

王井东:大模型已经成为自动驾驶能力提升核心驱动力
描述
百度Apollo Day技术开放日
2022年11月29日,百度Apollo Day技术开放日活动线上举办。百度自动驾驶技术专家全景化展示Apollo技术实力及前沿技术理念,在业内首发文心大模型落地应用于自动驾驶的技术。
大模型技术是自动驾驶行业近年的热议趋势,但能否落地应用、能否用好是关键难题。百度自动驾驶依托文心大模型特色优势,率先实现技术应用突破。百度自动驾驶技术专家王井东表示:文心大模型-图文弱监督预训练模型,背靠文心图文大模型数千种物体识别能力,大幅扩充自动驾驶语义识别数据,如:特殊车辆(消防车、救护车)识别、塑料袋等,自动驾驶长尾问题解决效率指数级提升;此外,得益于文心大模型-自动驾驶感知模型10亿以上参数规模,通过大模型训练小模型,自动驾驶感知泛化能力显著增强。
以下为演讲全文
大家好,我是王井东,由我跟大家分享自动驾驶感知相关的内容,我演讲的标题是:文心大模型在自动驾驶感知中的落地应用。
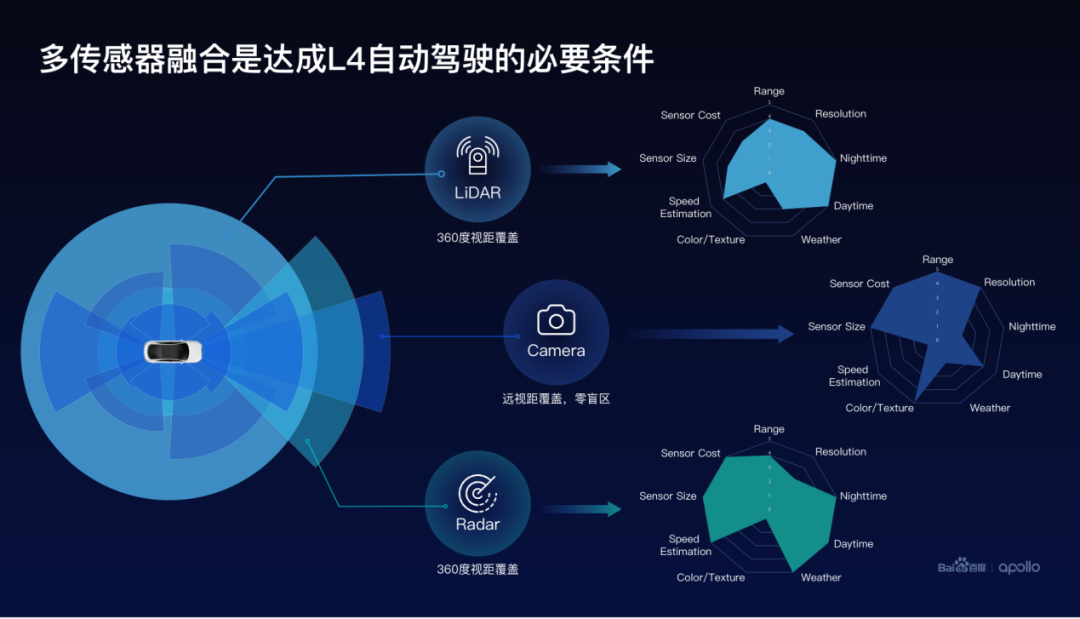
百度认为传感器融合是实现L4自动驾驶的必要条件,激光点云、毫米波雷达和摄像头这三种传感器是如何实现互补关系的。激光点云和毫米波雷达点云不能够提供很丰富的颜色信息和纹理信息,使得点云的识别效果一般。摄像头可以提供丰富的颜色纹理等信息,能够帮助提升语义识别的效果。
那激光点云和摄像头在天气不佳的条件下,如雨雪天气,感知效果受到限制,这个时候毫米波雷达点云仍然能够提供很好的效果,那毫米波雷达点云相对而言噪声比较大,分辨率比较低,这个时候雷达和摄像头提供了分辨率非常高的互补信息。
除此以外,摄像头相对远距离的感知效果比较友好。
百度自动驾驶感知经历了两代,第一代感知1.0,在感知1.0经过了三个阶段:
第一阶段
主要依赖激光雷达点云感知,辅助红绿灯的识别,同时利用了毫米波目标阵列。
第二阶段
增加了环视图像的感知,与激光雷达点云感知形成了两层的感知融合,提升了识别效果。
第三阶段
自研了毫米波点云感知算法,形成了三层感知的融合,那这些多模感知实际上用的是后融合的方案。
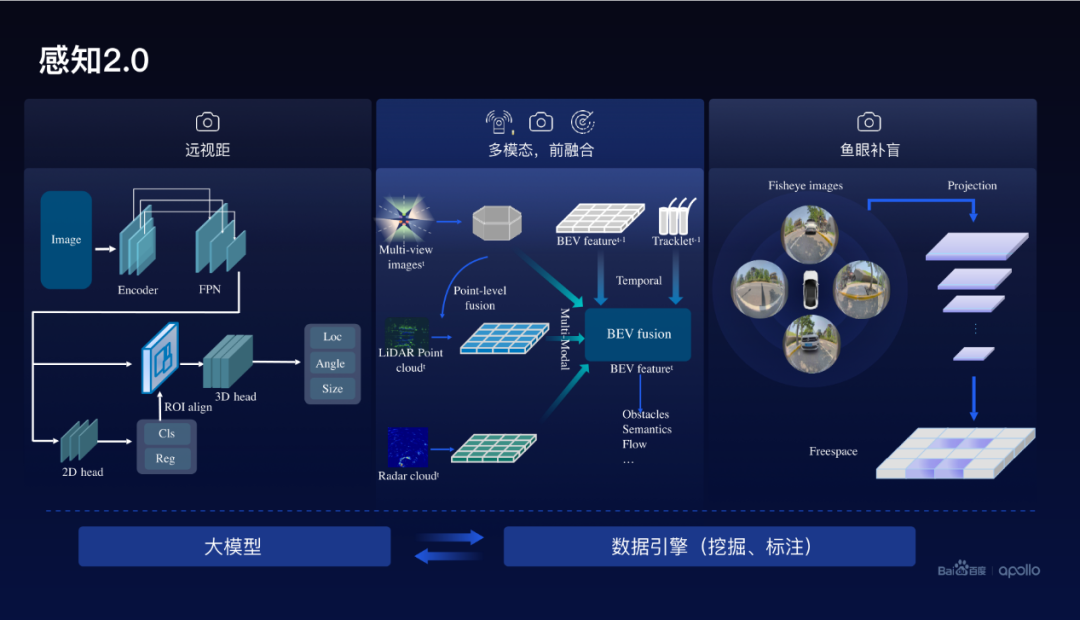
在后融合方案里面通常需要规则的方法,把这三种传感器的感知结果融合在一起,那这种基于规则的方法是不可学习的,它相对而言它的泛化能力不够。基于此,百度开发了基于前融合方案的新一代感知2.0。

