

用于视觉识别的Transformer风格的ConvNet
描述
本文旨在通过充分利用卷积探索一种更高效的编码空域特征的方式:通过组合ConvNet与ViT的设计理念,本文利用卷积调制操作对自注意力进行了简化,进而构建了一种新的ConvNet架构Conv2Former。ImageNet分类、COCO检测以及ADE20K分割任务上的实验结果表明:所提Conv2Former取得了优于主流ConvNet(如ConvNeXt)、ViT(如Swin Transformer)的性能。
本文方案
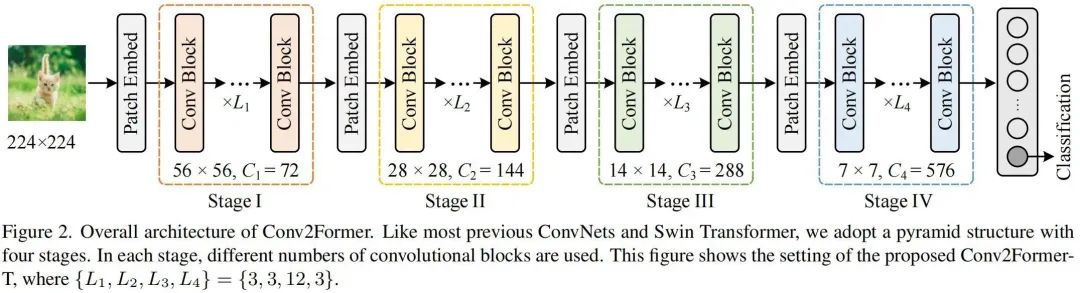
上图给出了本文方案架构示意图,类似ConvNeXt、SwinT,Conv2Former采用了金字塔架构,即含四个阶段、四种不同尺寸的特征,相邻阶段之间通过Patch Embedding模块(其实就是一个卷积核与stride均为的卷积)进行特征空间分辨率与通道维度的恶变换。下表给出了不同大小Conv2Former的超参配置,
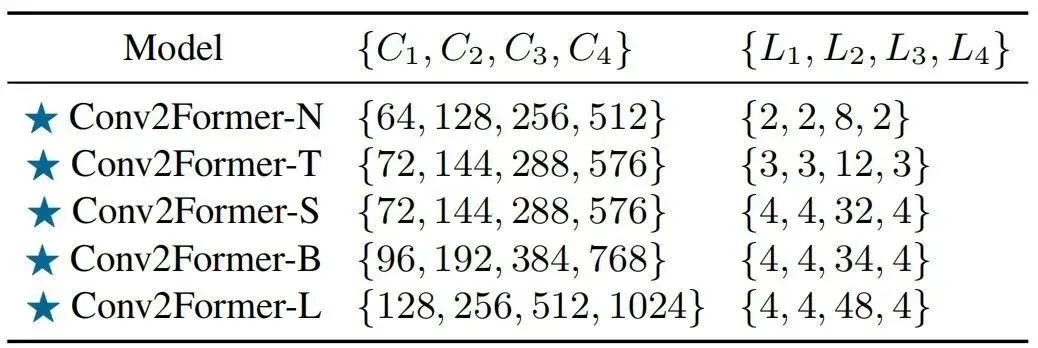
核心模块
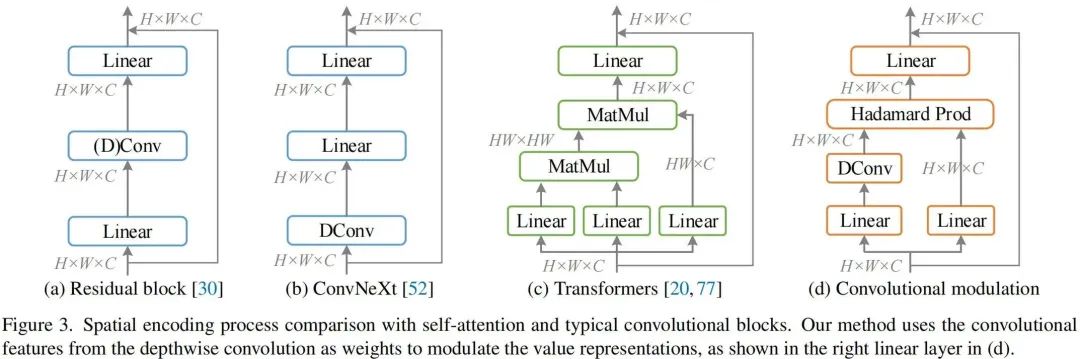
上图给出了经典模块的架构示意图,从经典的残差模块到自注意力模块,再到新一代卷积模块。自注意力模块可以表示为如下形式:
尽管注意力可以更好的编码空域相关性,但其计算复杂性随N而爆炸性增长。
