

Java 8 Stream之collect()的奇技淫巧
描述
前言
本身我是一个比较偏向少使用Stream的人,因为调试比较不方便。
但是, 不得不说,stream确实会给我们编码带来便捷。
所以还是忍不住想分享一些奇技淫巧。
正文
Stream流 其实操作分三大块 :
- 创建
- 处理
- 收集
我今天想分享的是 收集 这part的玩法。
OK,开始结合代码示例一起玩下:
lombok依赖引入,代码简洁一点:
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.20version>
<scope>compilescope>
dependency>
准备一个UserDTO.java
/**
* @Author: JCccc
* @Description:
*/
@Data
public class UserDTO {
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private String sex;
/**
* 是否有方向
*/
private Boolean hasOrientation;
}
准备一个模拟获取List的函数:
private static List getUserList() {
UserDTO userDTO = new UserDTO();
userDTO.setName("小冬");
userDTO.setAge(18);
userDTO.setSex("男");
userDTO.setHasOrientation(false);
UserDTO userDTO2 = new UserDTO();
userDTO2.setName("小秋");
userDTO2.setAge(30);
userDTO2.setSex("男");
userDTO2.setHasOrientation(true);
UserDTO userDTO3 = new UserDTO();
userDTO3.setName("春");
userDTO3.setAge(18);
userDTO3.setSex("女");
userDTO3.setHasOrientation(true);
List userList = new ArrayList<>();
userList.add(userDTO);
userList.add(userDTO2);
userList.add(userDTO3);
return userList;
}
第一个小玩法
将集合通过Stream.collect() 转换成其他集合/数组:
现在拿List 做例子
转成 HashSet :
List userList = getUserList();
Stream usersStream = userList.stream();
HashSet usersHashSet = usersStream.collect(Collectors.toCollection(HashSet::new));
转成 Set :
List userList = getUserList();
Stream usersStream = userList.stream();
Set usersSet = usersStream.collect(Collectors.toSet());
转成 ArrayList:
List userList = getUserList();
Stream usersStream = userList.stream();
ArrayList usersArrayList = usersStream.collect(Collectors.toCollection(ArrayList::new));
转成 Object[] objects :
List userList = getUserList();
Stream usersStream = userList.stream();
Object[] objects = usersStream.toArray();
转成 UserDTO[] users :
List userList = getUserList();
Stream usersStream = userList.stream();
UserDTO[] users = usersStream.toArray(UserDTO[]::new);
for (UserDTO user : users) {
System.out.println(user.toString());
}
第二个小玩法
聚合(求和、最小、最大、平均值、分组)
找出年龄最大:
stream.max()
写法 1:
List userList = getUserList();
Stream usersStream = userList.stream();
Optional maxUserOptional =
usersStream.max((s1, s2) -> s1.getAge() - s2.getAge());
if (maxUserOptional.isPresent()) {
UserDTO masUser = maxUserOptional.get();
System.out.println(masUser.toString());
}
