

基于VQVAE的长文本生成 利用离散code来建模文本篇章结构的方法
描述
写在前面
近年来,多个大规模预训练语言模型 GPT、BART、T5 等被提出,这些预训练模型在自动文摘等多个文本生成任务上显著优于非预训练语言模型。但对于开放式生成任务,如故事生成、新闻生成等,其输入信息有限,而要求输出内容丰富,经常需要生成多个句子或段落,在这些任务上预训练语言模型依然存在连贯性较差、缺乏常识等问题。本次与大家分享一篇建模长文本篇章结构的工作,用以提升生成文本的连贯性。
论文题目
《DISCODVT: Generating Long Text with Discourse-Aware Discrete Variational Transformer》
论文作者
Haozhe Ji, Minlie Huang
论文单位
清华大学
论文链接
https://github.com/cdjhz/DiscoDVT,EMNP2021/
1
动机(Motivation)
●
文本的全局连贯性一般表现为:
内容表达的流畅度;
内容之间的自然过渡。
如下图示例文本中的话语关系词(after, then, and, but 等),这些篇章关系词将连续的文本片段(text span)进行合理安排,从而形成结构、逻辑较好的文本。虽然预训练语言模型在关联与主题相关的内容时表现较好,但用好的篇章结构来安排内容仍然存在很多挑战。针对此问题,研究者提出建模文本内部片段与片段之间的篇章关系,利用篇章结构指导生成,以期能够改进生成文本的连贯性。

图 1 EDU片段和篇章关系示例
2
方法(Method)
●
任务定义
首先,长文本生成的任务可以定义为:给定输入 ,模型自动生成 的过程,即 。 基于以上的讨论,该工作基于 VQVAE 的方法提出 DiscoDVT(Discourse-aware Discrete Variational Transformer),首先引入一个离散code序列 ,学习文本中每个局部文本片段(span)的高层次结构,其中每一个 从大小为 的 code vocabulary 中得到。随后作者进一步提出一个篇章关系预测目标,使离散 code 能够捕获相邻文本片段之间显式的篇章关系,比如图 1 中的篇章关系,after,then 等。 整个方法包括后验网络 、生成器 和先验网络 ,使用类似 VAE 的学习目标,该方法通过最大化 ELBO 来优化。 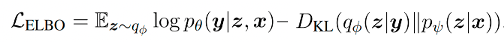 训练过程分为两个阶段:
训练过程分为两个阶段:
第一阶段联合训练后验网络和生成器,使后验网络根据 推导出离散的code序列 ,其中要求 能够学习到 的高层次结构,生成器则根据 和 code 序列 重构 ;
第二阶段训练先验网络,使其能够根据 ,预测离散 code 序列 。
两阶段训练完成之后,在生成阶段,先验网络首先根据 预测离散 code 序列 ,随后 用于指导生成文本, 中带有篇章结构信息,因此能够提升生成文本的连贯性。
学习离散隐变量
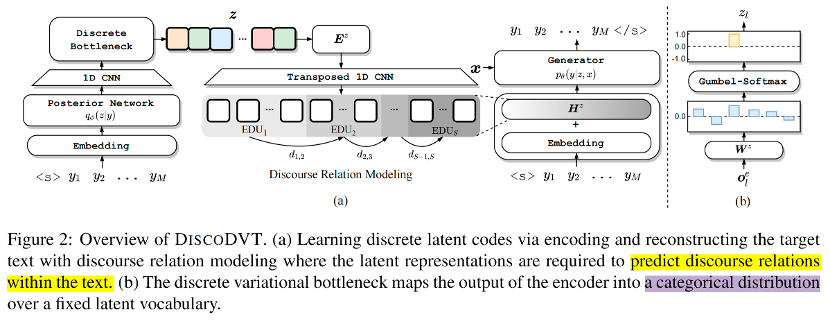
图 2 模型整体框架 这部分主要解决如何学习隐变量 code 序列 ,使其能够保留文本 的篇章结构。模型框架如上图所示,在编码阶段,首先使用编码器编码 得到语境化的表示,随后使用 CNN 和 Discrete Variational Bottleneck 技术得到离散 code 序列;在解码阶段,首先使用 transposed cnn 将 code embedding 序列的长度重新调整到文本 的长度,然后添加到解码器的嵌入层中进行 step-wise 的控制,重构生成 。重构生成的优化目标能够使离散 code 序列保存文本 中高层次的结构信息。 具体计算过程如下: 定义 code vocabulary 的大小为 ,以及随机初始化的 code embedding matrix 为 :
