

基于视频语言模型LiteVL的无参的特征池化方法
描述
沿着从大规模图文多模态预训练迁移适配到视频多模态任务的思路,我们提出了模型LiteVL,它利用图文预训练模型BLIP来初始化参数,可以直接在下游任务上微调而不需要进行额外的昂贵的视频文本预训练。并且为了增强图像语言模型中缺乏的时间建模,我们提出在BLIP的Image encoder中增加具有动态时间缩放(dynamic temporal scaling)的时间注意力模块。除了模型方面的这一适配之外,我们还提出了一种非参数池化text-dependent pooling,以自适应地重新加权以文本为条件的细粒度视频嵌入。我们选取了两个具有代表性的下游任务,即文本-视频检索和视频问答,来验证所提出方法的有效性。实验结果表明,所提出的LiteVL在没有任何视频文本预训练的情况下,甚至明显优于以前的视频文本预训练模型。
1. Motivation
近期许多Video-language modeling的工作往往基于大规模video-text数据集 (WebVid2M,CC-3M,HowTo100M) 上进行预训练,然后在下游任务的数据集上微调,而预训练的成本往往十分昂贵。另一方面,学习细粒度的visual-language对齐往往需要利用离线的目标检测器 (e.g., ActBERT) 来捕捉物体信息,但却受限于检测器有限的类别数量 (e.g., 在MSCOCO数据集上训练的目标检测器只能检测出不到100个类别) 和昂贵的计算开销。而且没有充分利用来自文本数据的监督信息。此外,以往的稀疏帧采样的video-text模型是利用image encoder在大规模图文对上预训练的,它忽略了视频理解所需要的时序信息建模 (e.g., CLIPBERT)。最近,在单一视频模态领域的研究上,基于预训练的图像编码器ViT初始化而来的TimeSformer在许多下游的视频任务上性能表现很好,它相比ViT仅仅插入了额外的一层用ViT的注意力层初始化来的时间注意力层。
2. Solution
