

InfiniBand网络设计和研究
电子说
描述
InfiniBand是目前发展最快的高速互连网络技术之一,具有高带宽、低延迟和易扩展的特点。通过研究和实践,对InfiniBand技术的数据包、数据传输、层次结构、与以太网技术的对比、交换机制、发展愿景等进行了全面探索。
01 引言
随着中央处理器(CPU)运算能力的极速增长,高速互连网络HIS (High Speed Interconnection)已成为高性能计算机研制的关键所在。HSI 是改善计算机外围元件扩展接口(Peripheral Component Interface,PCI) 的性能不足而提出的一项新技术。经过多年的发展,支持高性能计算(High Performance Computing,HPC) 的HSI目前主要是Gigabit Ethernet 和InfiniBand,而InfiniBand 是其中增长最快的HSI。InfiniBand 是在InfiniBand贸易协会(IBTA)监督下发展起来的一种高性能、低延迟的技术。
02 InfiniBand Trade
Association(IBTA)
IBTA 成立于1999年,由Future I/O Developers Forum 和NGI/O Forum 两个工业组织合二为一组成,在HP、IBM、Intel、Mellanox、Oracle、QLogic、Dell、Bull 等组成的筹划运作委员会领导下工作。IBTA 专业从事产品的遵从性和互用性测试,其成员一直致力于推进InfiniBand 规范的设立与更新。
03 InfiniBand 概述
InfiniBand是一种针对处理器与I/O 设备之间数据流的通信链路,其支持的可寻址设备高达64000 个。InfiniBand架构(InfiniBand Architecture,IBA) 是一种定义点到点(point-to-point)交换式的输入/ 输出框架的行业标准规范,通常用于服务器、通信基础设施、存储设备和嵌入式系统的互连。
InfiniBand具有普适、低延迟、高带宽、管理成本低的特性,是单一连接多数据流(聚类、通信、存储、管理)理想的连接网络,互连节点可达成千上万。最小的完整IBA 单元是子网(subnet),多个子网由路由器连接起来组成大的IBA 网络。IBA 子网由端节点(end-node)、交换机、链路和子网管理器组成。
InfiniBand发展的初衷是把服务器总线网络化,所以InfiniBand 除了具有很强的网络性能以外还直接继承了总线的高带宽和低时延。总线技术中采用的DMA(Direct Memory Access) 技术在InfiniBand 中以RDMA (Remote Direct Memory Access)的形式得以实现。RDMA服务可在处理器之间进行跨网络数据传输,数据直接在暂时内存之间传递,不需要操作系统介入或数据复制。RDMA 通过减少对带宽和处理器开销的需要降低了时延,这种效果是通过在NIC 的硬件中部署一项可靠的传输协议以及支持零复制网络技术和内核内存旁路实现的。
这使得InfiniBand 在与、及存储设备的数据交换方面天生地优于万兆以太网以及光纤通道(FiberChannel)。InfiniBand 实现了基于客户机- 服务器和消息传递的通信方案及基于存储映射实现网络通信的方案,将复杂的I/O系统与处理器、存储设备分离,使I/O 子系统独立,是一种基于I/O 通道共享机制的总线互连技术。
InfiniBand系统由信道适配器(Channel Adapter)、交换机、路由器、线缆和连接器组成。CA 分为主机信道适配器(Host Channel Adapter) 和目标信道适配器(Target ChannelAdapter)。IBA 交换机原理上与其它标准网络交换机类似,但必须能满足InfiniBand 的高性能和低成本的要求。InfiniBand 路由器是用来把大网络分割为更小的子网,并用路由器连接在一起。HCA 是一个设备点,诸如服务器或存储设备的IB 端节点通过该设备点连接到IB 网络。TCA是信道适配器的一种特别形式,多用于存储设备等嵌入式环境。