本文则旨在对自注意力进行简化:采用卷积特征对V进行调制。假设输入,所提卷积调制模块描述如下:
需要注意的是:上式中表示Hadamard乘积。上述卷积调制模块使得每个位置的元素与其近邻相关,而通道间的信息聚合则可以通过线性层实现。下面给出了该核心模块的实现代码。
class ConvMod(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = LayerNorm(dim, eps=1e-6, data_format='channel_first')
self.a = nn.Sequential(
nn.Conv2d(dim, dim, 1),
nn.GELU(),
nn.Conv2d(dim, dim, 11, padding=5, groups=dim)
)
self.v = nn.Conv2d(dim, dim, 1)
self.proj = nn.Conv2d(dim, dim, 1)
def forward(self, x):
B, C, H, W = x.shape
x = self.norm(x)
a = self.a(x)
v = self.v(x)
x = a * v
x = self.proj(x)
return x
微观设计理念
Larger Kernel than 如何更好的利用卷积对于CNN设计非常重要!自从VGG、ResNet以来,卷积成为ConvNet的标准选择;Xception引入了深度分离卷积打破了该局面;再后来,ConvNeXt表明卷积核从3提升到7可以进一步改善模型性能。然而,当不采用重参数而进一步提升核尺寸并不会带来性能性能提升,但会导致更高计算负担。
