

利用设计网关的 IP 内核在 Xilinx VCK190 评估套件上加速人工智能应用
描述
Xilinx 的 Versal AI Core 系列器件旨在通过使用高计算效率的 ASIC 级 AI 计算引擎和灵活的可编程结构来解决 AI 推理的独特和最困难的问题,以构建具有加速器的 AI 应用程序,最大限度地提高任何给定的效率工作负载,同时提供低功耗和低延迟。
Versal AI Core 系列VCK190 评估套件采用VC1902 器件,该器件在产品组合中具有最佳的 AI 性能。该套件适用于需要高吞吐量 AI 推理和信号处理计算性能的设计。提供比当前服务器级 CPU 高 100 倍的计算能力并具有多种连接选项,使 VCK190 套件成为从云端到边缘的各种应用程序的理想评估和原型设计平台。

图 1:Xilinx Versal AI Core 系列 VCK190 评估套件。(图片来源:AMD 公司)
VCK190 评估套件的主要特性
板载 Versal AI 核心系列设备
配备 Versal ACAP XCVC1902 量产芯片
AI 和 DSP 引擎提供比当今服务器级 CPU 高 100 倍的计算性能
用于快速原型制作的预建合作伙伴参考设计
用于前沿应用程序开发的最新连接技术
内置 PCIe® Gen4 Hard IP,用于 NVMe SSD 和主机处理器等高性能设备接口
内置 100G EMAC Hard IP,用于高速 100G 网络接口
DDR4 和 LPDDR4 内存接口
共同优化的工具和调试方法
Vivado® ML、Vitis™ 统一软件平台、Vitis AI、用于 AI 推理应用程序开发的 AI Engine 工具
使用 Xilinx 的 Versal AI Core 系列器件实现 AI 接口加速
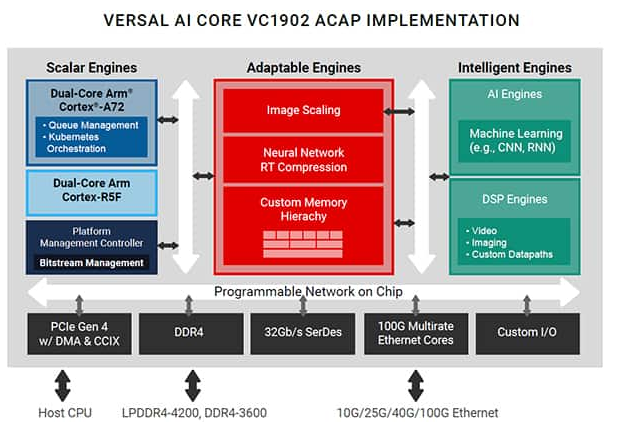
图 2:Xilinx Versal AI Core VC1902 ACAP 器件框图。(图片来源:AMD 公司)
Versal® AI Core 自适应计算加速平台 (ACAP) 是一款高度集成的多核异构设备,可在硬件和软件层面动态适应各种 AI 工作负载,是 AI 边缘计算应用或云加速器的理想选择牌。该平台集成了用于嵌入式计算的下一代标量引擎、用于硬件灵活性的自适应引擎,以及由 DSP 引擎和用于推理和信号处理的革命性 AI 引擎组成的智能引擎。其结果是一个适应性强的加速器,在 AI/ML 工作负载方面超越了传统 FPGA 和 GPU 的性能、延迟和能效。
Versal ACAP 平台亮点
自适应引擎:
自定义内存层次结构优化加速器内核的数据移动和管理
预处理和后处理功能,包括神经网络 RT 压缩和图像缩放
人工智能引擎 (DPU)
向量处理器的平铺阵列,XCVC1902 设备的性能高达 133 INT8 TOPS,称为深度学习处理单元或 DPU
适用于 CNN、RNN 和 MLP 等神经网络;硬件适用于优化不断发展的算法
标量引擎
四核 ARM 处理子系统,用于安全、电源和比特流管理的平台管理控制器
VCK190 AI推理性能
与当前服务器级 CPU 相比,VCK190 能够提供超过 100 倍的计算性能。下面是基于 C32B6 DPU Core 的 AI Engine 实现的性能示例,batch = 6。请参阅下表了解 VCK190 上各种神经网络样本的吞吐量性能(以帧/秒或 fps 为单位),DPU 在 1250 下运行兆赫兹。

表 1:VCK190 AI 推理性能示例。
查看 Vitis AI 库用户指南 (UG1354) r2.5.0 中的 VCK190 AI 性能的更多详细信息,网址为https://docs.xilinx.com/r/en-US/ug1354-xilinx-ai-sdk/VCK190-Evaluation-Board
Design Gateway 的 IP 核如何加速 AI 应用性能?
