

ACC-Turbo实现于可编程交换机
描述
背景/问题
在现在的DDoS攻击中,攻击流量不再是长而持续,而是转为了短而高频的波状流量。波状DDoS攻击与常规DDoS攻击相同,目的都为瘫痪服务节点或为瘫痪某条链路,但波状DDoS与常规DDoS不同的是,波状DDoS攻击可以突破现有DDoS防御机制——ACC(Aggregate-based Congestion Control,基于聚合的拥塞控制机制)——的防御。ACC的工作流程如下所示: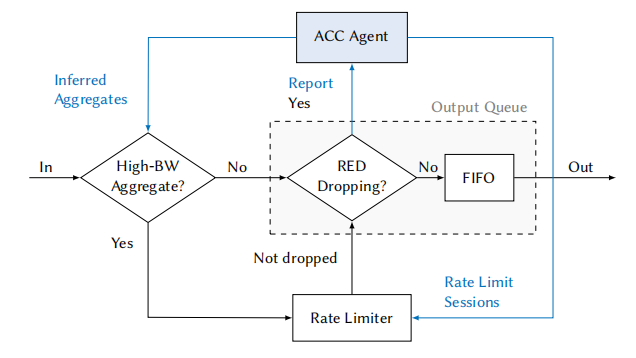
在DDoS攻击发生时,ACC会首先让所有的包过FIFO队列,当拥塞产生丢包之后,数据面会向控制面报告包信息。控制面上的ACC代理在接收到包信息之后会执行两个操作:包分析和包策略修改。这两步加起来耗时一般需要几分钟的时间量级。
之后,ACC代理向数据面发布新的包处理策略,将分析出的若干数据流聚合,并限制该聚合流的速率,以此实现对DDoS攻击的防御。
然而,ACC需要几分钟的响应时间才能对特定流完成分析并进行聚合与策略发布,这给了攻击者可乘之机。攻击者通过将攻击流划分成短而高频的波状攻击流,使得每一波攻击的持续时间约为一分钟,导致ACC无法完成对DDoS攻击的响应,并在效果上成功实现DDoS攻击。本文所诉即为如何设计并实现一个快速响应的DDoS防御系统。本文使用可编程交换机实现了ACC-Turbo,一种快速响应的DDoS防御系统,并进行了评估。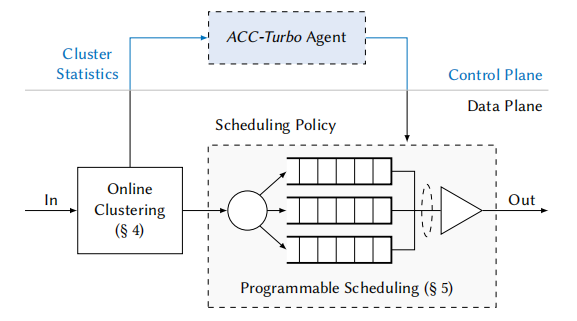
设计
本文将ACC代理拆成了两块:流量聚合与策略发布。时间敏感的流量聚合的功能实现在交换机上,它能够以线速率实现对于包粒度的流量聚合;而非时间敏感的策略发布功能实现在控制面上,负责接收聚合的信息并对每个不同的聚合分别发布不同的策略。ACC-Turbo的工作流程如下图所示。
在ACC-Turbo中,流量会先进入聚合器进行聚合,并在聚合完成后进入调度器执行被分配的策略。由于聚合器是在交换机上实现的,因此它是一个在线的聚合器,并且能以线速率实现在包粒度上实现对于流量的聚合。这是ACC-Turbo响应时间比ACC快的主要原因。聚合器的具体实现方式如图所示。
在交换机中,ACC-Turbo将流量以(源ip,目的ip)为坐标并映射到二维平面上,使用寄存器记录每个聚合的坐标上下限,使用布隆过滤器记录流量的集合。当新的包到达交换机时,ACC-Turbo会根据坐标与各个聚合之间的曼哈顿距离来将包聚合到最接近的类中,实现对于流量的聚合。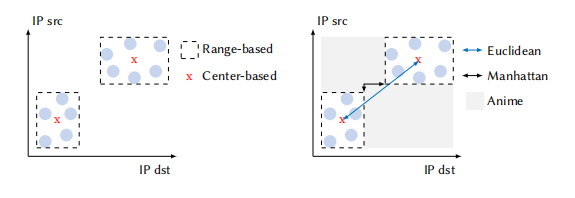
性能评估
