

聊一个云计算领域的热门概念—Serverless
描述
今天这篇文章,我们来聊一个云计算领域的热门概念——Serverless。
到底什么是Serverless? 英语好的童鞋,可能一眼就看出来了,Serverless是由Server和less两个词根组成的词。从字面上理解,就是“无服务器”。
行业通常所说的Serverless,主要是指“无服务器计算(Serverless Computing)”。
那么问题来了,这年头,就连小学生都知道,服务器是具有很强计算能力的计算机,是我们现在最主要的计算工具。“无服务器计算”,如果不采用服务器,那该怎么算呢?
事实上,Serverless所谓的“无服务器计算”,并不是真的不需要服务器,而是说,对于用户,服务器变得“不可见”了(或者说“无感知”了)。
越说越玄乎了,有木有?别急,还是让我从头开始说起吧——
█ Serverless的诞生背景
1946年2月,世界上第一台数字式电子计算机ENIAC诞生,标志着人类正式进入了数字计算机时代。
早期的计算机都是大型机,体积庞大,价格昂贵,但是,算力却很弱。当时,这些机器只有很少的公司才能拥有,用于特定的计算目的。
到了1970-80年代,为了解决单点式计算(一台大型机,独立完成全部的计算任务)算力不足的问题,专家们发明了网格计算这样的分布式计算架构,取得了不错的效果。
说白了,分布式计算,就是把一个巨大的计算任务,分解为很多的小型计算任务,交给不同的计算机分工完成, 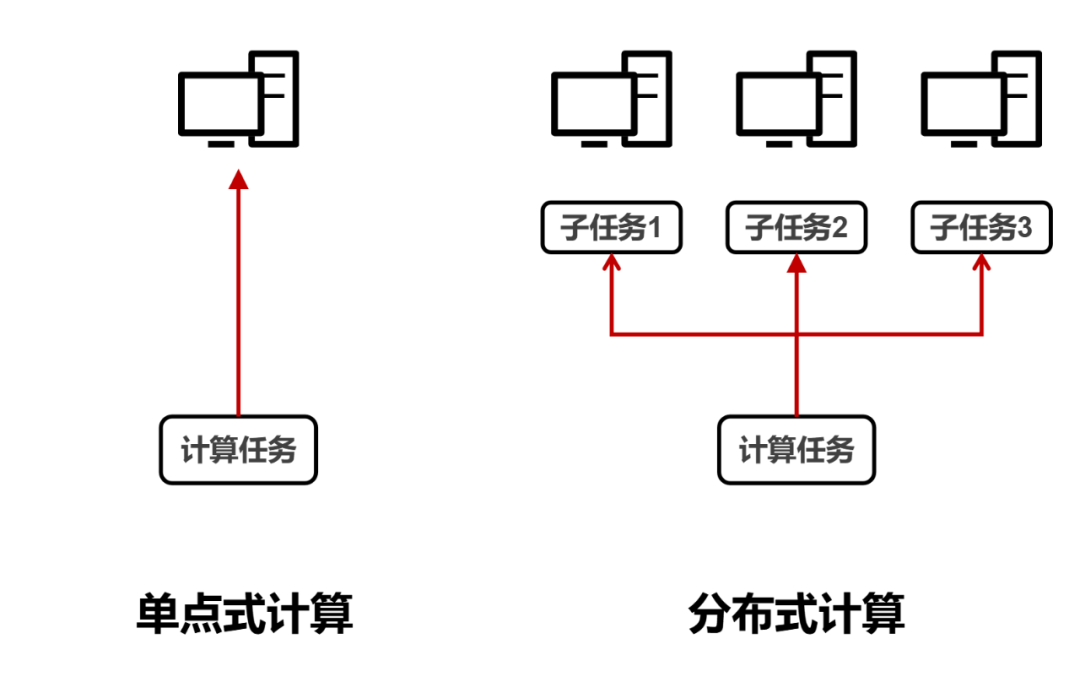
再后来,随着芯片技术的进步,计算机的体积变得越来越小,算力也变得越来越强劲。不久后,小型化的计算机出现了,也就是我们常说的PC(Personal Computer,个人电脑)。
