

在mysql中设计表为什么不建议采用uuid呢?
描述
背景
在 mysql 中设计表的时候,mysql 官方推荐不要使用 uuid 或者不连续不重复的雪花 id (long 形且唯一),而是推荐连续自增的主键 id,官方的推荐是 auto_increment,那么为什么不建议采用 uuid,使用 uuid 究竟有什么坏处?今天我们就来分析这个问题,探讨一下内部的原因。
数据展示
user_auto_key,user_uuid,user_random_key,分别表示自动增长的主键,uuid 作为主键,随机 key 作为主键,其它我们完全保持不变。根据控制变量法,我们只把每个表的主键使用不同的策略生成,而其他的字段完全一样,然后测试一下表的插入速度和查询速度: 注:这里的随机 key 其实是指用雪花算法算出来的前后不连续不重复无规律的 id: 一串 18 位长度的 long 值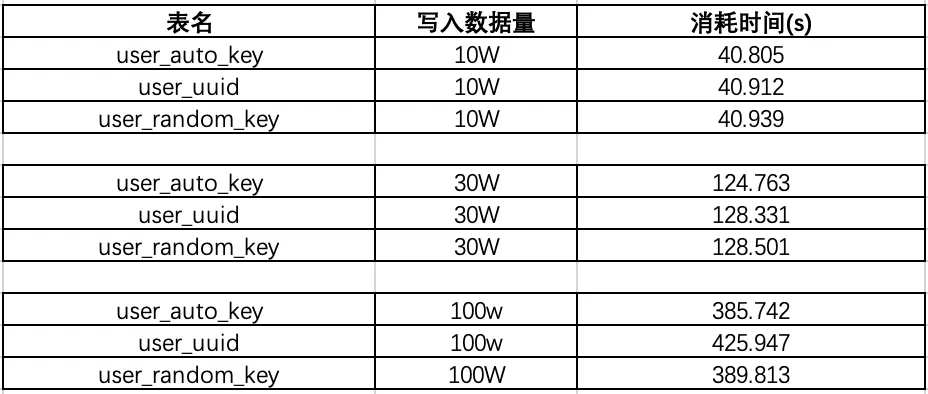

可以看出在数据量 100W 左右的时候,uuid 的插入效率垫底,并且在后续增加了 130W 的数据,uuid 的时间又直线下降。 时间占用量总体可以打出的效率排名为:auto_key>random_key>uuid,uuid 的效率最低,在数据量较大的情况下,效率直线下滑。
原因分析
对比一下 mysql 关于两者索引的使用情况. 自增的主键的值是顺序的,所以 Innodb 把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候 (innodb 默认的最大填充因子是页大小的 15/16, 会留出 1/16 的空间留作以后的修改):
①下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
②新插入的行一定会在原有的最大数据行下一行,mysql 定位和寻址很快,不会为计算新行的位置而做出额外的消耗
③减少了页分裂和碎片的产生 因为 uuid 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以 innodb 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
①:写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb 在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机 IO
②:因为写入是乱序的,innodb 不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上
③:由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片 在把随机值(uuid 和雪花 id)载入到聚簇索引 (innodb 默认的索引类型) 以后,有时候会需要做一次 OPTIMEIZE TABLE 来重建表并优化页的填充,这将又需要一定的时间消耗。
自增 ID 的缺点: 那么使用自增的 id 就完全没有坏处了吗?并不是,自增 id 也会存在以下几点问题:
①. 别人一旦爬取你的数据库,就可以根据数据库的自增 id 获取到你的业务增长信息,很容易分析出你的经营情况
②. 对于高并发的负载,innodb 在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
③. Auto_Increment 锁机制会造成自增锁的抢夺,有一定的性能损失
审核编辑:刘清
- 相关推荐
- 热点推荐
- MYSQL数据库
-
mysql为什么不推荐使用uuid呢?使用uuid究竟有什么坏处?2023-12-22 3426
-
labview 创建mysql 表时 设置时间 怎么在mysql中是格式是date 而不是datetime?2024-02-04 7506
-
mysql中文参考手册chm2008-12-26 14430
-
MySQL表分区类型及介绍2018-06-29 2533
-
为什么不建议在设备频率大于1MHz时使用FRC2019-08-27 1540
-
如何选择uuid以确保它与标准服务的现有uuid不冲突?2019-10-12 1387
-
如何利用labview获取MySQL数据库表中某一列的最大值2019-12-06 4687
-
请问UUID申明可以不声明GATT_CHAR_USER_DESC_UUID吗?2020-03-09 1910
-
在mysql中profile如何使用2020-04-24 1436
-
mysql表的结构修改、约束2020-05-21 2365
-
怎样在低功耗蓝牙中使用服务uuid AD类型呢?2022-12-12 549
-
如何获取APP及其动态库的UUID2017-09-25 1690
-
为什么不选择UUID?UUID有哪些特性2022-10-13 1987
-
Efinity在Debug时会出现UUID mismatch错误案例分享2023-02-20 3102
-
id的机制不同在mysql的索引结构以及优缺点2023-06-30 1594
全部0条评论

快来发表一下你的评论吧 !
