

基于深度学习的三维点云配准方法
人工智能
描述
0.笔者个人体会: 这个工作来自于上海交通大学,发表于CVPR 2022。我们知道,三维点云配准是三维视觉以及点云相关任务中的一个关键课题。早期最具有代表性的三维点云配准的工作是ICP,其根据点匹配估计输入点云的相对位姿。近年来随着深度学习技术的发展进步,基于深度学习的三维点云配准方法成为研究的主流,并随之诞生了DeepVCP、DGR、Predator等著名的方法。但这个工作重新聚焦于非学习的策略,通过聚类策略实现了先进的性能。同时,这个工作提出了一个新颖的点云配准问题设定,称为multi-instance point cloud registration,即同时估计某个instance的源点云与多个目标instance组成的目标点云中的每个instance的相对位姿。 这个工作与一般的多模态拟合工作有点类似,但不同的是,这个工作展现了更强的对异常值的鲁棒性,以及非常高的时间效率。但是,不可避免的是,这个工作同样存在着一般非学习的方法都面临的制约,即有许多阈值参数需要给定,这点可能会制约其应用。或者,将深度学习技术与本文观察到的distance invariance matrix的分布规律相结合是一个值得探索的方向。
论文相关内容介绍:
论文标题: Multi-instance Point Cloud Registration by Efficient Correspondence Clustering
作者列表: Weixuan Tang and Danping Zou
摘要:我们解决了多实例点云配准的问题,其是指源点云由一个实例(Instance)的点云构成,而目标点云由多个不同位姿的实例的点云构成的情况下,同时求多个相对位姿变换。现有的解决方案需要对大量假设进行采样以检测可能的实例并排除异常值,但当实例和异常值的数量增加时,其鲁棒性和效率会显著降低。我们提出根据距离不变矩阵将带噪声的对应集合直接分组到不同的簇中。通过聚类自动识别其中的实例和异常值。我们的方法鲁棒且快速。我们在合成数据集和真实数据集上评估了所提出的方法。结果表明,在存在70%异常值的情况下,我们的方法可以正确配准多达20个实例,F1得分为90.46%,其性能明显优于现有方法,速度至少快10倍。
主要贡献: 1)我们针对多实例点云配准问题提出了一种高效且鲁棒的解决方案,在准确性、鲁棒性和速度方面取得了卓越的性能。 2)我们提出了三个指标(Mean Hit Recall、Mean Hit Precision和Mean Hit F1)来全面评估多实例点云配准的性能。 3)我们的解决方案可以潜在地用于3D目标的检测。
问题建模: 多实例点云配准问题中,源点云X提供了一个3D模型的实例,目标点云Y包含该模型的K个实例,其中这些实例是可能仅对3D模型的一部分进行采样的点集。如果我们将第k个实例写为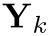 ,则目标点云Y可以分解为
,则目标点云Y可以分解为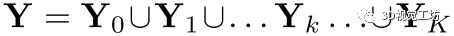 。这里我们使用
。这里我们使用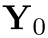 来表示点云中不属于任何实例的部分,即异常值的集合。多实例三维点云配准的目标是找到将源点云实例X 与每个目标实例点云对齐的刚性变换
来表示点云中不属于任何实例的部分,即异常值的集合。多实例三维点云配准的目标是找到将源点云实例X 与每个目标实例点云对齐的刚性变换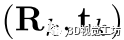 。如果我们设法获得源实例和每k个目标实例
。如果我们设法获得源实例和每k个目标实例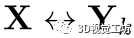 之间的对应关系,则目标点云中第 k 个实例的位姿可以通过最小化对齐误差的总和从对应关系集合中求解:
之间的对应关系,则目标点云中第 k 个实例的位姿可以通过最小化对齐误差的总和从对应关系集合中求解:
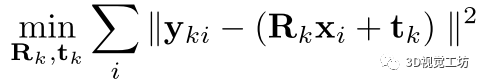
考虑我们已经获得了源点云和目标点云之间的对应关系集合。多实例点云配准任务的关键是将这些对应关系分类为关于不同实例的单独集合,即 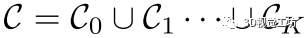 这里
这里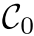 用于表示异常值的集合。正如我们所看到的,多实例点云配准不仅需要排除异常对应,还需要解决来自不同实例的对应的歧义。这项任务并不容易,因为所有实例看起来都一样,并且通常存在许多异常值对应。
用于表示异常值的集合。正如我们所看到的,多实例点云配准不仅需要排除异常对应,还需要解决来自不同实例的对应的歧义。这项任务并不容易,因为所有实例看起来都一样,并且通常存在许多异常值对应。

Fig1:所提出的多实例点云配准方法的流程。从输入对应关系中构造距离不变矩阵,用于将对应关系聚类到不同的簇并进行后续调整。最后,从每个对应集合中估计与每个实例的刚性变换(Transformations)。