计算机制造和使用成本的不断下降,加速自身的普及,也刺激了计算机网络的出现与发展。从局域网到广域网,再到互联网,计算机网络的规模变得越来越大。
互联网的出现,彻底改变了计算机服务用户的方式。
此前,一个机房服务于一所学校、一家企业、一个政府部门,现在,有了互联网,服务对象可以是全球用户,规模大大增加了。
用户规模增加,意味着对算力的需求也增加了。互联网服务提供商,需要一种更强大、更便宜的算力,满足用户需求。
于是乎,就有了云计算。
很多人认为,云计算就是一个超大号的机房,和以前的企业机房没有区别,只不过服务器更多些。
这种观点是不对的。
云计算的本质,不是算力资源的简单堆砌,而是池化——它将大量的零散算力资源(廉价的算力资源)进行打包、汇聚,实现更高可靠性、更高性能、更低成本的算力。
具体来说,在云计算中,CPU、GPU、内存、硬盘等计算资源被集合起来,通过软件的方式,组成一个虚拟的可无限扩展的“算力资源池”。如果用户有算力需求,“算力资源池”就会动态地进行算力资源的分配,构建一个虚拟的“计算机”。用户按需使用、付费,即可。
相比于用户自购设备、自建机房、自己运维,云计算有明显的成本优势,可以节约大量资金和人力。
根据提供算力资源的层级不同,云计算通常也分为IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)。如下图所示: 
那么,问题又来了——云计算这种“租”的方式,是不是最终极的算力资源使用方式呢?我们作为用户,使用算力,还能更简单一点吗?
答案是肯定的。
不管是自建机房,还是云计算,用户都需要和服务器打交道,和软硬件环境打交道。这些都是工具和过程,而我们的最终目的是什么?是得到运算结果。 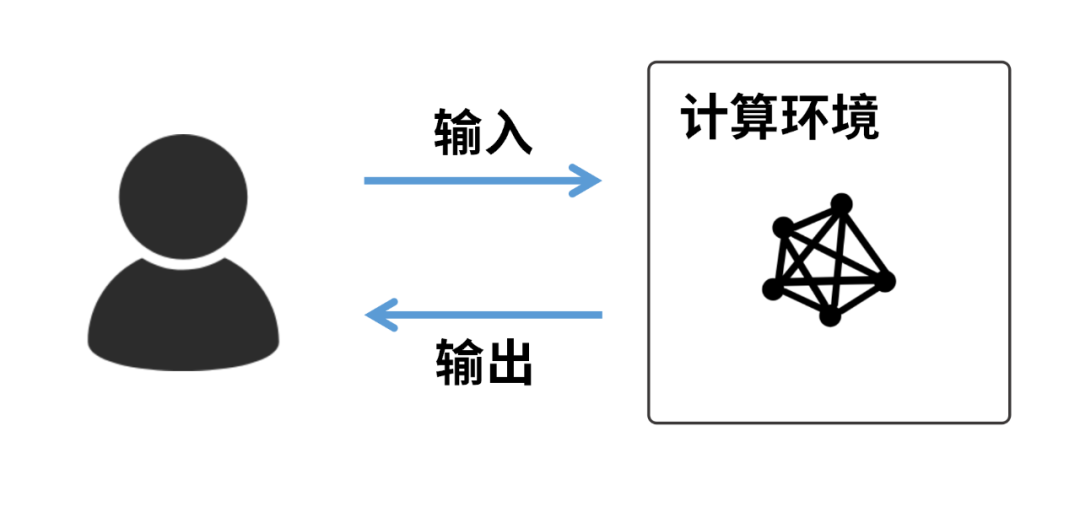
那么,为了得到结果,我们是不是一定要关心环境的搭建过程?
