

理解Vitis HLS默认行为
描述
相比于VivadoHLS,Vitis HLS更加智能化,这体现在Vitis HLS可以自动探测C/C++代码中可并行执行地部分而无需人工干预添加pragma。另一方面VitisHLS也会根据用户添加的pragma来判断是否需要额外配置其他pragma以使用户pragma生效。为便于说明,我们来看一个简单的案例。
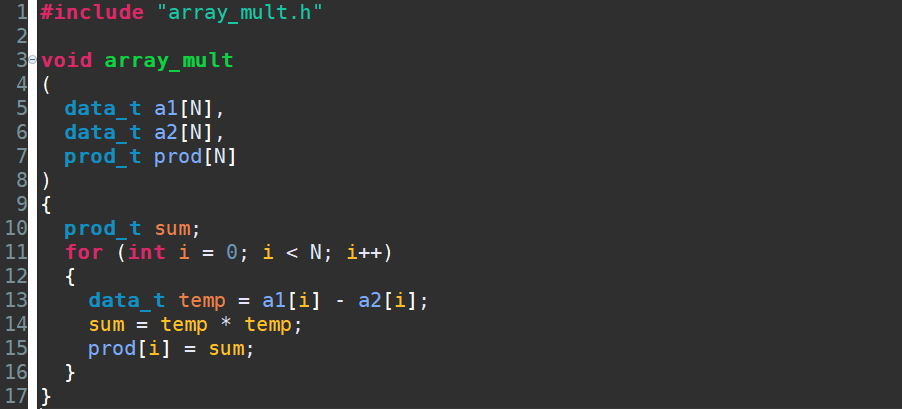
如下图所示代码,函数array_mult用于计算两个一维数组对应元素差的平方。数组长度为N,故通过N次for循环可完成此操作(这里N为8)。
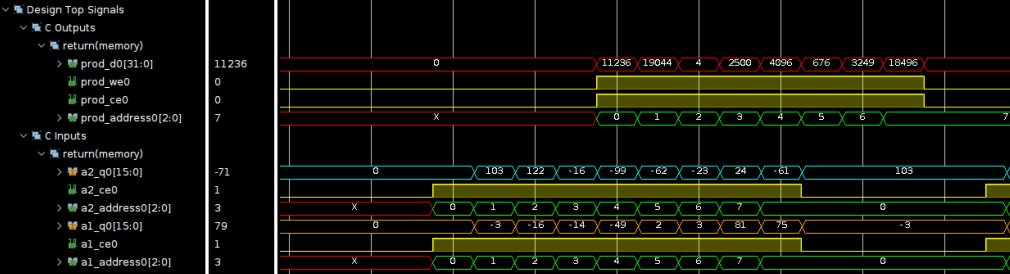
如果我们不添加任何pragma,从C综合后的报告来看,工具会自动对for循环添加PIPELINE,如下图所示。同时,工具会将数组映射为单端口RAM(因为数组是顶层函数的形参,故只生成单端口RAM需要的端口信号),这样匹配了DSP48的接口需求(两个输入数据一个输出数据)。从C/RTLCosim的波形可以看到输入/输出数据流关系。

