

如何解决下一代中央计算架构下的片内高速实时通信需求呢
接口/总线/驱动
描述
近日,中央计算架构委员会组织了一次年中团建,邀请各分委会的兄弟们来火焰山避暑,顺便聊聊汽车下一代中央计算架构的实施进展。
首先登场的是趾高气扬的SOC兄弟,还没等进门,就开始喊道:外面传感器是越来越多,数据量也是越来越大,还都想把原始数据送过来;我把拜把子兄弟都喊过来帮忙了,可高达Gbps级别的数据,我该如何与拜把子兄弟们实时交互信息呢?
接着登场的是大腹便便的存储兄弟,好不容易坐稳,一脸愁容的说道:各位看我体型也能猜出我甜蜜的烦恼了吧,什么高精地图数据,外部传感器数据,内部智能座舱数据全都需要我存储,存慢了就背锅,谁有什么好方法让SOC给我的数据传的快点呀。
其他小弟默默无语,两位大佬的问题不解决,中央计算架构似乎很难有所进展,而两位大佬问题的共同点就是:如何解决下一代中央计算架构下的片内高速实时通信需求。业内给出的一种解决方案就是PCIE。
PCIE简介
2001年初,Intel提出要采用新一代的总线技术来连接内部多种芯片,并取代当时使用的PCI总线,并称之为第三代输入输出技术(3GIO技术)。2001底,雷厉风行的Intel就联合AMD、DELL、IBM等20多家业内主导公司开始起草新技术的规范,并于2002年完成,这种新的总线标准对外正式命名为PCI Express(PCIE/PCI-E)。
PCIE(Peripheral Component Interconnect Express)是一种全双工、端到端、串行、高速可扩展通信总线标准。
全双工,是指允许设备在同一时刻,既可以发送数据也可以接收数据。这就好比一条双向车道,南来的北往的互不干扰。而实现总线上数据发送或接收的物理介质是一对差分线,接收端通过比较两根线上信号的差值,来判断发送端发送的是“逻辑0”还是“逻辑1”。采用差分信号传输,可以极大提高抗干扰能力,从而大幅提升传输频率。而这样的两对发送和接收组成的一个差分回路(总共4条线),被称为1xLane,如图1所示。
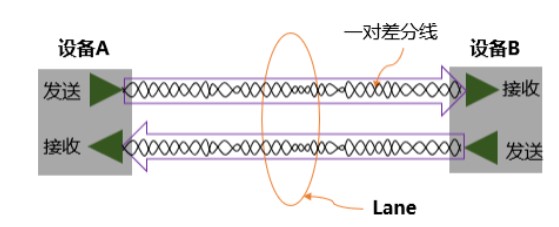
图1 1xLane结构示意图
端到端,指的是一条PCIE链路(Link)两端只能各连接一个设备,这两个设备互为数据的发送端和接收端,如图2的设备A和设备B。而一条Link可以由多条上文介绍的Lane组成,这就好比双向道路中,每一向道路中又可以包含多条车道。常见的Lane有x1,x2,x4,x8,x16,x32等。
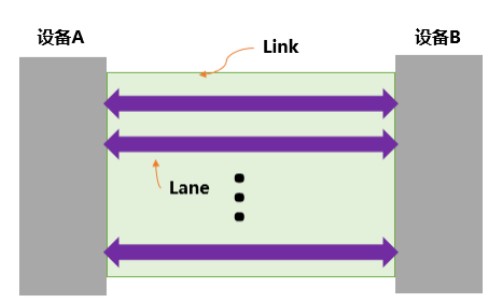
图2 一条PCIE链路
串行,数据一位一位的依次传输,每一位占据一个固定的时间长度。有点电子学基础的朋友可能要问,为什么不采用并行方式呢,一个固定时间长度,能同时传输8/16/32bit…,传输速率不是更快吗?巧了,PCIE的众多总线前辈们采用的也的确是并行方式。
采用并行的方式,数据通常在公共时钟周期的第一个上升沿将数据发送出去,数据通过传输介质到达接收端,接收端在公共时钟周期的第二个上升沿对数据进行采集,发送和接收正好经历一个公共时钟周期。也就说在这一个公共时钟周期内,发送端的发送数据必须保持不变,以保证接收端可以正确的采样。
