

浅谈Nitro V5、Graviton3E以及SRD网络传输协议
通信网络
描述
近日AWS re:Invent2022隆重召开,作为一年一度的云科技盛会,AWS高级副总裁Pete DeSantis介绍了 AWS 的一些重大工作成果与改进,主要包含硬件、网络、科学和软件四部分。本文将重点介绍Nitro V5、Graviton3E以及SRD网络传输协议方面的创新。
硬件:Nitro V5、Graviton3E
会上,AWS 宣布推出第五代Nitro网络安全芯片和硬件管理系统,以及全新基于ARM架构、自研的高性能计算服务器CPU芯片Graviton 3E。
Nitro V5
Nitro V5由 Annapurna Labs 团队打造,是AWS DPU的最新迭代。DeSantis 指出,与上代相比,Nitro V5采用的晶体管数量翻倍,内存速度提高了50%,PCIe带宽也实现了翻倍。这意味着Nitro V5每瓦性能提高40%,PPS(每包设备转发)性能提高60%,延迟降低30%,此外,能耗比也将提升大约30%。

Graviton 3E
AWS 专为高性能工作负载设计推出了新的 Graviton3E CPU。相比具有550亿个晶体管的Graviton 3,Graviton 3E在性能上有较大提升,包括并行负载执行效率(HPL)最高提升35%,用于金融相关运算执行效率提升30%。

DeSantis 表示,Graviton 3E在某些高性能计算能力上是现有Graviton芯片的两倍,当与其他AWS技术结合时新芯片的性能提高20%。在虚拟化应用部分,Graviton 3E芯片可组成最多64组虚拟CPU,并具有128GB存储容量,最快将在2023年初开始布署应用。
EC2 实例
DeSantis 还展示了三个新的 EC2 实例——C7gn、R7iz 和 Hpc7g。
1)C7gn由 AWS Graviton3E和 Nitro v5提供支持,专为要求苛刻的网络密集型工作负载而设计,例如虚拟网络设备和数据分析。C7gn实例支持高达 200 Gbps 的网络带宽和高达 50% 的数据包处理性能,它将提供多种尺寸,最多 64 个 vCPU 和 128 GiB 内存。
2)Hpc7g同样由 Graviton3E 提供支持,这个新实例将提供多种大小,最多 64 个 vCPU 和 128 GiB 内存。它旨在为紧密耦合的计算密集型 HPC 和分布式计算工作负载的公司提供最佳性价比。
3)R7iz由第 4 代英特尔至强可扩展处理器(代号 Sapphire Rapids)提供支持,将提供多种大小,最多 128 个 vCPU 和 1 TiB 内存。
客户变友商?
2021年,AWS业务净销售额为622.02亿美元,同比增长37%,是全球最大的云计算提供商,也是数据中心芯片的最大买家之一。但Graviton 3E的推出,使AWS与其合作伙伴英特尔、英伟达、AMD“芯片三巨头”展开竞争。
服务器芯片市场历来由英特尔主导,但近年来AMD 占据了很大一部分业务,英伟达的 GPU 也因运行AI系统和其他复杂任务而受到许多企业的青睐。AWS 相信自己也有机会从中获利,据悉,AWS在2015年收购了芯片制造商Annapurna Labs,随后开始自研芯片设计工作。
DeSantis 认为,与购买英特尔、英伟达或AMD芯片相比,AWS自研芯片将为客户提供更具性价比的算力支持。不过他也强调AWS与上述伙伴仍维持着密切的合作关系,并计划继续提供基于这些芯片厂商的高性能计算芯片相关服务。
网络:SRD协议
网络部分的重点是SRD网络协议,SRD全称Scalable Reliable Datagram,意思是可扩展的可靠数据报,SRD 是 AWS 为提高 HPC 性能而开发的一种高吞吐、低延迟的网络传输协议,并于 2019 年公布。DeSantis声称 SRD 协议优于 TCP。
1970 年代起出现的TCP/IP 虽然是目前以太网架构的主要传输手段,但它的问题在于不适合对延迟敏感的应用,TCP传输是一对一的连接,就算解决了时延的问题,也难在故障时重新快速连线。
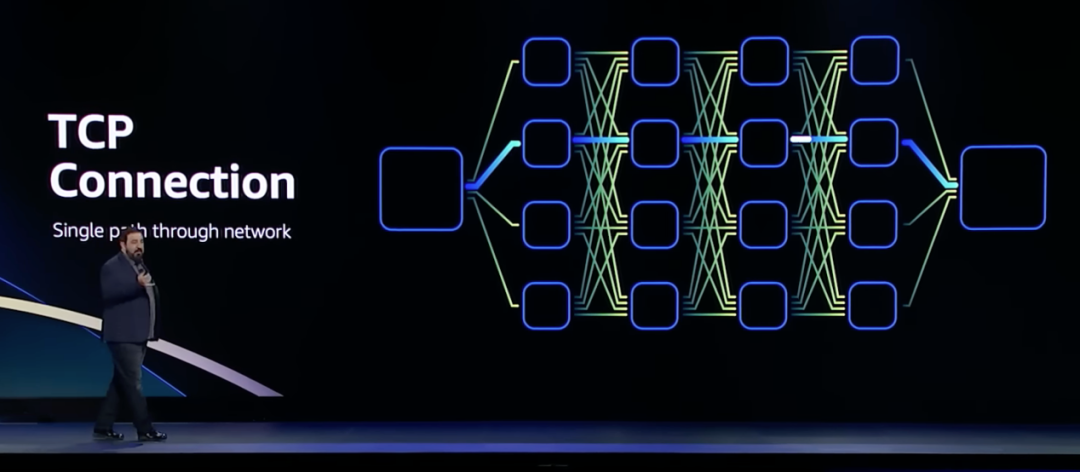
具体来看,数据中心中,理想情况下TCP的往返延迟为25us左右,如果发生拥塞或链路故障,TCP需要的等待时长会上升至50ms。带来这些延迟的主要原因是TCP丢包之后的重传机制。
TCP 是通用协议,没有针对HPC场景进行优化,早在2020 年,AWS 已经提出需要移除TCP。
SRD 协议是专门为AWS网络构建和优化的,可以将丢包重传的延时从毫秒级降低到微秒级。

