

采用基于时间序列的日志异常检测算法应用
描述
背景
目前,日志异常检测算法采用基于时间序列的方法检测异常,具体为:日志结构化 -> 日志模式识别 -> 时间序列转换 -> 异常检测。异常检测算法根据日志指标时序数据的周期性检测出历史新增、时段新增、时段突增、时段突降等多种异常。 然而,在实际中,日志指标时序数据并不都具有周期性,或具有其他分布特征,因此仅根据周期性进行异常检测会导致误报率高、准确率低等问题。因此如果在日志异常检测之前,首先对日志指标时序数据进行分类,不同类型数据采用不同方法检测异常,可以有效提高准确率,并降低误报率。
日志指标序列的类型
日志指标序列分为时序数据与日志指标数据两大类:
时序数据: 包含平稳型、周期型、趋势型、阶跃型。
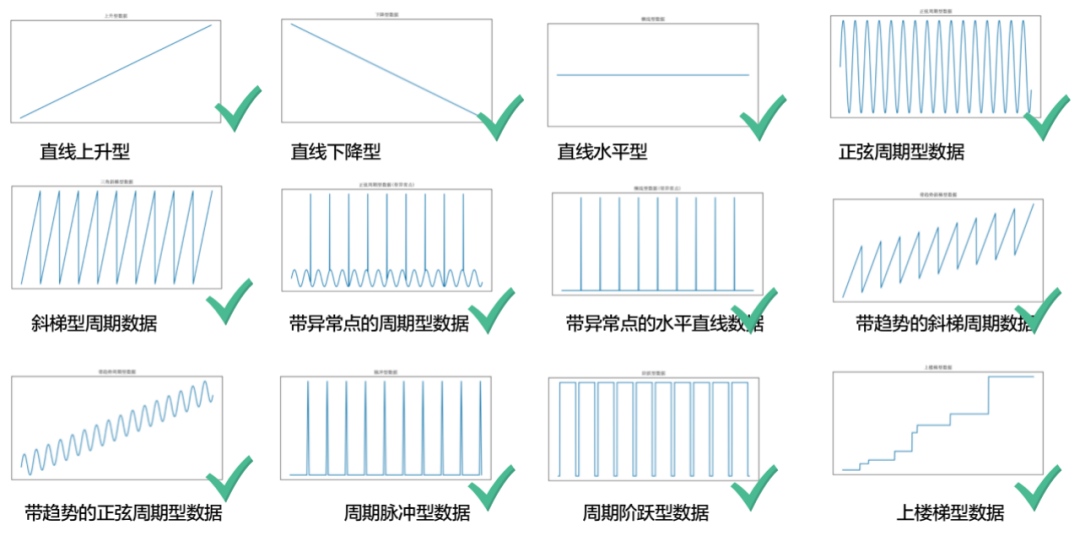
日志指标数据: 包含周期型、非周期型。
时间序列分类算法
时间序列分类是一项在多个领域均有应用的通用任务,目标是利用标记好的训练数据,确定一个时间序列属于预先定义的哪一个类别。时间序列分类不同于常规分类问题,因为时序数据是具有顺序属性的序列。 时间序列分为传统时间序列分类算法与基于深度学习的时间序列分类算法。