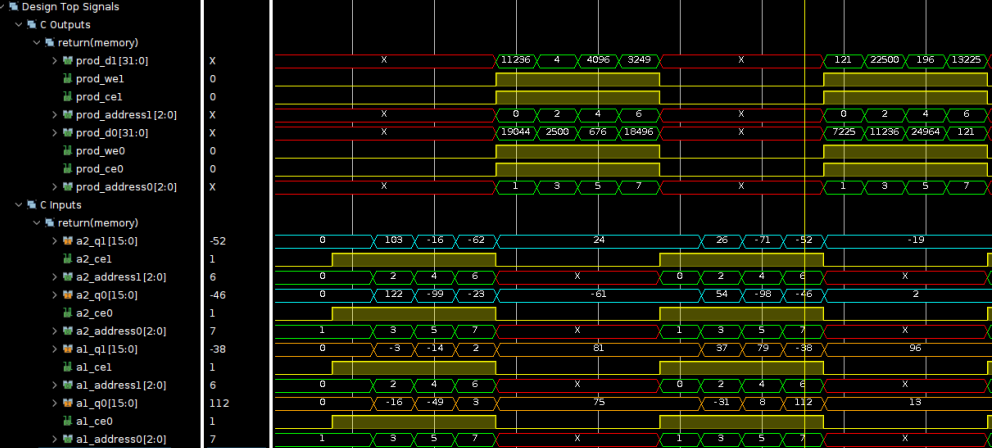
如果我们对for循环施加UNROLL,理论上分析可知工具应将for循环展开(复制8份),这样会消耗8个DSP48,如下图所示。这就需要能同时有16个数据提供给这8个DSP48,但此时工具只是将数组映射为双端口RAM。这显然造成了数据通路的不匹配。这其实造成了DSP48的浪费。这里,因为数组是顶层函数,故工具并没有对其施加ARRAY_PARTITION,但如果是子函数的形参,工具就会自动对数组施加ARRAY_PARTITION,以确保数据通路的匹配。

因此,我们换个思路,既然工具至多会将数组映射为双端口RAM,那么我们就将for循环复制两份,从而实现数据通路的匹配。这可通过UNROLL的选项factor设置为2。从C综合报告来看,消耗了2个DSP48,同时工具对for循环自动设置了PIPELINE。

当然,我们也可以对整个函数施加PIPELINE,这样工具会将for循环自动UNROLL,但这同样会造成DSP48的浪费,因为工具不会对顶层函数的形参数组自动进行ARRAY_PARTITION。于是,我们考虑手工添加ARRAY_PARTITION,同时对函数添加PIPELINE,从而使得数据通路完美匹配。

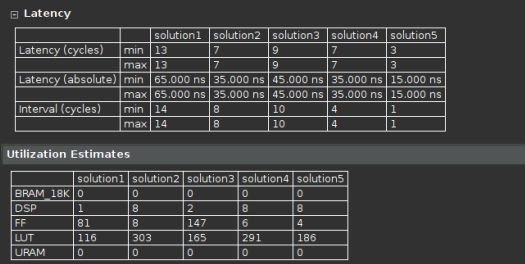
我们对这些Solution进行对比,如下图所示。solution1消耗资源最少,但Latency最大;solution5消耗资源最多,但Latency最小。
solution1:仅对for循环施加pipeline。
solution2:仅对for循环施加UNROLL。
solution3:仅对for循环施加UNROLL并将factor设置为2。
solution4:仅对函数施加PIPELINE。
solution5:对函数施加PIPELINE,对输入/输出数组施加ARRAY_PARTITION(Complete)。
审核编辑:汤梓红
-
使用AMD Vitis Unified IDE创建HLS组件2025-06-20 2884
-
如何使用AMD Vitis HLS创建HLS IP2025-06-13 2569
-
Vitis HLS移植指南2023-09-13 679
-
如何在Vitis HLS GUI中使用库函数?2023-08-16 2716
-
AMD全新Vitis HLS资源现已推出2023-04-23 2105
-
使用Vitis HLS创建属于自己的IP相关资料分享2022-09-09 5611
-
FPGA高层次综合HLS之Vitis HLS知识库简析2022-09-07 3935
-
Vitis HLS知识库总结2022-09-02 5214
-
Vitis HLS前端现已全面开源2022-08-03 1966
-
Vitis HLS工具简介及设计流程2022-05-25 3930
-
基于Vitis HLS的加速图像处理2022-02-16 3689
-
Vitis初探—1.将设计从SDSoC/Vivado HLS迁移到Vitis上2021-01-31 2267
-
Vivado HLS和Vitis HLS 两者之间有什么区别2020-11-05 41641
全部0条评论

快来发表一下你的评论吧 !