感知2.0主要的一个部分是多模态前融合端到端的方案,在点云和图像的表征层次上进行融合。除此以外,还包括远视距的视觉感知,通常在200米以上视觉的感知效果相对比较好。
另外,在近距离采用了鱼眼感知,从鱼眼感知实现了freespace的预测,百度把这三者有机的融合在一起,实现了近距离、中等距离和远距离统统形成高质量的这种感知。
在做感知时候,需要丰富的数据、高质量的数据,基于此,百度在2.0还利用大模型进行数据挖掘和数据的自动标注。
下面看几个例子,看看在自动驾驶感知里面遇到的一些挑战。
首先远距离的视觉感知,在较远的地方,物体看起来是比较小的,分辨率是比较低的,这对识别和感知带来非常大的挑战。那在远距离的情况下面,通常会遇到坡度比较大,对于感知也是非常大的挑战。大部分的数据都是地平面的,道路是平的,那这里面往往会利用了地平面接地这样一个重要的性质,去实现远距离物体的感知。

下面再看看第二个挑战,因为我们采用的激光雷达传感器不断的升级,那点云的空间分布也产生了非常大的变化,在早先激光雷达传感器基于威力登,后来我们升级为两种型号的禾赛,目前正在考虑启用半固态的传感器,这些传感器升级带来了点云空间的分布的变化,从原来的稀疏到现在的稠密,在点云空间去做3D的标注是非常困难的,能不能把以前旧的传感器的标注在新的传感器能很好利用起来,也成为技术上的一个重要挑战。