作者认为:ConvNeXt从大于卷积中受益极小的原因在于使用空域卷积的方式。对于Conv2Former,从到,伴随核尺寸的提升可以观察到Conv2Former性能一致提升。该现象不仅发生在Conv2Former-T(),同样在Conv2Former-B得到了体现()。考虑到模型效率,作者将默认尺寸设置为。
Weighting Strategy 正如前面图示可以看到:作者采用Depthwise卷积的输出对特征V进行加权调制。需要注意的是,在Hadamard乘积之前并未添加任务规范化层(如Sigmoid、),而这是取得优异性能的重要因素(类似SENet添加Sigmoid会导致性能下降超0.5%)。
Normalization and Activations 对于规范化层,作者参考ViT与ConvNeXt采用了Layer Normalization,而非卷积网络中常用的Batch Normalization;对于激活层,作者采用了GELU(作者发现,LN+GELU组合可以带来0.1%-0.2%的性能提升)。
本文实验
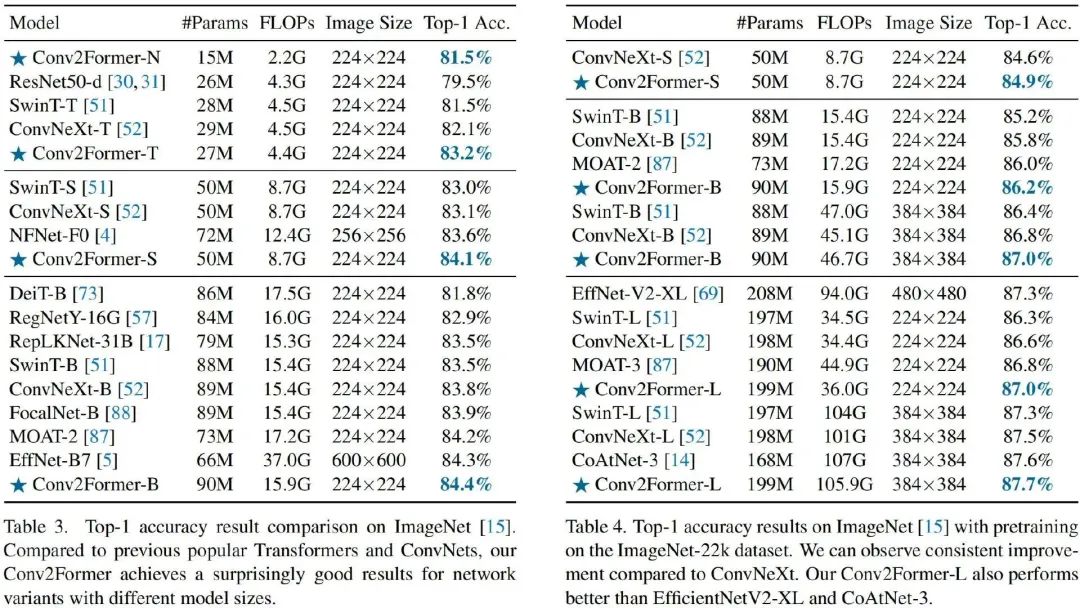
上述两表给出了ImageNet分类任务上不同方案的性能对比,从中可以看到:
-