传统方法又根据算法采用的用于分类的特征类型不同,分为全局特征、局部特征、基于模型以及组合方法 4 大类。基于深度学习的时间序列算法分为生成式模型与判别式模型两大类。本文主要对传统时间序列分类算法进行介绍。
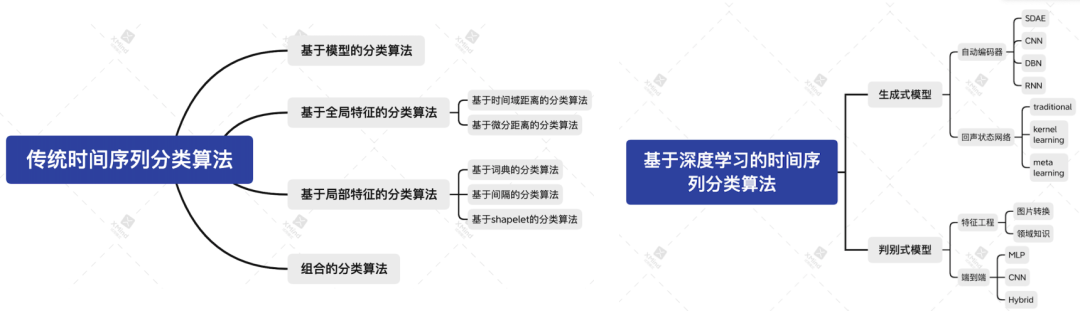
传统时间序列分类算法
基于全局特征的分类算法
全局特征分类是将完整时间序列作为特征,计算时间序列间的相似性来进行分类。分类方法有通过计算不同序列之间距离的远近来表达时间序列的相似性以及不同距离度量方法 + 1-NN(1 - 近邻)。主要研究序列相似性的度量方法。
时间域距离
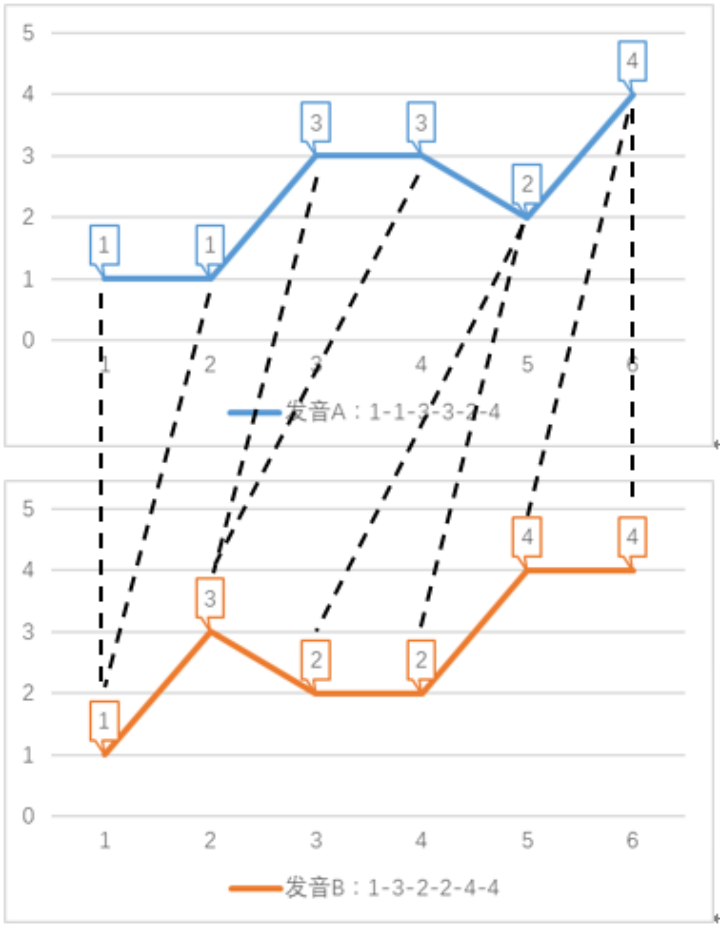
问题场景描述: 如下图所示,问题场景是一个语音识别任务。该任务用数字表示音调高低,例如某个单词发音的音调为 1-3-2-4。两个人说同一单词时,因为音节的发音拖长,会形成不同的发音序列 前半部分拖长,发音:1-1-3-3-2-4 后半部分拖长,发音:1-3-2-2-4-4 在采用传统欧式距离,即点对点的方式计算发音序列距离时,距离之和如下:欧式距离 = |A (1)-B (1)| + |A (2)-B (2)| + |A (3)-B (3)| + |A (4)-B (4)| + |A (5)-B (5)| + |A (6)-B (6)| =6_x0001_
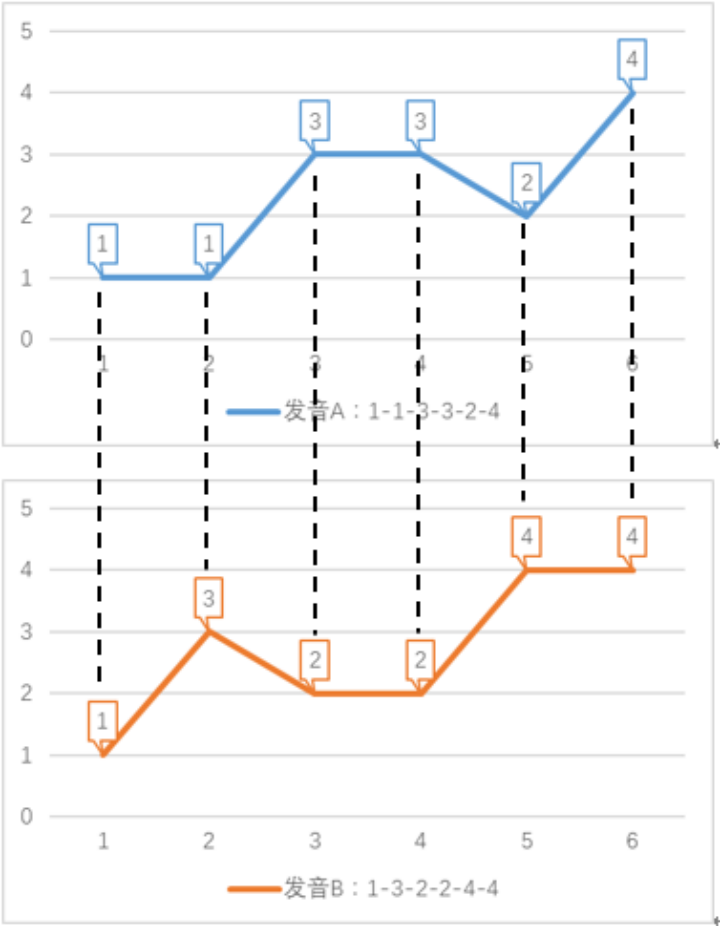
算法原理: 如果我们允许序列的点与另一序列的多个连续的点相对应(即,将这个点所代表的音调的发音时间延长),然后再计算对应点之间的距离之和,这就是 dtw 算法。dtw 算法允许序列某个时刻的点与另一序列多个连续时刻的点相对应,称为时间规整(Time Warping)。如下图所示,语音识别任务的 dtw 距离如下: dtw 距离 = |1-1| + |1-1| + |3-3| + |3-3| + |2-2| + |2-2| + |4-4| + |4-4| = 0 dtw 计算出的距离为 0,由此代表两个单词发音一致,与实际情况相符。
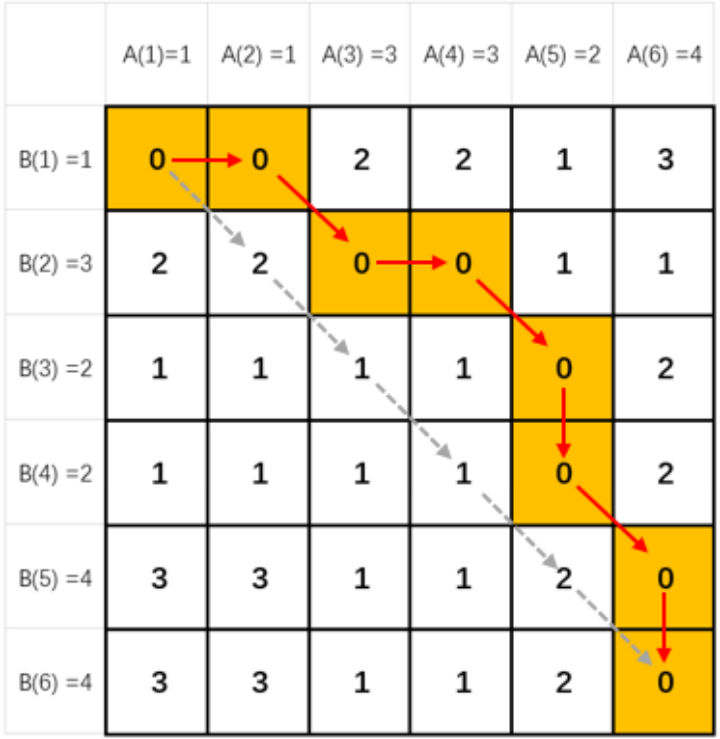
算法实现: dtw 算法实现包括计算两个序列各点之间距离构成矩阵以及寻找一条从矩阵左上角到右下角的路径,使得路径上的元素和最小两个主要步骤。