

复杂系统和复杂计算概述
描述
编者按
算力网络的概念逐渐深入人心,算力网络的愿景是“让算力无处不在,唾手可得”。这个愿景非常的令人向往。
在本篇文章中,我们提到两个概念:复杂系统和复杂计算。复杂系统指的是多个系统融合而成的宏系统;复杂计算,则是复杂系统的计算范式。
1 从宏观算力讲起
什么是性能?什么是算力?这两个概念是统一的,性能是微观的概念,而算力是宏观的概念。
性能和算力的关系,如下面这个简化公式:总算力 = 芯片性能 x 芯片数量 x 算力利用率。
这三个参数,也对应了算力优化的微观、中观和宏观的三个层次:
微观层次,即单芯片的性能,主要是通过工艺进步、Chiplet封装以及架构和微架构创新来提升。
中观层次,芯片要能够支持大规模落地。这里讲一个反面案例,由于AI的算法众多并且快速多变,AI芯片落地存在困难,难以大规模量产。无法量产的芯片,对宏观算力的提升,没有多大意义。
最后是宏观层次,算力的利用率。我们有了这么多芯片,但如果是孤岛,有的系统性能不够用,而大部分系统的算力又严重浪费,那就没有充分利用这些算力资源。有过统计,云计算,算力利用率通常在6%左右,要是有办法,把算力资源利用率提升到90%以上,这将是非常巨大的价值。要提升利用率,在芯片层面也要做很多的工作,宏观上也要做很多的工作。
对宏观算力影响最大最直接的,就是算力的利用率。需要把宏观的遍布在云网边端的所有计算的资源,连成一个宏大的资源池,统一调度。
2 从虚拟化到资源池化
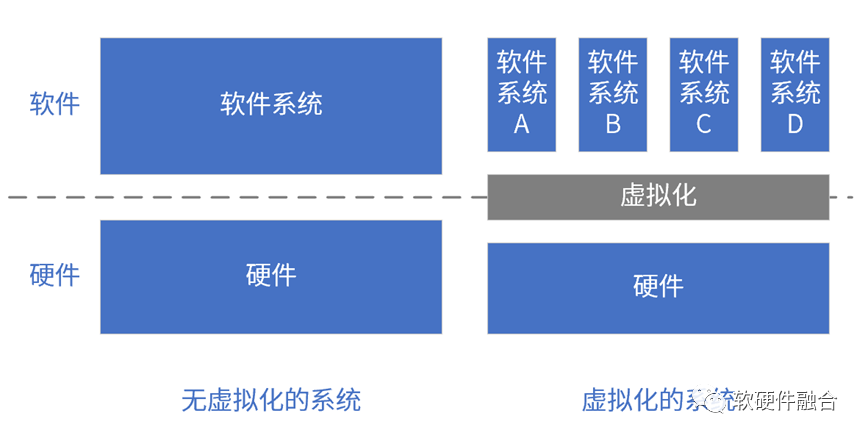
按照虚拟化层次,虚拟化分为计算机虚拟化、操作系统虚拟化和函数虚拟化。综合这三类虚拟化的共性价值:
虚拟化按照一定时间或空间的粒度,把资源切分和组合;
虚拟化屏蔽架构/接口差异性,为上层软件提供一致性的硬件/软件;
虚拟化为上层软件系统提供多种下层资源不同比例组合的运行平台;
上层软件系统和下层硬件/软件系统解耦,上层软件系统作为运行实体,可以创建/销毁、运行/挂起、复制、迁移等;
