

国产GPU绕不开的CUDA生态
电子说
描述
国内GPU厂家或许尝试,摸着英伟达过河。
近日,摩尔线程在北京发布多款软硬件新品,包括新一代GPU“春晓”、面向个人电脑的消费级显卡MTT S80和服务器计算卡MTT S3000、一体化计算设备“MCCX元计算一体机”,以及开发套件、数字人解决方案等。GPU“春晓”做为本次发布会的核心产品受到广泛关注。
“春晓”是摩尔线程的第二颗GPU,也是摩尔线程首颗面相国内消费级市场发售的GPU,它强调游戏、元宇宙与渲染用途,最重要的是,这个GPU支持英伟达CUDA生态。
其实经常关注显卡的同学总能从英伟达的发布会上听到CUDA这个词,例如最新的RTX3060有拥有多少颗CUDA核心,某某游戏首发即支持CUDA生态等。作为显卡领域的高频词汇,很多人好奇CUDA到底是什么?为什么国产显卡会用到英伟达的技术?本文将带你了解即熟悉又陌生的CUDA。
CUDA是什么?
CUDA(Compute Unified Device Architecture,统一计算架构)是由英伟达所推出的一种集成技术,是该公司对于GPGPU的正式名称。通过这个技术,用户可利用NVIDIA的GPU进行图像处理之外的运算,CUDA也是首次可以利用GPU作为C-编译器的开发环境。简单来说,程序员平时如果不使用特定框架都是针对CPU进行编程的,CUDA是全球最大GPU厂商英伟达推出的针对GPU的编程的架构。
2006年,英伟达发布了CUDA,它提供了GPU编程的简易接口,程序员可以基于CUDA编译基于GPU的应用程序,利用GPU的并行计算能力更高效的解决复杂计算难题。在CUDA发布之前,程序员需要到显卡内核并利用机器码进行编译,编程过程相当繁琐也很困难。CUDA的发布,相当于将较为复杂的底层代码封装成了一个个简单接口,使用时直接调用,其在GPU编程领域的革命性不亚于C、Python、PHP等高等编程语言的发明。当然,CUDA本身也是兼容C语言的,其本身就类似C语言,这可以帮助程序员更快速上手CUDA。现在主流的深度学习框架大多都基于CUDA进行GPU加速运算。
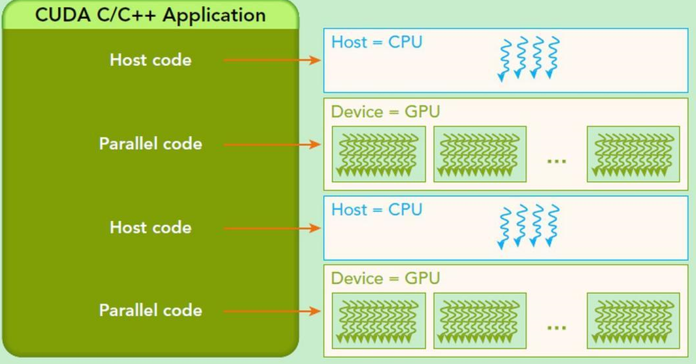
CUDA工作流程 图源:CSDN
从硬件角度看,英伟达会经常宣传自家显卡拥有的CUDA Core数量。CUDA Core其实就是英伟达的流处理器,也就是FP32计算单元,同样的结构在AMD的GPU内叫做SP。与CUDA Core相对的还有Tensor Core张量核心,从字面上就能看出该核心主要针对深度学习中的Tensor计算设计。Tensor计算就是混合精度计算,即在底层硬件算子层面用半精度(FP16)进行输入和输出,使用全精度(FP32)进行计算放置丢失过多精度的操作,这个底层硬件就是Tensor Core。CUDA 9.0引入了一个“warp矩阵函数” C++语言API,以便开发者可以使用GPU上的Tensor Core。
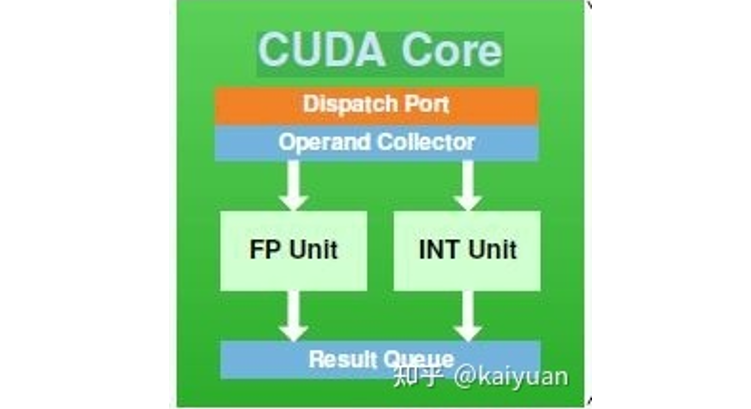
CUDA Core 图源:知乎
CUDA与 GPGPU的概念一脉相承。GPU就是传统意义上的显卡与图形加速卡。随着人工智能产业爆炸式增长,导致计算复杂化和算力不足,CPU并行计算能力远不如GPU,使得GPU在通用计算领域逐渐领先,为了进一步专注通用计算,GPGPU便应运而生。GPGPU与CUDA之间关系十分密切。GPGPU其实是去掉了图形显示功能的GPU,它将全部能力都投入到通用计算上,CUDA的出现让GPU真正实现更广泛的通用计算。CUDA与GPGPU也直接推动了AI与深度学习的发展与产业革命。
为什么要兼容CUDA?