我们提出了一种简单且高效的视频语言模型LiteVL,它是从近期的预训练图像语言模型BLIP初始化而来的,并且分别从模型层面和特征层面做了时域信息增强。
对于模型层面,我们提出用一组具有可学习scaling factor的时间注意层明确插入原始image backbone中,可以针对每个下游任务进行训练调整(Dynamic Temporal Scaling):
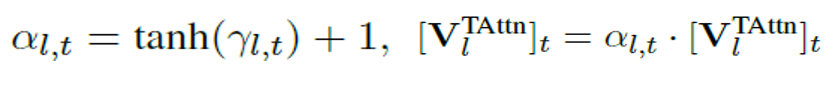
对于特征层面,我们设计了一种无参的特征池化方法(Text-dependent Pooling),以学习基于文本描述的细粒度时间-空间视频特征:
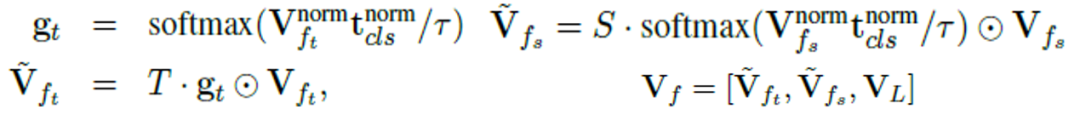
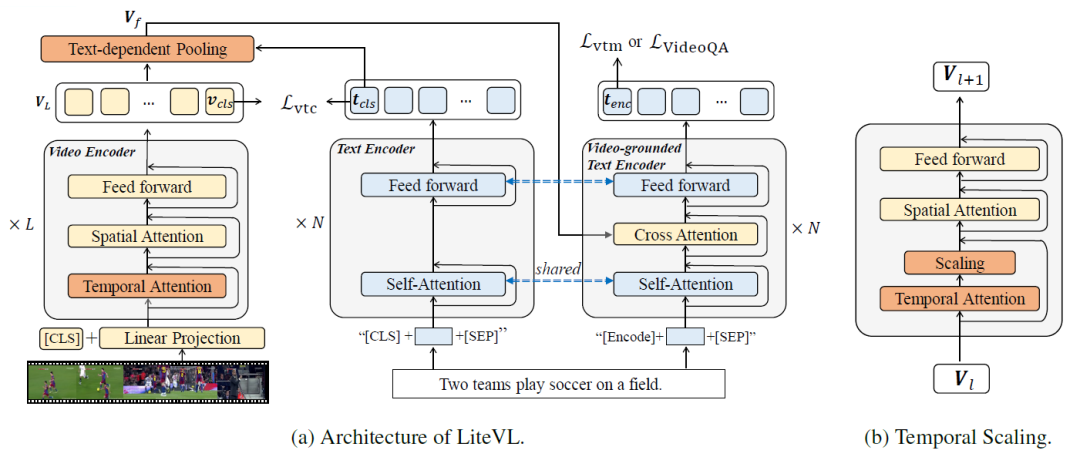
模型框架和动态时序scaling
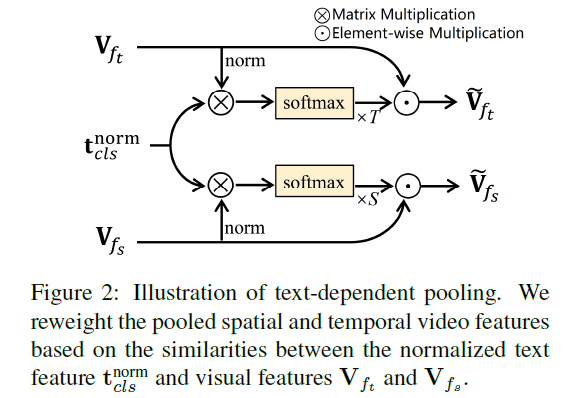
Text-dependent Pooling
3. Experiments
在三个视频文本检索数据集上和BLIP的性能比较:
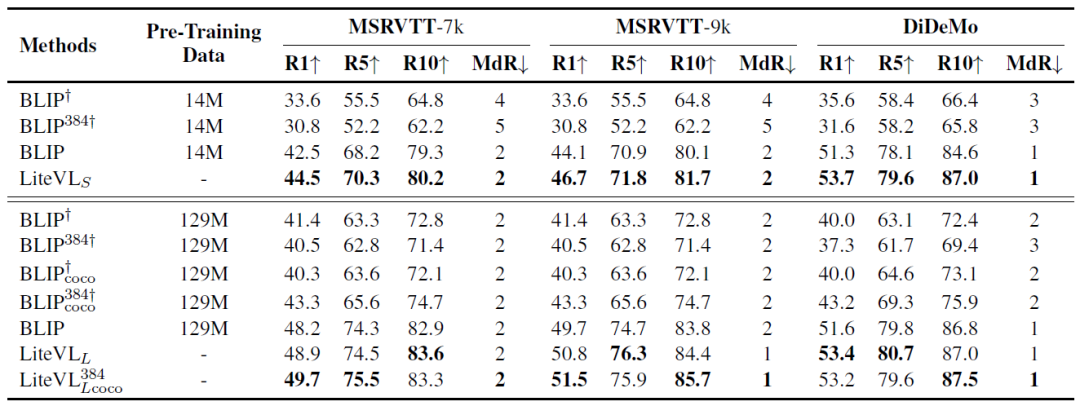
我们提出的LiteVL由于在模型和特征方面的显式时间建模,最终性能优于原始BLIP。
关于Dynamic Temporal Scaling和Text-dependent Pooling的消融实验
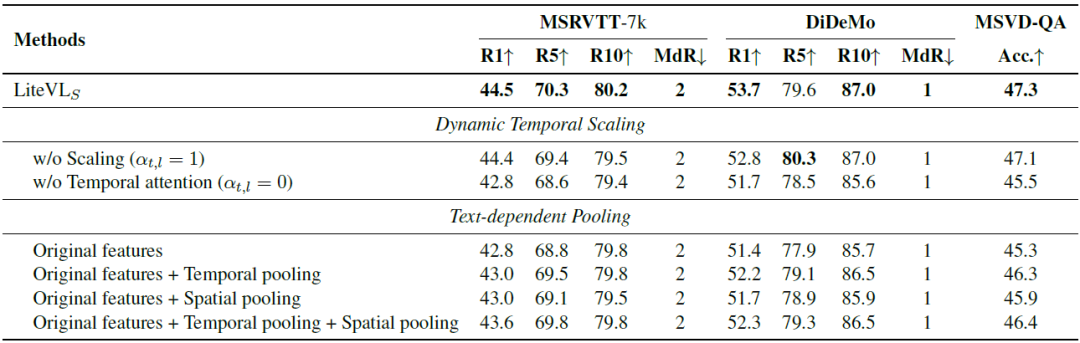
通过提出的轻巧的动态时间缩放自适应地根据每个特定任务调整框架级别的重要性,使性能得到进一步提高。此外,与仅使用原始特征相比,使用其他空间或时间池化后的特征会更好。
逐层的平均temporal scaling可视化分析
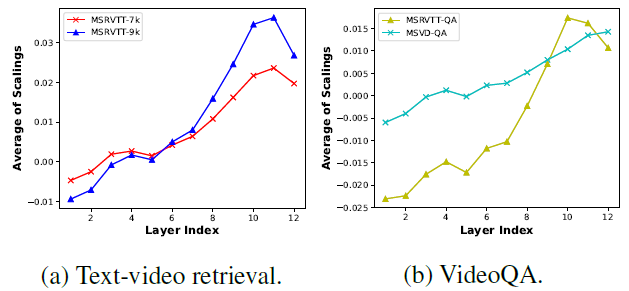
折线图的变化趋势显示了video encoder的浅层更多地集中在理解每个帧的空间内容上,并更少注意不同帧之间的时间依赖性。当层的深度增加时,每个帧的空间特征变得更加全局,并且该模型逐渐寻求学习它们之间的时间依赖性。