多系统隔离/共存:资源共享的同时,数据隔离、性能隔离、故障隔离、安全隔离;
提升系统灵活性,提升资源利用率,提升硬件负载均衡性,提升软件高可用性。
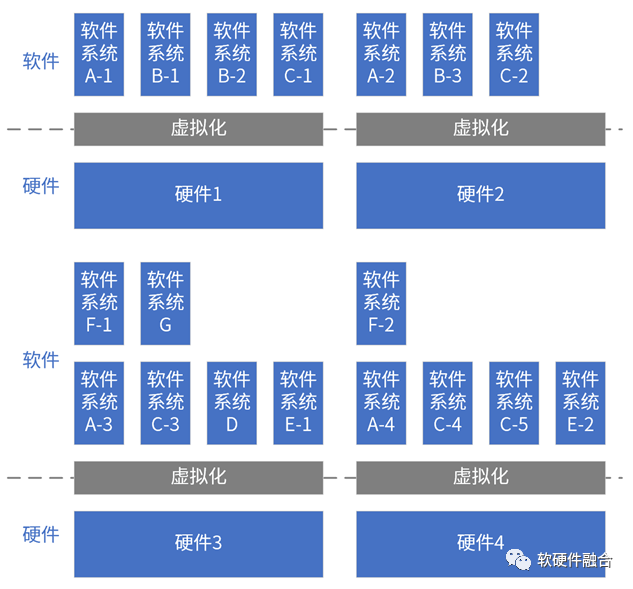
以VM为例,假设有100台服务器,一台物理的服务器虚拟出10台VM,1000个逻辑的(或虚拟的)VM分属于50个不同大小的私有集群(通过VPC)。
多集群多系统动态共存体现在:
硬件集群:供系统调度的一组硬件设备的集合,可以从数台到数千台,甚至百万台的规模;
软件多系统:通过虚拟化机制,实现单个硬件上的多个不同规格的软件系统共存;
软件多系统集群:一组软件系统组成软件集群,多组软件集群混合交叉部署在一组硬件集群之上;
动态性:宏观地看,这些硬件集群和软件集群的配置一直处于频繁的变更中。
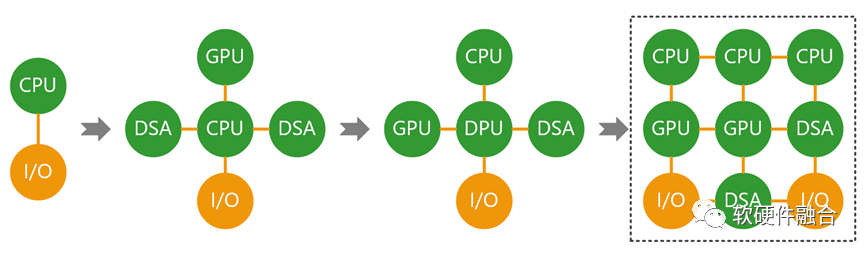
很多加速芯片,专注于特定领域:只考虑局部,而没有考虑全局。
数据中心硬件是预配置的,购买时不确定运行什么软件;以不变应万变,优先考虑足够通用的、综合性的硬件。
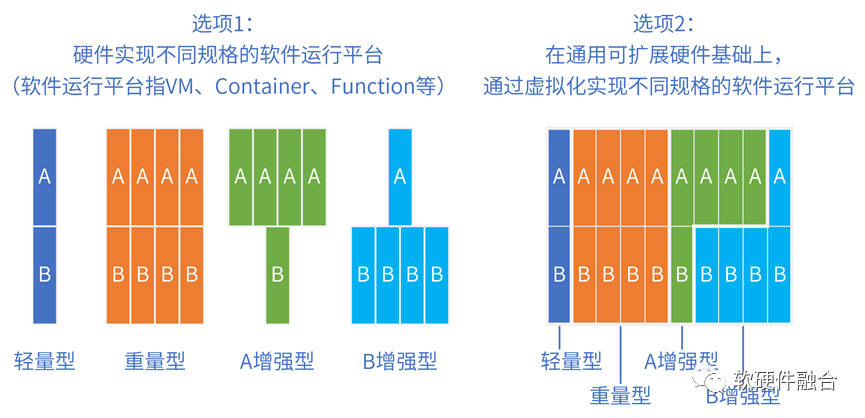
此外,站在云计算公司的运营管理视角,需要尽可能地减少硬件的型号,最理想情况是:硬件规格是一致性的,只有一种型号的硬件,然后通过虚拟化机制实现“软件运行平台”的差异性。
从虚拟化到资源池化:
虚拟化是池化的基础:虚拟化侧重于硬件个体,池化侧重宏观整体;
虚拟化:把资源切分成合适的粒度,再通过虚拟化实例的创建和迁移实现资源的调度;
资源池化的微观机制是虚拟化,通过云操作系统堆栈,甚至跨云网边端的操作系统堆栈,实现虚拟化资源的统一管理、使用和回收等;
微观的虚拟化实现了软件运行平台的高可用,宏观的资源池化实现硬件资源的高利用率;
可被池化的(显式可见的)底层硬件资源包括CPU、内存、GPU/DSA等加速器、存储等。
3 复杂系统的宏观特征
我们先了解一下,复杂计算面向的系统具有哪些宏观的特征呢?