当我们了解了CUDA是怎么回事,也就方便解释为什么国产GPU需要兼容CUDA。
前文提到,目前世界上的主流深度学习架构都在使用CUDA,其主要原因就是深度学习的重要载体—GPU市场已被英伟达占领大半。随之而来的,就是市面上绝大部分GPU相关软件都是用CUDA开发,国产GPU兼容CUDA可以同时“继承”英伟达打造好的软件生态,也有更多资料可供学习,这对于蹒跚起步的国产GPU行业来说,减轻了不少开发难度,也降低了推广压力。
从开发角度分析。业内GPU工程师称目前GPU市场可以笼统的分成两大块,分别是计算和渲染。此前国内GPU厂商通常专注与计算方面的研发,也有少部分渲染产品问世,最近摩尔线程发布的GPU强调其具有强大的渲染能力。然而渲染赛道难度较大,其计算复杂度更高,除了通用计算,还包图形渲染、前后端着色器配置、物体几何属性等需要处理。目前世界上标准API主要是CUDA与OpenCL,CUDA是英伟达系统架构,OpenCL则主要被AMD采用。采用标准化的API接口,无论是CUDA还是OpenCL,都可以极大减少开发渲染类GPU的前提投入,后期可以再做相应的优化,这样可以降低与CUDA等 “地位”稳固的GPU生态直接竞争的难度。
从市场推广角度看。英伟达的CUDA生态已经问世多年,与下游软件、驱动厂家已经有了深度合作。大部分厂家对于GPU生态的观点,往往是不在乎GPU本身好与坏,而是关注GPU好不好用、能不能用。好不好用的评价较为主观,但采用现成的英伟达CUDA接口进行编程,可以规避大多数未知风险,多数初创企业开发GPU软件采用统一接口也能增加开发稳定性,降低人才招聘难度。所以,构建自己的GPU生态要慢慢起步,一味求快推广自家生态只会把风险转嫁给更多下游开发者。
国产GPU要挑战CUDA吗?
CUDA本身涵盖了多个技术领域,其开发与后续更新都与英伟达自家GPU高度绑定,即使全部开源,第三方厂家也难以完美移植到自家GPU上。从另一个角度看,英伟达在GPU领域的垄断地位主要通过CUDA平台上的软件生态实现。国产GPU若想真正做到与英伟达一较高下,CUDA生态是绕不开的最终BOSS。
知乎用户对英伟达GPU生态做出分析。国产GPU厂商若无法做到与英伟达的架构、封装技术、驱动优化等都保持完全一致,CUDA生态就一定不会完美适配其他显卡。做到完全移植,CUDA生态内的各种库以及套件等都需要做相应调试,工作量太大。
此外,CUDA也并不是一成不变的。每隔一代GPU,CUDA架构就会发生很大变化。每个驱动小版本推送,CUDA都会做出部分微调。国产GPU如果完全基于CUDA生态进行开发,那它的硬件更新将完全绑定英伟达的开发进程,这样就失去了主动性,且永远慢人一步。
不过内开发者也不用悲观。CUDA本质是一个计算结构,甚至是一个理念,它并不需要英伟达的完全授权。我们可以参考英伟达的有力竞争者AMD。AMD的生态虽然基于开源生态OpenCL开发,但AMD也制作了HIP的编程模式,与CUDA相比,其开发函数甚至可以进行直接替换。如果说英伟达在GPU领域是摸着石头过河的,那AMD就是摸着英伟达过河。国内GPU厂家或许可以参考AMD发展模式,前期借鉴可以是后期创新的基础。
写在最后
CUDA作为英伟达垄断GPU领域的关键力量,是国产厂商必须面对的挑战。CUDA在诞生之初,为人们在深度学习与AI领域攻坚克难立下汗马功劳,但如果它被用来钳制新力量的发展,CUDA也将成为英伟达的马奇诺防线。
审核编辑 :李倩
-
在K520上能使用两个GPU进行CUDA作业吗2018-09-26 3182
-
linux安装GPU显卡驱动、CUDA和cuDNN库2019-07-09 3778
-
[嵌入式linux] 嵌入式学习分享:那些绕不开的技术点2020-04-16 1580
-
GPU加速的L0范数图像平滑(L0 Smooth)【CUDA】2020-07-08 3040
-
GPU高性能运算之CUDA2010-08-16 863
-
GPU难以超越CUDA生态?国产GPU厂商:干就对了!2022-01-27 9074
-
CUDA矩阵乘法优化手段详解2022-09-28 3074
-
使用CUDA进行编程的要求有哪些2023-01-08 3639
-
GPU平台生态,英伟达CUDA和AMD ROCm对比分析2023-05-18 4104
-
GPU平台生态:英伟达CUDA和AMD ROCm对比分析2023-06-06 4511
-
十大国产GPU产品及规格概述2023-06-25 43304
-
GPU技术、生态及算力分析2024-01-14 2953
-
软件生态上超越CUDA,究竟有多难?2024-06-20 6241
-
打破英伟达CUDA壁垒?AMD显卡现在也能无缝适配CUDA了2024-07-19 7591
-
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程2026-02-10 717
全部0条评论

快来发表一下你的评论吧 !
