

基本图像处理技术的数据增强方法介绍
描述
数据增强(DA)是训练先进的AI算法模型的必要技术,不过并不是所有的数据增强都能提升模型精度,在今天的分享中,从数据增强的角度,对于多种增强方式的效果进行了验证测试,希望对大家有帮助!
一、前言&简要
为了缓解上述问题,有研究者提出了一种简单而高效的方法,称为保持增强(KeepAugment),以提高增强图像的保真度。其主要思想是首先使用显著性map来检测原始图像上的重要区域,然后在增强过程中保留这些信息区域。这种信息保护策略使我们能够生成更忠实的训练示例。
在实验上,也证明了该方法在一些现有的技术数据增强方案上有了显著的改进,例如:自动增强、裁剪、随机擦除,在图像分类、半监督图像分类、多视点多摄像机跟踪和目标检测等方面取得了很好的效果。
二、知识回顾
首先我们回一下什么叫“数据增强”?数据增强(Data Augmentation)是一种通过让有限的数据产生更多的等价数据来人工扩展训练数据集的技术。它是克服训练数据不足的有效手段,目前在深度学习的各个领域中应用广泛。但是由于生成的数据与真实数据之间的差异,也不可避免地带来了噪声问题。
为什么需要数据增强?
深度神经网络在许多任务中表现良好,但这些网络通常需要大量数据才能避免过度拟合。遗憾的是,许多场景无法获得大量数据,例如医学图像分析。数据增强技术的存在是为了解决这个问题,这是针对有限数据问题的解决方案。数据增强一套技术,可提高训练数据集的大小和质量,以便您可以使用它们来构建更好的深度学习模型。在计算视觉领域,生成增强图像相对容易。即使引入噪声或裁剪图像的一部分,模型仍可以对图像进行分类,数据增强有一系列简单有效的方法可供选择,有一些机器学习库来进行计算视觉领域的数据增强,比如:imgaug (https://github.com/aleju/imgaug)它封装了很多数据增强算法,给开发者提供了方便。