在tiny-size(<30M)方面,相比ConvNeXt-T与SwinT-T,Conv2Former-T分别取得了1.1%与1.7%的性能提升。值得称道的是,Conv2Former-N仅需15M参数量+2.2GFLOPs取得了与SwinT-T(28M参数量+4.5GFLOPs)相当的性能。
-
在base-size方面,相比ConvNeXt-B与SwinT-B,Conv2Former-B仍取得了0.6%与0.9%的性能提升。
-
相比其他主流模型,在相近大小下,所提Conv2Former同样表现更优。值得一提的是,相比EfficientNet-B7,Conv2Former-B精度稍有(84.4% vs 84.3%),但计算量大幅减少(15G vs 37G)。
-
当采用ImageNet-22K预训练后,Conv2Former的性能可以进一步提升,同时仍比其他方案更优。Conv2Former-L甚至取得了87.7% 的优异指标。
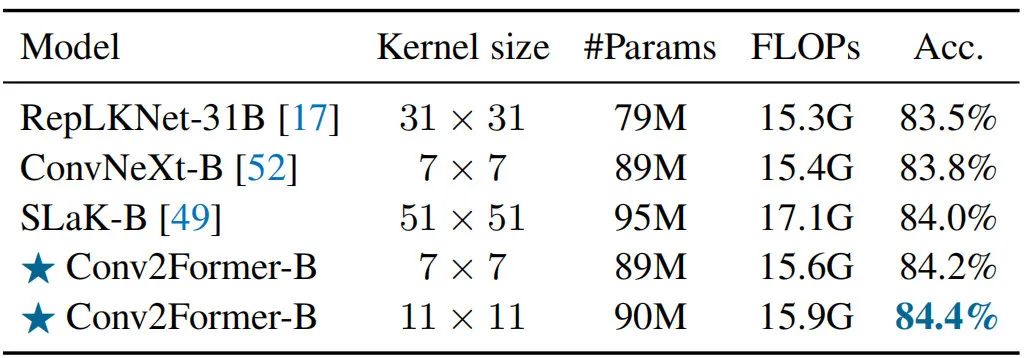
采用大核卷积是一种很直接的辅助CNN构建长程相关性的方法,但直接使用大核卷积使得所提模型难以优化。从上表可以看到:当不采用其他训练技术(如重参数、稀疏权值)时,Conv2Former采用时已可取得更好的性能;当采用更大的核时,Conv2Former取得了进一步的性能提升。
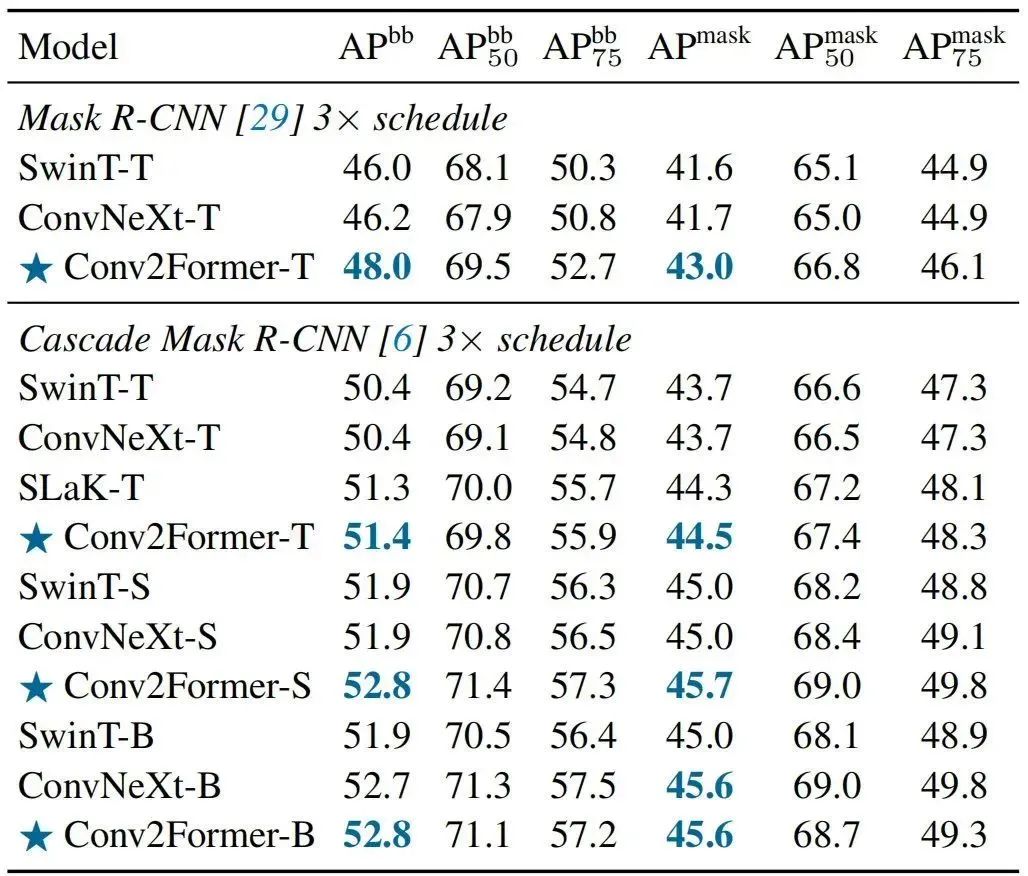
上表给出了COCO检测任务上不同方案的性能对比,从中可以看到:
-