Design Gateway 的 IP 核旨在处理网络和数据存储协议,无需 CPU 干预。这使得完全卸载 CPU 系统的复杂协议处理成为理想之选,并使它们能够将大部分计算能力用于 AI 应用程序,包括 AI 推理、前后数据处理、用户界面、网络通信和数据存储访问,以实现最佳性能表现。
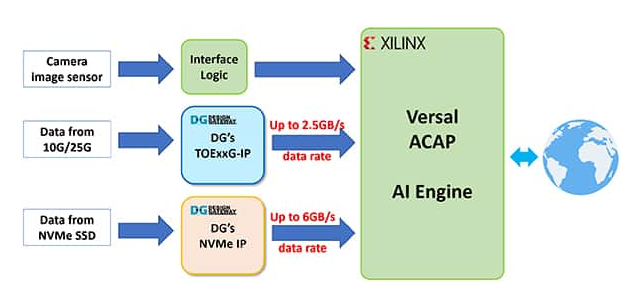
图 3:具有 Design Gateway 的 IP 核的 AI 应用示例框图。(图片来源:Design Gateway)
Design Gateway 的 TCP 卸载引擎 IP (TOExxG-IP) 性能
传统 CPU 系统处理超过 10GbE 或 25GbE 的高速、高吞吐量 TCP 数据流需要超过 50% 的 CPU 时间,这降低了 AI 应用程序的整体性能。根据 Xilinx 的 MPSoC Linux 系统上的 10G TCP 性能测试,10GbE TCP 传输期间的 CPU 使用率超过 50%,TCP 发送和接收数据传输速度可以达到 10GbE 速度的 40% 到 60% 或 400 MB/s 到600 兆字节/秒。
通过实施 Design Gateway 的TOExxG-IP 内核,通过 10GbE 和 25GbE 进行 TCP 传输的 CPU 使用率可以降低到几乎 0%,而以太网带宽利用率可以达到接近 100%。这允许通过纯硬件逻辑直接通过 TCP 网络发送和接收数据,并以最少的 CPU 使用率和尽可能低的延迟将数据馈送到 Versal AI 引擎。下面的图 4 显示了 TOExxG-IP 和 MPSoC Linux 系统之间的 CPU 使用率和 TCP 传输速度比较。
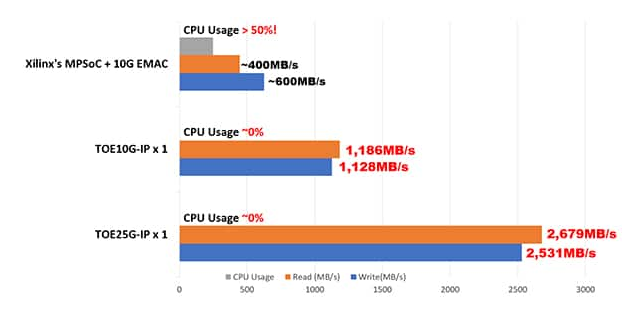
图 4:MPSoC Linux 系统和 Design Gateway 的 TOExxG-IP 内核的 10G/25G TCP 传输性能比较。(图片来源:Design Gateway)
Design Gateway 用于 Versal 器件的 TOExxG-IP
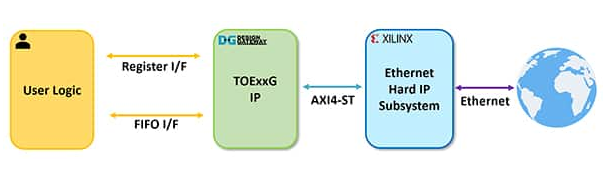
图 5:TOExxG-IP 系统概览。(图片来源:Design Gateway)
TOExxG-IP 内核实现了 TCP/IP 堆栈(在硬线逻辑中),并与 Xilinx 的 EMAC Hard IP 和以太网子系统模块连接,用于具有 10G/25G/100G 以太网速度的下层硬件接口。TOExxG-IP 的用户接口包括一个用于控制信号的寄存器接口和一个用于数据信号的 FIFO 接口。TOExxG-IP 旨在通过 AXI4-ST 接口与 Xilinx 的以太网子系统连接。用户界面的时钟频率取决于以太网接口速度(例如,156.625 MHz 或 322.266 MHz)。
