

mW范围内的机器视觉使物联网端点推理变得实用
描述
物联网端点位于嵌入式视觉的前沿。而且,与其他前沿领域一样,也存在挑战,其中最重要的是电源效率。
机器视觉已经迅速在世界上找到了自己的位置。从树上看到和摘下橙子。注视检测针对危险的无意识驾驶员。在工厂车间内移动的工业机器人依靠它进行安全的障碍物检测。
物联网端点位于嵌入式视觉的前沿。而且,与其他前沿领域一样,也存在挑战,其中最重要的是电源效率。是否可以在不超出节点功率容量的情况下在极端边缘进行推理?
这个问题值得考虑。这是因为在边缘进行推理可以避免不分青红皂白地将数据(其中只有一部分是可操作的)传输到云进行分析。这样可以降低存储成本。此外,访问云会损害延迟并抑制实时功能。传输数据是易受攻击的数据,因此最好进行端点处理。这对于降低支付给网络运营商的成本也是有利的。
全新的 SoC 架构方法
然而,对于所有这些好处,一个主要的绊脚石已经存在。使用传统微控制器的设备的功耗限制阻碍了神经网络在极端边缘的推理。
传统的微控制器(MCU)性能无法满足周期密集型操作。方法唤醒解决方案可能依赖于机器视觉进行对象分类,这反过来又需要卷积神经网络 (CNN) 执行矩阵乘法运算,这些运算转化为数百万乘法累加 (MAC) 计算(图 1)。