在并行方式下,公共时钟周期必须大于数据在传输介质中的传输时间(数据从发送端到接收端的时间),否则也将无法正确采样。而并行方式中有几十根数据线,要遵循木桶原理,即保证数据传输最慢的那根数据线满足公共时钟周期,这也是为什么高速并行总线需要做等长处理。
所以并行方式要想提高传输速率,必须不断提高时钟频率。但是受限于传输时间,时钟频率不可能非常高。同时随着频率越来越高,并行的连线相互干扰异常严重,已经到了不可跨越的程度。再加上时钟相位偏移等因素,导致采用并行方式并不能满足越来越高的数据传输速率要求。
而采用串行的方式便可完美解决上述问题,时钟信号和数据信号一同编码在同一数据流中,数据流一位一位的传输,接收端从数据流中恢复时钟信息。由于没有时钟线,也就不存在时钟相位偏移。再加上数据包分解、标记和重组技术的进步,使得串行传输数据的速度可以越来越快。
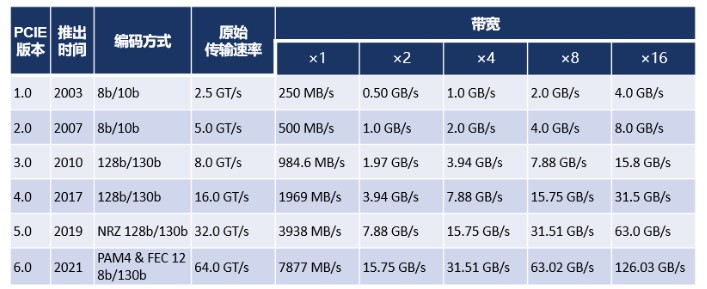
高速,PCIE目前已经正式发布6个标准版本,最新的为PCIE 6.0,其传输速率基本上遵循了下一代比上一代翻倍的定律。我们首先以PCIE 1.0来举例介绍下传输速率与我们更常用的带宽单位之间的关系。
PCIE标准中用GT/s(GigaTransfers per second,一秒内电位变化的次数)表示传输速率,而一次电位变化从数据角度来说就相当于传输了一个Bit。但是PCIE的电位变化并不全都用来传输有效数据,里面还包含了时钟信号。PICE 1.0采用的8/10b编码,就包含了2位时钟信号,这意味着传输8位有效数据要经历10次电位变化。(注:PCIE 3.0以前使用8/10b编码,PCIE 3.0及以后版本使用120/130b编码。)
PCIE 1.0标准中Lanex1的传输速率为2.5GT/s,换算成GBps为2GBps(2.5x8/10),换算成MB/s为250MB/s(2/8x1000),x2,x4,x8,x16依次类推。表1给出了PCIE 1.0到6.0不同Lane下的带宽数据。PCIE 6.0在Lanex16时可以提供高达126GB/s的带宽,这不就是汽车直男的心动女生吗。
表1 PCIE 1.0到6.0不同Lane下的带宽数据
而在2022年PCI-SIG开发者大会上,PCIE接口标准委员会PCI-SIG就公布了PCIE 7.0的规范目标,称其数据速率高达128 GT/s,并在2025年向其成员发布。这相当于在编码开销之前,通过16通道 (x16) 连接能实现512 GB/s的双向吞吐量。
PCIE拓扑结构
一、基于x86计算机系统
PCIE总线在x86计算机系统中作为局部总线,主要用来连接处理器系统中的外部设备。在x86计算机系统中,PCIE设备主要包括根复合体(Root Complex,RC),交换机(Switch),终端设备(Endpoingt),PCIE到PCI/PCI-X的桥(Bridge)等。一个典型的基于x86计算机系统的PCIE拓扑结构如图3所示。