距离矩阵如下图所示,矩阵中每个元素的值为两个序列对应点之间的距离。DTW 算法将计算两个序列之间的距离,转化为寻找一条从距离矩阵。左上角到右下角的路径,使得路径上的元素和最小。实现要点如下:
转化为动态规划的问题(DP);
由于寻找所有路径太耗时,需要添加路径数量限制条件(可以等效为寻找矩阵横纵坐标的差的允许范围,即 warping window)。
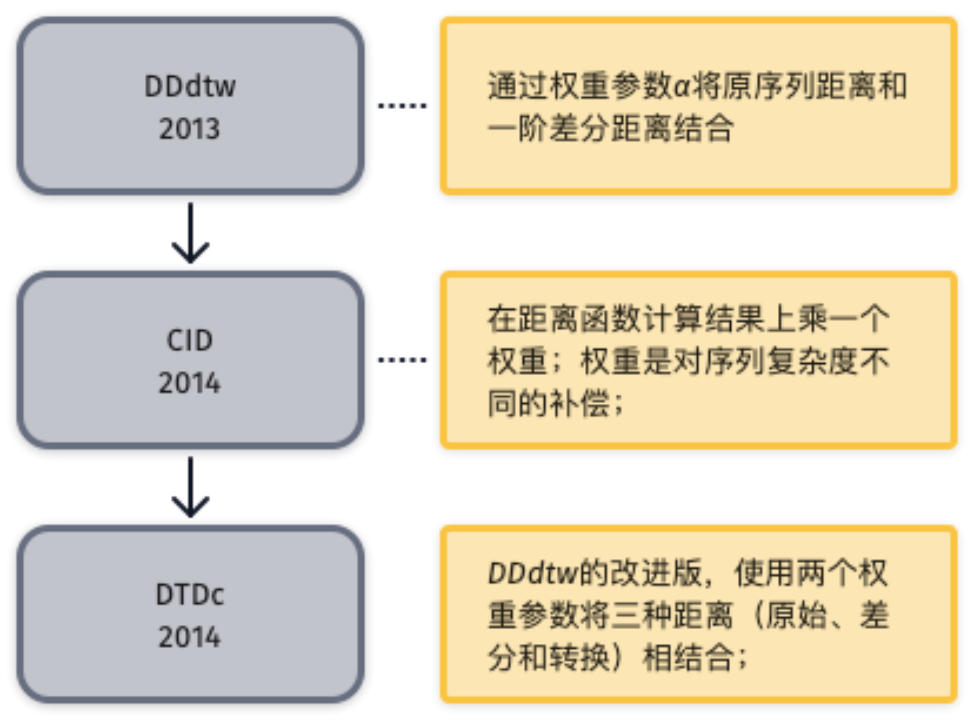
差分距离法
差分距离法是计算原始时间序列的一阶微分,然后度量两个时间序列的微分序列的距离,即微分距离。差分法将微分距离作为原始序列距离的补充,是最终距离计算函数的重要组成部分。 对于一个时间序列 t=(t1, t2, …,tm),其一阶微分计算公式如(2-1)所示,二阶微分计算公式如(2-2)所示,更高阶的微分计算方式依次类推。差分距离法将位于时间域的原时间序列和位于差分域的一阶差分序列相结合,提升分类效果。研究方向主要是如何将原序列和差分序列合理结合。
基于局部特征的分类算法
将单条时间序列中的一部分子序列作为特征,用于时间序列分类。主要有以下特点:
关键在于寻找能够区分不同类的局部特征;
由于子序列更短,因此构建的分类器速度更快;