图1.到目前为止,微控制器不具备承担大容量乘法累加(MAC)的效率的问题一直是一个绊脚石。
MCU存在各种各样的神经网络。但是,这些未能作为生产就绪型解决方案流行起来,因为所需的性能无法超越电源障碍。
克服功耗-性能困境是为什么采用全新方法处理处理器角色和 SoC 架构的解决方案是有意义的。采用这种新方法需要了解 IoT 终结点需要处理三个工作负载才能成功推理。一个是程序性的,一个是数字信号处理,一个是执行大量MAC操作的。满足每个工作负载独特需求的一种方法是在 SoC 中组合一个用于信号处理和机器学习的双 MAC 16 位 DSP,以及一个用于程序负载的 Arm Cortex-M CPU。
这种混合多核架构充分利用了 DSP 双存储器组、零环路开销和复杂地址生成。有了它,可以处理工作负载的任何组合:例如,网络堆栈、RTOS、数字滤波器、时频转换、RNN、CNN 以及传统的类似人工智能的搜索、决策树和线性回归。图 2 显示了当 DSP 架构优势发挥作用时,神经网络计算性能如何提高 2 倍甚至 3 倍。
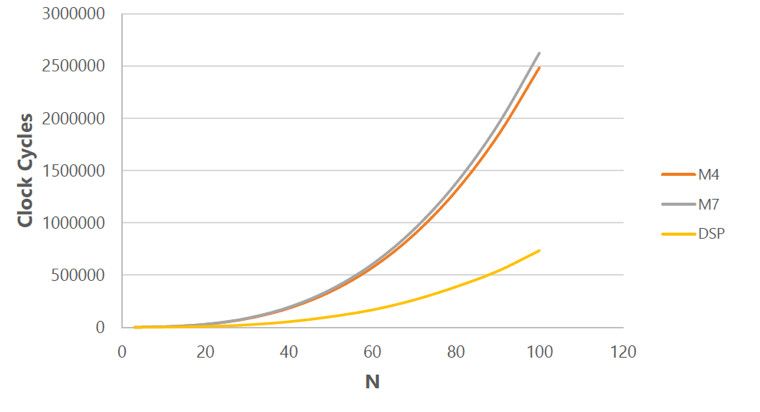
图2.矩阵乘法 (NxN) 基准测试。
仅靠架构更改是不够的
无论是对于嵌入式视觉系统还是依赖于显著提高神经网络效率的任何其他系统,实施混合多核架构都很重要。但是,当目标是将功耗降至mW范围时,必须做更多的工作。认识到这一需求,Eta Compute获得了连续电压和频率缩放(CVFS)的专利。
CVFS克服了动态电压频率调节(DVFS)遇到的问题。DVFS确实利用了降低功耗的选项,即降低电压。缺点是行使此选项时最大频率会降低。这个问题将DVFS的有效性锁定在一个狭窄的范围内 - 一个由严格限制数量的预定义离散电压电平定义并限制在几百mV的电压范围内。
相比之下,为了在最有效的电压下实现一致的SoC操作,CVFS使用自定时逻辑。通过自定时逻辑,每个器件都可以连续自动调整电压和频率。CVFS比DVFS更有效,也比亚阈值设计更容易实施,CVFS在另一个重要方面也与这些不同。关键区别在于,上面提到的混合多核架构使CVFS已经做的好事成倍增加。
处于最前沿的生产级
最边缘的终结点(例如用于人员检测的终结点)具有特定需求。虽然已发布的神经网络可供任何人用于这些物联网端点,但它们并没有优先针对这些需求。使用领先的设计技术优化这些网络可以解决这个问题。
除了使用先进的设计方法外,我们在 Eta Compute 采用的神经网络优化方法以生产级神经传感器处理器 ECM3532 为中心(图 3)。它融合了混合多核架构和 CVFS 技术的所有优势。
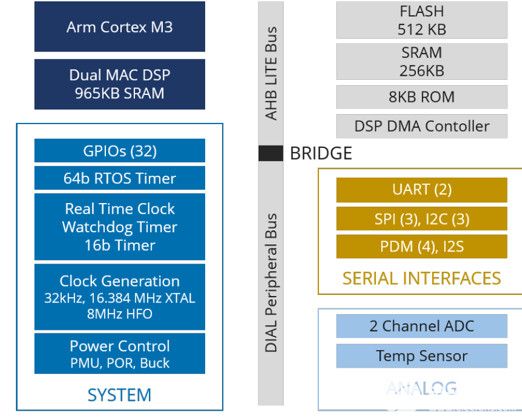
图3.Eta Compute ECM3532神经传感器处理器的混合多核架构将Arm Cortex-M3处理器、恩智浦CoolFlux DSP、512KB闪存、352KBSRAM和支持外设集成在SoC中,可实现mW范围内最边缘的推理。
获得的知识
如图4所示的测试结果显示,为了将深度学习引入嵌入式视觉系统,电力成本不必上升到不可接受的水平。虽然没有一根魔杖可以为高功耗的神经网络供电,但将MCU功耗效率和DSP优势与网络优化相结合的方法可以帮助应用避免仅依赖云计算导致的安全性、延迟和低效率问题。
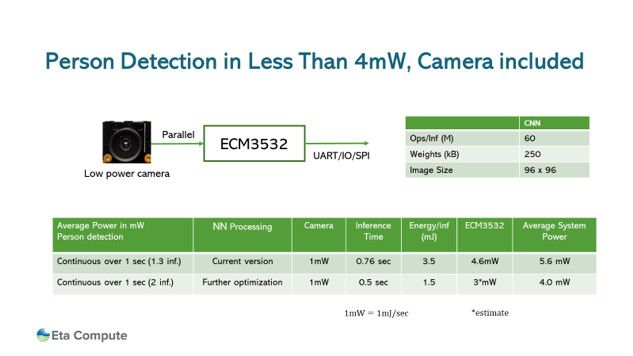
图4.在对人员检测模型的测试中,包括相机在内的平均系统功耗为5.6mW。对于此测试,速率为每秒 1.3 个审核编辑:郭婷
-
物联网的应用范围有哪些?2025-06-16 2243
-
机器视觉的镜头选择2012-10-22 3327
-
机器视觉在工业自动化领域的前景应用解析2014-03-31 3723
-
是什么让物联网卡变得如此火?2018-04-04 9815
-
超低功耗FPGA解决方案助力机器学习2018-05-23 6818
-
物联网传感解决方案更简单安全2018-08-29 2712
-
物联网传感的更多可能性2019-03-13 2463
-
物联网是解决“小”数据问题的关键2019-11-20 1512
-
深圳机器视觉光源选择有什么因素要考虑?2021-10-28 917
-
MCU是怎么为物联网端点设备提高安全性的?2023-10-17 720
-
机器视觉对于物联网来说是什么位置2020-01-07 1511
-
mW范围内的机器视觉使物联网端点推理变得实用2022-06-06 1701
-
mW范围内的机器视觉使物联网端点推理变得切实可行2022-10-14 1108
-
端点智能2022-12-02 1514
-
为什么接收机中频不能落入调谐范围内?2023-10-19 1526
全部0条评论

快来发表一下你的评论吧 !
