

多核处理器的挑战,多核处理器结构与分类
处理器/DSP
描述
近几年RISC-V江湖发生了几件有影响的事情,平头哥大手笔一股脑开源了4款RISC-V CPU,SIFIVE公布了其基于RISC-V 128核的高端CPU的SOC计划,再加上前段时间Esperanto发布了其基于RISC-V的1000核AI处理器,RISC-V江湖可谓是热闹非凡,你争我赶,百花齐放,百家争鸣;当然RISC-V的前程到底会怎么样?可能还有很多不可确定的因素。但我们可以看RISC-V已经不再满足于现有的嵌入式领域,而是在向多种应用场景蚕食。包括高性能计算,数据中心的云服务器应用等,各玩家也都在摩拳擦掌,蓄势待发。
CPU核数的增多给处理器的设计带来了很多新的挑战,包括我在前面文章中介绍的cache一致性,内存一致性等,既然多核的引入使系统变得如此复杂,那为什么我们还需要发展多核处理器,并且核数还越来越庞大,而不是专注于提升单核的计算能力?天下武功,唯快不破!我们继续保持原来的方向把单核的性能再提升一个台阶不是更香吗?
我们今天就简单地来谈一下这个问题。
1.多核处理器介绍
1.1为什么需要多核处理器?
人类生活对计算能力提出了越来越高的需求,气象预报,各种AI业务,各种生态模拟无不要求更多的计算能力和计算资源。提升计算机系统的计算能力的方法之一是提升系统中每一个处理器(我们称为核)的计算能力,另外一种途径就是增加系统中处理器的数目,在单个处理器的计算能力一定的情况下,通过并行计算的方式来提升系统整体的计算能力和计算吞吐量。
【注:目前针对AI计算需求,由于其业务模型的独特性,还有一种技术潮流,就是把计算下沉,不管是process in memory 还是process near memory, 或者Compute Express Link (CXL), 其本质都是减少数据在内存与CPU之间的来回搬运,有兴趣的同学可以关注】
对于一个处理器的性能,我们可以用完成一项任务所需要的时间来衡量,我们可以用如下公式来表示:
CPU Time (seconds) = Total Instructions x (Cycles/Instruction) x (Seconds/Cycle)
也就是衡量一个处理器性能,我们需要考察三个因素:
(1) 完成一项任务所需要的指令数目(Total Instructions),比如需要完成一个乘法运算和一个加法运算 (a = a + b x c),某些体系架构需要采用两条指令(一条乘法指令和一条加法指令),但某些体系结构可以直接用一条乘加指令(MAC)完成该任务,所以针对一个具体的任务,不同CPU需要的指令数目是不同的。
这个参数主要是由程序算法,CPU体系结构,指令集ISA以及编译器的能力决定的。
(2) 单指令的耗费的周期数目(CPI:Cycles per Instruction),与此对应的我们常用另外一个性能参数叫IPC(Instructions per cycle),这两者互为倒数。这个是由CPU的微架构确定的。
(3) 单cycle的时间长度,这个就是CPU的时钟频率。CPU能够达到的时钟频率主要受硅工艺以及微架构的影响。为了提高CPU的频率通常需要采用更先进的工艺(比如7纳米,5纳米),在微架构设计上需要采用更多的流水线级数。
过去我们一直在为提高单处理器的计算性能做持续不断的努力,我们来看一下过去35年处理器发展的一个整体趋势:
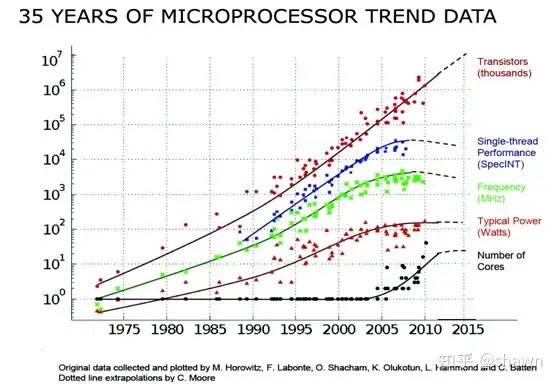
从这个发展趋势我们可以看出:
