

CLIP-Chinese:中文多模态对比学习预训练模型
描述
笔者最近尝试在业务中引入多模态,基于CLIP论文的思想,实现了基于Vit-Bert的CLIP模型,下面将其称为BertCLIP模型。笔者用140万的中文图文数据,基于LiT-tuning的方式,训了一版BertCLIP模型。BertCLIP模型在中文图文相似度、文本相似度、图片相似度等任务上都有着不错的表现。
本文将对该工作进行详细的介绍并且分享笔者使用的中文训练语料、BertCLIP预训练权重、模型代码和训练pipeline等。
首先展示一下BertCLIP预训练模型在图文相似度上的效果。

项目地址:
https://github.com/yangjianxin1/CLIP-Chinese
预训练权重(使用方法,详见下文):
| 预训练模型 | 预训练权重名称 | 权重地址 |
| BertCLIP整体权重 |
YeungNLP/clip-vit-bert-chinese-1M |
https://huggingface.co/YeungNLP/clip-vit-bert-chinese-1M |
| 单独提取出来的Bert权重 |
YeungNLP/bert-from-clip-chinese-1M |
https://huggingface.co/YeungNLP/bert-from-clip-chinese-1M |
论文标题:
Learning Transferable Visual Models From Natural Language Supervision
01
模型简介
CLIP是由OpenAI提出的一种多模态对比学习模型,OpenAI使用了4亿对图文数据,基于对比学习的方法对CLIP模型进行训练。
CLIP模型主要由文本编码器和图片编码器两部分组成,训练过程如下图所示。对于batch size为N的图文对数据,将N个图片与N个文本分别使用图片编码器和文本编码器进行编码,并且映射到同一个向量空间。然后分别计算两两图文对编码的点乘相似度,这样就能得到一个N*N的相似度矩阵。
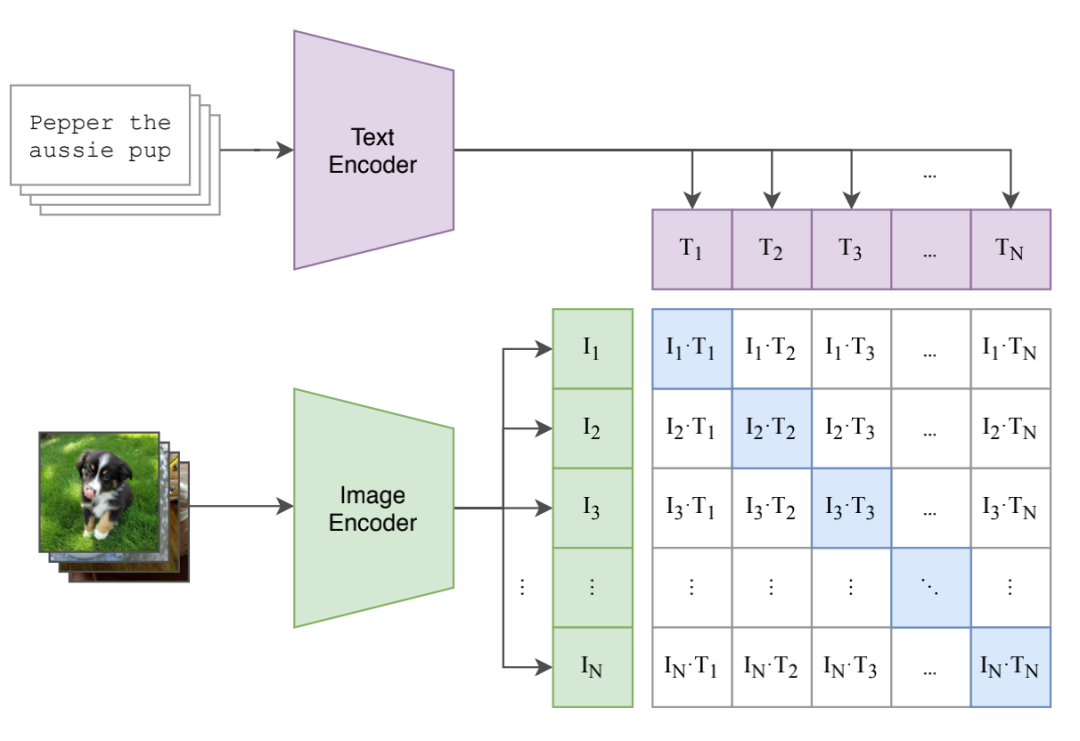
