

AI/ML应用和处理器的架构探索
描述
人工智能应用的架构探索很复杂,涉及多项研究。首先,我们可以针对单个问题,例如内存访问,也可以查看整个处理器或系统。
行业背景
人工智能 (AI) 应用考虑了计算、存储、内存、管道、通信接口、软件和控制。此外,人工智能应用程序处理可以分布在处理器内的多核、PCIe 主干上的多个处理器板、分布在以太网中的计算机、高性能计算机或数据中心的系统。此外,AI处理器还具有巨大的内存大小要求,访问时间限制,跨模拟和数字的分布以及硬件 - 软件分区。
问题
人工智能应用的架构探索很复杂,涉及多项研究。首先,我们可以针对单个问题,例如内存访问,也可以查看整个处理器或系统。大多数设计都是从内存访问开始的。有很多选择 - SRAM 与 DRAM、本地与分布式存储、内存计算以及缓存反向传播系数与丢弃。
第二个评估扇区是总线或网络拓扑。虚拟原型可以具有用于处理器内部的片上网络、TileLink 或 AMBA AXI 总线、用于连接多处理器板和机箱的 PCIe 或以太网,以及用于访问数据中心的 Wifi/5G/Internet 路由器。
使用虚拟原型的第三个研究是计算。这可以建模为处理器内核、多处理器、加速器、FPGA、多重累加和模拟处理。最后部分是传感器、网络、数学运算、DMA、自定义逻辑、仲裁器、调度程序和控制函数的接口。
此外,人工智能处理器和系统的架构探索具有挑战性,因为它在硬件的全部功能上应用了数据密集型任务图。
模型构建
在Mirabilis,我们使用VisualSim进行AI应用程序的架构探索。VisualSim 的用户在图形离散事件仿真平台中非常快速地组装虚拟原型,该平台具有大型 AI 硬件和软件建模组件库。该原型可用于进行时序、吞吐量、功耗和服务质量权衡。提供超过20个AI处理器和嵌入式系统模板,以加速新AI应用程序的开发。