下面是长尾数据挖掘的问题,这里面举了三类典型的例子:
第一类是少见的车型,比如说异形车出现的频率比较低,通常这种异型车它的形态、形状不太规则,甚至有时候会有一些突出的部件,那这个时候会为感知、理解带来挑战,很难很好地定位这些异形车的空间位置以及距离。
第二类是各种形态、各种姿态的行人,这个时候可能是一群人在道路上面,这样会带来非常大的挑战,同时也为后面的预测跟踪带来很大的挑战。
第三类是低矮物体以及交通、施工的元素,那低矮物体一直是感知里面非常有挑战的问题,那我们在实践过程里面你会发现一些施工元素会对我们自动驾驶感知带来一些问题,比如说道路中间的护栏,其实往往意味着这条路可能是不可通行的,那我们需要识别这样的道路施工元素。

那如何解决刚才提到的这三种挑战呢?百度利用了大模型技术来提升自动驾驶感知的能力,从两个方面去解决这个自动驾驶感知遇到的挑战。
第一个,利用文心大模型自动驾驶感知的技术,来提升车载小模型的感知能力,另外,在数据方面,利用了文心大模型图像弱监督预训练的模型来挖掘长尾数据,来提升模型训练的效果。

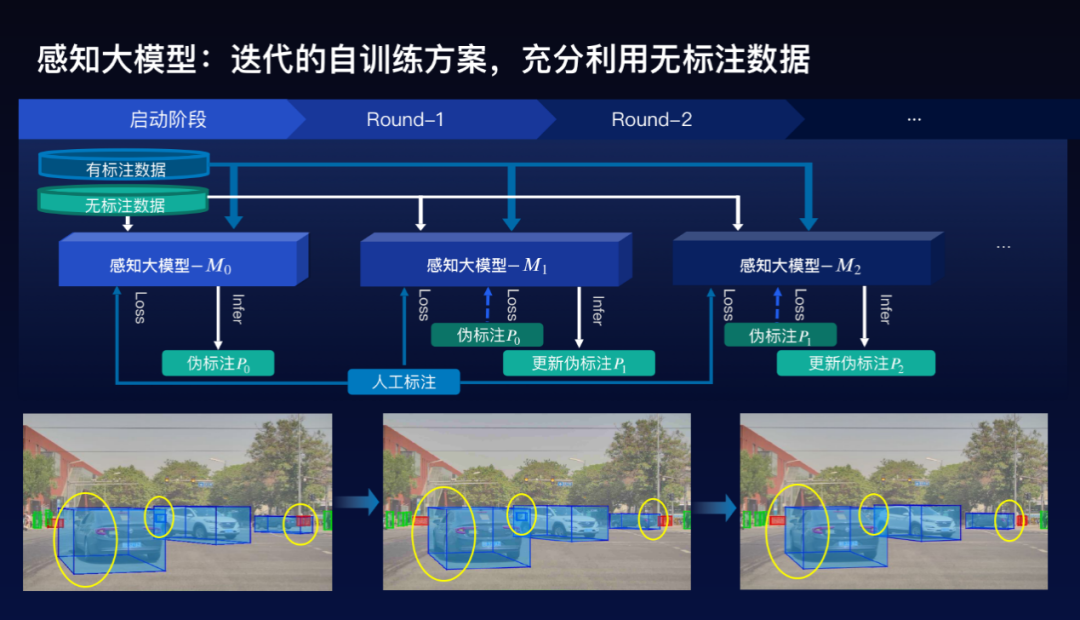
这个自动驾驶感知大模型是怎么训练的。在自动驾驶感知里面,需要标注大量的数据,但是在这里面,往往相对而言容易获得千万量级的2D的标注数据,但对3D的标注数据来讲相对比较困难,如何利用这些没有3D标注的数据是成为一个很大的挑战,百度采用半监督的方法来充分利用2D的标注和没有3D标注的数据。
具体方案是采用迭代的自训练方案。首先是在既有2D又有3D的训练数据上面,去训练一个感知大模型,给那些没有3D标注的数据打上3D伪标注。然后再继续训练一个感知大模型出来,如此迭代,逐步把感知大模型的效果提升,同时也使得3D尾标注的效果越来越好,可以看到下面的三个图的例子,结果实际上是变得越来越好。
这样的一个感知大模型,不仅用于视觉,也用于点云,也用于我们后面要讲的多模态端到端的方案。
在这个远视觉感知方案里面,实际上也利用了编码器和解码器的预训练方案,利用了公开的数据集Object 365和COCO这样的预训练。
那这里要提一下的是,百度基于这么一个编码器和解码器预训练的方案,采用的方法Group DETR v2,实际上在标准的公开数据集上面首次突破了64.5mAP的一个效果。
我们看看大模型在三个方面的应用,首先是在远视距方面。