InfiniBand 体系结构如图1所示:
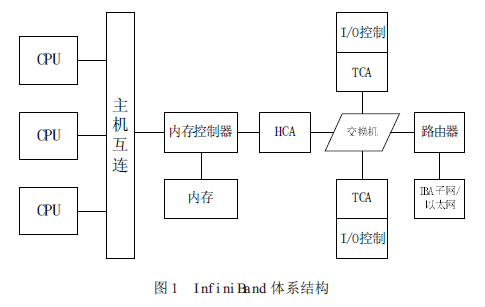
InfiniBand有几大优势,基于标准的协议、高速率、远程直接内存存取(RDMA)、传输卸载(transport offload)、网络分区和服务质量(QoS)。
标准:成立于1999年的IBTA 拥有300 多个成员,它们共同设计了IBA 开放标准。IBA 支持SRP(SCSI RDMA Protocol)和iSER(iSCSI Extensions for RDMA)存储协议。
速率:InfiniBand传输速率目前已达168Gbps(12xFDR),远远高于万兆光纤通道的10Gbps 和10 万兆以太网的100Gbps。
内存:支持InfiniBand的服务器使用主机通道适配器(HCA),把协议转换到服务器内部的PCI-X或PCI-E 总线。HCA 具有RDMA 功能,RDMA 通过一个虚拟的寻址方案,数据直接在服务器内存中传输,无需涉及操作系统的内核,这对于集群来说很适合。
传输卸载:RDMA实现了传输卸载,使数据包路由从操作系统转到芯片级,大大节省了处理器的处理负担。网络分区:支持可编程的分区密钥和路由。
服务质量:多层次的QoS 保障,满足服务请求者对QoS需求的多样性。
04 InfiniBand 数据包和数据传输
数据包(Packet)是InfiniBand 数据传输的基本单元。为使信息在InfiniBand 网络中有效传播,信息由信道适配器分割成许多的数据包。一个完整的IBA 数据包由本地路由报头(Local Route Header)、全局路由报头(Global Route Header)、基本传输报头(Base TransportHeader)、扩展传输报头(Extended Transport Header)、净荷(Payload,PYLD)、固定循环冗余检测(Invariant CRC,ICRC)和可变循环冗余检测(Variant CRC,VCRC)等域(field)组成,如图2 所示。
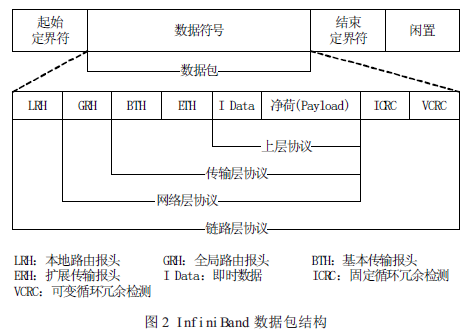
LRH:8 字节,用于交换机转发数据包时确定本地源端口和目的端口以及规范数据包传输的服务等级和虚通路(Virtual Lane,VL)。
GRH:40 字节,用于对子网间的数据包进行路由,确保数据包在子网之间的正确传输。它由LRH 中的Link Next Header(LNH)域指定,采用RFC 2460 定义的IPv6 报头规范。
BTH:12 字节,指明目的队列偶(Queue Pair,QP)、指示操作码、数据包序列号和分段。
ETH:4-28 字节,提供可靠数据报(Datagram)服务。Payload (PYLD):0-4096 字节,被发送的端到端应用数据。
ICRC:4 字节,封装数据包中从源地址发往目的地址时保持不变的数据。
VCRC:2 字节,封装链接过程中可变的IBA 和原始(raw)数据包。VCRC 在结构(fabric)中可被重构。
InfiniBand数据包使用一个128 位的IPv6 扩展地址,其数据包包括InfiniBand GRH 中的源(HCA)和目的(TCA)地址,这些地址使InfiniBand 交换机可以立即将数据包直接交换到正确的设备上。
基于铜缆和光纤,InfiniBand物理层支持单线(1X)、4 线(4X)、8 线(8X)和12 线(12X)数据包传输。