为 AI 系统中的权衡生成的报告包括响应时间、吞吐量、缓冲区占用、平均功耗、能耗和资源效率。
ADAS模型构建
首先,让我们考虑自动驾驶(ADAS)应用程序,这是图1中的一种AI部署形式。ADAS应用程序与计算机或电子控制单元(ECU)和网络上的许多应用程序共存。ADAS任务还依赖于现有系统的传感器和执行器才能正常运行。
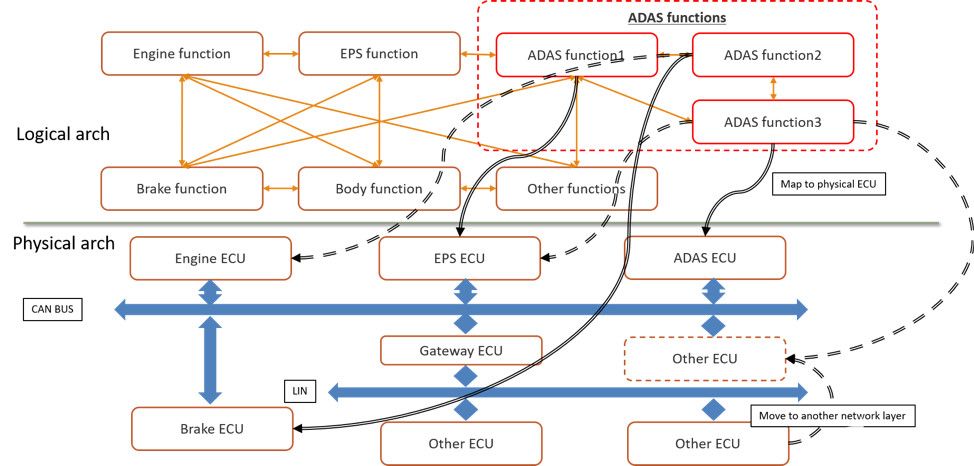
图1.汽车设计中 AI 应用的逻辑到物理架构
早期架构权衡可以测试和评估假设,以快速识别瓶颈,并优化规范以满足时序、吞吐量、功耗和功能要求。在图 1 中,您将看到架构模型需要硬件、网络、应用任务、传感器、衰减器和流量激励来了解整个系统的运行情况。图 2 显示了映射到物理架构的此 ADAS 逻辑架构的实现。
架构模型的一个很好的功能是能够分离设计的所有部分,以便可以研究单个操作的性能。在图 2 中,您会注意到单独列出了现有任务、带有 ECU 的网络、传感器生成和 ADAS 逻辑任务组织。ADAS任务图中的每个功能都映射到ECU。
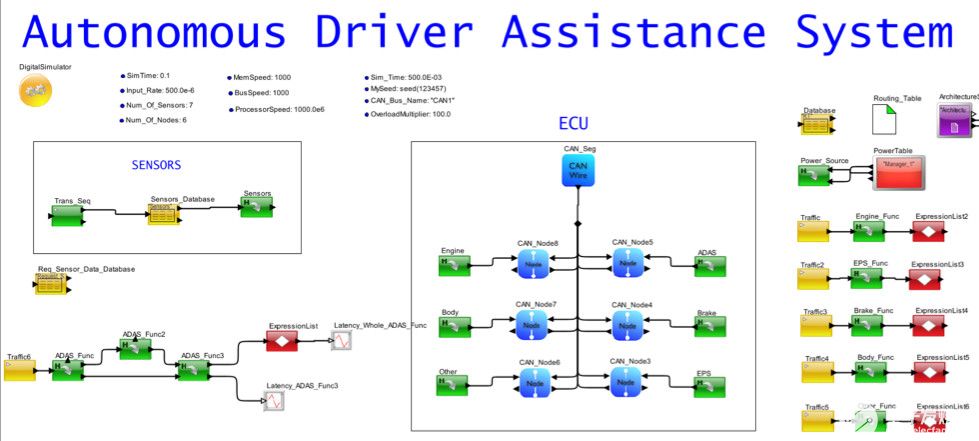
图2.将ADAS映射到ECU网络的汽车系统的系统模型
自动辅助系统分析
仿真图2中的ADAS模型时,您可以获得各种报告。图3显示了完成ADAS任务的延迟以及电池为此任务散发的相关热量。其他感兴趣的图可以是测量的功率、网络吞吐量、电池消耗、CPU 利用率和缓冲区占用。
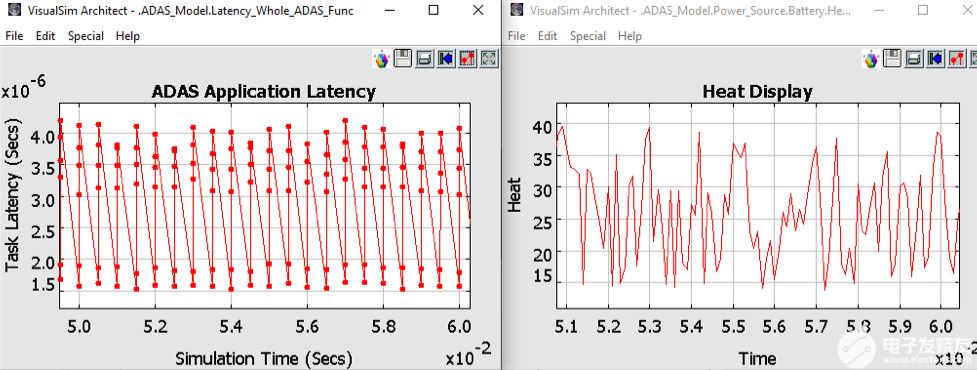
图3.来自 ADAS 架构模型的分析报告
处理器模型构建