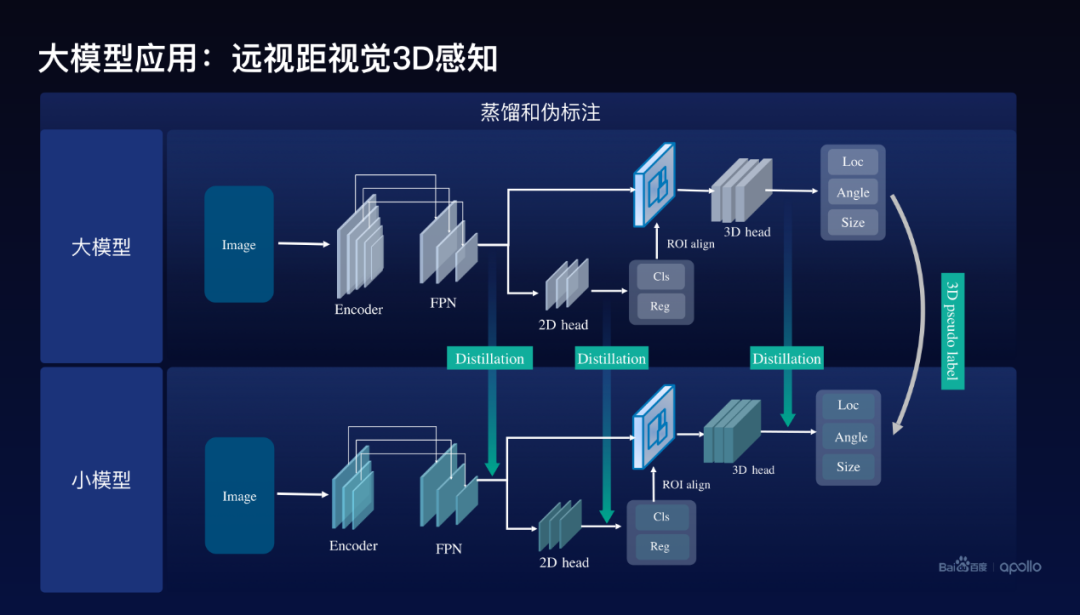
大模型怎么去帮助小模型,百度采用的方案是基于蒸馏和伪标注的方案,伪标注通过刚才训练好的感知大模型,给这个图像打上3D的伪标注,同时使用了蒸馏方案。在网络架构里面通常会包含编码器。还有2D检测的Head,以及3D检测的Head,百度分别在三个地方使用了蒸馏,第一个是在编码器出来的地方,用大模型的特征去帮助训练小模型的特征,除此以外在2D的Head上面与3D的Head上面分别去做大模型到小模型特征的蒸馏。
这里我们实际上在训练这个模型的时候还使用了这么一个小的技巧,就是把大模型的Detection head,包括2D、3D里面的参数,直接作为小模型的初始化,进一步地提升训练的效率和效果。
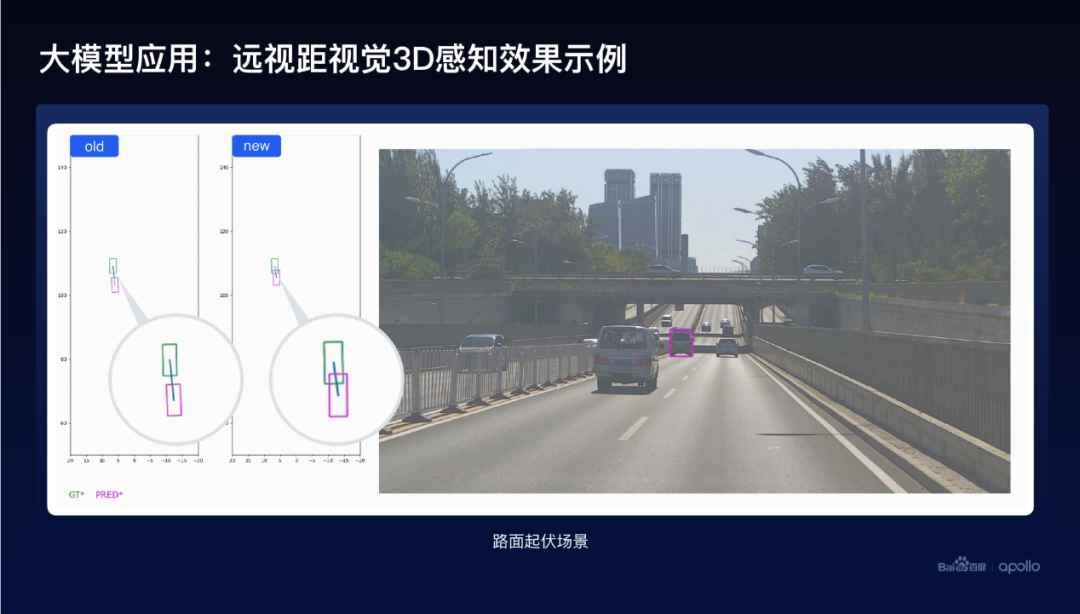
大模型帮助小模型带来了一个效果,远视距3D感知带来的效果,遮挡的场景可以看到这个图里面,左边绿色的框是对应的Ground truth,红色的是预测的,对比一下在旧模型和新模型的对比可以看到,新模型的效果从感知、预测车辆的距离等方面,效果提升是非常明显的。
再看一看道路起伏的例子,仍然可以看到左边这个旧模型和新模型效果的对比,跟前面对比起来,不仅仅预测的物体的车辆的距离变得更准确了,同时这个车辆的方向也预测得会更好,它的角度也会更好。