InfiniBand标准支持单倍速(SDR)、双倍速(DDR)、四倍速(QDR)、十四倍速(FDR)和增强倍速(EDR)数据传输速率,使InfiniBand 能够传输更大的数据量( 见表1)。由于InfiniBand DDR/QDR 极大地改善了性能,所以它特别适合于传输大数据文件的应用,如分布式数据库和数据挖掘应用。
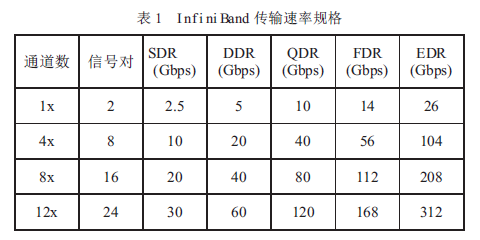
与InfiniBandSDR 一样,DDR 和QDR 也采用了直通转发技术(Cut-Through)。如果采用不同的传输速率,则InfiniBand 子网管理器须是拓扑透明(Topology-aware)的,并只把SDR 数据包转发至SDR 连接(或把DDR 数据包转发至DDR 连接),或者交换网络须能存储和转发数据包以提供速率匹配。
当在SDR 和DDR 连接之间进行数据交换时,附加的存储转发延时是数据包串行化延时的一半。为了在SDR 主机和DDR 主机进行数据交换,DDR主机根据连接建立时交换产生的QP 参数进行限速传输。
05 InfiniBand 架构层次结构
根据IBTA 的定义,InfiniBand 架构由物理层、链路层、网络层和传输层组成,其层次结构如图3所示。
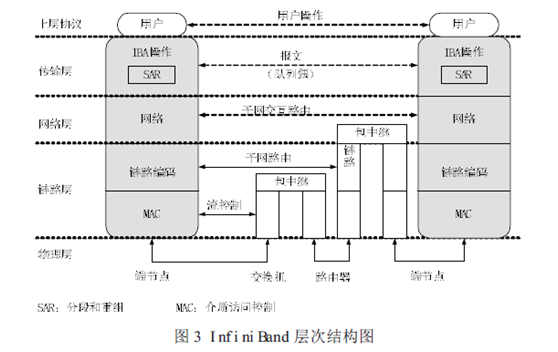
物理层:物理层为链路层提供服务,并提供这两层的逻辑接口。物理层由端口信号连接器、物理连接(电信号和光信号)、硬件管理、电源管理、编码线等模块组成,其主要的作用:
(1)建立物理连接;
(2)通知链路层物理连接是否有效;
(3)监听物理连接状态,在物理连接有效时,把控制信号和数据传递给链路层,传输从链路层来的控制和数据信息。
链路层:链路层负责处理数据包中链接数据的收发,提供地址、缓冲、流控制、错误检测和数据交换等服务。服务质量(QoS)主要由该层体现。状态机(state machine)用来把链路层的逻辑操作定义为外部可访问操作,并不指定内部操作。
例如,虽然我们希望链路层的操作能够并行处理数据流的多个字节,但数据包接收状态机还是将从链路层接收到的数据作为字节流来处理。
网络层:网络层负责对IBA 子网间的数据包进行路由,包括单点传送(unicast)和多点传送(multicast)操作。网络层不指定多协议路由(如非IBA 类型之上的IBA 路由),也不指定IBA 子网间原始数据包是如何路由。
传输层:每个IBA数据包含有一个传输报头(header)。传输报头包含了端节点所需的信息以完成指定的操作。通过操控QP,传输层的IBA 通道适配器通信客户端组成了“发送”工作队列和“接收”工作队列。
对于主机来说,传输层的客户端是一个Verbs 软件层,客户端传递缓冲器或命令至这些队列,硬件则往来传送缓冲器数据。当建立QP时,它融合了四种IBA 传输服务类型(可靠的连接、可靠的自带寻址信息、不可靠的自带寻址信息、不可靠的连接)中的一种或非IBA协议封装服务。传输服务描述了可靠性和QP 传送数据的工作原理和传输内容。
06 InfiniBand 的交换机制
InfiniBand所采用的交换结构(Switched Fabric)是一种面向系统故障容忍性和可扩展性的基于交换的点到点互联结构。
交换机主要作用是把数据包送达数据包本地路由报头指定的目标地址,同时交换机也耗用数据包以满足自管理的需要。IBA 交换机是内部子网路由的基本路由构件(子网间路由功能由IBA 路由器提供)。交换机的相互连接由链路间的中继数据包(relaying packets)来完成。
InfiniBand交换机实现的功能有:子网管理代理(SMA)、性能管理代理(PMA)和基板管理代理(BMA)。SMA 提供一个让子网管理者通过子网管理包获得交换机内部的记录和表数据的接口,实现消息通知、服务等级(Service Level,SL)到虚路径(Virtual Lane,VL)的映射、VL 仲裁、多播转发、供应商特性等功能。PMA 提供一个让性能管理者监控交换机的数据吞吐量和错误累计量等性能信息的接口。BMA 在基板管理者和底架管理者之间提供一个通信通道。