在tiny-size方面,相比SwinT-T与ConvNeXt-T,Conv2Former-T取得了2% 的检测指标提升,实例分割指标提升同样超过1%;
-
当采用Cascade Mask R-CNN框架时,Conv2Former仍具有超1%的性能提升。
-
当进一步增大模型时,性能优势则变得更为明显;
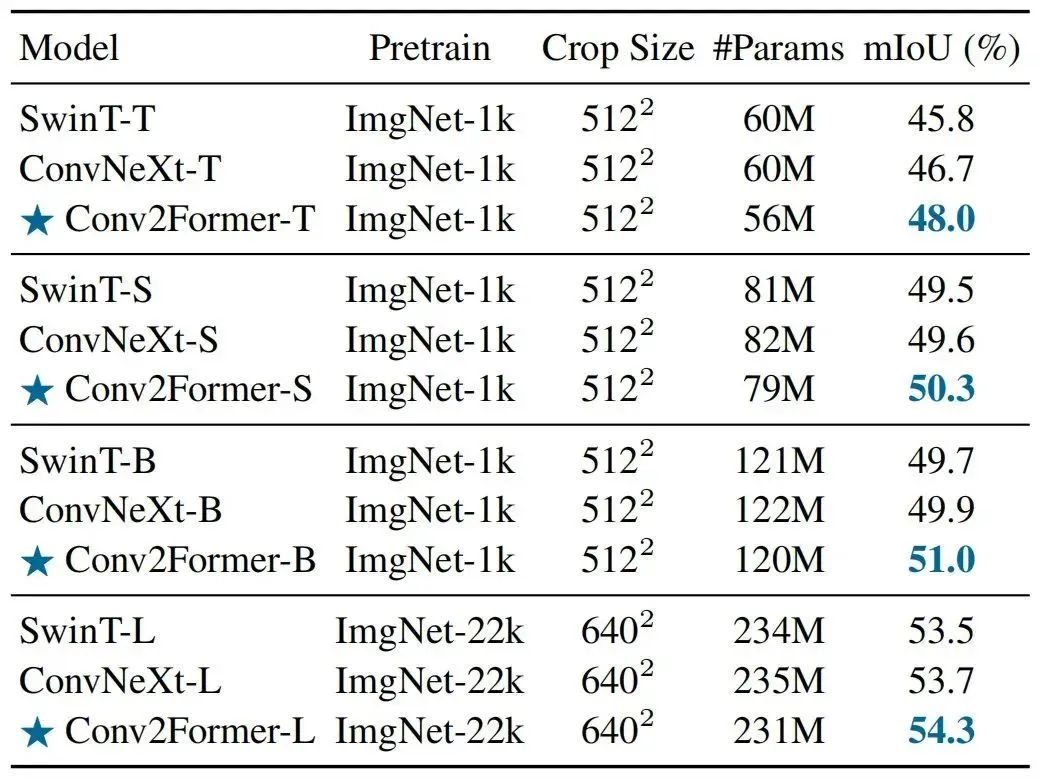
上表给出了ADE20K分割任务上的性能对比,从中可以看到:
-
在不同尺度模型下,Conv2Former均具有比SwinT与ConvNeXt更优的性能;
-
相比ConvNeXt,在tiny尺寸方面性能提升1.3%mIoU,在base尺寸方面性能提升1.1%;
-
当进一步提升模型尺寸,Conv2Former-L取得了54.3%mIoU,明显优于Swin-L与ConvNeXt-L。
一点疑惑解析
到这里,关于Conv2Former的介绍也就结束了。但是,心里仍有一点疑惑存在:Conv2Former与VAN的区别到底是什么呢?关于VAN的介绍可参考笔者之前的分享:《优于ConvNeXt,南开&清华开源基于大核注意力的VAN架构》。
先来看一下两者的定义,看上去两者并无本质上的区别(均为点乘操作),均为大核卷积注意力。
-
VAN:
-
Conv2Former
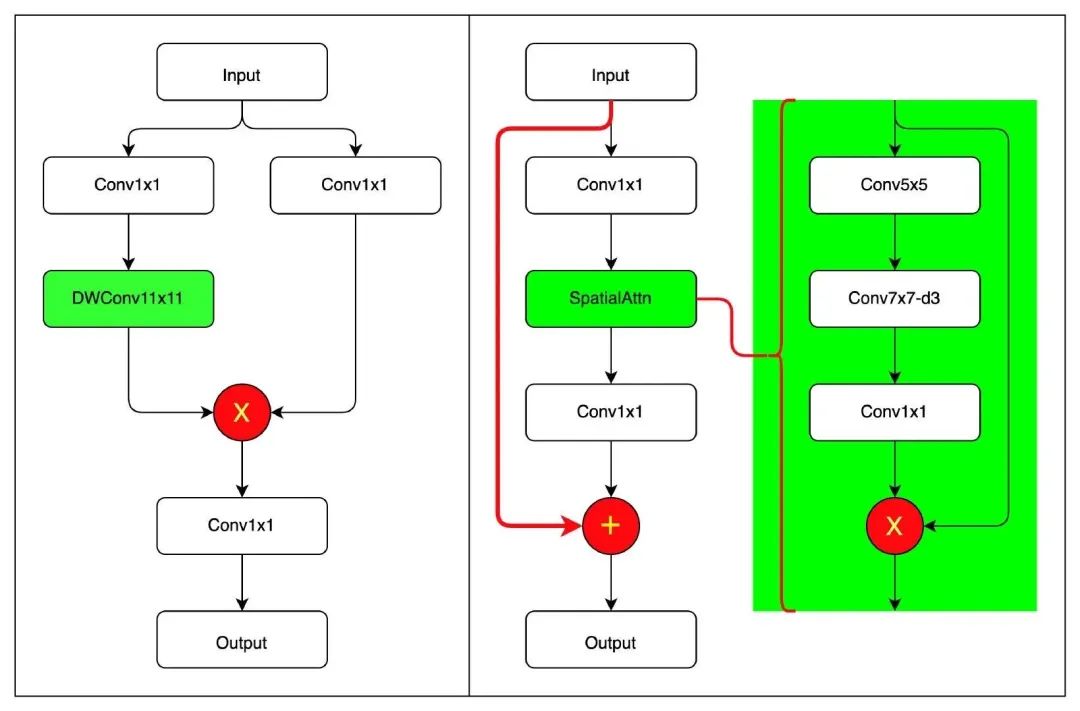
结合作者开源代码,笔者绘制了上图,左图为Conv2Former核心模块,右图为VAN核心模块。两者差别还是比较明显的!