(1) 集体管的数目还是继续按照摩尔定律在推进;
(2) 单核的性能从1988年到2007年,微处理器的性能以平均50%的速度不断提升。但从2008年开始,单处理器的性能基本达到了顶点,提升速度不太明显。
(3) 系统的主频经过大幅的提升以后也达到了一个很高的水平,在2008年后基本达到了峰值。
(4) CPU的功耗也进入了一个高原区域。
随着晶体管密度的不断增加,CPU的能耗密度也显著提升,热量的散失成为了一个大问题,几乎达到了空气冷却散热能力的极限。下图展示了CPU的能量密度趋势。
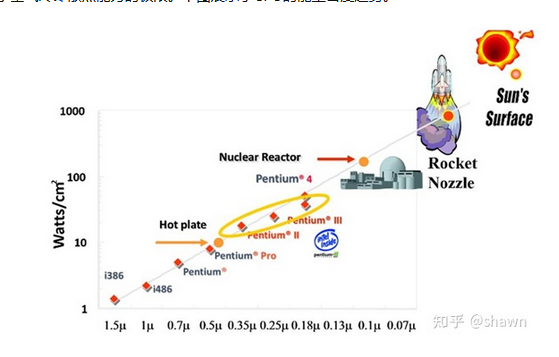
在70纳米的工艺下CPU的能耗密度基本就与原子核反应堆的能量密度相当,随着制造工艺的提升,当前的能耗密度甚至已经与火箭尾喷管的能量密度相当。
所以通过继续增加集成电路的规模和工艺来提高处理器性能的方法变得不再那么有效,我们需要另外一种手段来提升系统的计算性能,那就是并行处理。与其建造更快更复杂的单处理器,不如在单个芯片上放置多个相对简单的处理器,我们将它称之为多核处理器。采用多核处理器来构造我们计算机系统,我们称之为多核系统。此外多核系统与单纯意义上的指令并行ILP(Instruction Level Parallelism)超标量处理器相比还具备两个优势:(1)性价比更高,(2)能耗效率高
1.2多核处理器结构与分类
并行计算架构可以有多种分类方式,比如可以根据并行计算系统采用的控制方式分类,地址空间组织方式,处理器之间的连接网络等维度来对并行架构进行分类。我们采用知名的Flynn分类方式,根据指令和数据流来对并行计算架构进行分类。
-
SISD(Single Instruction Single Data): 这个就是顺序执行
-
MISD(Multiple Instruction Single Data): 多个处理器对同一个数据执行不同的指令。这个理论上存在,在实际应用的非常少。
-
SIMD(Single Instruction Multiple Data): 多个处理器对不同数据执行相同的指令(比如矩阵加法和相关矢量运算,目前AI领域应用广泛)。
-
MIMD(Multiple Instruction Multiple Data): 多个处理器独立地执行自己的指令处理自己的数据。
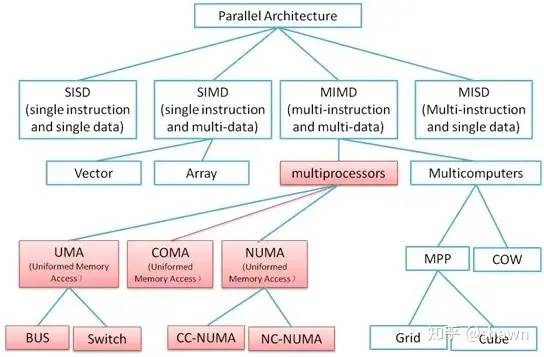
我们重点关注MIMD中多核处理器部分,由于多核处理器目前大部分都是通过共享内存方式进行通信(还有采用消息方式通信的,不在我们的讨论范围,就不罗嗦了),根据内存组织方式的不同,共享内存多核处理器系统具有如下几个细分:
-
UAM(Uniform memory access)
-
NUMA(non-uniform memory access)
-
COMA(Cache-only memory access)
UMA系统中所有的处理器共享统一的物理内存(集中式共享内存Centralized shared memory),所有处理器访问该物理内存的时间基本相同,每个处理器可以有它自己的私有缓存(cache)。所有的外设对内存的访问能力也完全平等相同。
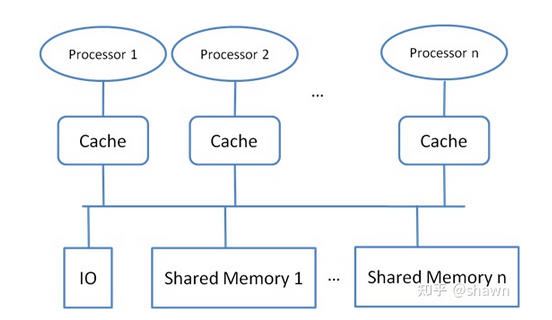
当所有的处理器对外设IO也拥有相同的访问能力时,这种共享的多核处理器就叫做对称处理器SMP(symmetric multiprocessor)。如果系统中只有一个或者少数几个拥有对外设的访问能力,则可以称为非对称处理器(asymmetric multiprocessor)。