InfiniBand交换机的数据转发主要功能:
(1)选择输出端口:根据数据包的本地目的标识符(Destination Local Identifier,DLID),交换机从转发表中查出输出端口的端口号。
(2)选择输出VL:支持SL 和VL。交换机根据SL-VL 映射表确定不同优先级别的数据包所使用输出端口的VL。
(3)数据流控制:采用基于信用的链路级流控机制。
(4)支持单播、多播和广播:交换机能把多播包或广播包转换为多个单播包进行交换。
(5)分区划分:只有同一分区的主机才能相互通信。每个分区具有唯一的分区密钥,交换机检查数据包的DLID 是否在密钥所对应的分区内。
(6)错误校验:包括不一致错误检验、编码错误校验、成帧错误校验、包长度校验、包头版本校验、服务级别有效性校验、流控制遵从和最大传输单元校验。
(7)VL 仲裁:支持子网VL(包括管理VL15 和数据VL)。交换机采用VL 仲裁保证优先级高的数据包得到更好的服务。
目前生产InfiniBand交换机的厂商主要有Mallanox、QLogic、Cisco、IBM 等。
07 InfiniBand 与以太网
从InfiniBand的诞生、发展,到现在占据HPC 领域的主流地位,人们总会拿它与普遍采用的以太网技术做比较。作者整理两者的比较如表2 所示。
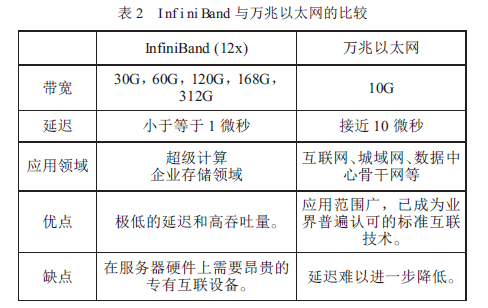
从表2 可知,InfiniBand 在数据传输和低延迟两方面大大超过了以太网。InfiniBand 的低延迟设计使得它极其适合高性能计算领域。此外,InfiniBand 在单位成本方面也具有相当的优势。
从最新的全球HPCTOP500中可以发现,Infiniband 的占有率不断提高,其在TOP100 中更是占主导地位,而以太网的占有率则逐年下降,目前两者在HPC 领域的占有率基本持平。
08 结束语
随着InfiniBand的不断发展,它已成为取代千兆/ 万兆以太网的最佳方案,必将成为高速互连网络的首选,其与以太网络、iSCSI 融合将更加紧密。IBTA 对InfiniBand的发展作出了预测,表明在未来三年里InfiniBand FDR、EDR 和HDR 将有快速增长的市场需求,2020 年之前InfiniBand 的带宽将有望达到1000Gbps。InfiniBand 未来在GPU、固态硬盘和集群数据库方面将有广阔的应用前景。
审核编辑 :李倩
-
端到端InfiniBand网络解决LLM训练瓶颈2024-10-23 20312
-
深入探索InfiniBand网络、HDR与IB技术2024-04-19 3529
-
一文详解超算中的InfiniBand网络、HDR与IB2024-04-16 15606
-
态路小课堂丨InfiniBand与以太网:AI时代的网络差异2023-11-29 2064
-
InfiniBand AOC有源光缆简介2023-10-26 1545
-
InfiniBand的网络架构及技术原理解析2023-08-09 5430
-
关于InfiniBand网络相关内容简介!2023-03-21 2488
-
InfiniBand和远程直接访问是什么,如何进行配置2022-11-25 2781
-
NVIDIA发布新一代InfiniBand网络平台2021-11-12 3370
-
InfiniBand系统级调试2019-09-10 1512
-
InfiniBand的SMI/O模块的电源管理解决方案2017-06-26 949
-
实现InfiniBand网络优化自动化HPC管理工具2010-05-24 1066
-
InfiniBand,InfiniBand是什么意思2010-04-10 1385
-
InfiniBand 连接现在和未来2009-11-13 3635
全部0条评论

快来发表一下你的评论吧 !