不一定。既然环境可以租,那何不更彻底一点,直接“租”服务呢?
举例来说,如果把计算过程理解为炒菜。以前,我们为了炒菜,需要自己建个厨房,自己买锅碗瓢盆、油盐酱醋,自己亲自炒菜。后来,有了云计算,我们可以租个厨房,租工具,然后炒菜。现在,想要更简单的话,是不是可以直接叫外卖?
再例如,以前,我们上班通勤,是自己买车,自己开车。然后,有了云计算,相当于租车。现在,是不是可以直接打车?
说白了,我们要的是计算服务和计算结果。计算环境(硬件),我们完全可以不去操心。 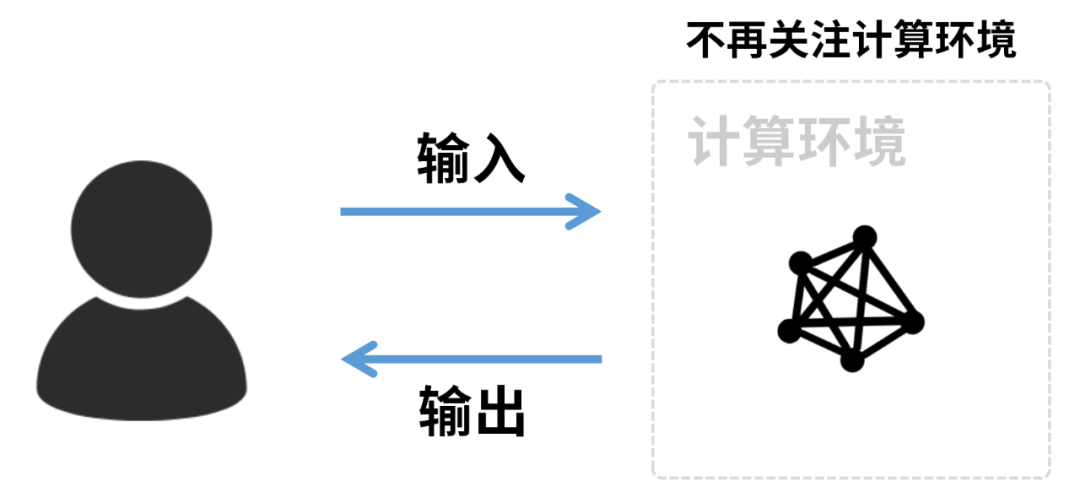
说到这,我们的主角——Serverless,终于闪亮登场了。
对于Serverless,我们可以把它理解为一种架构,一种理念,甚至是一种思想。
Serverless的核心目的,就是在云计算的基础上,再向前迈进一步,彻底“包揽”所有的环境工作,直接提供计算服务。
在Serverless架构下,开发者只需编写代码并上传,云平台就会自动准备好相应的计算资源,完成运算并输出结果,从而大幅简化开发运维过程。
换句话说,用户完全不用关心厨房,你把食材提供给Serverless平台,它负责把菜炒好,就这么简单。
█ Serverless的特点
Serverless是云计算的进一步延伸,所以,它继承了云计算的最大特点——按需弹性伸缩、按需付费。 现在的互联网服务,基本上都是采用微服务架构。也就是把一整套服务,拆分为多个细分服务,由不同的服务器完成运算。
Serverless的特点是,这个服务足够“细小”,变成了“函数级”的颗粒度。 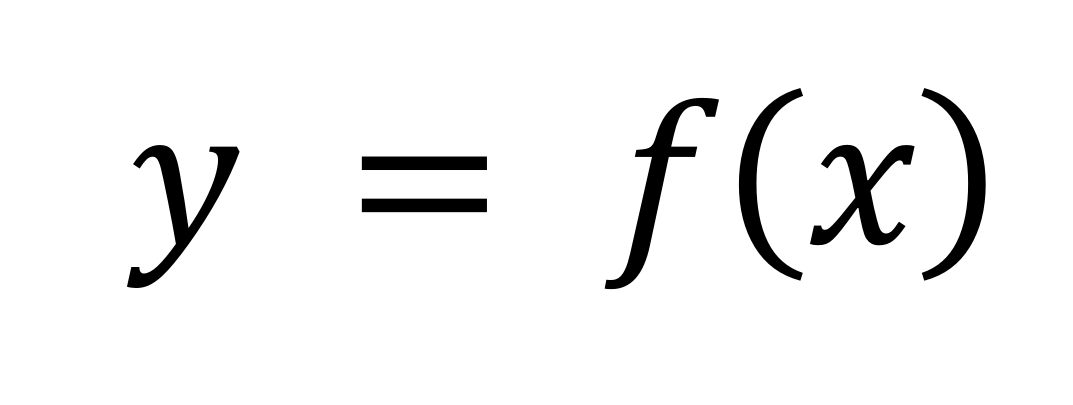
所谓函数,就是提供输入,计算输出。
从层级上来看,Serverless在传统云计算SaaS的Application(应用)层级之上,又加了一层——function(函数)。它的颗粒度更细,可以更灵活地满足用户的算力需求。
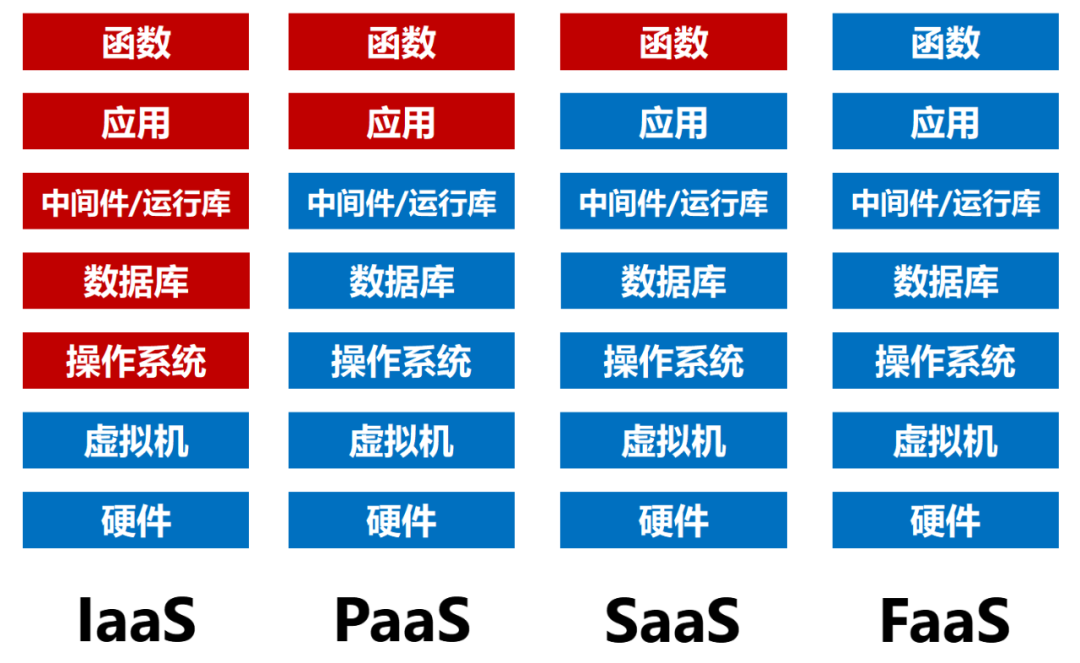
按照CNCF对Serverless 的定义,Serverless架构是采用FaaS(函数即服务)和BaaS(后端服务)服务来解决问题的一种设计。