这边仅仅给大家展示了两个例子,在实际里面会发现更多非常好的效果,下面看看大模型在多模态前融合端到端感知上面的一个应用。多模态前融合的方案对应的大模型实际上是用前面我们讲到的方案,通过半监督的方案,迭代的自训练的方案去训练出来的。
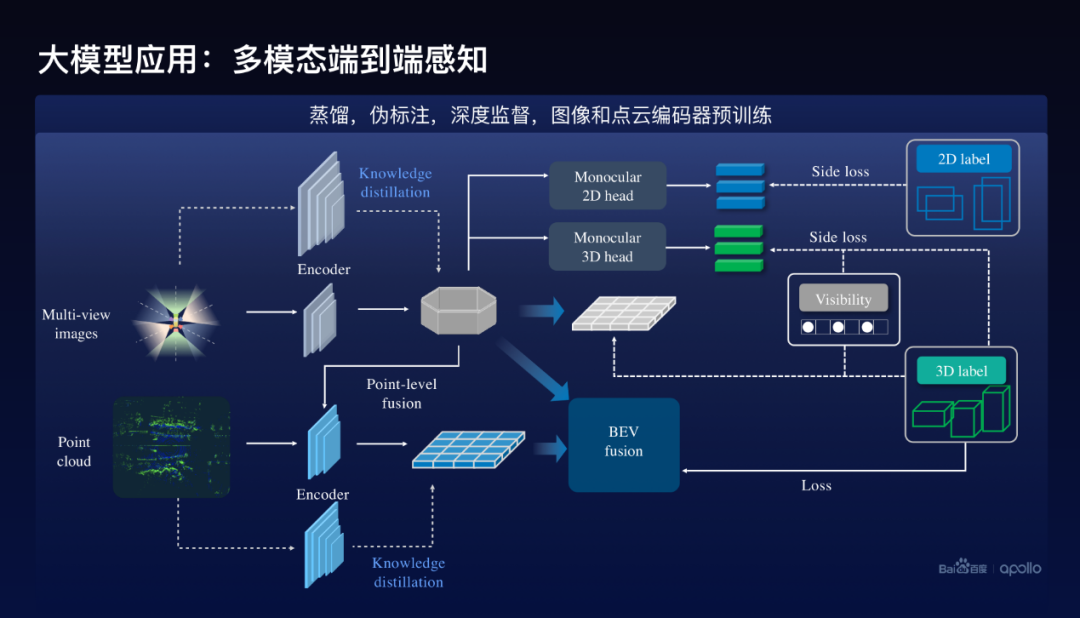
在这个地方怎么去帮助小模型的训练呢?除了蒸馏方案以外,在编码器做蒸馏以外,也使用了伪标注,就是用大模型对数据进行伪标注,然后去帮助训练。这里面要特别提到的其他几点:第一个我们使用了深度监督的方法,分别在图像端和点云端做了3D的预测,比如说在图像端对每个图像进行2D的跟3D的预测,我们称之为Side loss,这样能够很好的提升训练的效果。
还有一点百度还使用了预训练的方案,因为在多模态方案里面,既有图像的编码器,也有点云的编码器,这个时候图像的编码器实际上不是在多模态下面训练出来的编码器,来作为它的初始化,类似的点云也是同样。

