

亿铸存算一体AI大算力芯片:存算一体架构
存储技术
描述
一文带你快速了解:什么是存算一体?
它与近存计算、存内计算等概念有何不同?
为何存算一体架构是实现数字经济时代的先进生产力?
为什么我们需要存算一体?
在传统的冯·诺依曼架构中,处理与存储单元是分离的。由于存算分离,AI计算的数据搬运量非常大,会导致功耗大大增加,也就是存储墙。
此外,不管是传输还是计算工艺本身的限制,能效比已经接近极限。无论是20W, 75W, 150W的模组还是PCIe板卡,目前能支持的最高算力已经达到了天花板。以75W为例,不管是7nm工艺或将来会有的更高工艺,150TOPS到200TOPS已经基本封顶,这是存储墙带来的能耗墙导致的。
存储墙还导致了另一个问题——编译墙(生态墙),也可以说是可编程性。由于存算分离,数据搬运容易发生拥塞,尤其是在动态环境下,对数据进行调度和管理其实非常复杂,所以编译器无法在静态可预测的情况下对算子、函数、程序或者网络做整体的优化,只能手动、一个个或者一层层对程序进行优化,包括层与层之间的适配等,耗费了大量时间。
随着人工智能相关的高度数据中心化应用迎来爆发性增长,由传统的冯·诺依曼架构带来的这“三堵墙”弊端愈发凸显。这就要求人们寻找非冯·诺依曼的计算方法,于是就提出了存算一体架构。
存算一体赋能AI加速效率的理论基础
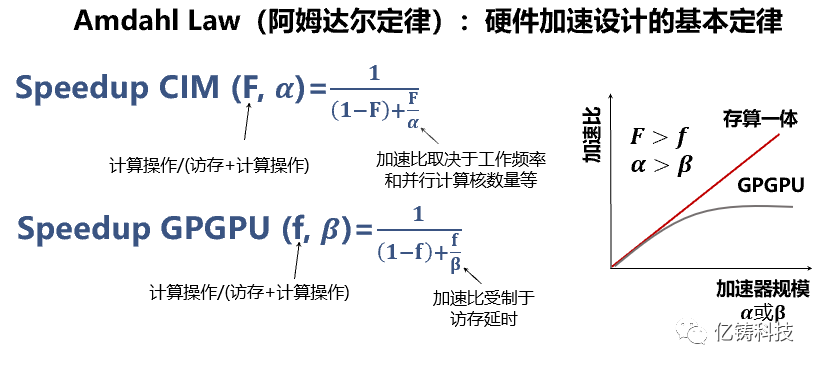
硬件加速性能是由Amdahl Law(阿姆达尔定律)确定,如同力学中的牛顿三定律:Speedup (F, α)=1/(F+((1-F))/α)。F ~访存/(访存+计算操作),α ~加速比取决于工作频率和并行计算核数量等裸性能。
阿姆达尔定律取决于两个因子:F和α。一个是裸算力,取决于先进工艺和计算单元核;一个是数据搬运效率或占用整体计算过程的时间和资源百分比,该因子决定了硬件性能提升的天花板。比如F=0.5,数据搬运占用了50%时间和资源,性能提升的天花板是2倍,高等级工艺无济于事,只能改进架构降低F因子。比如数据搬运不占用任何时间和资源或忽略不计,或F接近于0,硬件性能的提升和裸算力是线性关系。
阿姆达尔定律揭示了摩尔定律的误导,大算力芯片的真实性能不完全取决于先进工艺,尤其是需要大量数据搬运的AI芯片或类似芯片。这也是冯•诺依曼存算分离的瓶颈,也是存算一体的核心优势。
什么是存算一体?
存算一体目前在学术界和产业界有不少相似的概念,例如Computing-in-Memory, In-Memory-Computing, Logic-in-Memory等,不同研究领域的称呼不统一,相应的中文翻译也不尽相同,如:内存处理(In-Memory-Processing)、存内处理(Processing-in-Memory)、存内计算(Computing-in-Memory)、存算一体(In-Memory-Computing)等。
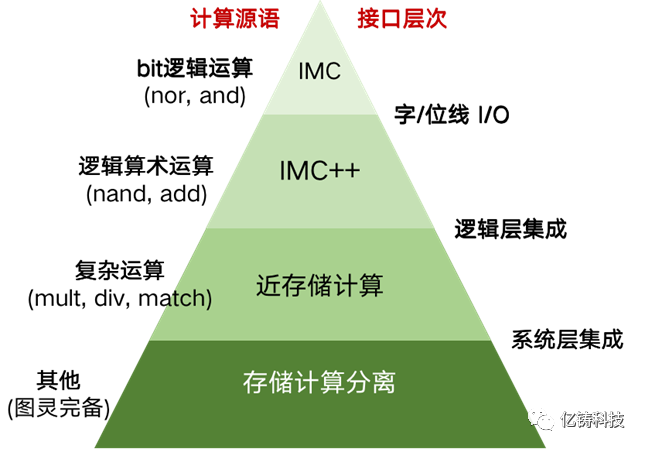
为清晰区分多种存算一体技术,可按照计算单元与存储单元在系统中的距离来进行分类。如图所示,越往金字塔顶端,计算与存储距离越近。同时,这一距离也改变了软硬件抽象分层。金字塔左侧的计算源语(源语:在百度词条中定义为具有原子操作性的若干指令组成的程序片段),指的是卸载到硬件单元进行原子操作的粒度,硬件通过在该粒度的高并发操作来获得性能提升。金字塔右侧代表存储与计算在哪个设计抽象层次进行融合。
存算一体分类
最底层为存算分离的冯·诺依曼架构。
往上一层,计算由位于存储芯片内部的计算单元完成。计算单元与存储单元在系统层集成,但两者依然相互独立操作。计算与存储的数据交换发生在存储系统内部,不会经过系统总线,因此带来带宽上极大提升。这一层的存算一体架构往往被称为Process-in-Memory,或Near Memory Computing。存储单元往往以大容量的DRAM为主,计算单元可以是处理器(如RISC-V),可编程加速器或硬加速器等。计算源语往往是一些较为复杂的运算,如(张量/向量/标量)乘法/除法,匹配查找等。硬件的峰值性能由计算单元数量,计算与存储的片内传输带宽决定。