AI 处理器和系统的设计人员对应用程序类型、训练与推理、成本点、功耗和大小限制进行实验。例如,设计人员可以将子网络分配给流水线阶段,权衡深度神经网络 (DNN) 与传统机器学习算法,测量 GPU、TPU、AI 处理器、FPGA 和传统处理器上的算法性能,评估在芯片上融合计算和内存的优势,计算类似于人脑功能的模拟技术的功耗影响,以及构建具有针对单个应用的部分功能集的 SoC。
从PowerPoint到新AI处理器的第一个原型的时间表非常短,第一个生产样品不能有任何瓶颈或错误。因此,建模成为强制性的。
图 4 显示了 Google 张量处理器的内部视图。框图已转换为图 5 中的架构模型。处理器通过 PCIe 接口接收来自主机的请求。MM、TG2、TG3 和 TG4 是来自独立主机的不同请求流。权重存储在片外 DDR3 中,并调用到权重 FIFO 中。到达的请求在统一本地缓冲区中存储和更新,并发送到矩阵动车单元进行处理。通过 AI 管道处理请求后,它将返回到统一缓冲区以响应主机。
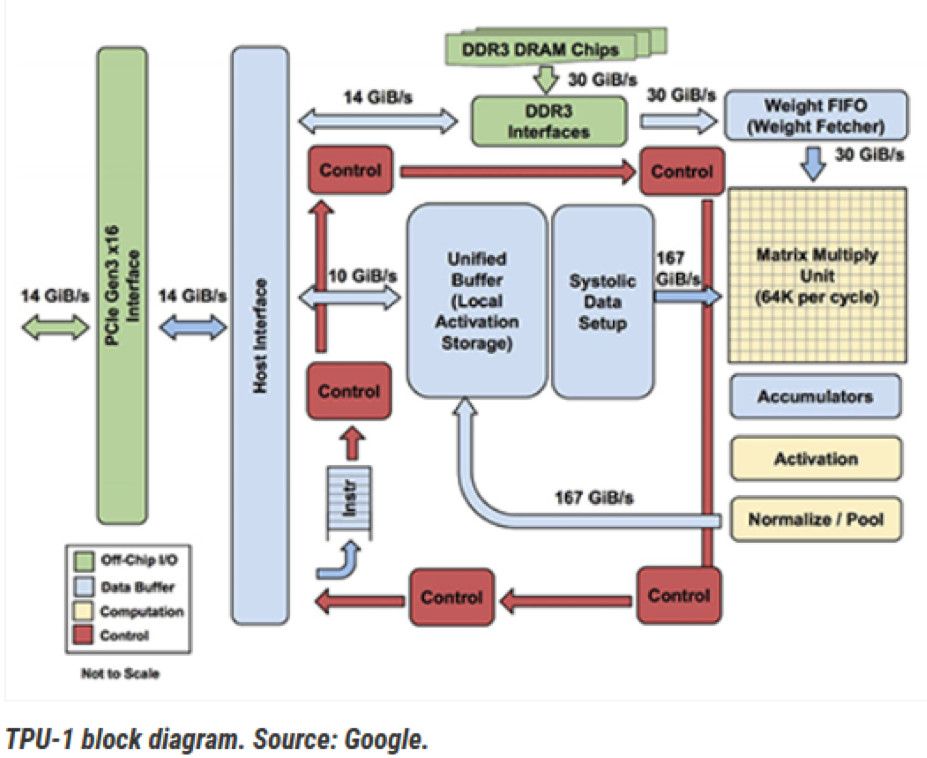
图4.来自谷歌的 TPU-1
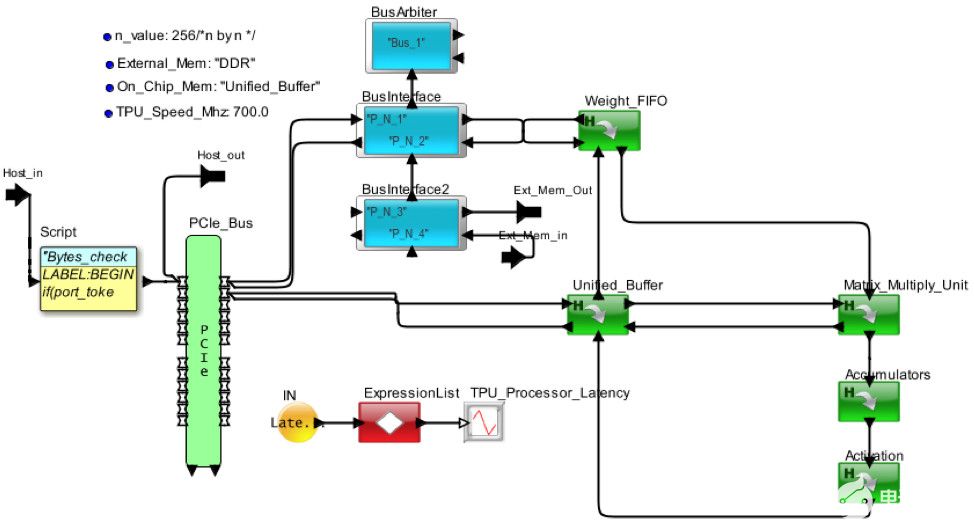
图5.AI 硬件架构的 VisualSim 模型的俯视图
处理器模型分析
在图 6 中,您可以查看片外 DDR3 中的延迟和反向传播权重管理。延迟是从主机发送请求到接收响应的时间。您将看到TG3和TG4能够分别在200 us和350 us之前保持低延迟。MM和TG2在仿真早期开始缓冲。由于存在相当大的缓冲,并且这组流量配置文件的延迟正在增加,因此当前的 TPU 配置不足以处理负载和处理。TG3和TG4的优先级较高,有助于维持更长的运营时间。
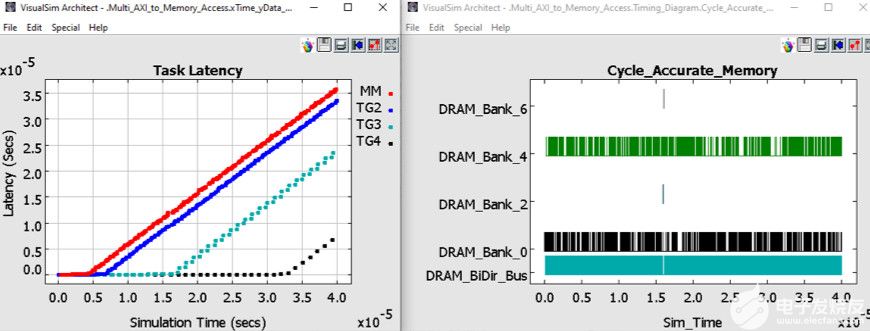
图6.架构探索权衡的统计信息
汽车设计施工
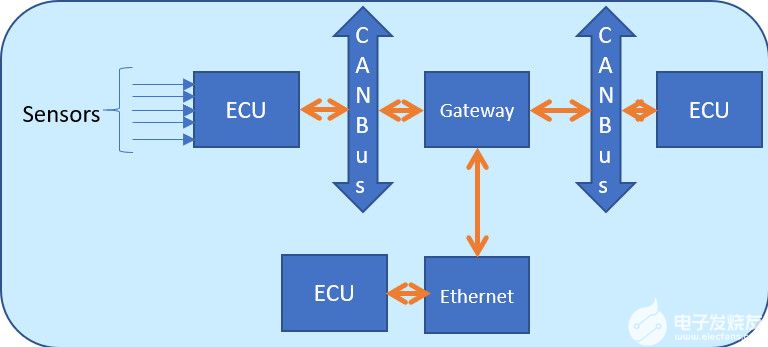