然后使用我们熟悉的对比损失InfoNCE Loss来计算该batch的训练损失,更新模型权重。对InfoNCE Loss不熟悉的小伙伴,可以回顾笔者往期的文章:SimCSE:简单有效的句向量对比学习方法。
举个例子,对于图片I1,分别计算I1与文本T1~TN的相似度,T1是I1的正样本,而T2~TN均视为I1的负样本,我们希望I1与T1的相似度尽可能大,而I1与其他文本的相似度尽可能小。
在计算T1的InfoNCE Loss时,首先将T1与所有文本的相似度进行softmax归一化,得到相似度的分布,然后计算相似度分布与label的交叉熵损失,而T1的label为1。由此可以将这个loss的计算方式推广到整个batch。
有小伙伴可能会觉得,对于图片l1,文本T2~TN中可能存在它的正样本,若将T2~TN均视为I1的负样本,会对模型的训练带来很大的影响。对于该问题,我们可以认为,当数据量足够大,并且batch size足够大的时候,上述误差对模型的优化方向的影响是有限的。在预训练时代,我们要相信大力是能够出奇迹的,只要堆足够多优质的数据,很多问题都可以迎刃而解。
02
项目介绍
训练细节
BertCLIP主要由Vit和Bert组成,在预训练时,笔者分别使用不同的预训练权重来初始化Vit和Bert的权重。使用OpenAI开源的CLIP模型来初始化Vit权重,使用孟子中文预训练权重来初始化Bert权重。
我们基于LiT-tuning的方法来训练BertCLIP模型,也就是将Vit部分的模型参数进行冻结,只训练BertCLIP的其他部分的参数。LiT-tuning是多模态模型训练的一种范式,它旨在让文本编码空间向图像编码空间靠近,并且可以加快模型的收敛速度。
笔者使用了140万条中文图文数据对,batchsize为768,warmup step为1000步,学习率为5e-5,使用cosine衰减策略,混合精度训练了50个epoch,总共73100步,训练loss最终降为0.23左右。模型的训练loss变化如下图所示。
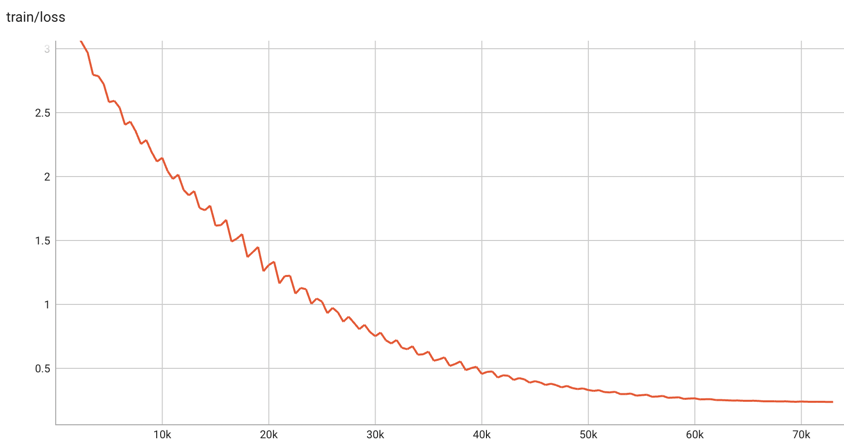
由于训练资源的限制,以及训练数据的获取需要耗费较多时间,目前笔者仅使用了140万的训练数据。对于预训练而言,140万的训练数据量略微少了些,笔者训练50轮,模型也许会过分拟合训练数据。如若条件允许,读者可以在共享的模型权重的基础上,使用更多域内数据进行二次预训练。