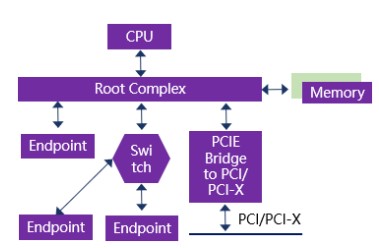
图3 基于x86计算机系统的PCIE拓扑结构
RC将PCIE总线端口、存储器等一系列与外部设备有关的接口都集成在一起。CPU平时比价忙,便会把很多事情交给RC去做,比如访问内存,通过内部PCIE总线及外部Bridge拓展出若干个其他的PCIE端口。
Endpoint作为终端设备,可以是PCIE SSD、PCIE网卡等,既可以挂载到RC上,也可以挂载到Switch上。
Switch扩展了PCIE端口,可以将数据由一个端口路由到另一个端口,从而实现多设备的互联,具体的路由方法包括ID路由,地址路由,隐含路由。靠近RC的端口称为上游端口,扩展出来的端口称为下游端口。下游端口可以挂载其他Switch或者Endpoint,并且对他们进行管理。
从上游过来的数据,它需要鉴定:(1)否是是传给自己的数据,如果是便接收;(2)是不是自己下游端口的数据,如果是便转发;(3)如果都不是,便拒绝。从下游端口挂载的Endpoint传给RC的数据,Switch会进行相应的仲裁,确定数据的优先级,并将优先级高的数据传送到上游端口中去。
Bridge则是用来实现PCIE设备与PCI/PCI-X设备之间的连接,实现两种不同协议之间的相互转换。
二、基于汽车
汽车电子电气架构的多样性,导致很难有像x86一样的统一架构。而基于中央计算架构,Mircochip曾给出过一种架构方案,如图4所示。
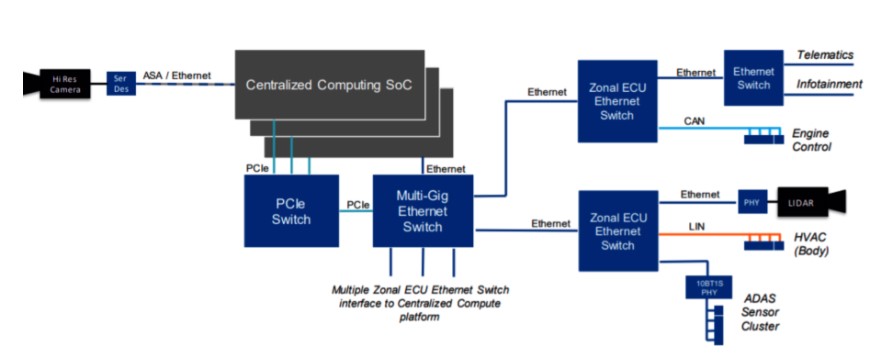
图4 汽车上的一种PCIE架构
在此架构中,PCIE Switch串联起整个片内通信。中央计算单元中的不同SOC,Ethernet Switch等均挂载其上面。外部传感器通过Zonal ECU的Ethernet Switch串联在一起。
PCIE分层体系
在PCIE总线中,数据报文在接收和发送过程中,需要经历三层蹂躏,包括事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)。各层又都包含发送和接收两块功能。这种分层的体系结构和网络的经典七层模型有异曲同工之妙,但不同的是,PCIE总线中每一层都是使用硬件逻辑实现的。
工作流程如图5所示,数据报文首先在设备A的核心层中产生,然后再经过该设备的事务层、数据链路层和物理层,最终发送出去。而接收端的数据也需要通过物理层、数据链路层和事务层,并最终到达设备B的核心层。
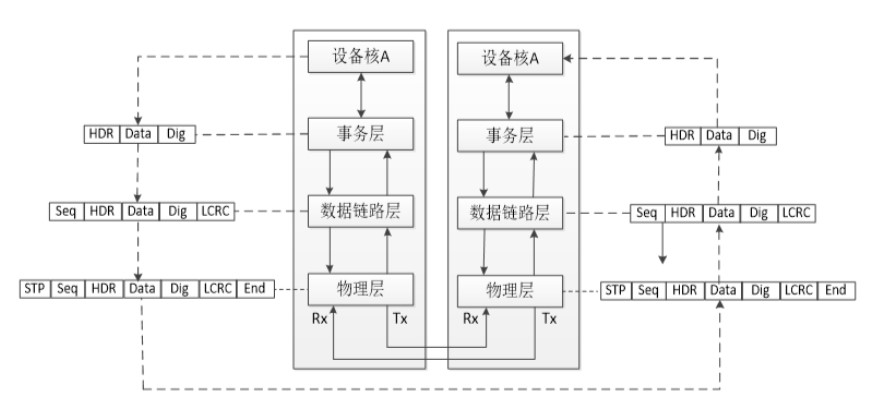
图5 PCIE工作流程
一、事务层。
事务层位于PCIE分层体系的最高层,一方面接收设备核心层的数据请求,封装为TLP(Transaction Layer Packet)并在TLP头中定义好总线事务后,发送给数据链路层。另一方面,从数据链路层中接收数据报文,掐头去尾保留有效数据后转发至PCIE设备核心层。