要跟大家分享的是,把这样的一个方案降级到多视角图像的端到端的感知里面去。这样一个方案,在公开的nuScenes数据集上面取得了非常好的一个效果,目前在nuScenes 3D检测里面multi-view的情况下面取得了最好的效果,能够把这样的一个方案应用到nuScenes里面的跟踪tracking里面去,也取得了非常好的效果。现在目前是在这个tracking榜单里面排名第一的。
那下面看看点云感知的效果,在多模态前融合方案里面,我们使用了点云感知的编码器的预训练,如果只是在点云里面使用大模型的方案带来了一个效果,这里面我们可以看到从旧模型和新模型的对比,在路测的误检方面我们改进得非常多,同时在中间的比如说绿化硬隔离带也会有一些误检,那这样子我们通过大模型帮助小模型以后,可以解决很多问题。

下面看看多模态前融合感知的整体的效果,这里举了一个非常困难的一个例子,大家看看左边实际上是一个洒水车,洒水车的前面实际上有喷雾。那在旧的方案里面,如果没有使用我们这个多模态前融合端到端的方案,很容易把这个喷雾识别成车辆,但是用了新方案以后,这样的误检就会消失。
最后看看大模型在数据挖掘里面的使用,这是整个自动驾驶感知的数据闭环的流程图。这里主要分享一下数据挖掘方面的这么一个技术。


在数据挖掘里面采用了大模型的方案,跟前面的感知的方案相关,但不完全一样,这使用了基于图文弱监督预训练模型去帮助做长尾数据的挖掘。怎么去做预训练的模型,通常里面会有大量的图文,把图像送到一个我们称之为图像编码器里面去,图文对里面对应的文本也送到文本编码器里面,通过优化所谓的对比损失来训练这个文本编码器和图像编码器。
这样训练出来的编码器有非常好的一个效果,可以处理称之为开放集的语义识别,不同于传统的比如说在ImageNet上面,通常ImageNet-1K可以处理1000类,那这样训练出来的图文预训练模型可以处理1000类以外,甚至成千上万的类别,正是利用了这么一个性质去帮助做数据挖掘。
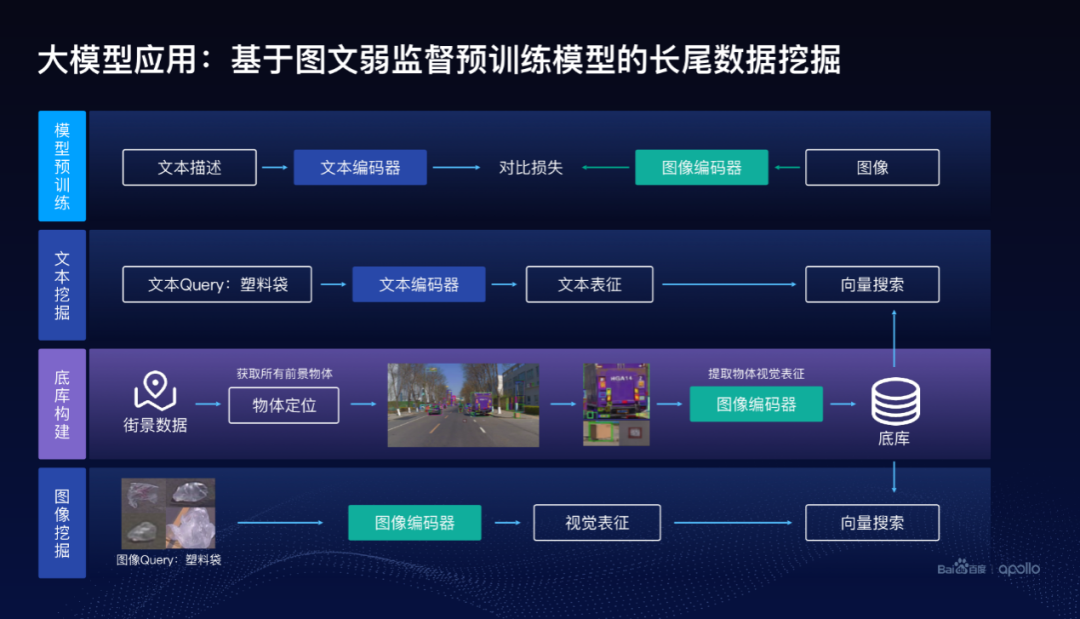
当训练好这么一个模型以后,在自动驾驶数据库里面,经过我们的底库构建,怎么做呢?
我们把街景数据,比如这里面图像,首先做一步物体定位,把这个图像里面可能的物体都给找出来,这里面使用了叫Group DETR v2的检测方案,很好地把可能的物体给定位出来。把可能的物体定位出来以后,物体所在的图像块抠出来,放到图像编码器里面,形成一个向量,这就是底库的构建。
做数据挖掘的时候可以采用两种:一种是没有所需要挖掘的图像时,可以直接通过文本去进行挖掘,比如,把塑料袋输入到文本编码器里面,形成一个文本特征,变成一个文本表征的向量,然后通过快速的向量搜索算法,在底库里面很快找到可能是塑料袋的图像出来。
慢慢的已经找到了一些塑料袋图像以后,这个时候也可以把图像输入到图像编码器里面,抽取视觉表征,然后类似的进行向量搜索。
在这样的过程中,刚开始搜索出来的图像效果准确率不见得那么高,随着搜索越来越多,回来的图像数量越来越多,可以训练一个称之为fine classifier完成进一步的筛选,最终不断地提升数据挖掘的效果。
看看数据挖掘一些例子,以及最终怎么帮助自动驾驶感知能力的提升呢?左边是给了一些典型的例子。比如说小孩在路面上面,比如说快递车、轮椅、地面上有塑料袋,还有消防车、救护车等,是百度在数据挖掘的例子。