图7.带有CAN总线、传感器和ECU的汽车网络
当今的汽车设计融合了许多安全和自动驾驶功能,需要大量的机器学习和推理。可用的时间表将决定处理是在ECU完成还是发送到数据中心。例如,可以在本地完成制动决策,同时可以发送更改空调温度进行远程处理。两者都需要基于输入传感器和摄像头的一定数量的人工智能。
图 7 是包含 ECU、CAN-FD、以太网和网关的网络框图。
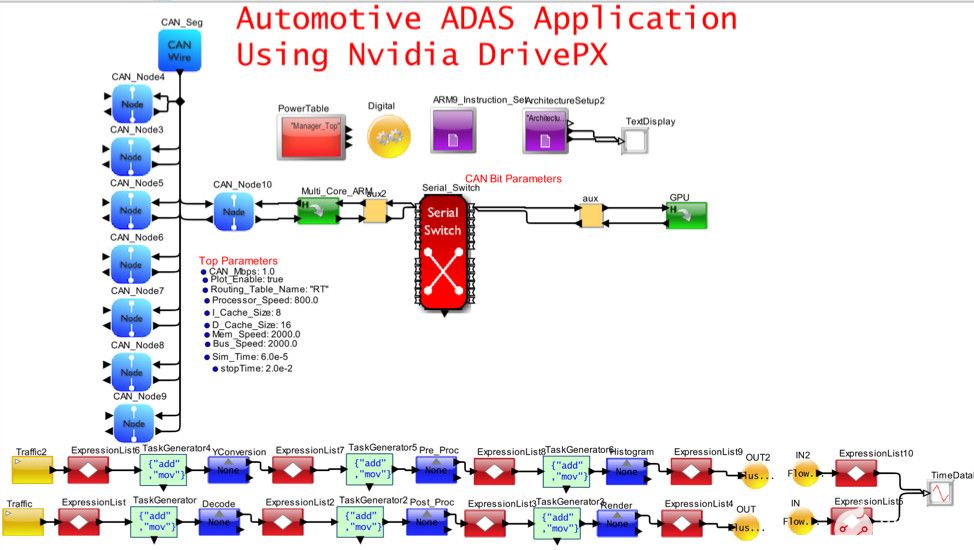
图8.自动驾驶和E/E架构的可视化模拟模型
图 8 捕获了图 7 的一部分,该部分将 CAN-FD 网络与包含多个 ARM 内核和一个 GPU 的高性能 Nvidia DrivePX 集成在一起。以太网/TSN/AVB 和网关已从模型中删除,以简化视图。在此模型中,重点是了解 SoC 的内部行为。该应用程序是由车辆上的摄像头传感器触发的 MPEG 视频捕获、处理和渲染。
汽车设计分析
图 9 显示了 AMBA 总线和 DDR3 内存的统计信息。您可以查看工作负载在多个主节点之间的分布情况。可以评估应用程序管道的瓶颈,确定最高周期时间任务、内存使用情况配置文件以及每个任务的延迟。
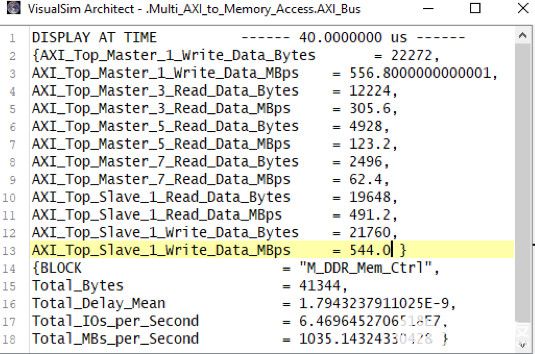
图9.总线和内存活动报告
用例和流量模式应用于组装为硬件、RTOS 和网络组合的架构模型。定期交通状况用于对雷达、激光雷达和摄像头进行建模,而用例可以是自动驾驶、聊天机器人、搜索、学习、推理、大数据操作、图像识别和疾病检测。用例和流量可以根据输入速率、数据大小、处理时间、优先级、依赖性、先决条件、反向传播循环、系数、任务图和内存访问而变化。通过改变属性在系统模型上模拟用例。这会导致生成各种统计信息和绘图,包括缓存命中率、管道利用率、拒绝的请求数、每条指令或任务的瓦数、吞吐量、缓冲区占用和状态图。