FaaS就是Function as a service(函数即服务)。每一个函数都是一个服务,函数可以由任何语言编写,直接托管在云平台,以服务形式运行,通过事件触发。
BaaS则是Backend as a service(后端即服务)。云平台提供的后端组件整合,开发者无需开发和维护后端服务,通过API/SDK的调用,便可获得例如数据存储、消息推送、账号管理等能力。
Serverless = FaaS + BaaS
Serverless的背后,依然是虚拟机和容器。只不过,服务器部署、runtime安装、编译等工作,都由Serverless计算平台负责完成了。
对开发人员来说,只需要维护源代码和Serverless执行环境的相关配置即可。这就叫“无服务器计算”。
Serverless架构的最大优势,显然就是帮助用户彻底摆脱了基础设施管理这样的“杂事”,更加专注于业务开发,从而提升了效率,降低了开发和运营成本。
根据业界的统计,在商业和企业数据中心里的典型服务器,日常仅仅只提供了5%~15%的平均最大处理能力的输出。这是一种算力资源的巨大浪费。
Serverless的出现,可以让用户按照实际算力使用量进行付费,属于真正的“精确计费”。 换言之,用户的每一分钱,都花在了刀刃上。
█ Serverless的发展历程
世界上第一个Serverless平台,是2006年发布的Zimki。这个平台提供服务端JavaScript应用,支持“按照实际调用付费”。不过,当时他们并没有使用Serverless这个名词。
后来,到了2012年,Iron.io的副总裁Ken Form在文章“Why The Future of Software and Apps is Serverless”中,首次提出了Serverless,才宣告这个概念的正式诞生。
2014年11月,亚马逊率先推出了真正意义上的第一款Serverless FaaS服务——Lambda。从此,各大厂商开始跟进。
2017年,Serverless开始在国内落地。这一年,阿里云和腾讯云先后推出了自己的 Serverless平台。阿里云的Serverless平台,被直接命名为函数计算(FC,Function Compute)。
一年后的2018年,阿里云推出Serverless容器服务ASK和Serverless应用引擎SAE。