PCIE中定义的总线事务有存储器读写、I/O 读写、配置读写、Message总线事务和原子操作等总线事务。这些总线事务可以通过Switch等设备传送到其他PCIE设备或者RC。RC也可以使用这些总线事务访问PCIE设备。
以存储器读为例,网络中某个有需求的Endpoint初始化该请求后发送出去,请求经过Switch之后到达RC,RC收到存储器读请求后在系统缓存中抓取数据并回传完成报告。完成报告同样经过Switch后到达Endpoint,Endpoint收到完成报告后结束此次事务请求。
事务层还使用流量控制机制来保证PCIE链路的使用效率。
二、数据链路层
数据链路层在PCIE总线中发挥着承上启下的作用。来自事务层的报文在通过数据链路层时,将被添加Sequence Number前缀和CRC后缀,并使用ACK/NAK协议保证来自发送端事务层的报文可以可靠、完整地发送到接收端的数据链路层。来自物理层的报文在经过数据链路层时,会被剥离Sequence Number前缀和CRC后缀再被发送到事件层。
PCIE总线的数据链路层还定义了多种DLLP(Data Link Layer Packet),DLLP产生于数据链路层,终止于数据链路层。值得注意的是,TLP与DLLP并不相同,DLLP并不是由TLP加上Sequence Number前缀和CRC后缀组成的。
三、物理层
物理层是PCIE总线的最底层,将PCIE设备连接在一起。PCIE总线的物理电气特性决定了PCIE链路只能使用端到端的连接方式。PCIE总线的物理层为PCIE设备间的数据通信提供传送介质,为数据传送提供可靠的物理环境。
物理层是PCIE体系结构最重要,也是最难以实现的组成部分。PCIE总线的物理层定义了LTSSM(Link Training and Status State Machine)状态机,PCIE链路使用该状态机管理链路状态,并进行链路训练、链路恢复和电源管理。
PCIE总线的物理层还定义了一些专门的“序列”,有的书籍将物理层这些“序列”称为PLP(Phsical Layer Packer),这些序列用于同步PCIE链路,并进行链路管理。值得注意的是PCIE设备发送PLP与发送TLP的过程有所不同。对于系统软件而言,物理层几乎不可见,但是系统程序员仍有必要较为深入地理解物理层的工作原理。
汽车领域应用案例
一、理想
从网络上公开资料获悉,理想2023年要上市的新车,除了采用800V纯电平台,还将采用其最新的第三代架构LEEA3.0,如图6所示。LEEA3.0为中央计算平台+区域控制架构,中央计算平台很有可能采用类似工控机的模块化方案,将实现智能车控、自动驾驶和智能座舱功能的三块板子通过高性能交换机连接在一起,并设计到一套壳体中,有点类似特斯拉HW3.0的松耦合方案。
而高性能交换机的方案有两种,一种是PCIE Switch,一种是TSN Switch。PCIE Switch主要充当算力芯片之间“话事人”,通过提供20Gb/s以上的端到端的数据传输带宽,可以解决高带宽、低延时的痛点需求。同时通过物理隔离,单点失效将不会影响系统失效。TSN Switch主要充当与安全芯片及区域控制器的通信,提供时间确定性的数据流转发和数据交换。
