

JSON压缩算法解读
描述

1. 关于作者
大家好!我是来自深圳技术大学FSR Lab(编者注:Falcon Swarm Robotics Lab猎鹰集群机器人控制实验室的缩写)的同学,标题FFH就是FSRlab For Harmony!并且我也正在参加OpenHarmony成长计划从论文到开源提交研究,以后我们也会陆续在这个社区记录学习心得和体会。
在OpenHarmony成长计划啃论文俱乐部里,FFH小组同学们与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究序列化相关技术…
2. 为什么需要压缩JSON?
尽管JSON数据格式比XML效率要高,但是它仍然是web服务器和浏览器传输过程中比较低效的数据格式。为什么呢?
-
首先,它将所有的内容都转换为了文本。
-
第二是转换之后的文本过度使用引号,这样会给每个字符串添加多两个字节。
-
第三,它本身没有schema的标准格式,比如在一个消息中序列化多个对象的时候,即使每个对象的属性的键名是重复且相同的,但是转换后的文本数据还是会重复每一个键名。
JSON以前的时候有一个优势,就是可以被Javascript引擎直接解析,但因为现在越来越重视安全性,JSON的这个优势也逐渐消失了,但是因为它比XML效率以及性能都更高,所以许多传统的C/S模式都是选择JSON,比如web服务。当有庞大的数据量以及复杂数据结构需要从web浏览器中传输到服务器的时候,JSON压缩就起到了非常大的作用,然而中间就会存在我们刚刚说的三点问题,我们也不能使用传统的gzip压缩算法,因为浏览器不知道服务器是否支持gzip解压。
下面我们就来看看两种常见的JSON压缩算法,cJSON与HPack。
3. cJSON压缩算法
cJSON压缩算法(cJSON Compression Algorithm)的特点就是可以使用自动类型提取压缩JSON数据格式的内容。它成功解决了一个非常重要的问题,就是我们上一小节提到的第三点,将不断重复的键名舍去了,我们我们来看一个例子:
使用cJSON前的数据格式:
[
{ //表示一个坐标点
"x":100,
"y":100
},
{ //表示一个长方形
"x":100,
"y":100,
"width":200,
"height":150
},
{},//表示一个空对象
... //以下省略数以万计的对象
]
上面未经压缩的数据中,我们可以看到有非常多的空间被重复的键名所占据,比如“x”,“y”等等,当数据非常多的时候,这些看起来不起眼的重复键名会给传输效率带来非常大的影响,其实解决思路也非常简单,因为他们是重复的,那我们只存储一次不就好了?下面我们来按照我们的思路看看cJSON处理过后的数据吧。
{
"templates":[
[], //type1
[] //type2
],
"value":[
{ //第一个对象:坐标点
"type":1,
"values":[
100,
100
]
},
{ //第二个对象:矩形
"type":2,
"values":[
100,
100,
200,
150
]
},
{
//第三个空对象
},
//以下省略数以万计的对象......
]
}