笔者曾使用实际业务中1700万的图文数据训练BertCLIP模型,训练10轮,大概22万步,训练损失大约降为0.7。在域内的图文匹配、同义词挖掘等任务中有不错的效果。
使用方法
BertCLIP模型的使用方法非常简单,首先将项目clone到本地机器上,并且安装相关依赖包。
git clone https://github.com/yangjianxin1/CLIP-Chinese.git
pip install -r requirements.txt
使用如下代码,即可加载预训练权重和processor,对图片和文本进行预处理,并且得到模型的输出。
from transformers import CLIPProcessor
from component.model import BertCLIPModel
from PIL import Image
import requests
model_name_or_path = 'YeungNLP/clip-vit-bert-chinese-1M'
# 加载预训练模型权重
model = BertCLIPModel.from_pretrained(model_name_or_path)
# 初始化processor
CLIPProcessor.tokenizer_class = 'BertTokenizerFast'
processor = CLIPProcessor.from_pretrained(model_name_or_path)
# 预处理输入
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["一只小狗在摇尾巴", "一只小猪在吃饭"], images=image, return_tensors="pt", padding=True)
inputs.pop('token_type_ids') # 输入中不包含token_type_ids
outputs = model(**inputs)
# 对于每张图片,计算其与所有文本的相似度
logits_per_image = outputs.logits_per_image # image-text的相似度得分