首先使用 Bart encoder 编码 得到语境化的表 ;
为了抽象出与文本的全局结构相对应的 high-level feature, 使用多层 CNN 对 进行卷积操作,得到 span-level 的表示 ;
随后使用 Discrete Variational Bottleneck 技术获得离散 code。具体地,将 CNN 的输出 线性映射到离散空间:
训练阶段通过 gumbel-softmax 方法采样得到 soft categorical distribution : 随后 categorical distribution 与 相乘得到 code embedding 。 在推理阶段则通过 argmax 方式得到离散 code 序列 :
为了使每个 code 能够指导局部文本的生成,首先利用 Transposed CNN 网络(与步骤2中使用的CNN对称),将code embedding 重新调整到 。(这里类似上采样的操作,将离散的 code embedding 序列的长度,恢复到原始文本 的长度,可以看到 的长度恢复为 。)之后, 与解码器输入的 token embedding 相加用于重构文本 。重构优化目标如下:
篇章关系建模 为了将文本的篇章结构抽象为 latent representation,作者设计了一个辅助的篇章关系感知目标,将篇章关系嵌入到离散化的 code 中。使用 bi-affine 建模相邻 EDU 片段 和 的篇章关系,使得 和 EDU 片段对应的 latent representation 能够预测出两者之间的篇章关系 。 最大化下述的对数概率: 其中, 和 分别表示第 个和 个EDU 片段的隐表示(latent representation)。 正则化隐变量 此外,作者在前期的实验中发现模型倾向于仅利用这个 code vocabulary 中少量的离散 code,这种现象会损害离散 code 的表达能力。为了鼓励模型尽可能等概率的利用离散 code,作者还引入基于熵的正则方法。
训练目标 在第一阶段中,联合上述的几个优化目标来训练后验网络和生成器,总的优化目标为: 离散 code 学习完成之后,作者使用额外的一个基于编码-解码的先验网络来学习给定 条件下离散 code 的先验分布 ,优化目标如下: 这里因为离散 code 已经学习完成,得到后验网络 ,对于原始的数据集 中的每一个 ,可以通过后验网络得到离散 code 序列 ,从而形成一个数据集 ,该数据集用于训练先验网络。
3
实验
●
数据集
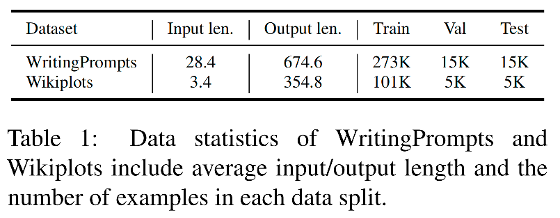
作者在公开的故事生成数据集 WritingPrompts 和 Wikiplots 数据集上评测所提方法,数据统计信息如下表所示。
baseline 模型对比
对比的 baseline 模型如下:
Seq2Seq:它是采用与 Bart 相同框架的编码-解码模型,没有经过预训练;
Bart:采用预训练 Bart 模型,并在下游数据集上对其微调;
Bart-LM:同样采用预训练 Bart 模型,先使用 bookcorpus 数据对其继续训练,随后在下游数据集进行微调;
BART-CVAE:基于 CVAE 的框架,引入连续隐变量到 Bart 模型,将隐变量加到解码器的 embedding 层指导生成文本;
Aristotelian Rescoring:它采用内容规划的方法,给定输入 ,它首先生成一个基于SRL 的情节,然后根据情节打分模型修改情节,最后基于修改的情节生成文本。
结果分析
下表展示了所有模型在两个数据集的自动评测结果。
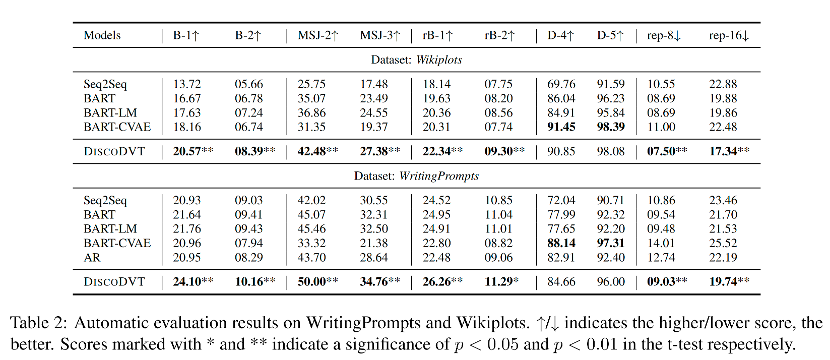