ACC-Turbo的评估如下图所示。在使用波状DDoS攻击的时候,可以看到ACC-Turbo成功防止了链路被攻击。在防御过程中,会有部分攻击流量因为没有成功聚合到正确的类而被放过,但总体占比较小并不会对链路产生较大影响;在响应时间上,ACC-Turbo成功的在每个波状流量来临时及时的完成了响应,它的响应时间小于1秒,比当前其他最前沿防御技术快了10倍。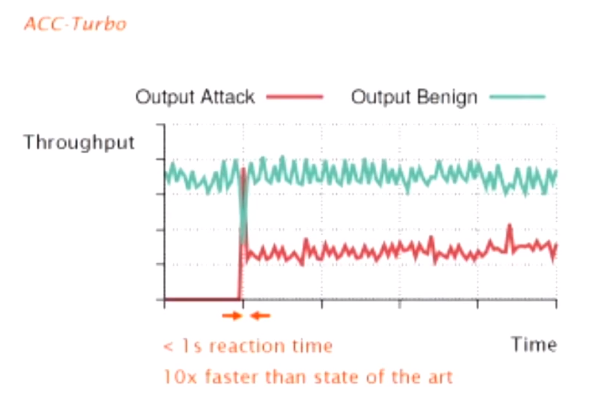
个人观点
个人觉得这是一个很有意思的事情,你有你的张良计,我有我的过墙梯。DDoS攻击与防御算的上是最强之矛与最强之盾的角逐之一。ACC的设计者可能并没有想到,嘿,DDoS还给我整出波状攻击的花活;而波状攻击的设计者可能也没想到,嘿,ACC-Turbo居然用可编程交换机来快速聚合。个人很期待下一轮的DDoS的攻防角逐,毕竟ACC-Turbo依旧有反应延迟,DDoS依旧有可能通过压缩每波的持续时间来进行攻击,不知到时候防御方将如何应对。
IXP scrubber: learning from blackholing traffic for ML-driven DDoS detection at scale
Matthias Wichtlhuber (DE-CIX), Eric Strehle(Brandenburg University of Technology), Daniel Kopp (DE-CIX), Lars Prepens (DE-CIX), Stefan Stegmueller (DE-CIX), Alina Rubina (DE-CIX), Christoph Dietzel (DE-CIX), Oliver Hohlfeld (Brandenburg University of Technology)
这篇文章来自麻省理工学院和瞻博网络团队的研究者。它介绍了一种用于瞻博网络MX系列路由器和交换机的可编程芯片组——Trio。
背景/问题
分布式拒绝服务(DDoS)攻击是最严重的网络安全威胁之一,甚至危及最大网络和服务的稳定性。现有的缓解服务范围主要在互联网边缘进行过滤,从而给网络基础设施造成不必要的负担。因此,我们提出了一种基于机器学习(ML)的系统IXP过滤器,用于在互联网交换点(IXP)检测和过滤互联网核心的DDoS流量,这些交换点可以看到大量和各种DDoS。
设计
步骤1:引入规则标签,通过将单个流标记为良性或恶意,通过网络防火墙,操作员可以在WEB界面中验证他们。步骤2:将平衡数据集的流以时间和目标进行分组,在相同时间内。所有时间和目标相同的流会被整合到一个数据集里。这些数据记录会根据数据包平均大小,所有流的字节数还有数据包数进行排序。如果我们发现数据记录中至少有一个流被标记为blackholed,那么我们可能会认为这条记录是DDOS。
性能评估