第一,系统要干什么,不知道。传统我们做芯片和系统设计,通常是要去理解场景,然后根据场景的需求来设计我们的芯片和系统。现在的挑战是,场景的需求是完全不确定的,不但芯片公司不了解,客户自己也“不了解”。未来,需要“无的放矢”。
第二,由于系统要什么不清楚,也因此系统要包罗万象,啥都能干。
第三,系统干任何事情,都要足够专业而高效。我们通常说“专业的人做专业的事”。言下之意就是说:专业的人只能做本专业的事情,而通才则意味着在每个领域都不够高效。那么复杂计算的系统,则要求:既通又专(啥都能干,干啥都高效)。
第四,系统要“三头六臂”,同时能做好千千万不同领域和场景、不同客户诉求的工作。
第五,系统提供的算力等资源无处不在,唾手可得。在用户最需要的地方,最需要的时刻,随叫随到;并且,以最合适的形态,最合适的方式出现;还给用户创造更多的价值,给用户更好的体验。
最后,关键的一点,系统要持续演进,适应用户需求的快速变化。
当然,这并不是说单个芯片的能力能够支撑如此强大的系统。而是要发挥数以千计万计的个体芯片协同甚至融合的能力,来共同支撑宏观大系统的更强大的能力。
4 复杂计算的定义
复杂计算的定义:①基于一组硬件集群,②运行多系统集群的、 ③动态的、 ④交叉混合计算。展开说明:
单个硬件支持多个不同规格系统的计算;
单个硬件集群支持多个系统集群的计算,并且系统集群交叉混布;
数以万计甚至百万级的计算设备规模,完全动态的、非常频繁的软硬件配置变更;
硬件需要足够的一致性(尽可能少的型号和规格),在一致性硬件基础上实现软件平台的差异性;
尽可能满足所有场景的、足够通用的、综合性的计算平台和系统。
5 复杂计算的场景
5.1 从云计算来,到云网边端去
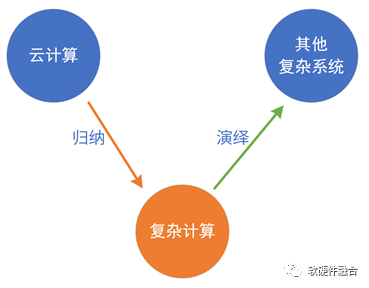