写法2:
List userList = getUserList(); Stream usersStream = userList.stream();
Optional maxUserOptionalNew = usersStream.max(Comparator.comparingInt(UserDTO::getAge));
if (maxUserOptionalNew.isPresent()) {
UserDTO masUser = maxUserOptionalNew.get();
System.out.println(masUser.toString());
}
效果:
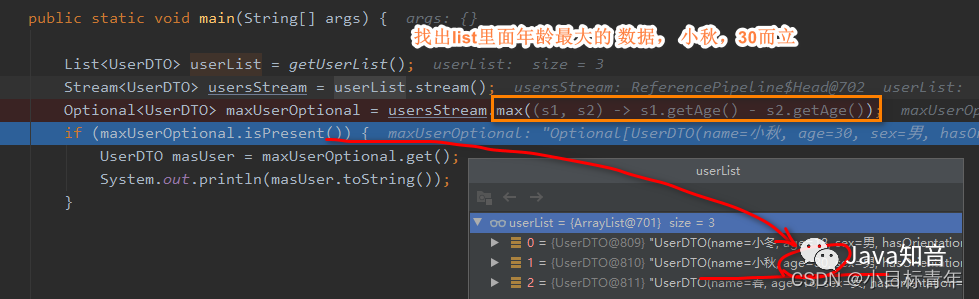
输出:
UserDTO(name=小秋, age=30, sex=男, hasOrientation=true)
找出年龄最小:
stream.min()
写法 1:
Optional minUserOptional = usersStream.min(Comparator.comparingInt(UserDTO::getAge));
if (minUserOptional.isPresent()) {
UserDTO minUser = minUserOptional.get();
System.out.println(minUser.toString());
}
写法2:
Optional min = usersStream.collect(Collectors.minBy((s1, s2) -> s1.getAge() - s2.getAge()));
求平均值:
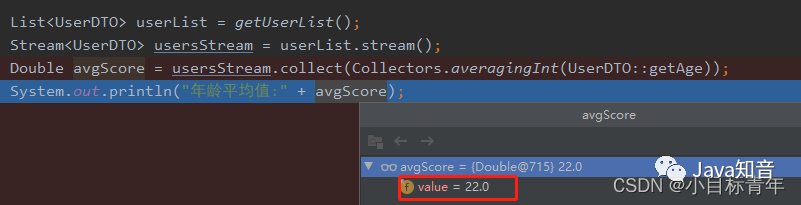
List userList = getUserList();
Stream usersStream = userList.stream();
Double avgScore = usersStream.collect(Collectors.averagingInt(UserDTO::getAge));
效果:
求和:
写法1:
Integer reduceAgeSum = usersStream.map(UserDTO::getAge).reduce(0, Integer::sum);
写法2:
int ageSumNew = usersStream.mapToInt(UserDTO::getAge).sum();
统计数量:
long countNew = usersStream.count();
简单分组:
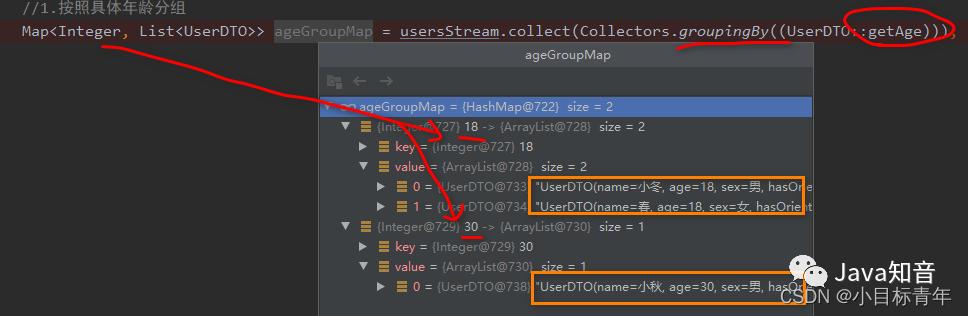
按照具体年龄分组:
//按照具体年龄分组
Map> ageGroupMap = usersStream.collect(Collectors.groupingBy((UserDTO::getAge)));
效果:
分组过程加写判断逻辑:
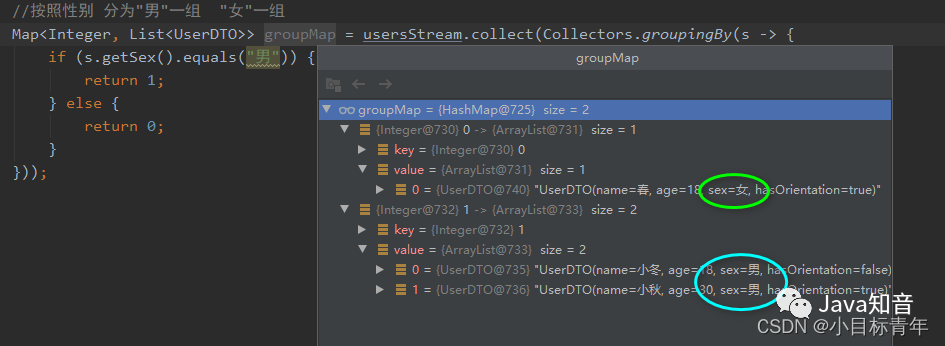
//按照性别 分为"男"一组 "女"一组
Map> groupMap = usersStream.collect(Collectors.groupingBy(s -> {
if (s.getSex().equals("男")) {
return 1;
} else {
return 0;
}
}));
效果:
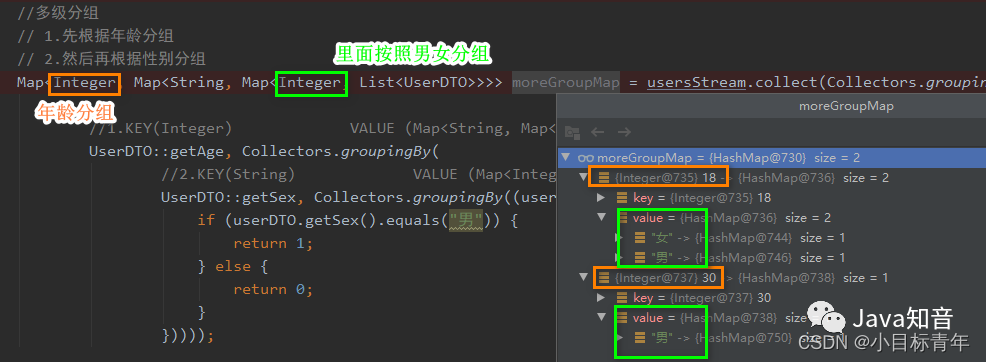
多级复杂分组:
//多级分组
// 1.先根据年龄分组
// 2.然后再根据性别分组
Map>>> moreGroupMap = usersStream.collect(Collectors.groupingBy(
//1.KEY(Integer) VALUE (Map>)
UserDTO::getAge, Collectors.groupingBy(
//2.KEY(String) VALUE (Map>)
UserDTO::getSex, Collectors.groupingBy((userDTO) -> {
if (userDTO.getSex().equals("男")) {
return 1;
} else {
return 0;
}
}))));
效果:
来源:blog.csdn.net/qq_35387940/article/details/127008965
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Java利用hanlp完成语句相似度分析的案例详解2019-02-23 3228
-
如何利用Stream API来优化Java代码2021-07-26 1967
-
JDK8 Stream数据流效率分析2022-08-17 2113
-
java的stream编程调试技巧2022-10-11 2441
-
怎么使用Java8的Stream API比较两个List的差异呢?2023-08-12 3254
-
Stream API原理介绍2023-09-30 1542
-
Java8的Stream流 map() 方法2023-09-25 3196
-
Java的Stream的常用知识2023-10-11 1219
全部0条评论

快来发表一下你的评论吧 !