TOExxG-IP 的特点
无需 CPU 即可实现完整的 TCP/IP 堆栈
支持一个会话与一个 TOExxG-IP
可以通过使用多个 TOExxG-IP 实例来实现多会话
支持服务器和客户端模式(被动/主动打开和关闭)
支持巨型帧
通过标准 FIFO 接口的简单数据接口
通过单端口 RAM 接口的简单控制接口
XCVC1902-VSVA2197-2MP-ES FPGA 设备上的 FPGA 资源使用情况如下表 2 所示。

表 2:Versal 设备的实施统计示例。
TOExxG-IP 的更多详细信息在其数据表中进行了描述,该数据表可通过以下链接从 Design Gateway 网站下载:
TOE10G-IP 内核 Xilinx 数据表
TOE25G-IP 内核 Xilinx 数据表
TOE100G-IP 内核 Xilinx 数据表
Design Gateway 的 NVMe 主机控制器 IP 性能
NVMe 存储接口速度与 PCIe Gen3 x4 或 PCIe Gen4 x4 的数据速率高达 32 Gbps 和 64 Gbps。这比 10GbE 以太网速度高三到六倍。CPU 处理复杂的 NVMe 存储协议以达到尽可能高的磁盘访问速度需要比 10GbE 以上的 TCP 协议更多的 CPU 时间。
Design Gateway 通过开发能够作为独立 NVMe 主机控制器运行的 NVMe IP 核解决了这个问题,能够在没有 CPU 的情况下直接与 NVMe SSD 通信。这实现了 NVMe PCIe Gen3 和 Gen4 SSD 访问的高效率和性能,从而简化了用户界面和标准功能,以便在无需了解 NVMe 协议的情况下易于使用。NVMe PCIe Gen4 SSD 性能可通过 NVMe IP 实现高达 6 GB/s 的传输速度,如图 6 所示。
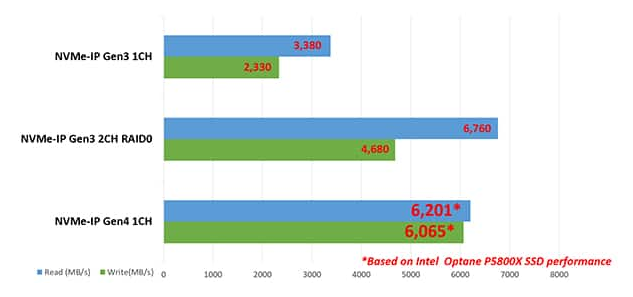
图 6:NVMe PCIe Gen3 和 Gen4 SSD 与 Design Gateway 的 NVMe-IP Core 的性能比较。(图片来源:Design Gateway)
Design Gateway 的 NVMe-IP 用于 Versal 设备
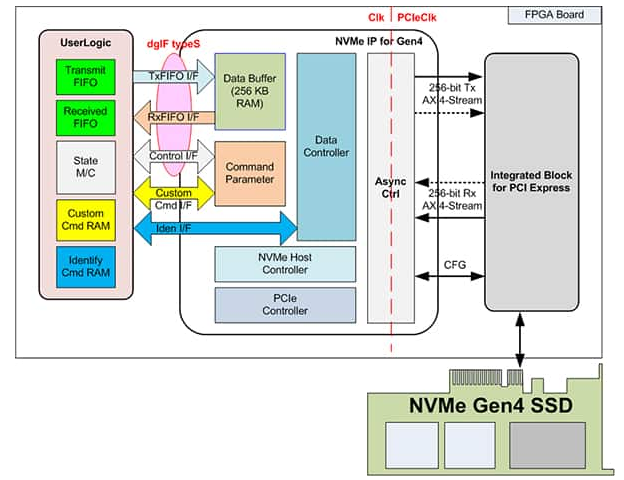
图 7:NVMe-IP 系统概览。(图片来源:Design Gateway)
NVMe-IP的特点
能够实现应用层、事务层、数据链路层和部分物理层访问NVMe SSD,无需CPU或外部DDR内存