云计算行业的朋友,看到复杂系统和复杂计算的概念,肯定会说,这不就是云计算吗?没错,复杂计算的确是从云计算的基础特征中提取出来的。
云计算的这些基础的特征,在边缘计算、软件定义的网络计算、超级终端计算等场景,都有类似的特征存在。
我们试图归纳总结这些特征,把它提炼成复杂计算这个概念,用这个概念:
从个体视角看,指导底层的芯片的功能定义和系统架构的设计;
从宏观视角看,指导宏观算力资源和其他相关资源的统筹,为全局资源的池化、编排等提供能力支持,并且进一步提升宏观算力的利用率。
5.2 云计算场景
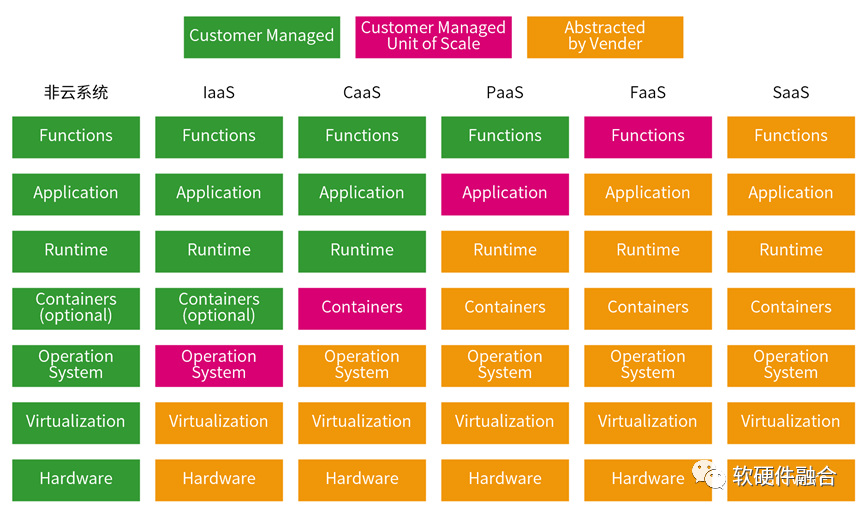
云计算主要是由IaaS、PaaS和SaaS组成的分层服务体系。云计算的各种XaaS服务,本质上是系统堆栈逐步由云运营商接管的过程。用户只需要关心自己最核心的应用/功能即可。
5.3 边缘计算场景
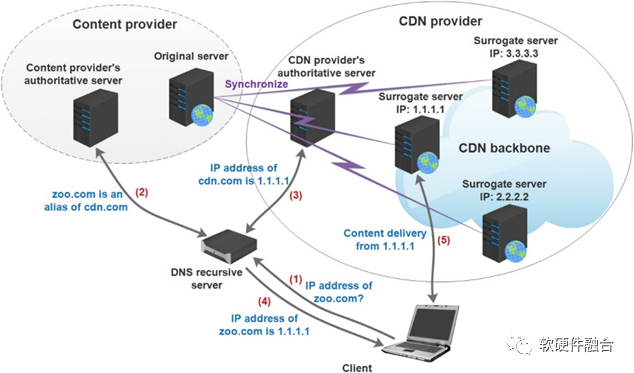
CDN(Content Delivery Network,内容分发网络)是一种利用最靠近用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,提供高性能、可扩展性及低成本的网络内容传递服务。
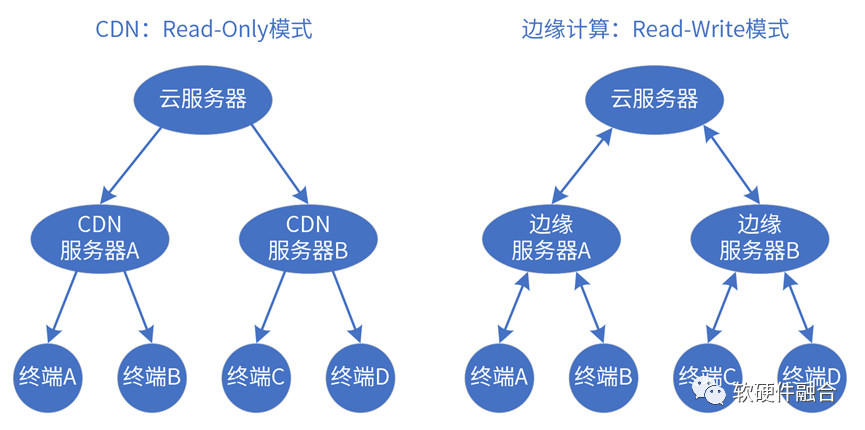
边缘计算和CDN有很多相似之处,均通过DNS修改调用地址,提供类似缓存的机制,做到客户端无感。
CDN和边缘计算的本质区别在于:
CDN是只读模式,不管是服务器推送静态内容或者动态内容;
边缘计算同样需要支持多租户多系统运行,其系统堆栈跟云端有一定相似(可复用)之处。
5.4 超级终端场景
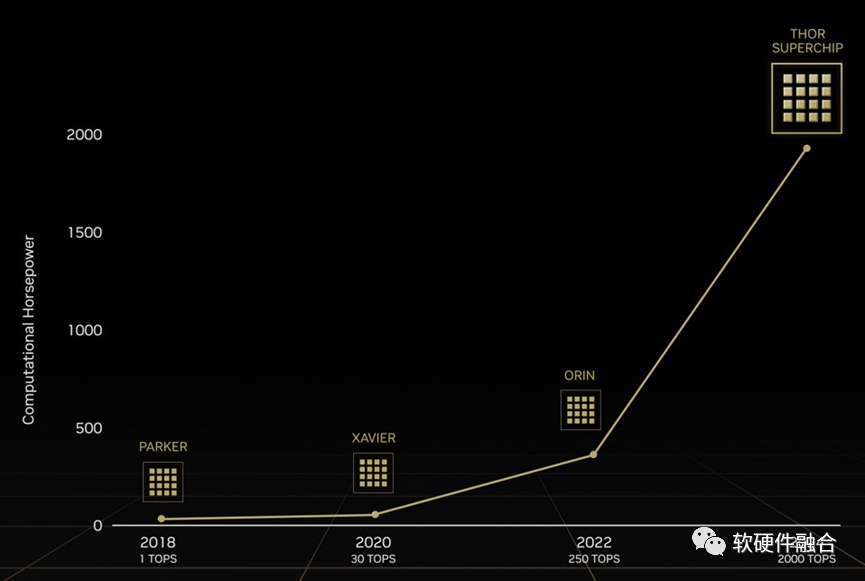
