但不一定限于此。无论您运行的是 Linux 还是 Windows,都有 eBPF 工具可帮助您优化这些部署并使其更具弹性。
审核编辑 :李倩
-
openEuler 倡议建立 eBPF 软件发布标准2022-12-23 1723
-
比亚迪电池有这样的超能力,确实挺牛X的2009-10-27 1610
-
医疗用增进装置:让“超能力”成为可能!2013-01-06 1372
-
双11阿里云人工智能ET魔术表演解密:“超能力”口译+语音视频识别2016-11-15 2157
-
阿尔法蛋拥有什么超能力?2018-08-18 19680
-
应用前沿 | 快速连接,浩亭汽车行业的“超能力”2019-07-02 2793
-
LED漂移超能力卤素重建-PSDE May 20092021-04-23 613
-
eBPF是什么以及eBPF能干什么2021-07-05 13768
-
HarmonyOS3超能力加持 聚能泵技术让华为Mate50“没电也能打电话”2022-09-07 2887
-
摄像机+运营商专线,解锁融合服务超能力!2023-07-04 893
-
基于ebpf的性能工具-bpftrace脚本语法2023-09-04 2623
-
大核桃单北斗防爆手持终端,凭啥能在高危环境里“横着走”?它到底有何超能力!2025-01-07 762
-
AI大模型赋能!移远通信打造具有“超能力”的AI智能玩具解决方案2025-01-13 564
-
揭秘短波红外相机的 “超能力”2025-08-05 1468
全部0条评论

快来发表一下你的评论吧 !