计算视觉数据增强
计算视觉领域的数据增强算法大致可以分为两类:第一类是基于基本图像处理技术技术的数据增强,第二个类别是基于深度学习的数据增强算法。下面先介绍基于基本图像处理技术的数据增强方法:
1、flipping翻转 一般都是水平方向翻转而少用垂直方向,即镜像变换。图像数据集上证实有用(CIFAR-10,ImageNet等),但无法应用在文本识别数据集(MNIST,SVHN等)
2、color space色彩空间 简单做法是隔离单个色彩通道,例如R,G或B,此外可以通过简单的矩阵运算以增加或减少图像的亮度。更高级的做法从颜色直方图着手,更改这些直方图中的强度值(想到了图像处理中的直方图均衡)。
3、cropping裁剪 分统一裁剪和随机裁剪。统一裁剪将不同尺寸的图像裁剪至设定大小,随机裁剪类似translation,不同之处在于translation保留原图尺寸而裁剪会降低尺寸。裁剪要注意不要丢失重要信息以至于改变图像标签。
4、rotation旋转 要注意旋转度数。以MNIST为例,轻微旋转(例如1°-20°)可能有用,再往后增加时数据标签可能不再保留。
5、translation位置变换 向左,向右,向上或向下移动图像可能是非常有用的转换,以避免数据中的位置偏差。例如人脸识别数据集中人脸基本位于图像正中,位置变换可以增强模型泛化能力。
6、noise injection添加噪声 添加高斯分布的随机矩阵 7、color space transformations色彩空间增强 照明偏差是图像识别问题中最常见的挑战之一,因此色彩空间转换(也称为光度转换)的比较直观有效。 ①遍历图像以恒定值减少或增加像素值(过亮或过暗) ②拼接出(splice out)各个RGB颜色矩阵 ③将像素值限制为某个最小值或最大值 ④操作色彩直方图以改变图像色彩空间特征 注意将彩色图转换黑白虽然简化了这些操作,但精度会降低 geometric versus photometric transformations几何与光度转换