Intel的Xeon多核处理器就是一个典型的SMP应用例子。
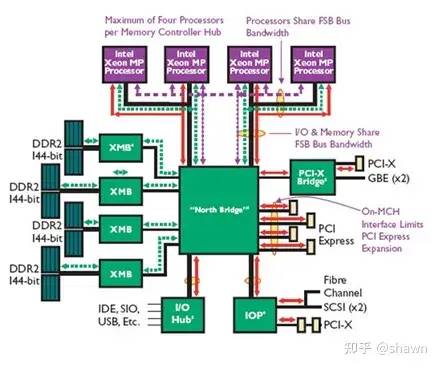
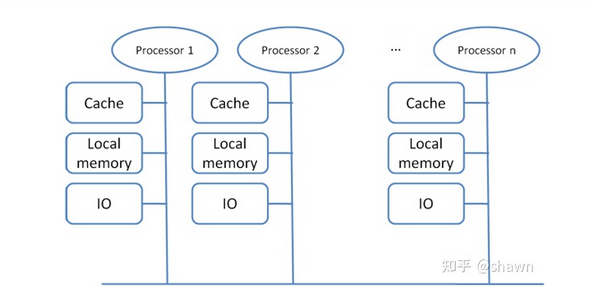
如果在多核处理器中,每个处理器访问内存所需要的时间不同,则我们称为NUMA系统,在NUMA系统中,内存不再集中在一起供所有处理器平等访问,不同的处理器都有其自身的本地内存(分布式共享内存系统DSM : Distributed Shared Memory)。但这些处理器上的内存共享同一个全局地址空间,其它处理器也都能访问,处理器访问本地内存需要的时间少于访问其他处理器的远端内存需要的时间。
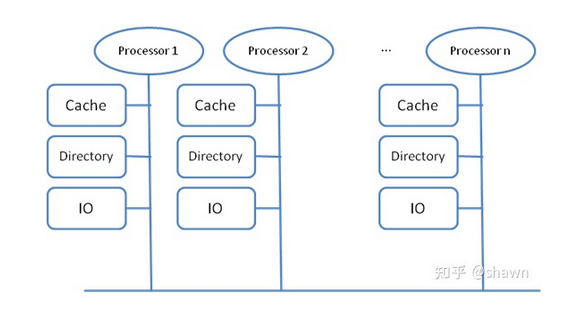
如果在多个核之间还维持cache的一致性,则称为CC-NUMA(Cache Coherency NUMA),如果每个处理器只在本地Cache中保持处理器的私有信息,则不需要维持全系统的cache一致性,我们称这种系统为 NC-NUMA。
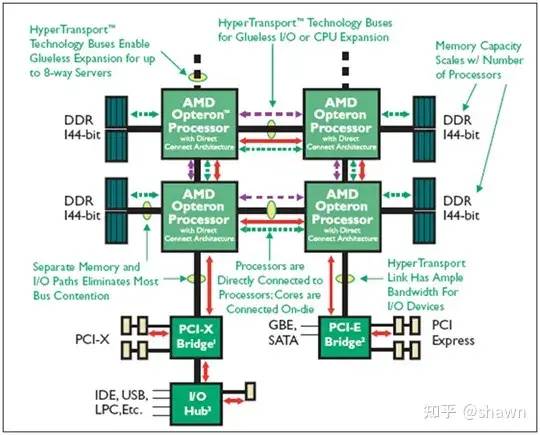
ARM公司的Opteron处理器就是一个典型的NUMA应用例子。
如果把上述NUMA系统中所有的分布式的主memory变为cache则形成了COMA系统,它是NUMA的一种特殊形式。
Kendall Square Research的KSR-1就是COMA的一个例子。
1.3多核处理器的挑战
共享内存式的多核处理器需要解决两个主要问题:
(1) Cache一致性问题:由于同一份数据在整个系统中存在多份,分布在不同的处理器的cache中,如果一个处理器修改了自己的那份数据,则其它处理器的数据就不是最新有效的了。如果保证核间的cache一致性是多核处理器设计的一个重要方面。
(2) 核间互联:多核之间通过共享内存通信是通过往全局内存中写入数据和读取数据来完成的,当多个处理器同时访问(写入或者读取)共享内存时会导致总线上的竞争,从而导致系统性能恶化,所以优化总线结构设计也是提升多核性能的一个关键技术。
当然其它方面的问题,比如任务在多个核之间的调度管理也是一个专题。
编辑:黄飞
-
嵌入式多核处理器硬件结构分析与对排序算法进行并行化优化2018-10-17 5082
-
为什么有多核处理器?从多核到众核处理器2023-11-16 3932
-
多核处理器设计九大要素2011-04-13 3354
-
多核处理器的优点2019-06-20 5195
-
嵌入式ARM多核处理器的结构2021-03-02 1474
-
多核处理器分类之SMP与NUMA简析2022-06-07 4009
-
多核处理器架构及调试2010-08-26 1723
-
多核处理器及其对系统结构设计的影响2011-02-27 1030
-
多核处理器中的超越函数协处理器设计2017-01-07 1008
-
多核处理器会取代FPGA吗?2017-02-11 1505
-
第1章 多核处理器基础2017-04-11 1028
-
多核处理器成最新潮流,多核处理器几大特点你都知道吗?2017-04-24 2286
-
基于FPGA的NoC多核处理器的设计2017-11-22 5607
-
处理器关于多核概念与区别 多核处理器工作原理及优缺点2017-12-08 33179
-
浅议多核处理器技术2021-03-29 1379
全部0条评论

快来发表一下你的评论吧 !