但由于需要寻找局部特征,需要一定的训练时间。
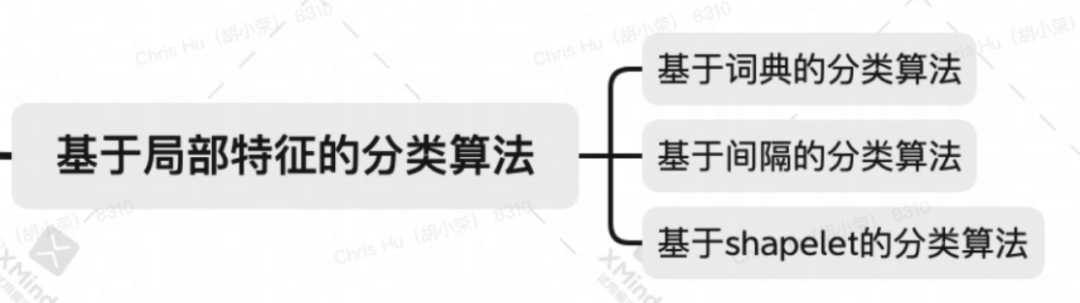
基于间隔(interval)的分类算法
基于间隔(interval)的分类算法分类方法是将时间序列划分为几个间隔,从每个间隔中提取特征。过程中需考虑以下关键问题:
需要找到最具有区分度特征的区间;
区间划分方法很多,如果处理大量的候选区间;
如何在每个区间上合理提取特征。
关键问题解决方法如下(TSF-Time Series Forest):
采用随机森林的方法解决序列区间数量大的问题,采用统计值作为特征;
长度为 m 的序列,提取 sqrt (m) 个区间,每个区间上提取均值、标准差和斜率三个特征,共 3*sqrt (m) 个特征用于训练;
分类结果由集成的所有树的多数投票决定;
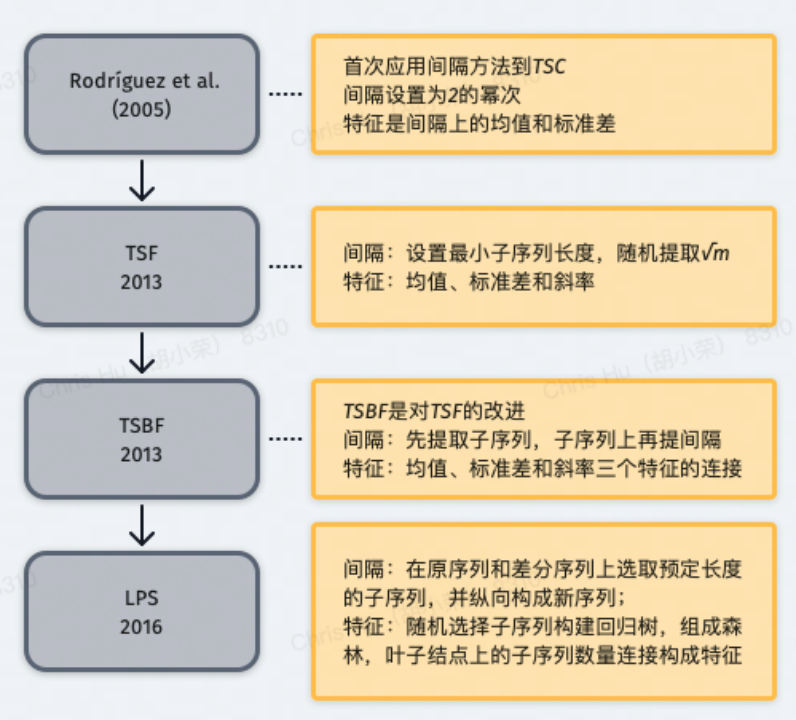
基于 shapelets 的分类算法
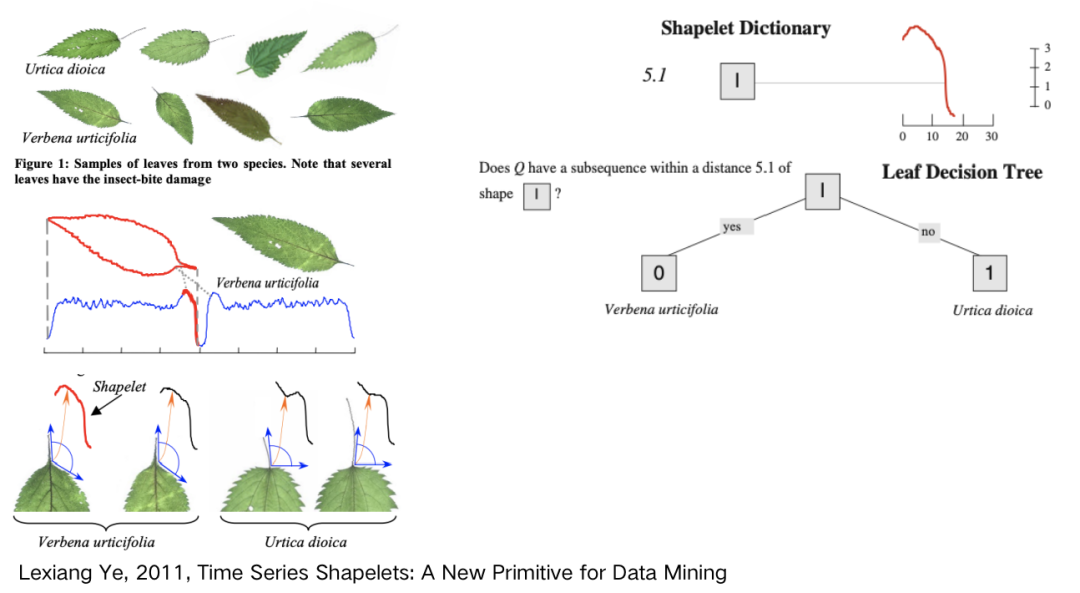