在能力提升方面把它分为两大类:一类是本来有这么一个能力,通过这样的数据挖掘以后这个能力得到了很大的提升,比如说对儿童的检测,比如说对塑料袋的误检,因为塑料袋检测是非常重要的,如果说不能够很好的把塑料袋跟其他的比如说非常硬的物体给区分开来,那对后面的PNC会带来很大的挑战,会容易出现急刹的情况。
另外一个能力的提升,就是说本来可能没有这样的能力,通过数据挖掘以后,就有这样的能力了,比方说消防车和救护车这样的例子,以前可能并不区分消防车和救护车,消防车和救护车在路上会有较高的路权,这个时候如果很好地把它识别出来以后,对后面下游的驾驶策略调整会起到很大的帮助。
另外一个,在实践里面就会发现一些有意思的现象,道路上有时候会出现一些小动物,比如说我们在成都二环路上会发现,成都二环路上的马,还有我们在路上会发现少见的羊群,比如说我们在顺义区路上会发现的羊群,这样都是感知长尾问题,通过这样的数据挖掘,现在有了这个能力,充分增强了自动驾驶感知的效果。
最后,我用这么一句话来结束我今天的报告。大模型,已经成为自动驾驶能力提升的核心驱动力。
审核编辑 :李倩
-
FPGA在自动驾驶领域有哪些优势?2024-07-29 8159
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 14211
-
自动驾驶真的会来吗?2016-07-21 14514
-
自动驾驶的到来2017-06-08 7435
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 7531
-
无人驾驶与自动驾驶的差别性2017-09-28 6530
-
高级安全驾驶员辅助系统助力自动驾驶2018-09-14 3439
-
车联网对自动驾驶的影响2019-03-19 3555
-
如何让自动驾驶更加安全?2019-05-13 3730
-
自动驾驶汽车的处理能力怎么样?2019-08-07 2896
-
激光雷达成为自动驾驶门槛,陶瓷基板岂能袖手旁观2021-03-18 3143
-
自动驾驶系统设计及应用的相关资料分享2021-08-30 2429
-
自动驾驶技术背后的驱动力是计算机视觉和人工智能2020-07-22 3574
-
禾多科技大数据闭环能力可提升整个自动驾驶系统性能安全2022-09-01 1056
-
西井科技端到端自动驾驶模型获得国际认可2025-10-15 1439
全部0条评论

快来发表一下你的评论吧 !