北京时间2022年9月21凌晨,NVIDIA GTC 2022秋季发布会上,CEO黄仁勋发布了其2024年将推出的自动驾驶芯片。因为其2000TFLOPS的性能过于强大,英伟达索性直接把它全新命名为Thor,代替了之前1000TOPS的Altan。

Thor SoC能够实现多域计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖这些分布式的ECU/DCU。
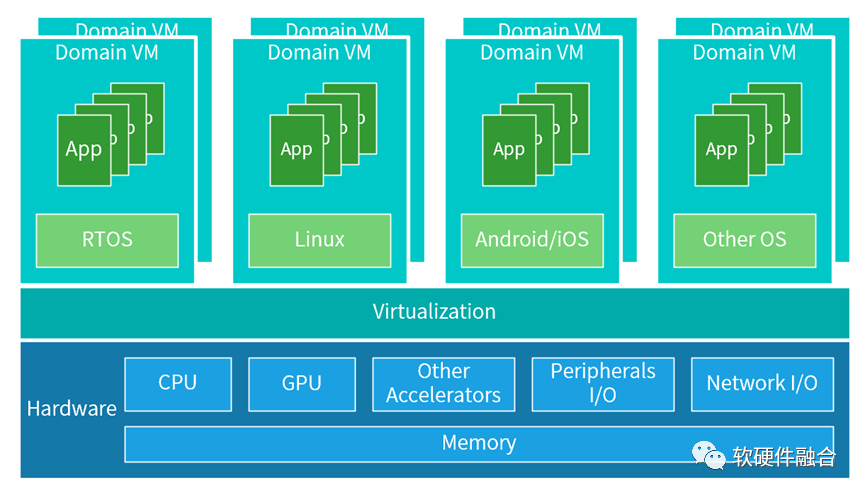
超级终端与传统终端最大的区别在于:支持虚拟化,支持多系统运行,支持微服务。手机、平板、个人电脑等传统AP是一个系统:部署好OS,上面运行各种应用,软件附属于硬件而存在。而自动驾驶等超级终端,需要通过虚拟化将硬件切分成不同规格,供不同形态的多个系统运行,并且各个系统之间需要做到环境、应用、数据、性能、故障、安全等方面的隔离。
自动驾驶汽车,通常需要支持五个主要的功能域,包括:动力域、车身域、自动驾驶域、底盘域、信息娱乐域,每个域会占用一个或多个VM。
5.5 未来,更多的场景需要复杂计算
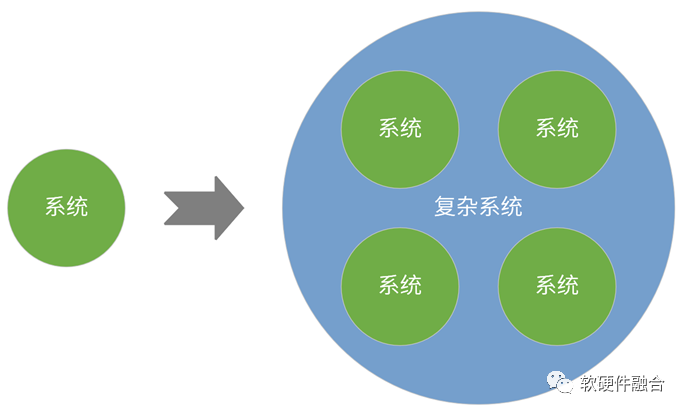
芯片工艺越来越先进,能支撑的系统规模越来越大;上层的软件应用,层出不穷,已有的应用持续快速演进。系统从单个系统变成了多个系统混合甚至融合的复杂系统。
系统越来越复杂,支持系统计算的硬件也越来越复杂;复杂的系统越多,需要复杂计算覆盖的场景也就越多。
6 复杂计算的挑战
底层计算的资源主要是CPU、内存、网络和存储等I/O,以及GPU、DSA等加速器。复杂计算的核心挑战在于:如何把种类繁多并且架构/接口不一致的资源汇集成池。
个体的硬件,需要支持非常好的扩展性。个体硬件包括各种异构的处理器资源,可以形成小的资源池;并且支持数以万计的个体资源连成一片,形成更大的资源池。
硬件个体需要支持系统的连接和融合,根据程度的高低,分为四个阶段:
阶段一,孤岛。所有设备各自独立的工作;
阶段二,互联。把设备连到一起,设备和设备之间可以通信;
阶段三,协同。C/S架构是典型的协同;有了协同,也就有了云网边端。
阶段四,融合。协同通常是静态的,随着时间推移,初始任务划分不一定能适应系统的发展;融合代表着动态以及更多自适应性;协同代表着多个系统的协同,而融合代表了多个系统融合成一个大系统。
站在宏观大系统的视角,云服务器、边缘服务器、终端设备,以及网络设备,都是一致性的硬件。通过软件编排,选择尽可能最优的资源,组成最适合软件运行的逻辑平台。
算力芯片是水滴,算力网络是海洋。我们要思考的是,这滴水如何设计的更好,更好地融入到这片海洋,让海洋更加浩瀚宏大。
审核编辑:刘清
-
复杂电磁环境构建与测试软件系统2025-04-29 847
-
一文详解复杂系统和复杂计算2022-11-24 1841
-
CISC复杂指令集2021-12-14 1207
-
用什么方法去计算复杂电路?2021-11-09 1352
-
MSGQ模块是如何简化复杂的DSP设计的2021-08-06 1512
-
时间复杂度是指什么2021-07-22 1926
-
CAD入门学习教程:如何快速计算复杂图形面积?2019-11-21 1751
-
请问怎么用单片机进行复杂计算?2018-07-13 876
-
触觉的发展及我们与复杂系统的接触2016-08-08 1064
-
Labview之复杂公式计算2016-04-19 848
-
复杂电磁环境系统的效能评估2011-05-12 1117
-
基于Agent的复杂系统建模与仿真2011-05-05 1241
-
复杂数字逻辑系统的Verilog2010-11-01 440
-
复杂目标双站图形电磁计算2009-10-21 1735
全部0条评论

快来发表一下你的评论吧 !