可以看到,在两个数据集上,在基于参考的指标上,DiscoDVT 生成的文本获得最高的n-gram 重叠度(BLEU)和相似度(MSJ)。多样性方面,DiscoDVT 在 distinct 指标上略微低于 BART-CVAE,这里作者进一步检查了 BART-CVAE 的生成文本,发现BART-CVAE 会生成不出现在参考文本中的虚假单词,从而提高了多样性。在重复度方面,由于 DiscoDVT 使用了 step-wise 的控制,因此 rep- 有较大幅度领先。 基于规划的方法 AR 可以获得较高的多样性,但在基于参考的指标上 BLEU、MSJ、rB 上的结果较低,这可能是多阶段方法中的暴露偏差,对生成质量有负面影响。
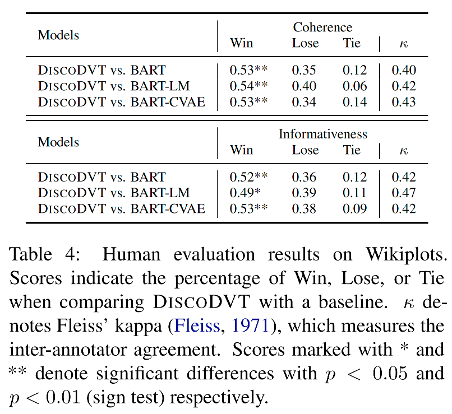
人工评测结果显示,在生成文本的连贯性和信息度方面,大多数 DiscoDVT 生成文本的质量要优于 BART, BART-LM 和 BART-CAVE baseline。

如上图所示,作者进一步对学习的 code 进行分析,可以发现离散的 code 确实能够学习到篇章关系,比如 and, so, when, however 等。
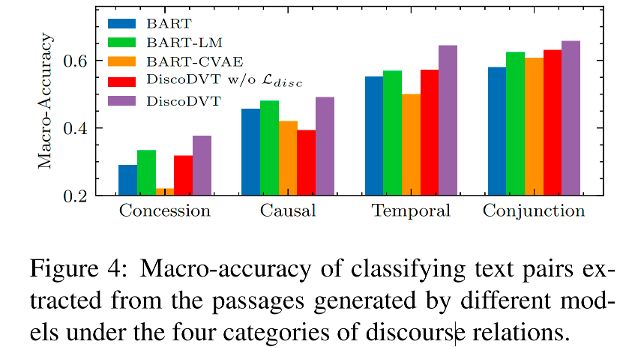
作者利用 discourse marker classifification 任务评测生成的篇章关系词是否正确,如上图所示。在让步、因果、时序和连接 4 种篇章关系上,DiscoDVT 生成文本中的篇章关系准确率最高,说明 DiscoDVT 生成的文本在篇章关系上质量更好。当去掉篇章关系建模的优化目标,生成的篇章关系准确率有明显下降,从而证明了篇章关系建模方法的有效性。
4
结语
●
本次分享展示了一种利用离散 code 来建模文本篇章结构的方法。该方法引入一个离散 code 序列学习文本的篇章结构,随后采用 step-wise 解码指导生成文本。为了建模显式的篇章关系,作者进一步提出了篇章关系建模优化目标。自动评测和人工评测结果证明了该方法的有效性。对于 code 的分析实验验证了离散 code 确实能够保留篇章关系的信息。
文本连贯性是自然语言生成的重要课题,目前改进的方法包括基于规划、建模高层次结构等方面,主要流程是首先生成文本大纲,再根据大纲生成完整的文本,其中大纲可以由关键词序列或者事件序列构成。整体来看,长文本生成中的篇章结构建模还仍不够成熟,存在诸多问题,期待未来有更多的工作取得改进。
作者来自:澜舟科技 杨二光 在此特别鸣谢!
北京交通大学自然语言处理实验室四年级博士生,导师为张玉洁教授,研究方向为可控文本生成、复述生成、故事生成。在澜舟科技实习期间主要从事长文本生成、营销文案生成等课题。
-
如何构建文本生成器?如何实现马尔可夫链以实现更快的预测模型2022-11-22 1423
-
三菱Q系列PLC编程手册(结构化文本篇)2018-03-07 4938
-
KUKA-C4机器人如何导出/导入长文本2020-12-23 5287
-
如何优雅地使用bert处理长文本2020-12-26 9843
-
给KUKA-C4机器人导入长文本方法2021-02-09 2857
-
面向搜索的微博短文本语义建模方法综述2021-06-24 942
-
文本生成任务中引入编辑方法的文本生成2021-07-23 2853
-
受控文本生成模型的一般架构及故事生成任务等方面的具体应用2021-10-13 5068
-
基于GPT-2进行文本生成2022-04-13 6094
-
KUKA-C4机器人导出/导入长文本2022-07-26 3470
-
MELSEC Q/L结构体编程手册(结构化文本篇)2022-08-25 706
-
ETH提出RecurrentGPT实现交互式超长文本生成2023-05-29 1895
-
面向结构化数据的文本生成技术研究2023-06-26 1826
-
Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama2023-08-25 2841
-
如何使用 Llama 3 进行文本生成2024-10-27 2065
全部0条评论

快来发表一下你的评论吧 !