作者在5个IXP节点安装了IXP Scrubber以测试其在时间稳定性(重新训练时长间隔)、地理稳定性(不同地区的模型是否通用)以及结果的可解释性。分类排序: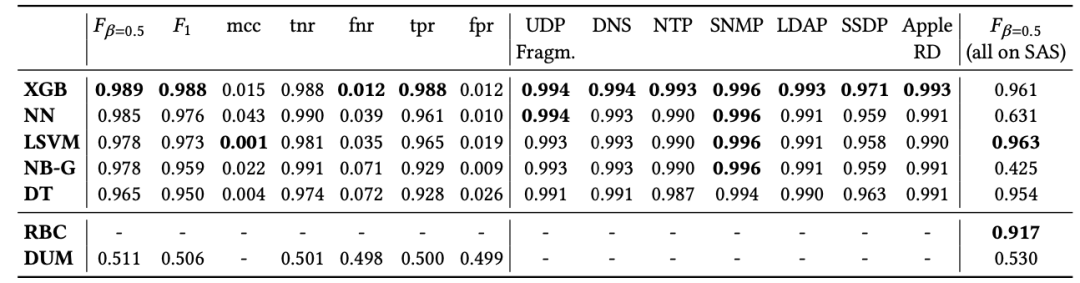
实验发现采用XGB模型可以获得最高的正确率。同时对于运营者而言可读的rule mining 方法也具有较优的性能,应证了在设计中将两者结合的合理性。同时实验表明不同IXP之间的模型可以通用(仅有较小性能损失),同时模型的有效性与重训练时长负相关(合理的重训练间隔在1月左右)。
个人观点
IXP Scrubber将防御DDOS攻击与机器学习相结合,具有较好的创新性。它作用场景在互联网交换点,而在这些交换点可以看到大量和各种DDoS流量。IXP Scrubber中的XGB模型有最高的正确率,而rule mining模型则有较高的可读性与较高的准确性。但是文章对于流量过滤中的false positive情景及其对网络有效传输产生的影响还需要进一步说明。
SurgeProtector: mitigating temporal algorithmic complexity attacks using adversarial scheduling
Nirav Atre (Carnegie Mellon University), Hugo Sadok (Carnegie Mellon University), Erica Chiang (Carnegie Mellon University), Weina Wang (Carnegie Mellon University), Justine Sherry (Carnegie Mellon University)
这篇文章来自普渡大学的Vishal Shrivastav。它主要介绍了Thanos,可以增强现有的可编程交换机pipeline,支持对一组资源进行可编程的多维过滤。
背景/问题
网络中路由器内置函数易受到算法复杂度攻击(ACA)的攻击。使用ACA,攻击者只需要少量的网络和计算资源生成数据报,就可以在目标系统上消耗大量计算资源。给定足够的请求速率,攻击者可以使受害者过载,导致其丢弃来自服务的常规用户的请求。与传统的DoS攻击相比,ACA以其效率和不易发现性,更加危险。
设计
Surgeprotector的主要功能是在network function中,加入一个WSJF(Weighted Shortest Job First)的调度算法,这个算法可以对DF(displacement factor)设置一个上限,同时他对其他的算法有很好的兼容性。同时WSJF不会对正常的用户流量施加限制,即使用户的报文出现了失序,也不会因为处理时间复杂度过高而被丢弃,因此可以将损失降到最低。
性能评估