方法介绍: 所提出的方法的框架如图1所示。我们的方法将点对应作为输入。然后通过检查对应关系之间的距离一致性来构造一个不变的一致性矩阵。接下来,通过将列或行向量视为这些对应关系的“特征”,将这些对应关系快速聚集到不同的组中。聚类是通过凝聚聚类有效地完成的,其通过交替合并相似的刚性变换和多次迭代重新分配聚类标签来实现。并且,如果出现对应数量很大的情况,我们可以应用下采样和上采样操作来进一步处理。
一、不变性矩阵和兼容性向量
多年来,距离不变性已经在 3D 配准被充分探索,它描述了两点之间的距离在经过刚性变换后保持不变。即,如果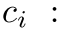
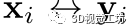 且
且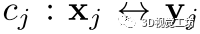 是两个真正的对应,它们应该满足:
是两个真正的对应,它们应该满足: 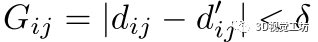

通过计算所有对应对之间的分数,可以获得距离不变矩阵(我们令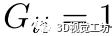 )。距离不变矩阵是对称的,其中每一列或每一行都是一个向量,描述了给定对应关系和其他对应关系之间的兼容性。 我们将列向量
)。距离不变矩阵是对称的,其中每一列或每一行都是一个向量,描述了给定对应关系和其他对应关系之间的兼容性。 我们将列向量 命名为对应ci的兼容性向量。我们观察到,如果两个对应关系属于同一个实例,则它们的兼容性向量具有相似的模式。考虑两个对应关系
命名为对应ci的兼容性向量。我们观察到,如果两个对应关系属于同一个实例,则它们的兼容性向量具有相似的模式。考虑两个对应关系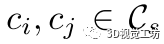 。对于任何对应
。对于任何对应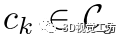 ,由于距离不变性,我们有
,由于距离不变性,我们有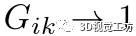 ,
,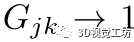 。对于其他对应关系
。对于其他对应关系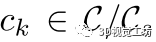 ,我们很可能有
,我们很可能有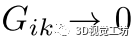 ,
, 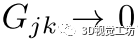 。换句话说,
。换句话说,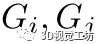 有相似的0-1模式。相比之下,如果这两个对应关系属于不同的实例,那么它们的兼容性向量就会非常不同。为了更好地理解这一观察结果,我们在图2 中给出了一个简单的示例。 对应的兼容性向量可以被视为该对应的特征表示。属于同一刚性变换的对应具有相似的特征。因此,基于这些兼容性向量,我们可以将这些对应关系聚类到不同组中,每个组来自不同的实例或者属于异常值。
有相似的0-1模式。相比之下,如果这两个对应关系属于不同的实例,那么它们的兼容性向量就会非常不同。为了更好地理解这一观察结果,我们在图2 中给出了一个简单的示例。 对应的兼容性向量可以被视为该对应的特征表示。属于同一刚性变换的对应具有相似的特征。因此,基于这些兼容性向量,我们可以将这些对应关系聚类到不同组中,每个组来自不同的实例或者属于异常值。
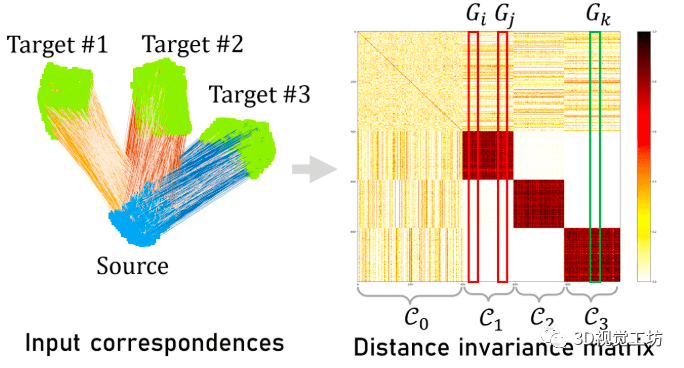
Fig2. 距离不变矩阵中的列向量(兼容性向量)包含与实例相关的丰富信息。这里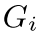 ,
,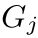 表示第i个和第j个对应的兼容性向量,它们都在实例中。我们观察到与相似。相比之下,与
表示第i个和第j个对应的兼容性向量,它们都在实例中。我们观察到与相似。相比之下,与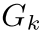 显着不同,因为第k个对应在不同的实例
显着不同,因为第k个对应在不同的实例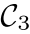 内。这里
内。这里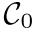 代表异常值的集合。 二、快速对应关系聚类 我们以自下而上的方式对对应进行聚类,这比现有的谱聚类方法要快得多。一开始,每个对应都被视为一个单独的类,然后重复合并距离最小的两个类,直到两类之间的最小距离大于给定阈值。定义类之间距离的方式会产生不同的算法。这里定义距离如下。设
代表异常值的集合。 二、快速对应关系聚类 我们以自下而上的方式对对应进行聚类,这比现有的谱聚类方法要快得多。一开始,每个对应都被视为一个单独的类,然后重复合并距离最小的两个类,直到两类之间的最小距离大于给定阈值。定义类之间距离的方式会产生不同的算法。这里定义距离如下。设 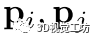 为类i和j的表示向量,类间距离定义为
为类i和j的表示向量,类间距离定义为