SRD提供跨多个路径的负载平衡以及从数据包丢失或链路故障中快速恢复。利用商用以太网交换机上的标准ECMP功能并解决其局限性。SRD采用专门的拥塞控制算法,通过将排队保持在最低限度,有助于进一步降低丢包的机会并最大限度地减少重传时间。
SRD提供可靠但乱序的交付,并将次序恢复的任务留给上层。强制执行严格的有序交付通常只会造成队头阻塞、增加延迟并减少带宽。SRD不保留数据包顺序,而是通过尽可能多的网络路径发送数据包,同时避免路径过载。通过在接收处以极快的速度进行重新排序,最终在充分利用网络吞吐能力的基础上,极大降低传输延迟。
DeSantis表示,EFA、EBS和ENA都用上了自家的SRD。
EFA(Elastic Fabric Adapter)
EFA是用于大规模运行HPC/ML应用的高性能网络接口,直接与Nitro 控制器配合使用,实现更低延迟和更高吞吐量,支持内核旁路和RDMA。这避免了使用传统网络协议的上下文切换和内存复制带来的低延迟和性能下降。对性能敏感的应用更适合使用EFA。

EBS(Elastic Block Store)
EBS为EC2实例提供块级存储,它被各种任务关键型应用(如IO密集型数据库使用),对于块存储,性能、离群值、尾部延迟都很重要。EBS对网络延迟最敏感的地方之一是写入,它能将极少数(P99.999)会出现的35ms延迟降低五倍,并且能将整体的延迟水平降到一个全新的水平。
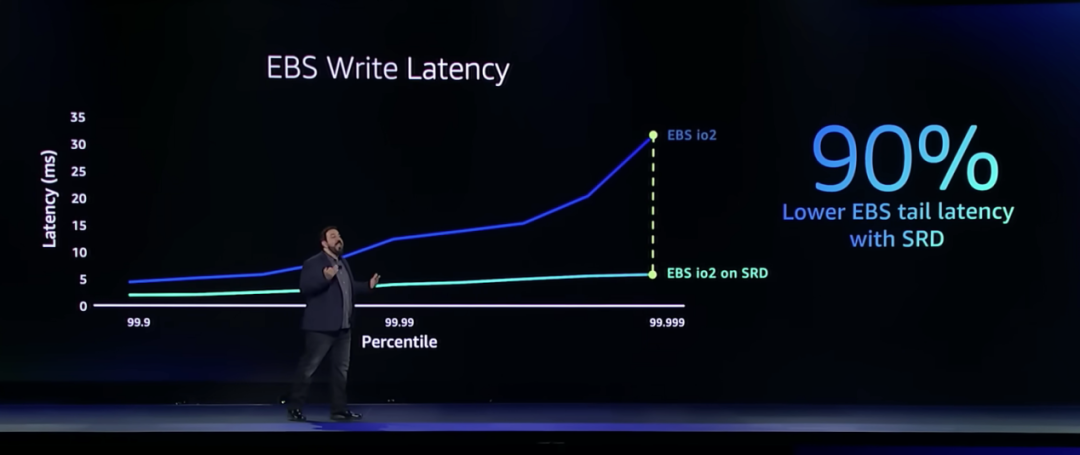
EBS和SRD的结合还将吞吐量提高了4倍。