那一时期,刚好小程序开始火爆。Serverless的灵活架构,非常适合小程序的开发。于是,吸引了大量的开发者们。
到了2019年,国内厂商纷纷入局Serverless。如今,Serverless已经成了各大云厂商的标配,受到整个行业的热捧。
█ 结语
随着数字经济浪潮的蓬勃发展,以及各行各业数字化转型的不断推进,算力的价值正在持续提升。
在单纯提升芯片算力方面,我们面临越来越大的挑战(摩尔定律逐渐失效)。在这种情况下,我们必须更多地考虑,该如何提升算力的使用效率。
作为一种灵活轻量化的新型算力架构,Serverless毫无疑问是我们挖掘算力潜力、提升算力效率的一个重要手段。
客观来说,目前的Serverless谈不上完美。在实时性等方面,还存在一些不足。随着时间的推移,这些问题最终都会得到解决。
Serverless,将引领我们全面走向算力新时代。
审核编辑:刘清
-
华为云全域 Serverless 8 月更新盘点2024-09-27 1884
-
HarmonyOS/OpenHarmony原生应用开发-华为Serverless云端服务支持说明(一)2023-10-08 582
-
全域 Serverless 化,华为云引领下一代云计算新范式2023-09-06 1358
-
阿里云宣布核心产品全面 Serverless 化2022-11-03 812
-
【学习打卡】ArkUI eTS 云函数计算十二生肖[Serverless]2022-07-12 6501
-
Serverless概念2021-09-15 1239
-
云手机概念2021-09-14 1803
-
云计算概念、原理、分类、特点和应用2020-11-11 22495
-
Bazaar:阿里云Serverless计算服务探秘2018-06-08 2877
-
持续优化云原生体验,阿里云在Serverless容器与多云上的探索2018-05-15 3388
-
阿里云宣布推出Serverless Kubernetes服务 30秒即可完成应用部署2018-05-03 3355
-
云计算的概念是由谁提出的_云计算的云是什么意思2018-04-10 65650
-
基于阿里云Serverless架构下函数计算的最新应用场景详解(一)2018-01-25 2849
全部0条评论

快来发表一下你的评论吧 !