probs = logits_per_image.softmax(dim=1) # 对分数进行归一化
# 对于每个文本,计算其与所有图片的相似度
logits_per_text = outputs.logits_per_text # text-image的相似度得分
probs = logits_per_text.softmax(dim=1) # 对分数进行归一化
# 获得文本编码
text_embeds = outputs.text_embeds
# 获得图像编码
image_embeds = outputs.image_embeds
单独加载图像编码器,进行下游任务。
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPVisionModel
model_name_or_path = 'YeungNLP/clip-vit-bert-chinese-1M'
model = CLIPVisionModel.from_pretrained(model_name_or_path)
CLIPProcessor.tokenizer_class = 'BertTokenizerFast'
processor = CLIPProcessor.from_pretrained(model_name_or_path)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
单独加载文本编码器,进行下游任务。
from component.model import BertCLIPTextModel
from transformers import BertTokenizerFast
model_name_or_path = 'YeungNLP/clip-vit-bert-chinese-1M'
model = BertCLIPTextModel.from_pretrained(model_name_or_path)
tokenizer = BertTokenizerFast.from_pretrained(model_name_or_path)
inputs = tokenizer(["一只小狗在摇尾巴", "一只小猪在吃饭"], padding=True, return_tensors="pt")
inputs.pop('token_type_ids') # 输入中不包含token_type_ids
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
笔者也将BertCLIP中Bert的预训练权重单独拎出来,可以使用BertModel直接加载,进行下游任务。
from transformers import BertTokenizer, BertModel
model_name_or_path = 'YeungNLP/bert-from-clip-chinese-1M'
tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
model = BertModel.from_pretrained(model_name_or_path)
在项目中,笔者上传了多线程下载训练图片、训练pipeline,以及相似度计算的脚本,更多细节可参考项目代码。
03
模型效果
图文相似度
在计算图文相似的时候,首先计算两两图文向量之间的点乘相似度。对于每张图,将其与所有文本的相似度进行softmax归一化,得到最终的分数。


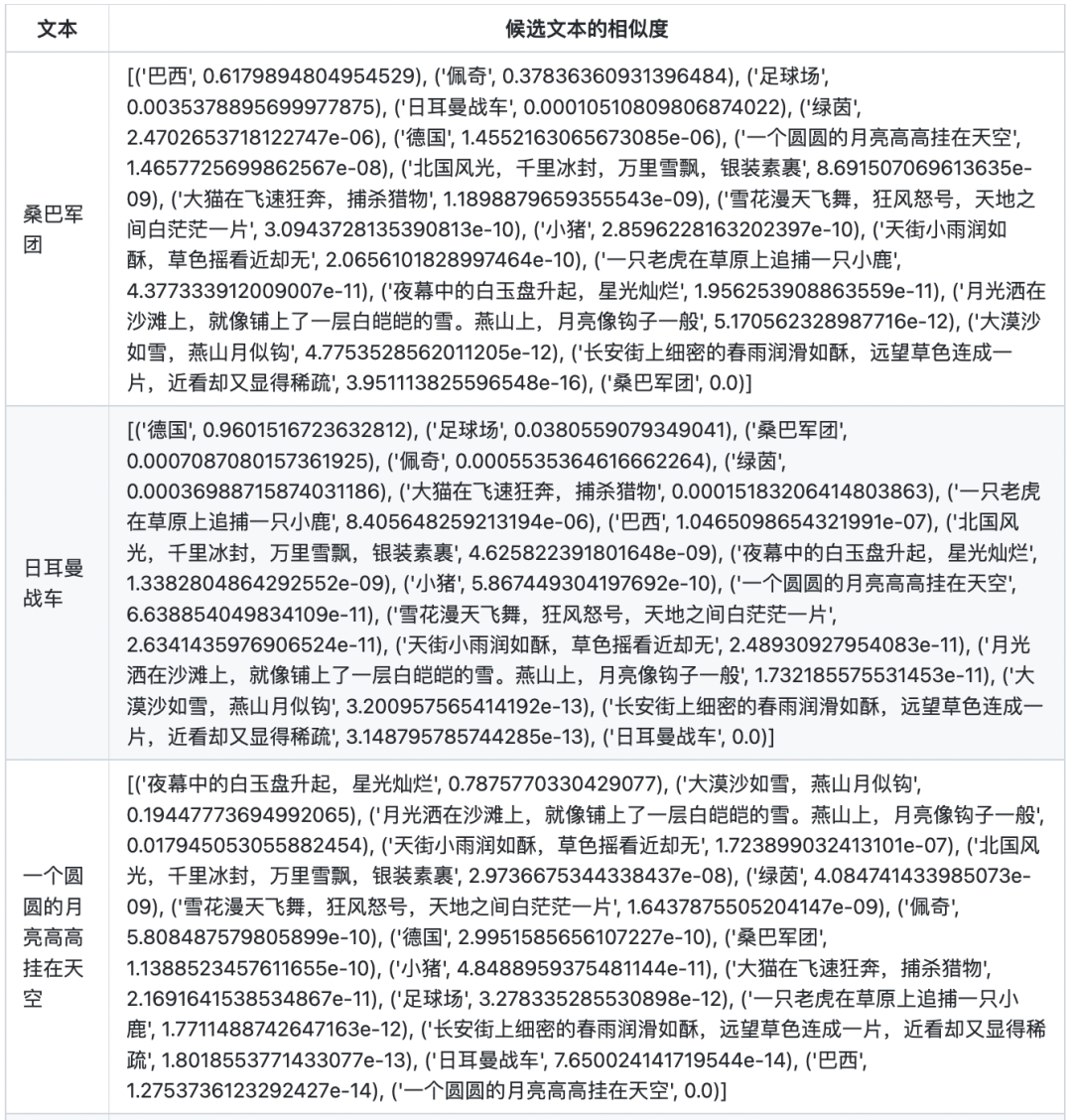
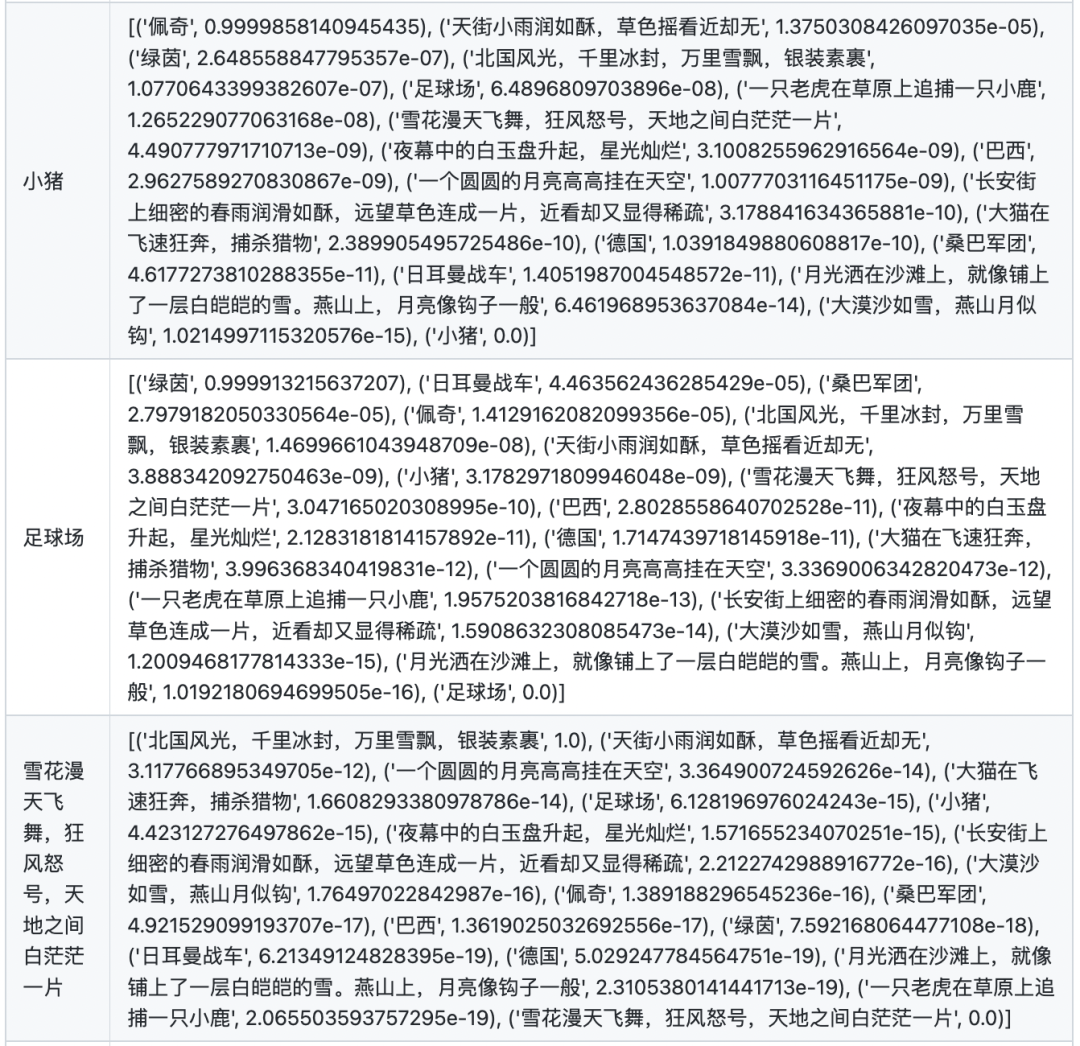
文本相似度
在计算文本相似度的时候,首先计算两两文本之间的点乘相似度。对于每个文本,将其与自身的相似度置为-10000(否则对于每个文本,其与自身的相似度永远为最大),然后将其与所有文本的相似度进行softmax归一化,得到最终的分数。
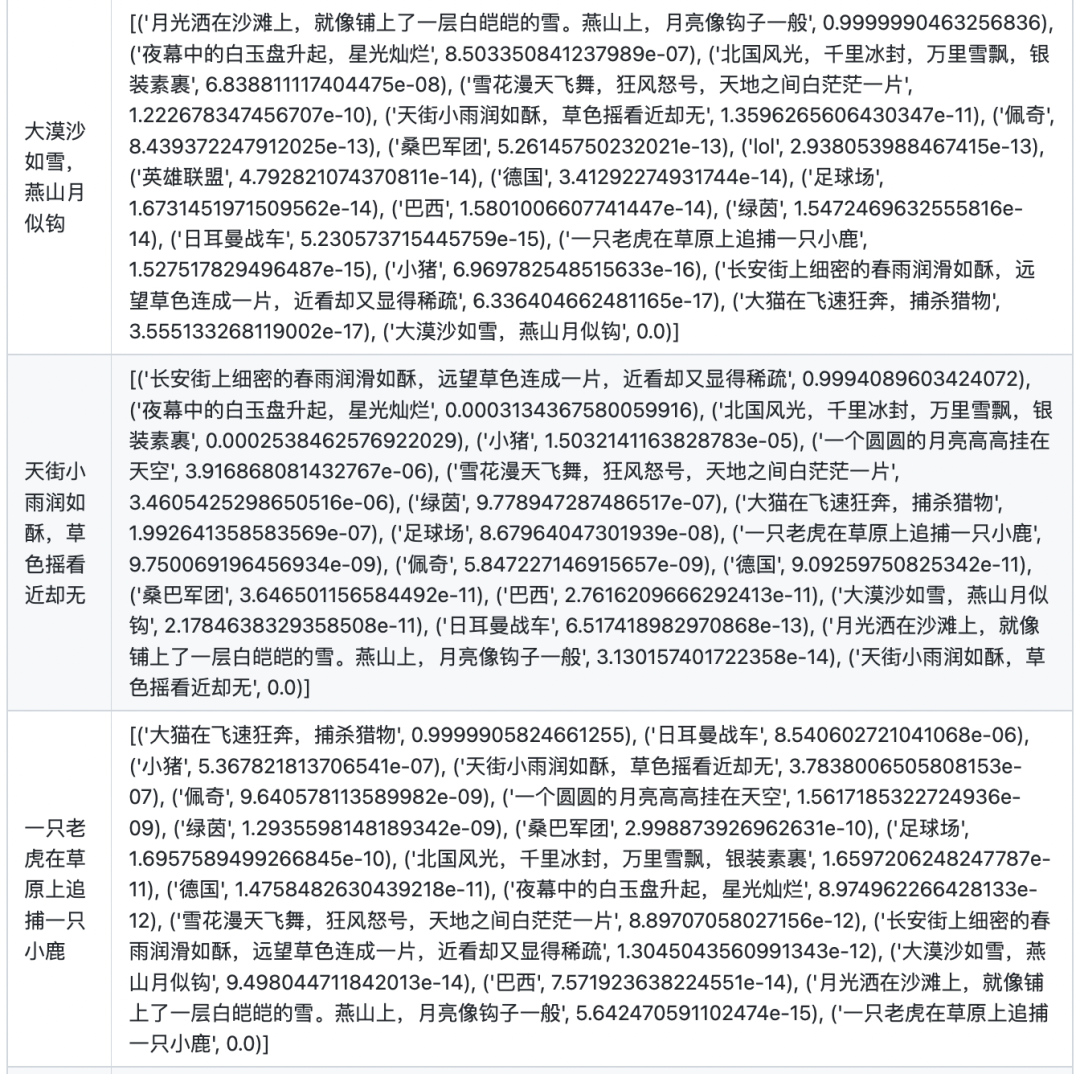

图片相似度
图片相似度的计算方式与文本相似度的方式一致。为方便展示,仅选出top1的图片及其相似度分数。
注:由于在训练BertCLIP时,将图像编码器的权重冻结,所以该部分的能力,主要归功于OpenAI的clip预训练权重。如想要优化模型在域内数据的图片相似度计算能力,图像编码器需要一起参与训练。