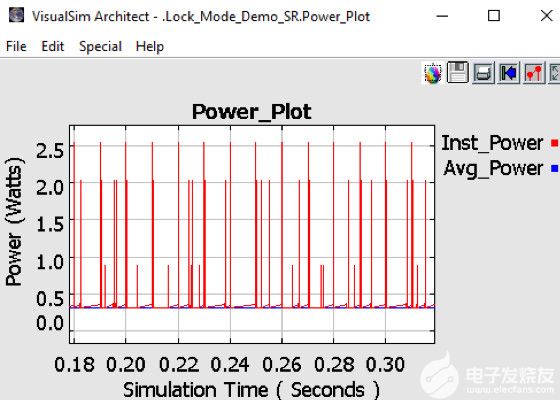
图 10.实时测量 AI 处理器的功耗
图10显示了系统和芯片的功耗。除了散热、电池充电消耗率和电池生命周期变化外,该模型还可以捕获动态功率变化。该模型绘制了每个器件的状态活动、相关的瞬时尖峰和系统的平均功耗。获得有关功耗的早期反馈有助于热和机械团队设计外壳和冷却方法。大多数机箱对每个板都有最大功率限制。这种早期的功耗信息可用于执行架构与性能的权衡,从而寻找降低功耗的方法。
进一步的勘探方案
以下是一些其他示例,重点介绍了如何使用 AI 体系结构模型和分析。
1. 自动驾驶系统,配备360度激光扫描仪、立体摄像头、鱼眼摄像头、毫米波雷达、声纳或激光雷达,通过网关连接的多个IEEE802.1Q网络上的20个ECU连接。原型用于测试 OEM 硬件配置的功能包,以确定硬件和网络要求。主动安全措施的响应时间是主要标准。
2. 用于学习和推理任务的人工智能处理器使用片上网络主干网定义,该骨干网由 32 个内核、32 个加速器、4 个 HBM2.0、8 个 DDR5、多个 DMA 和全缓存一致性组成。该模型试验了 RISC-V、ARM Z1 和专有内核的变体。实现的目标是在链路上实现 40Gbps,同时保持低路由器频率并重新训练网络路由。
3. 需要 32 层深度神经网络才能将内存从 40GB 增加到 7GB 以下。数据吞吐量和响应时间未更改。该模型是使用行为的功能流程图设置的,其中包含处理和反向传播的内存访问。对于不同的数据大小和任务图,该模型确定了数据的丢弃量以及各种片外DRAM大小和SSD存储选项。任务图通过任意数量的图和多个输入和输出而变化。