从上面的数据中我们可以看到,我们格式化了数据,把键名存储了起来,重复的就不存储,然后值通过“type”索引来对应键名,这样在数据量庞大的时候确实减少了不少空间,但是我们仔细看“templates”内的键名依旧有重复的字段存在。说明了我们还存在优化空间,优化完压缩后效果如下:
{ "function": "cjson",
"templates": [
[0, "x", "y"],
[1, "width", "height"]
],
"values": [
[1, 100, 100 ], //第一个对象:坐标点
[2, 100, 100, 200, 150 ], //第二个对象:矩形
[] //第三个空对象
]
}
直接看压缩后的代码结构你可能不太能理解,那我们就来看看他的具体原理,为了解决“template”内键名重复的字段,这个算法采用了树这个数据结构,每遇到一个要传输的对象,就按顺序把键值存入树的节点中(灰色的节点是被标记的结尾节点指针,表示该节点存储的是某个对象最后一个属性的键值),重复的就不存储,这样就解决了我们的问题,这个键值树的变化过程如下:
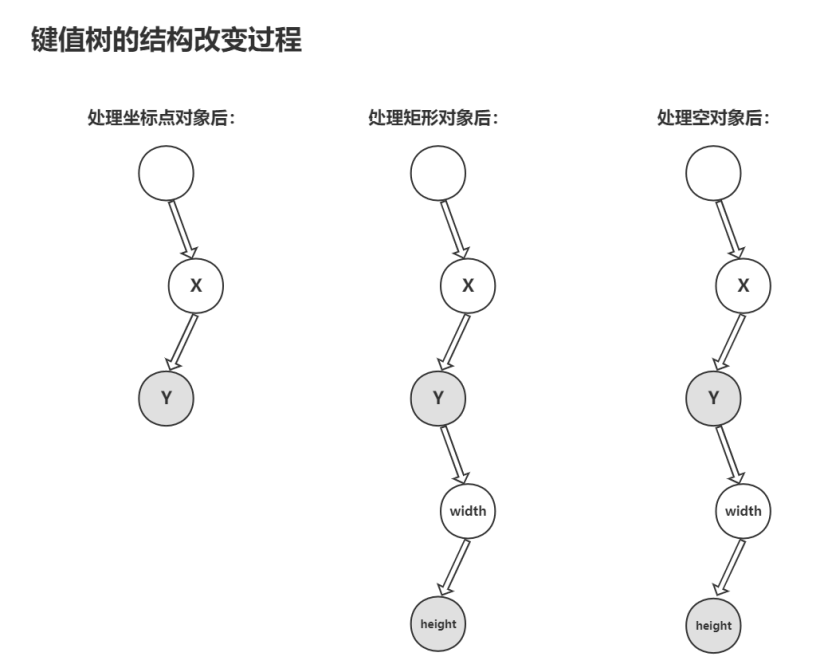
最后数据在匹配键值的时候就根据 “values” 中所标记的结尾节点指针找到对应键值数组,这样就构成了cJSON的压缩算法。
仔细的同学就会发现,如果一个对象中没有"X"和"Y",只有“width”和“height”,或者键值节点顺序是错的,是不是会出问题?答案是对的,会出现无法匹配的键值的情况,所以这种方法只能在特定的场景下应用,存在一定局限性。
总体来说,cJSON在处理非常庞大的数据量的时候效果还是非常客观的。
4. JSON.HPack压缩算法
JSON.HPack压缩算法(HPack Compression Algorithm)是一种无损、跨语言、注重性能的JSON数据压缩算法,可以让我们在使用post请求在客户端发送数据到服务器的过程中相对普通JSON格式节省约70%的字符。
其原理本质上也是跟cJSON一样将键值抽离开,举个例子:
使用HPack算法前:
{
"id" : 1,
"sex" : "Female",
"age" : 38,
"classOfWorker" : "Private",
"maritalStatus" : "Married-civilian spouse present",
"education" : "1st 2nd 3rd or 4th grade",
"race" : "White"
}
使用HPack算法后:
[],
[]
可以看到相对于普通JSON以及cJSON少了很多字符,比如引号,各种括号等等,这种压缩算法在数据量庞大的情况下效果也非常可观。
HPack算法提供了几个级别的压缩(从0到4)。等级越高压缩效率越高,每提升一个等级都有引入附加功能。0级压缩通过从结构中分离键值来执行最基本的压缩,并在索引0的元素上创建键名数组,下一个等级就可以通过假设存在重复条目来进一步减小JSON数据的大小。
5. 性能分析
接下来我们直接用数据来看看这几个压缩算法的压缩效率,我们分别用5组大小不同的JSON文件(50KB~1MB),每个JSON文件将使用servlet容器(tomcat)提供给浏览器,并分别用以下算法进行压缩:
-
Original JSON size - 未作修改的JSON数据
-