与 Xilinx PCIe Gen3 和 Gen4 Hard IP 一起运行
无需外部存储器接口即可利用 BRAM 和 URAM 作为数据缓冲器的能力
支持六个命令:Identify、Shutdown、Write、Read、SMART 和 Flush(可选的附加命令支持)
XCVC1902-VSVA2197-2MP-ES FPGA 设备上的 FPGA 资源使用情况如表 2 所示。

表 3:Versal 设备的实施统计示例。
用于 Versal 设备的 NVMe-IP 的更多详细信息在其数据表中进行了描述
适用于 Gen4 Xilinx 数据表的 NVMe IP 核
结论
TOExxG-IP 和 NVMe-IP 内核都可以通过完全卸载 CPU 系统从计算和内存密集型协议(例如 TCP 和 NVMe 存储协议)中卸载对实时 AI 应用程序至关重要的协议来帮助加速 AI 应用程序性能。这使得 Xilinx 的 Versal AI Core 系列器件能够执行 AI 推理和高性能计算应用,而不会出现网络和数据存储协议处理的瓶颈或延迟。
VCK190 评估套件和 Design Gateway 的网络和存储 IP 解决方案可在赛灵思 Versal AI Core 设备上以尽可能低的 FPGA 资源使用率和极高的能效在 AI 应用中实现最佳性能。
审核编辑 黄昊宇
-
FPGA在人工智能中的应用有哪些?2024-07-29 8297
-
VCK190评估板用户指南2023-09-13 471
-
如何将人工智能应用到效能评估系统软件中去解决2023-08-30 815
-
在Versal VCK190评估套件上使用器件固件升级(DFU)执行USB辅助启动模式测试2023-07-10 1968
-
利用Design Gateway的IP Core加速Xilinx VCK190评估套件上的AI应用2023-07-07 2849
-
【产品测试】利用设计网关的 IP 内核在 Xilinx VCK190 评估套件上加速人工智能应用2022-11-29 3888
-
利用设计网关的 IP 内核在 Xilinx VCK190 评估套件上加速人工智能应用2022-11-25 2772
-
如何更改VCK190单板启动模式2022-08-26 2263
-
在VCK190板子上使用DDR4-DIMM的ECC2022-08-17 2332
-
嵌入式人工智能简介2021-10-28 1981
-
赛灵思宣布两款Versal ACAP评估套件现已上市2021-03-12 4230
-
赛灵思Versal评估套件助力开发者迈入解锁ACAP功能的高速路2021-01-14 3172
-
人工智能是什么?2015-09-16 6449
全部0条评论

快来发表一下你的评论吧 !