再往上一层,计算单元与存储阵列(如SRAM阵列,ReRAM阵列)在逻辑层集成,融为一体,共同完成一个完整的计算源语的操作。并发执行的计算源语为更细的逻辑算数运算(如与非,加法等),数据并行的潜能进一步提升。存储阵列的字线与位线直接与存储阵列周边电路中的逻辑运算单元直连,存储与计算之间的数据传输距离进一步缩短。根据不同的存储Macro架构设计,计算的并发度也会不同。如常见的比特顺序流(bit-serial)模式,比特并行方式(bit-parallel)等。
最顶层是计算与存储完全的融合。部分计算发生在存储阵列的字线、位线甚至存储器件的I/O上。以数字计算方式实现时,存储阵列内的计算源语通常为Bit位逻辑运算(如抑或、与操作等),需要配合周边电路上的其他逻辑操作才能组成更为复杂的运算。以模拟计算实现时,存储阵列可以基于电阻定律在每个存储单元内实现乘法操作,然后基于电流定律实现位线上的加法操作。模拟计算具有极大的性能和能效优势,缺点是需要ADC等功耗较大的模数转换器,计算精度还可能受到一些器件工艺偏差等影响。
总之,计算与存储距离越近,数据移动代价(延迟,带宽)呈数量级下降,因此,计算源语的并发执行/并行计算的潜力越大;但计算与存储融合的越紧密,可编程性越差,越需要软件提供大并行度,大颗粒的并发算子才能发挥存算一体的优势。这也是当前主要将存算一体芯片用于加速深度学习的张量运算的主要原因。
根据存储器介质的不同,目前存算一体芯片的主流研发集中在传统易失性存储器,如SRAM, DRAM, 以及新型非易失性存储器,如RRAM(ReRAM), PCM, MRAM与闪存等。
实现存算一体的存储介质有哪些?
应用于存算一体,对于不同应用场景,Flash, SRAM和以ReRAM为代表的新型存储介质各有特长。
Flash是最早被采用的介质,技术和工艺等各方面最成熟,比较适合中小算力存算一体设计。但相比其它介质,性能有数量级的差距,而且工艺上难以突破40nm,用于大算力芯片会面临许多挑战。
SRAM的性能优异,而且容易实现DIY自主设计,常被学者采用。但密度较低、功耗较高,特别是工程实现难,尤其可靠性存在挑战,较适合中小算力存算一体芯片设计。
ReRAM新型存储介质在密度、性能、功耗和工程实现等方面,综合来说比较平衡,没有短板,比较适合大、中、小各类存算一体芯片,尤其是大算力芯片。
相比MRAM和PCRAM等其它新型存储介质,ReRAM在密度和可靠性等方面更有优势。比如密度高到一定程度之后,MRAM和PCRAM都会存在相邻单元被“磁”或“热”干扰的微缩性天花板问题。ReRAM不存在这类问题,可以完全兼容先进CMOS工艺。
为什么ReRAM是最适合实现
存算一体AI大算力的存储介质?
从非易失性、存储密度、读写次数、读写速度、读写功耗、未来发展潜力以及工艺成熟度等角度综合来看,ReRAM是业内普遍认为最适合做存算一体大算力的存储介质,它在算力潜能、算力精度和算力效率等主要指标上都拥有数量级的优势。
审核编辑:汤梓红
-
存算一体大算力AI芯片将逐渐走向落地应用2022-05-31 6947
-
比存算一体更进一步,“感存算一体化”前景如何?2022-06-08 8027
-
存算一体技术路线如何选2022-06-21 11658
-
存算一体技术发展现状和未来趋势电子发烧友网官方 2023-04-25
-
亿铸科技发布基于ReRAM的全数字化存算一体AI大算力芯片技术2022-09-01 4316
-
存算一体芯片在可穿戴设备市场有哪些机会2022-10-14 1837
-
亿铸科技存算一体大算力AI芯片技术助力苏州集成电路设计产业蓬勃发展2022-10-19 2495
-
国产存算一体超速前进 存算一体架构有机会解决很多AI面临的问题2022-11-25 3211
-
基于3DIC架构的存算一体芯片仿真解决方案2023-02-24 8794
-
ChatGPT开启大模型“军备赛”,存算一体开启算力新篇章2023-07-06 949
-
存算一体芯片的技术壁垒2023-09-22 2950
-
存算一体芯片新突破!清华大学研制出首颗存算一体芯片2023-10-11 2474
-
浅谈为AI大算力而生的存算-体芯片2023-12-06 1061
-
存算一体架构创新助力国产大算力AI芯片腾飞2024-10-23 2149
-
安克与知存科技联合打造Thus存算一体AI音频芯片2026-05-27 703
全部0条评论

快来发表一下你的评论吧 !