实验主要应对两种ACAs攻击场景:1.向TCP Reassembler发送高度乱序的报文;2.发送最大报文长度限制的数据包,以消耗路由器在验证报文正确性的时间。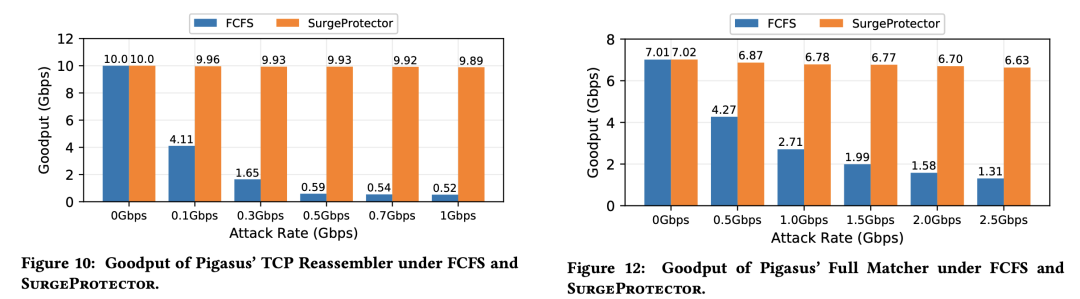
实验显示SurgeProtector的策略相较默认策略(FCFS)在吞吐量上有极大提高。
个人观点
Surgeprotector的设计其实不算复杂,本质上是将WSJF(Weighted Shortest Job First)算法应用在路由器中易受攻击的网络函数(network function)中,使得复杂的任务不会无限占用资源。但是却能够收到很好的效果,主要在于它不会对正常的用户流量施加限制。我认为有一个可能的改进是能否根据某种特征主动识别出疑似ACA的攻击报文,并将其从任务队列中移除,这样可以进一步提高效率。
Design and Evaluation of IPFS: A Storage Layer for the Decentralized Web
Dennis Trautwein (Protocol Labs & University of Göttingen), Aravindh Raman (Telefonica Research), Gareth Tyson (Hong Kong University of Science & Technology (GZ)), Ignacio Castro (Queen Mary University of London), Will Scott(Protocol Labs), Moritz Schubotz (FIZ Karlsruhe – Leibniz Institute for Information Infrastructure), Bela Gipp (University of Göttingen), Yiannis Psaras (Protocol Labs)
这是一篇来自哥廷根大学等各个地方的论文。他给出了IPFS(the InterPlanetary File System)的设计与评估。IPFS是一个去中心化的WEB平台,用于文件存储与传输。
背景/问题
近年来,网络运营的整合越来越多。例如,现在大部分的网络流量都来自于少数几个组织,甚至微型网站也经常选择托管在已经存在的大型云基础设施上。为了应对这一问题,“去中心化网络”试图更均匀地分配网络服务的所有权和操作。本文给出了IPFS的设计与实现与评估。IPFS是目前最大同时也是最广泛运用的去中心化的web平台,已经支持了数十个第三方应用。
设计