Minimized - 删除空白和新行(最基本的js优化)
-
Compresse cJSON - 使用CJSON压缩算法进行JSON压缩
-
Compresse HPack - 使用JSON.HPack压缩算法进行JSON压缩
-
Gzipped - 使用gzip和进行JSON压缩
-
Gzipped + Minimized - 使用gzip和删除空白和新行(最基本的js优化)进行JSON压缩
-
Gzipped + Compresse cJSON - 使用gzip和CJSON压缩算法进行JSON压缩
-
Gzipped + Compresse HPack - 使用gzip和JSON.HPack压缩算法进行JSON压缩
下表(TABLE I.RESULTES)是用以上各种方式处理完后的JSON数据大小(bytes),不同列表示不同的JSON数据集,不同行表示使用不同的压缩方式。
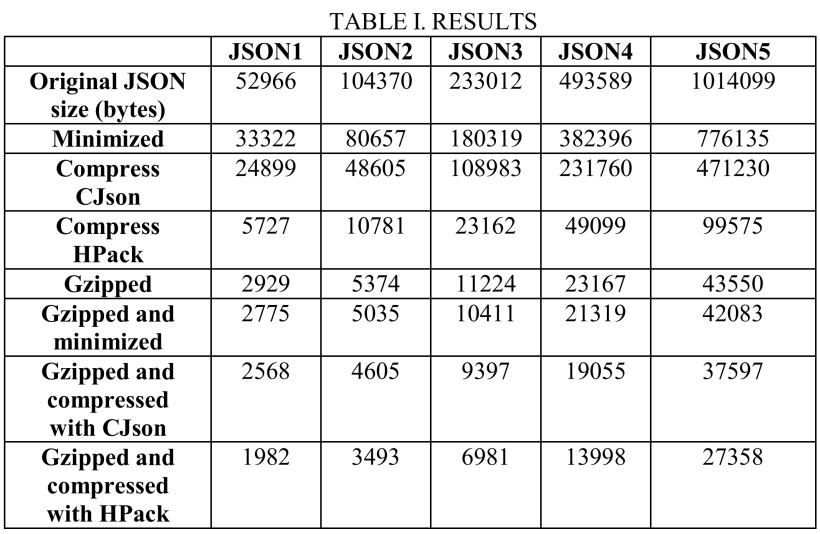
下面第一个图表Y轴表示JSON数据大小(bytes):
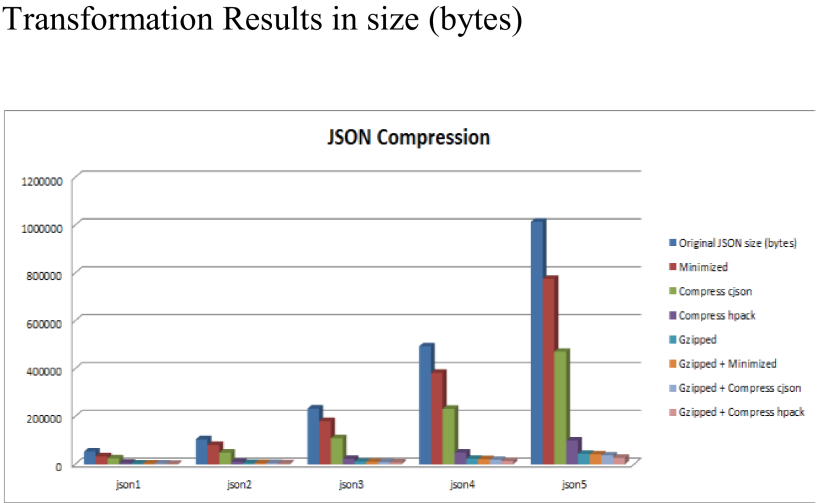
第二张图Y轴是JSON数据大小的百分比(%),原始数据为100%:
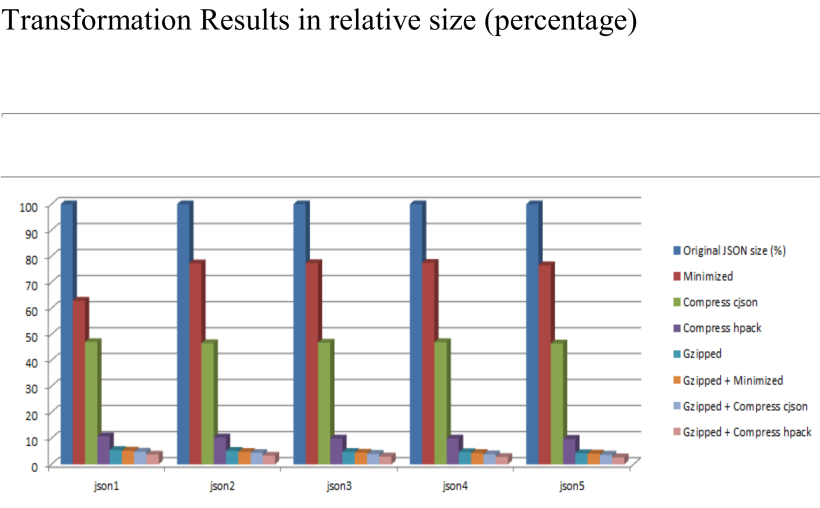
从上面的几个图表中我们可以直观地看到,单独使用cJSON可以把原始数据大小压缩到45%左右,单独使用HPack可以把原始数据大小压缩到8%左右,可见整体上HPack是优于cJSON的。
然而我们可以看到当使用gzip和上面提到的两个压缩算法相结合进行JSON压缩,效果才是最优的,基本可以达到1%~2%的压缩率。
总的来说,HPack比cJSON效率更高,速度也更快,但是在使用压缩算法进行传输的过程中,接收的一端需要进行相应的解压缩操作,否则无法使用被压缩过后的JSON数据,这一步也会存在一定的性能开销,在我们选择使用JSON压缩的时候,也需要考虑到这一点。当可以使用gzip进行压缩的时候,这种方法比其他压缩算法的效率都高,当两者同时结合起来,效果显而易见。
好了,我们这一次完整地了解了JSON序列化的发展,规范,应用以及相关的压缩算法,相信大家不仅对JSON压缩算法有了更深的了解,也对JSON序列化这个技术领域有了深刻的认识。
6. 参考文献
JSON Compression Algorithmshttp://repository.utm.md/bitstream/handle/5014/6418/ICMCS_2011_1_pg_244_247.pdf?sequence=1<本文完>
写在最后
OpenHarmony 成长计划—“啃论文俱乐部”(以下简称“啃论文俱乐部”)是在 2022年 1 月 11 日的一次日常活动中诞生的。截至 3 月 31 日,啃论文俱乐部已有 87 名师生和企业导师参与,目前共有十二个技术方向并行探索,每个方向都有专业的技术老师带领同学们通过啃综述论文制定技术地图,按“降龙十八掌”的学习方法编排技术开发内容,并通过专业推广培养高校开发者成为软件技术学术级人才。
啃论文俱乐部的宗旨是希望同学们在开源活动中得到软件技术能力提升、得到技术写作能力提升、得到讲解技术能力提升。大学一年级新生〇门槛参与,已有俱乐部来自多所高校的大一同学写出高居榜首的技术文章。