4. 通用SoC,使用ARM处理器和AXI总线进行低成本AI处理。目标是获得最低的每瓦功率,从而最大化内存带宽。乘法累加函数被卸载到矢量指令,加密到IP核,自定义算法卸载到加速器。构建该模型的明确目的是评估不同的缓存内存层次结构,以提高命中率和总线拓扑以减少延迟。
5. 模数AI处理器需要对功耗进行彻底分析,并对所达到的吞吐量进行准确分析。在该模型中,非线性控制在离散事件模拟器中建模为一系列线性函数,以加快仿真时间。在本例中,对功能进行了测试,以检查行为并衡量真正的节能效果。
审核编辑:郭婷
-
ARM发布两款针对移动终端的AI芯片架构:物体检测和机器学习处理器2018-02-23 8122
-
Alif Semiconductor宣布推出先进的BLE和Matter无线微控制器,搭载适用于AI/ML工作负载的神经网络协同处理器2024-04-18 1689
-
端侧 AI 音频处理器:集成音频处理与 AI 计算能力的创新芯片2025-02-16 4022
-
瑞芯微SOC智能视觉AI处理器2025-12-19 1119
-
多核处理器的优点2019-06-20 5175
-
浅谈ARM处理器架构2020-08-18 4340
-
ARM公版架构 真的是麒麟处理器的槽点吗?2017-01-04 3905
-
主流AI处理器的制程、架构和市场发展对比分析2018-02-09 11271
-
音频处理器的架构_音频处理器的延时怎么调整2020-04-09 6164
-
处理器架构探索的混合创新2022-06-01 1900
-
AI/ML应用和处理器的架构探索2022-07-08 1796
-
用于处理器架构探索的混合创新2022-11-21 1158
-
处理器架构与指令集2023-04-26 9020
-
简单认识MIPS架构处理器2023-11-29 4225
-
联发科或将与英伟达开发Arm架构AI PC处理器2024-05-13 1404
全部0条评论

快来发表一下你的评论吧 !