如果两个类合并,则新类的表示向量通过 更新,其中
更新,其中 表示对两个向量的每个维度取最小值。在聚类开始时,将一类(仅包含一个对应)的表示向量设置为该对应的兼容性向量。
表示对两个向量的每个维度取最小值。在聚类开始时,将一类(仅包含一个对应)的表示向量设置为该对应的兼容性向量。
三、迭代聚类调整
在聚类之后,我们通过重复一下步骤进一步细化,直到没有变化为止。 Step1. 估计来自每个类的刚性变换,其中对应的数量大于阈值ɑ。 Step2. 合并相似的变换。 Step3. 将类的标签重新分配给每个对应的。每个对应都分配给其对齐误差最小的变换。如果对于所有变换的最小对齐误差都大于内点阈值,则将该对应标记为异常值。 在迭代过程中,对应变得越来越聚集,因此我们可以在Step1中调整ɑ以增加异常值拒绝的强度。我们使用以下策略在每次迭代中更新ɑ:  其中表示第次迭代,N是对应的数量,是舍入取整操作。我们在实验中设置
其中表示第次迭代,N是对应的数量,是舍入取整操作。我们在实验中设置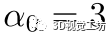 和
和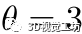 。在我们的实验中,细化过程通常在三个迭代内收敛,因此它也是高效的。
。在我们的实验中,细化过程通常在三个迭代内收敛,因此它也是高效的。
四、合并相似的刚性变换
有时不同的对应类会产生类似的刚性变换,这意味着它们可能属于同一个实例。在这种情况下,我们需要合并它们。给定两个估计的变换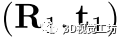 和
和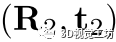 ,我们计算每个对应的对齐误差,即
,我们计算每个对应的对齐误差,即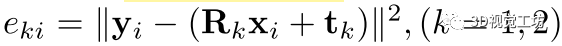 接下来,如果
接下来,如果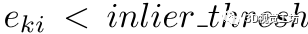 ,我们设置
,我们设置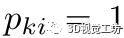 ,否则设置
,否则设置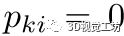 。因此,我们为两个转换获得了两个二元集合
。因此,我们为两个转换获得了两个二元集合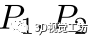 。合并两个变换的标准是
。合并两个变换的标准是 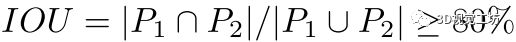 如果满足此标准,我们将丢弃具有更多异常值的其中一个变换。然后,我们根据所有变换中对齐误差最小的一个,将簇标签重新分配给每个对应。
如果满足此标准,我们将丢弃具有更多异常值的其中一个变换。然后,我们根据所有变换中对齐误差最小的一个,将簇标签重新分配给每个对应。
五、从每一类提取刚性变换
聚类后,我们需要从这些不同类的对应集合中提取刚性变换。由于我们不知道目标点云中实例的真实数量,我们需要自动选择那些内点对应类。我们首先选择元素数大于阈值的内点对应类,并估计这些类的刚性变换。接下来,我们按这些刚性变换的内点对应数,以降序对其进行排序。刚性变换内点对应越多,它与真实实例相关联的机会就越高。最后,我们通过以下方式检查刚性变换和具有最多对应内点的刚性变换之间的内点对应数的下降率 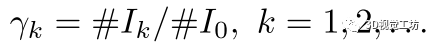 其中
其中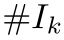 表示第k次刚性变换的内点对应数。如果,我们忽略第k个刚性变换之后的所有变换。这里可以更改阈值以在召回率和精度之间进行权衡。
表示第k次刚性变换的内点对应数。如果,我们忽略第k个刚性变换之后的所有变换。这里可以更改阈值以在召回率和精度之间进行权衡。
编辑:黄飞
- 相关推荐
- 热点推荐
- 深度学习
-
一种快速的三维点云自动配准方法2013-09-23 804
-
三维颅骨自动非刚性配准方法2017-12-09 705
-
基于分层策略的三维非刚性模型配准算法2019-01-23 1471
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1549
-
点云的概念以及与三维图像的关系2021-08-17 9057
-
自动驾驶圈黑话:常用的点云配准方法以及未来发展方向2022-11-11 3254
-
三维点云配准的相关知识学习技巧2022-12-02 2819
-
一个基于学习的LiDAR点云3D线特征分割和描述模型2023-01-12 2869
-
自动驾驶领域点云配准的工作原理与技术方法2023-03-24 1594
-
基于深度学习的三维点云配准新方法2023-06-17 2611
-
三维点云配准过程详解:算法原理及推导2023-09-21 2647
-
三维点云配准算法原理及推导2023-09-25 2175
-
基于深度学习的三维点云分类方法2024-10-29 2817
-
AI 驱动三维逆向:点云降噪算法工具与机器学习建模能力的前沿应用2025-08-20 1086
全部0条评论

快来发表一下你的评论吧 !