-
虽然大核卷积注意力均是其核心,但Conv2Former延续了自注意力的设计范式,大核卷积注意力是其核心;而VAN则是采用传统Bottleneck设计范式,大核卷积注意力的作用类似于SE。
-
从大核卷积内在机理来看,Conv2Former仅考虑了的空域建模,而VAN则同时考虑了空域与通道两个维度;
-
在规范化层方面,Conv2Former采用了Transformer一贯的LayerNorm,而VAN则采用了CNN一贯的BatchNorm;
-
值得一提的是:两者在大核卷积注意力方面均未使用Sigmoid激活函数。两者均发现:使用Sigmoid激活会导致0.2%左右的性能下降。
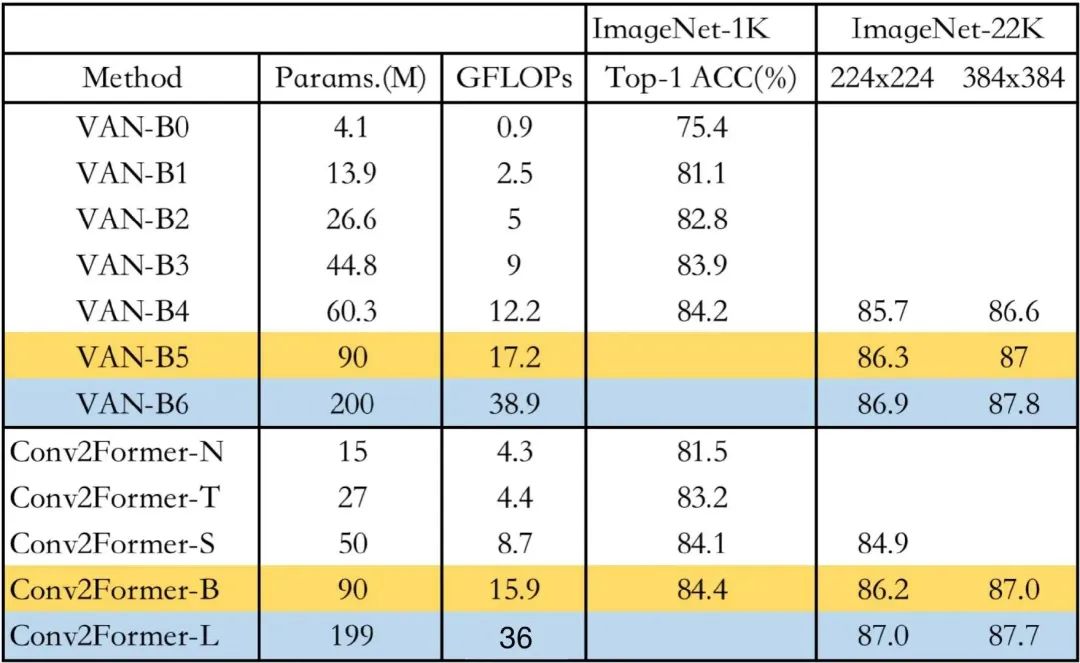
为更好对比Conv2Former与VAN的性能,特汇总上表(注:GFLOPs列仅汇总了)在Image输入时的计算量Net-1K上的指标进行了对比,可以看到:在同等参数量前提下,两者基本相当,差别仅在0.1%。此外,考虑到作者所提到的“LN+GELU的组合可以带来0.1%-0.2%的性能提升”,两者就算是打成平手了吧,哈哈。
审核编辑 :李倩
-
人脸检测与识别的方法有哪些2024-07-03 2126
-
AI视觉识别有哪些工业应用2023-11-27 2171
-
机器视觉与生物特征识别的关系2023-08-09 1293
-
视觉颜色识别与传感器颜色识别的区别2023-03-20 1930
-
利用卷积调制构建一种新的ConvNet架构Conv2Former2022-12-19 1833
-
基于视觉transformer的高效时空特征学习算法2022-12-12 2497
-
普通视觉Transformer(ViT)用于语义分割的能力2022-10-31 6259
-
轻量级视觉模型设计的新启发2022-07-28 1829
-
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果2021-12-28 2357
-
射频识别的构成_射频识别的主要工作频率2020-03-28 6629
-
游戏中视觉风格的历史和现状2018-11-08 3380
-
基于机器视觉识别的交通灯控制系统2018-01-09 16970
-
ABBYY PDF Transformer+改善转换结果之识别语言2017-10-18 1993
-
求助,会搞视觉识别的高人,企鹅8135699692015-03-20 1590
全部0条评论

快来发表一下你的评论吧 !