IPFS的工作流程如下图所示。对于提供者而言,他首先将文件传入本地的IPFS中生成一个CID(Content Identifiers),并将该CID发布给请求者并把CID传入DHT网络。DHT网络会自动找到和该CID最接近的节点。在找到之后,提供者会与该节点一同存储数据。对于请求者而言,他首先会将获取到的CID传入DHT网络。DHT网络会自动为其找到最接近的节点。当请求者得到节点信息之后,即可通过该节点与提供者形成链路连接,开始下载。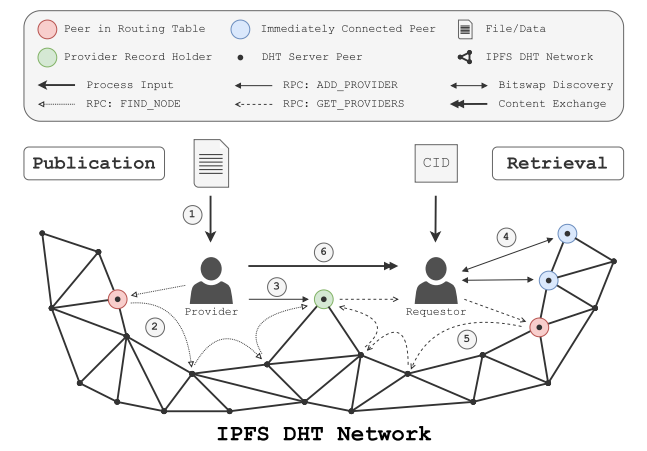
性能评估
由于IPFS是一个已经在使用的系统,因此文中给出了许多真实的用户数据。例如,如果对IP进行归属,可以发现大量的IP所属都为亚马逊、微软等服务巨头,佐证了当前大部分的网络流量都来自于少数几个组织的说话。具体的性能评估方面,对于UE节点的请求80%可以在500ms内处理完成,而对于所有请求类型来说,500%的请求可以在1s内完成。
个人观点
由于这是一个已经使用中的系统,因此在设计上没有给笔者十分亮眼的感觉,这可能是笔者的偏见。在论文中,由于是一个实际使用的系统因此有很多真实数据,值得一观。
From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud
Rui Miao, Lingjun Zhu, Shu Ma, Kun Qian, Shujun Zhuang, Bo Li, Shuguang Cheng, Jiaqi Gao, Yan Zhuang,Pengcheng Zhang, Rong Liu, Chao Shi, Binzhang Fu, Jiaji Zhu, Jiesheng Wu, Dennis Cai, Hongqiang Harry Liu (Alibaba Group)
这是来自阿里巴巴group的文章。本文虽然是一篇文章,但是提出的是两个系统。针对一个数据中心的计算集群和存储集群而言,存在前端网络(FN)和后端网络(BN),本文的目的是优化这两个网络的性能使整体性能更优。第一个系统Luna同时优化了FN和BN,但是使得SA成为瓶颈。第二个系统Solar将SA部分功能卸载至硬件,优化了SA的性能。
背景/问题
一个EBS(Elastic Block Storage)的网络结构如下图所示。对于EBS而言,计算集群和存储集群通讯需要分别进过前端网络(CN)和后端网络(BN)。前端网络和后端网络的性能对于I/O来讲至关重要。由于前端网络需要支持多种多样的计算集群,而后端网络需要具有良好的拓展性以及良好的错误处理,常规的TCP已经不能满足两个网络的需求。 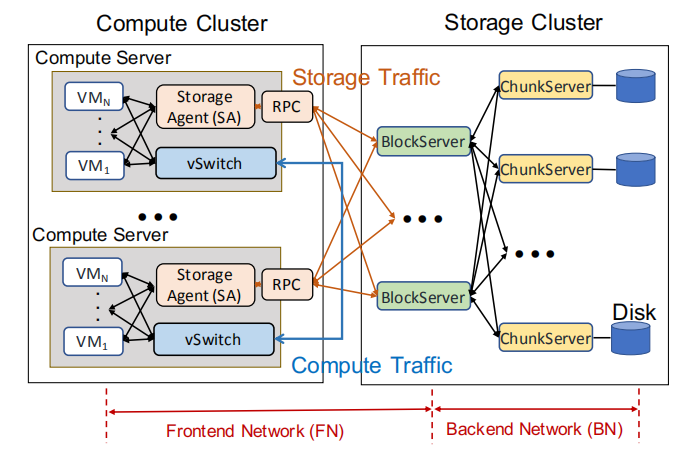
设计
Luna:对于前端网络来讲,Luna使用一个用户级别的软件TCP来实现对不用计算集群种类的支持;而对于后端网络来讲,由于其存储节点都是一致的,而任务也大致相同,因此可以采取不那么灵活的处理方案,在Luna中采用的处理方案是硬件RDMA。