DeSantis表示即将推出的新的EBS io2 数据平台,将与SRD 一起运行。
ENA(Elastic Network Adapter)
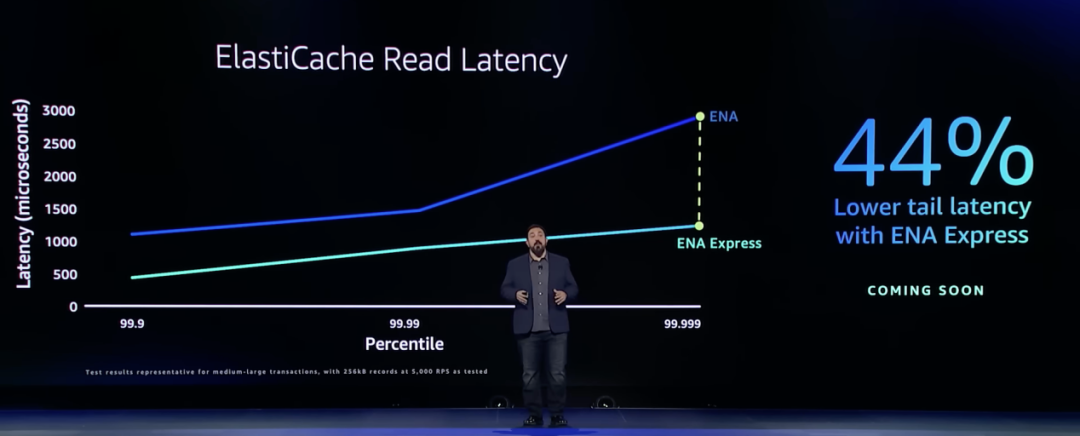
ENA是用于EC2实例的标准网络驱动程序。ENA利用Nitro控制器从主EC2服务器卸载工作,允许客户讲更多资源用于他们的工作负载。ENA Express可以引入任何网络接口,可以与任何网络协议(如TCP/UDP)一起工作,只需在ENA上启用ENA Express接口,就可以获得更低延迟和更高吞吐量。

科学:机器学习
科学方面的创新主要讨论的是机器学习,DeSantis谈到的两大性能改进是:
1)使用STOCHASTIC ROUNDING,使用户能够同时获得16位计算精度的训练速度和32位的计算精度。
2)Ring of Rings 算法使计算处理器能够在模型每次迭代后更有效地交换信息,从而使处理器之间的同步速度提高 75%。
软件:Lambda SnapStart
软件运行方面的创新主要谈的是Lambda SnapStart。Lambda 是一项计算服务,是 Serverless 技术的先驱者,使用者无需预置或管理服务器即可运行代码。
Lambda 最大的优势就是模型操作简单、价格经济实惠,但仍面临着“冷启动”这一挑战,Lambda SnapStart 通过使用Firecracker及快照功能将性能提高90%,减少了Lambda运行软件应用时的冷启动时间。此外,Lambda SnapStart可以对延迟敏感的 Java 应用程序提供高达 10 倍更快启动时间的改进性能,只需最少或无需更改代码。
值得一提的是,DeSantis称 Amazon Lambda SnapStart 版本自发布起免费向公众开放,Amazon Lambda SnapStart 项目地址:
https://github.com/aws/aws-lambda-snapstart-java-rules
编辑:黄飞
-
CATIA V5安装详细说明2011-01-22 1942
-
采用μC/OS-II实现V5接口2019-05-06 1601
-
信号通过V5芯片上的铜线的传输速度是多少?2020-06-04 1618
-
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用2022-08-31 3940
-
V5协议,V5协议内容有哪些?2010-03-29 2150
-
沈阳唯实V5巡更方案2011-04-17 1200
-
Ncstudio V5操作说明2016-05-04 939
-
MPU6050资料V52016-06-22 1134
-
伺服选型手册v5(2016.02.15)2016-12-23 862
-
英特尔正式发布至强处理器 E3 v5 & v6 等系列处理器2020-08-26 9014
-
realme V5怎么样?拆解realme V5 评测5G手机的性价比2020-09-07 18538
-
利用 MPLAB® Harmony v3 TCP/IP协议栈在SAM E54 MCU 上实现文件传输协议2023-12-18 788
-
信捷V5 - F5变频器接入到Profibus网络的关键2025-06-20 1593
全部0条评论

快来发表一下你的评论吧 !