Grad-CAM可视化分析

上图展示了Grad-CAM可视化,提出的LiteVL有效地捕捉了不同帧之间的细微差异。这也表明我们提出的text-dependent pooling为video-grounded text encoder提供了丰富的信息。
4. Conslusion
我们提出了LiteVL,这是一种视频语言模型,它无需大量的视频语言预训练或目标检测器。LiteVL从预先训练的图像语言模型BLIP中继承了空间视觉信息和文本信息之间已经学习的对齐。然后,我们提出了具有动态时间缩放的额外时间注意力块,以学习视频帧中的时间动态。我们还引入了一种无参的text-denpendent pooling,该方法基于文本描述来对不同帧或者空间位置进行加权,从而实现了细粒度的视频语言对齐。实验结果表明,我们的LiteVL优于利用了视频文本预训练的最先进方法。
审核编辑:郭婷
-
如何优化自然语言处理模型的性能2024-12-05 2974
-
云端语言模型开发方法2024-12-02 1245
-
一种利用光电容积描记(PPG)信号和深度学习模型对高血压分类的新方法2024-05-11 15792
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1387
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 890
-
C语言-函数的可变形参(不定形参)2022-08-14 3992
-
模型调参:CANape与Simulink的强强联手2022-08-01 2985
-
OpenHarmony硬件资源池化模型2022-05-11 2457
-
基于机器学习等的高速公路视频图像检测系统2021-06-01 1036
-
基于深度学习的视频质量评价方法及模型研究2021-03-29 1216
-
深度视频自然语言描述方法2017-12-04 1131
-
猫池是什么 短信猫池使用方法2012-04-23 11200
全部0条评论

快来发表一下你的评论吧 !