在使用了Luna之后,对比之前的系统核方案,FN和BN的性能都得到了提升,但是存储代理(SA)成为了瓶颈。Solar:Solar的核心想法如图所示。由于在SA上数据都会走CPU,导致给数据总线过大的流量,使得网络性能被限制在了SA的性能上。Solar通过将数据流的路径卸到DPU上,并将控制面部署在CPU中,实现了数据流量与PCIe的脱钩,使得SA的性能不再是系统瓶颈。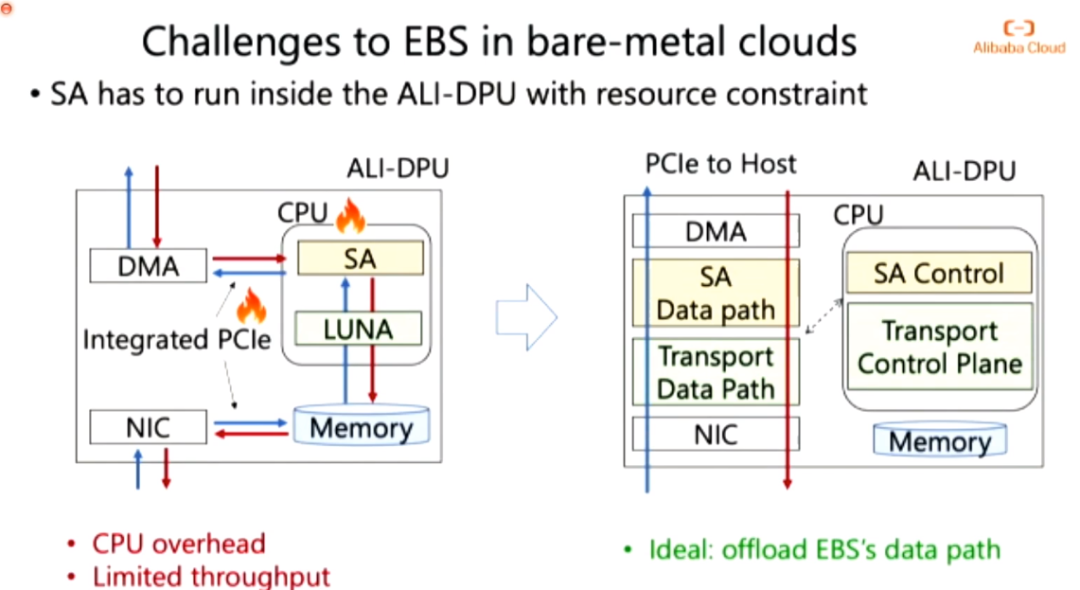
性能评估
相对于未使用Luna和Solar的情况下,Luna在FN的延迟上减少了80%,并且在BN的延迟上减少了50%。而在使用了Solar之后,SA的延迟相对于Luna减少了40%。 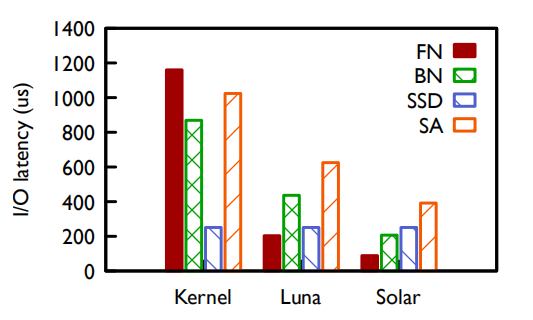
个人观点
与会之后就觉得,啊,这不是废话嘛!当然,这是事后诸葛。Luna对两个不同要求的网络使用了不同的定制网络,分别对其性能进行优化;而Solar在笔者看来,SA的物理位置有点像粘合器,将两种不同的网络接上,因此Solar对SA专门优化,将SA的数据面由CPU卸载至RDMA,使得SA对系统性能的限制有所下降。Luna和Solar分别对EBS的不同部分进行了优化,是非常优秀的工作。
审核编辑:刘清
-
如何实现POE交换机串联?2025-03-25 1581
-
具有单MII/RMII/Turbo MII支持LAN9303的以太网交换机2020-05-18 5485
-
接入层交换机、汇聚层交换机和核心层交换机的区别2021-06-04 8107
-
交换机堆叠2010-01-08 1243
-
与思科惠普竞争 瞻博发布核心SDN交换机2013-04-02 1197
-
英特尔展示P4可编程以太网交换机,采用光学引擎一体封装2020-03-07 5784
-
Intel展示Barefoot Networks可编程以太网交换机技术 具备高达12.8Tbps的吞吐量2020-03-08 5637
-
核心交换机、汇聚交换机与普通交换机的区别介绍2020-03-19 14382
-
HMC857:14 Gbps、2 x 2交叉点交换机,带可编程输出电压数据表2021-05-15 964
-
核心交换机、汇聚交换机、接入交换机之间的对比分析2022-11-02 27721
-
交换机配置是如何完成的2023-05-04 3912
-
千兆交换机和百兆交换机应该如何选择?2023-06-18 7789
-
PoE交换机可以当普通交换机使用吗2023-06-27 11245
-
浅谈交换机的发展历史2024-06-06 4961
-
可编程交换机如何无缝卸载集体操作2024-10-22 1682
全部0条评论

快来发表一下你的评论吧 !