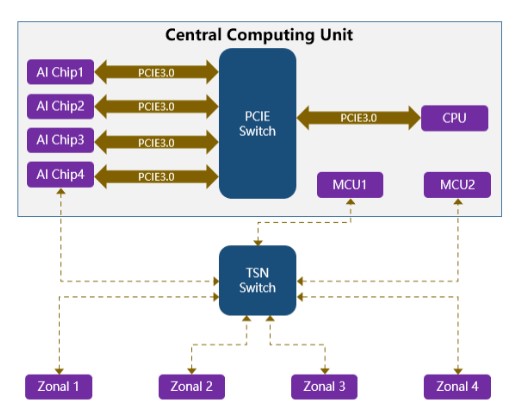
图6 LEEA3.0原理示意图(图片来源:基于网络公开资料整理)
二、Mircochip
2020年9月,Microchip在一期《Inter-Processor Connectivity for Future Centralized Vehicle Computer Platforms》分享中,共享了其对下一代中央计算平台的一些观点。什么区域配合计算中心、SOA、以太网,都是写老掉牙的话题,没什么新意。但在提到下一代架构以太网带宽的挑战时,预测中央计算平台中送入的数据量将达到200Gbps(说实话我愣是没估算出来,大家看下面图自己领悟吧),如图7所示。
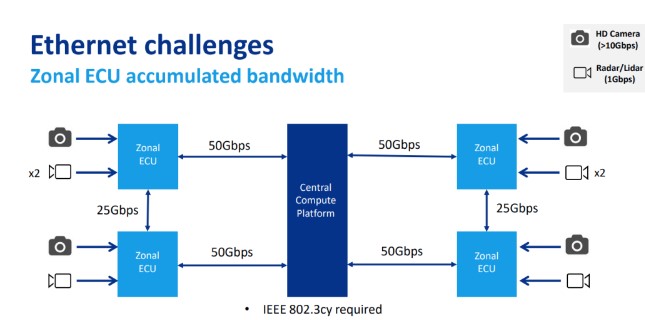
图7 以太网面临的带宽挑战(来源:Microchip官方材料)
中央计算单元为了解决这么大数据的涌入问题,必须采用PCIE。PCIE可挂载的Endpoint如图8所示。
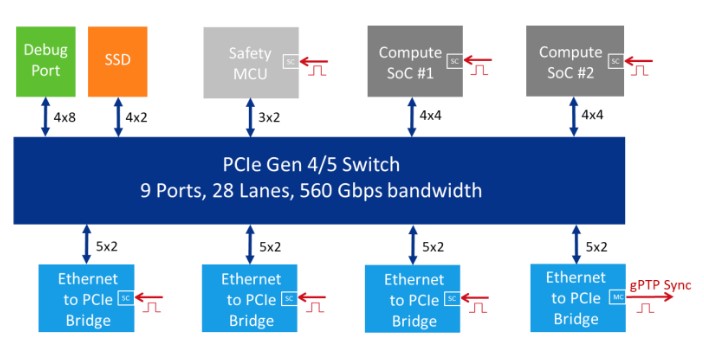
图8 PCIE挂载节点示意图(来源:Microchip官方材料)
基于以上需求,2022年2月,Mircochip宣布推出市场上首款通过汽车级认证的第四代PCIE交换机,提供了一种面向分布式异构计算系统的高速、低延迟连接解决方案,主要用于提供连接ADAS内CPU和加速器所需的最低延迟和高带宽性能。
审核编辑:刘清
-
Intel CPU架构升级将提升至5年,下一代架构代号NGC2020-02-11 4003
-
下一代高速芯片晶体管解制造问题解决了!2025-06-20 913
-
下一代定位与导航系统2012-08-18 2766
-
为什么说射频前端的一体化设计决定下一代移动设备?2019-08-01 3196
-
下一代SONET SDH设备2019-09-05 2694
-
单片光学实现下一代设计2019-09-20 3645
-
Zonal架构和中央集中软件下的氛围灯控制2023-02-09 1996
-
下一代宽带无线通信网络信令体系结构2011-05-24 1371
-
Imagination推出全新一代PowerVR Furian GPU架构 满足下一代消费类设备图形运算需求2017-03-10 1235
-
在英特尔架构上启用下一代分析2020-05-31 3816
-
下一代无线技术是VR下一代发展的缺失环节2019-08-11 1193
-
蔚来下一代电子电气架构技术原理解析2022-11-02 1968
-
中国移动联合华为等发布《下一代泛在实时通信网络需求、能力与架构理念白皮书》2023-11-04 3381
-
驱动下一代E/E架构的神经脉络进化—10BASE-T1S2025-07-08 799
-
中科创达与恩智浦共同打造面向下一代汽车中央计算架构的参考设计方案2026-04-30 445
全部0条评论

快来发表一下你的评论吧 !