如今,搜索“啃论文”,人们不禁想到、而且看到的都是我们——OpenHarmony 成长计划—“啃论文俱乐部”的产出。
OpenHarmony开源与开发者成长计划—“啃论文俱乐部”学习资料合集
1)入门资料:啃论文可以有怎样的体验
https://docs.qq.com/slide/DY0RXWElBTVlHaXhi?u=4e311e072cbf4f93968e09c44294987d
2)操作办法:怎么从啃论文到开源提交以及深度技术文章输出 https://docs.qq.com/slide/DY05kbGtsYVFmcUhU
3)企业/学校/老师/学生为什么要参与 & 啃论文俱乐部的运营办法https://docs.qq.com/slide/DY2JkS2ZEb2FWckhq
4)往期啃论文俱乐部同学分享会精彩回顾:
同学分享会No1.成长计划啃论文分享会纪要(2022/02/18) https://docs.qq.com/doc/DY2RZZmVNU2hTQlFY
同学分享会No.2 成长计划啃论文分享会纪要(2022/03/11) https://docs.qq.com/doc/DUkJ5c2NRd2FRZkhF
同学们分享会No.3 成长计划啃论文分享会纪要(2022/03/25)
https://docs.qq.com/doc/DUm5pUEF3ck1VcG92?u=4e311e072cbf4f93968e09c44294987d
现在,你是不是也热血沸腾,摩拳擦掌地准备加入这个俱乐部呢?当然欢迎啦!啃论文俱乐部向任何对开源技术感兴趣的大学生开发者敞开大门。

扫码添加 OpenHarmony 高校小助手,加入“啃论文俱乐部”微信群
后续,我们会在服务中心公众号陆续分享一些 OpenHarmony 开源与开发者成长计划—“啃论文俱乐部”学习心得体会和总结资料。记得呼朋引伴来看哦。























原文标题:JSON压缩算法解读
文章出处:【微信公众号:开源技术服务中心】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 开源技术
- OpenHarmony
-
压缩算法的类型和应用2024-10-21 2524
-
数据压缩算法的介绍2023-02-28 3083
-
Spring Boot+Filter实现Gzip压缩超大json对象2022-12-01 1574
-
啃论文俱乐部 | 压缩算法团队:我们是如何开展对压缩算法的学习2022-06-21 2237
-
压缩算法是怎么定义的呢2021-10-19 1456
-
什么是压缩算法呢?压缩算法又是怎么定义的呢?2021-07-28 1270
-
Linux 5.7将支持Zstd压缩算法2020-03-26 3631
-
【案例分享】经典的压缩算法Huffman算法2019-07-17 2729
-
语音压缩算法研究2013-09-18 4469
-
基于ADPCM的语音压缩算法研究2011-04-08 1363
-
基于小波变换的干涉图压缩算法?2010-05-12 679
-
FPGA实现滑动平均滤波算法和LZW压缩算法2010-04-24 4423
全部0条评论

快来发表一下你的评论吧 !