04
结语
在本文中,笔者基于CLIP的思想,设计了Vit-Bert结构的BertCLIP模型,并且使用140万中文图文数据对,对模型进行预训练。在图文相似度、文本相似度、图片相似度任务上做了尝试,取得了不错的效果。
该预训练模型,能够在中文图文检索、文本相似度计算、同义词挖掘、相似图召回等任务上发挥作用。并且在下游的一些多模态任务中,可以凭借该模型同时引入图片和文本信息,扩充模型的信息域。由于Bert需要将文本空间向图片空间对齐,所以Bert必然能够学到了丰富的语义信息,这能够对下游的NLP任务带来增益。读者也可以基于笔者分享的Bert预训练权重,进行下游NLP任务的finetune,相信会有所帮助。
不足之处在于,对于预训练而言,140万的数据稍显不足,读者可以使用自身域内数据进行二次预训练。
审核编辑 :李倩
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 187
-
基于预训练模型和长短期记忆网络的深度学习模型2021-04-20 1416
-
基于BERT的中文科技NLP预训练模型2021-05-07 1182
-
多模态图像-文本预训练模型2021-09-06 5037
-
中文多模态对话数据集2023-02-22 2490
-
什么是预训练 AI 模型?2023-04-04 2717
-
什么是预训练AI模型?2023-05-25 2219
-
基于预训练模型和语言增强的零样本视觉学习2023-06-15 1366
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1693
-
多模态大模型最全综述来了!2023-09-26 3825
-
如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解2023-10-29 3199
-
北大&华为提出:多模态基础大模型的高效微调2023-11-08 2638
-
大模型+多模态的3种实现方法2023-12-13 3568
-
预训练模型的基本原理和应用2024-07-03 6075
全部0条评论

快来发表一下你的评论吧 !