1、kernel flters内核过滤器 平滑和锐化,即图像处理中用卷积核滑过整幅图像的操作。这一点尚未开发,它和CNN中卷积机制非常相似(就一样啊),因此可以通过调整网络参数更好地改善网络,而不需要额外进行这样的数据增强操作。
2、mixing images图像混合 做法是通过平均图像像素值将图像混合在一起:
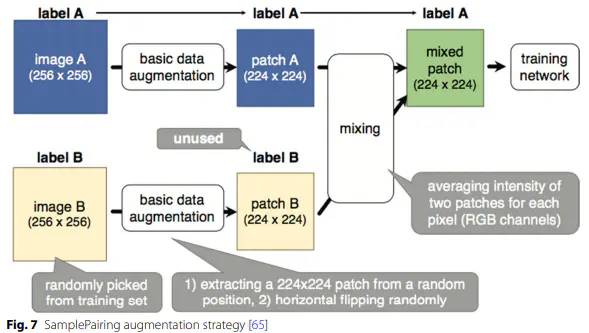
mixing images 研究发现是当混合来自整个训练集的图像而不是仅来自同一类别的实例的图像时,可以获得更好的结果。其它一些做法: ①一种非线性方法将图像组合成新的训练实例:

非线性方法 ②另一方法是随机裁剪图像并将裁剪后的图像连接在一起以形成新图像:

随机裁剪再拼接 这类方法从人的视角看毫无意义,但确实提升了精度。可能解释是数据集大小的增加导致了诸如线和边之类的低级特征的更可靠表示。 3、random erasing随机擦除 这一点受到dropout正规化的启发,随机擦除迫使模型学习有关图像的更多描述性特征,从而防止过拟合某个特定视觉特征。随机擦除的好处在于可以确保网络关注整个图像,而不只是其中的一部分。最后随机擦除的一个缺点是不一定会保留标签(例如文本8->6)。

三、新方法
新方法控制数据增强的保真度,从而减少有害的错误信息。研究者的想法是通过显著性映射测量图像中矩形区域的重要性,并确保数据增强后始终呈现得分最高的区域:对于裁剪,通过避免切割重要区域(见下图a5和b5);对于图像级转换,通过将重要区域粘贴到转换图像顶部(参见下图a6和b6)。


Eq2:
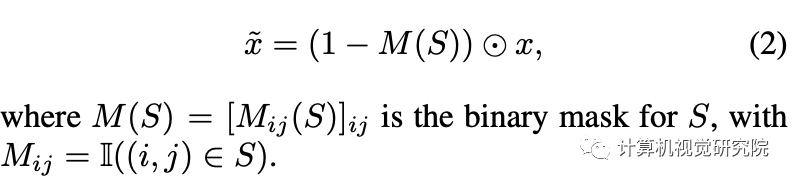
Eq3:
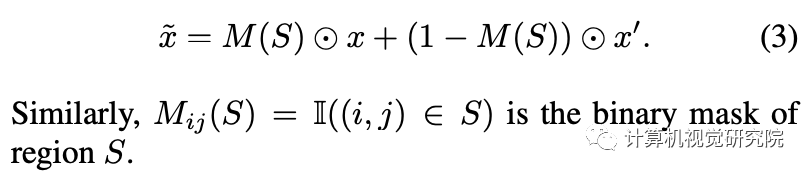
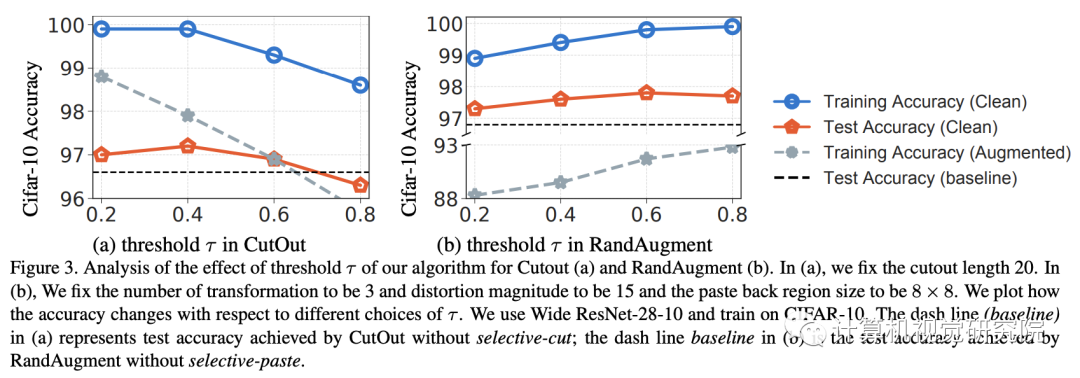
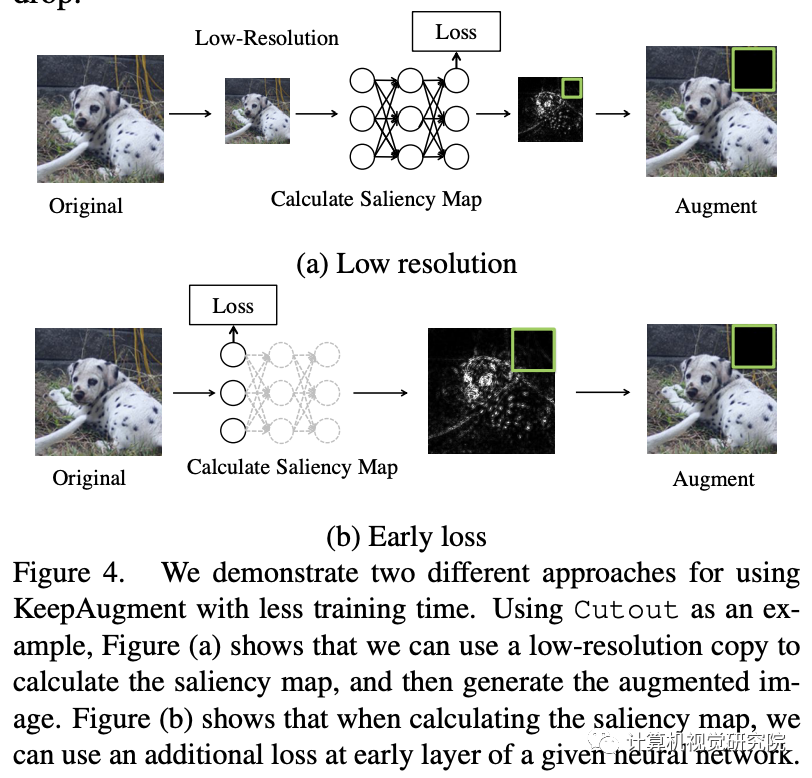
四、实验
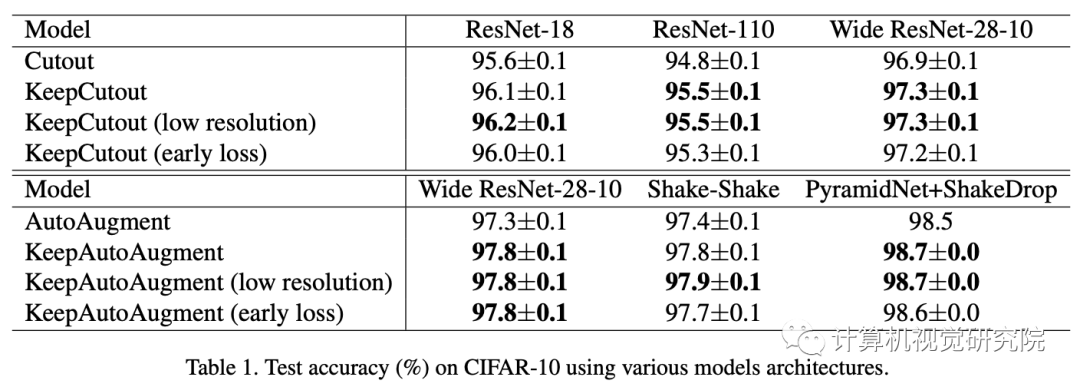
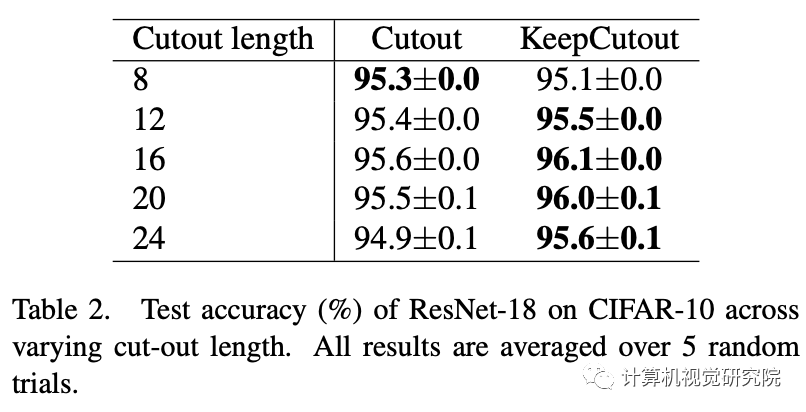
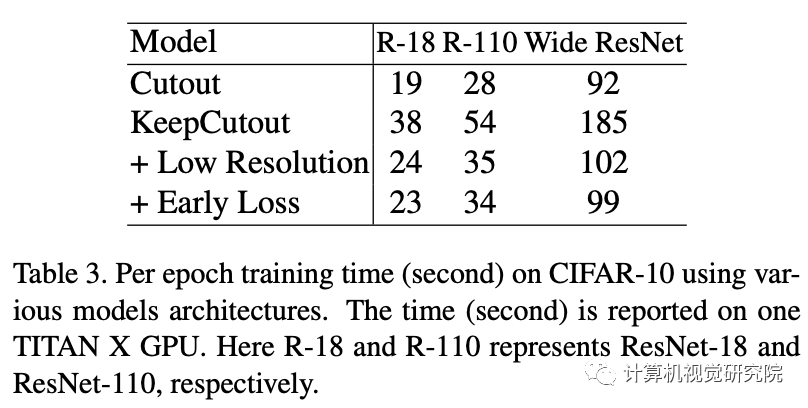
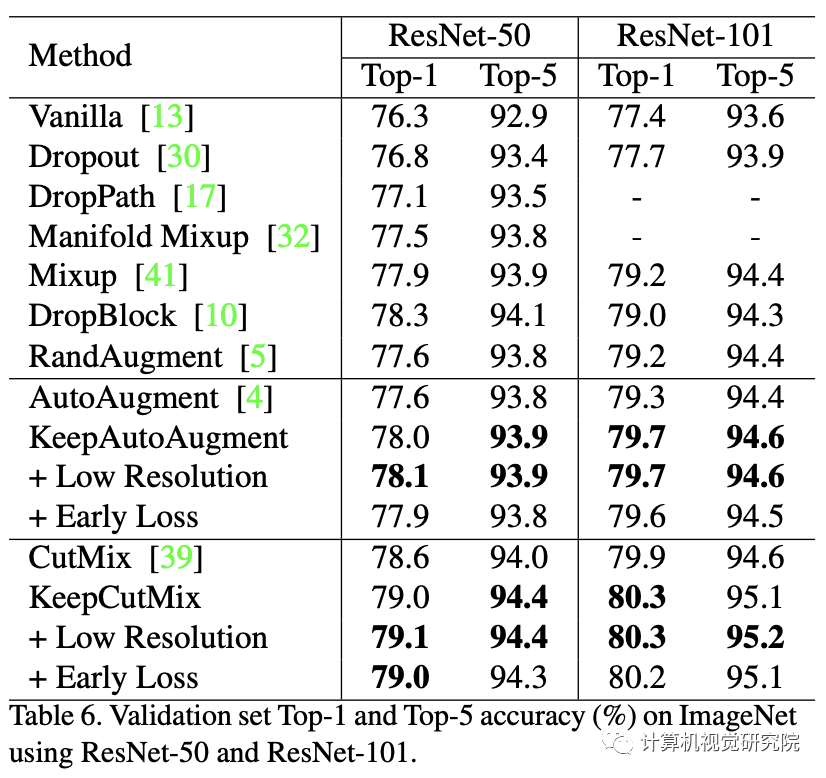
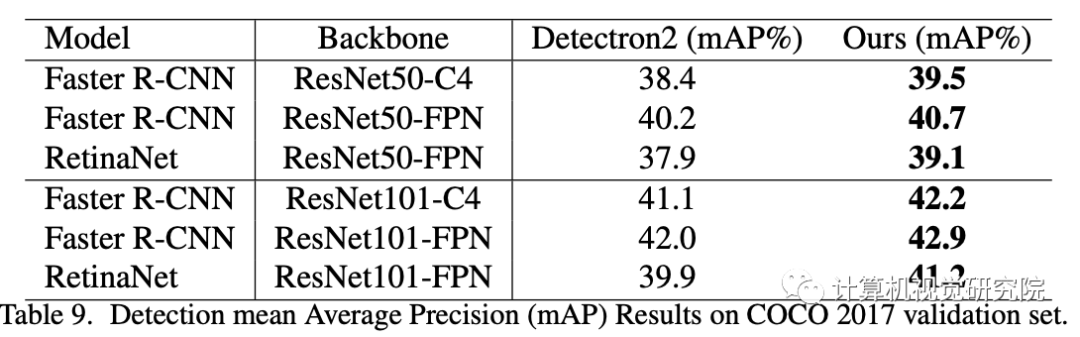
审核编辑:郭婷
-
机器视觉之图像增强和图像处理2023-10-23 4018
-
机器视觉:图像处理技术、图像增强技术2023-10-20 5817
-
详解各种图像数据增强技术2022-10-26 2619
-
基于基本图像处理技术的数据增强方法2022-08-13 2513
-
基于图像的数据增强方法发展现状综述2022-03-23 2525
-
FPGA图像处理方法2020-12-25 4483
-
MATLAB图像处理工具箱的函数介绍和图像处理与分析的技术实现分析2019-10-30 1684
-
基于Matlab的图像增强与复原技术在SEM图像中的应用2018-11-14 2680
-
基于Hash函数的文本图像脆弱水印算法2017-12-04 950
-
基于岭回归的稀疏编码文本图像复原方法2017-11-28 928
-
数字图像处理的技术方法和应用2015-11-18 4449
-
利用API 增强VB 的图像处理功能2009-08-28 547
-
一种有效的文本图像二值化方法2009-06-11 818
全部0条评论

快来发表一下你的评论吧 !