shapelet 分类算法通过在序列中查找最具辨别性的子序列用于分类,其中 shapelet 指一个与位置无关的最佳匹配子序列。该类算法适用于可以通过序列中的一种模式定义一个类,但是与模式的位置无关的分类问题。主要有以下两个研究方向:
shapelet 寻找:枚举所有可能的 shapelet,挑选最好的;
shapelet 用法:将 shapelet 用于决策树的结点分裂准则。
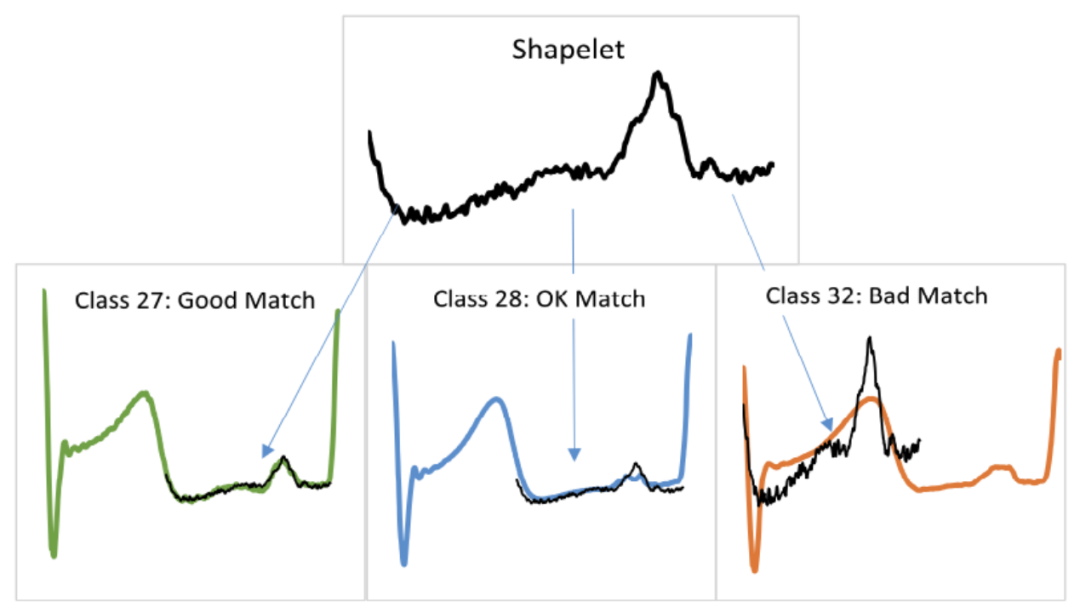
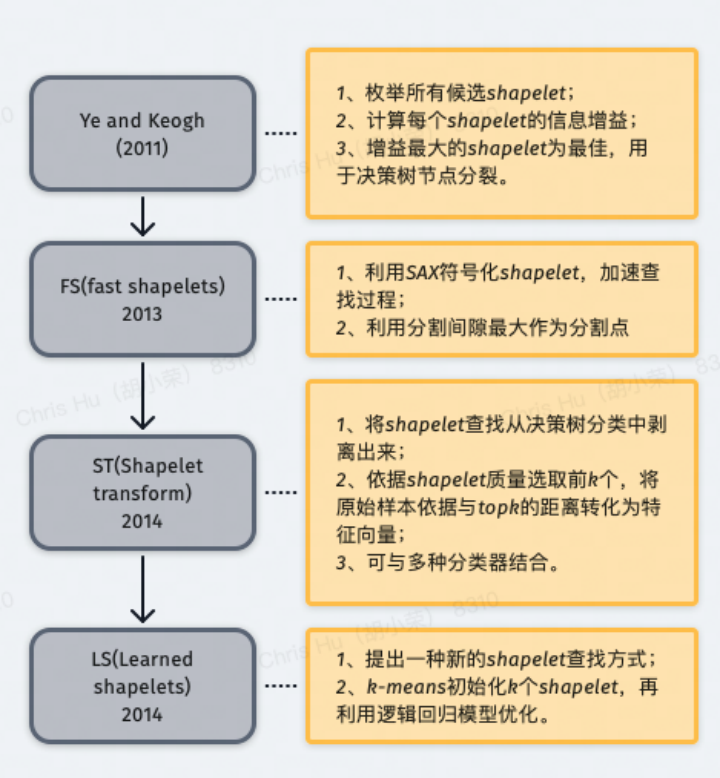
shapelet 分类算法通过在序列中查找最具辨别性的子序列用于分类,其中 shapelet 指一个与位置无关。
基于词典的分类算法
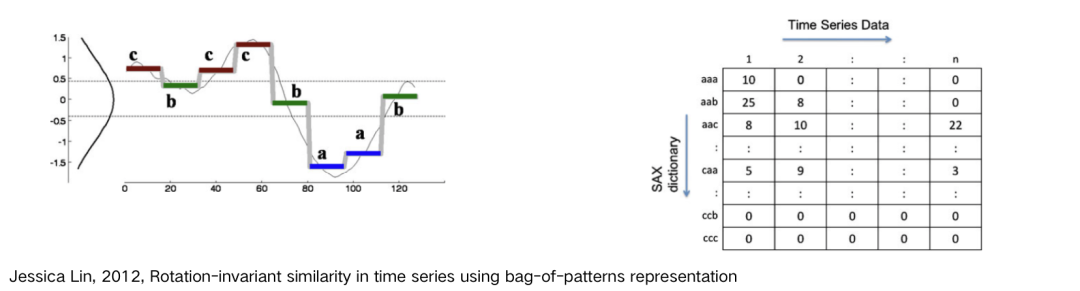
由于 shapelet 分类算法需要花费大量时间搜索子序列,因此更适用于短序列。对于长序列,更适用于在高级结构上衡量相似度。此外,shapelet 只使用一个最佳匹配进行分类,无法解决区别在模式重复数量上的分类问题。因此,对于长序列中一种模式反复出现的时间序列,更适用于一种叫做 dict 词典类的分类算法。 基于词典的分类算法原理是以序列中的子序列的重复频率作为特征进行分类。首先对序列进行降维和符号化表示,形成单词序列,然后根据单词序列中的单词分布情况进行分类。特点是通过给每个序列传入一个长度为 w 的滑动窗构建单词,每一个窗产生 l 个近似值,将每个值离散化,对应到一个字母表中的符号。 BOP - Bag of Patterns 采用了类似 “bag of words” 的思路,将时间序列表示成一系列模式的向量。存在问题如下:
需要构建 “模式词汇表 -> SAX
时间序列没有明显分隔符进行分割。- 滑动窗口
操作步骤如下:
BOP 算法采用滑动窗口在原始序列上取子序列;
再利用 SAX 方法将子序列转化为单词,并记录每个单词数量,所有的单词汇总为词汇表;
最后构建 “单词 - 句子” 向量矩阵,行是词汇表,列是每个时间序列,点的值是词汇在序列中的出现频率。
_x0008_SAX (Symbolic Aggregate Approximation) 对序列进行正则化,在横轴方向,将时间序列等长划分为 w 段,计算每一段的均值,并将 w 个系数聚集在一起,这个过程称为分段聚集近似(Piecewise Aggregate Approximation,PAA)。 研究表明正则化的时间序列的子序列服从高斯分布,在纵轴方向,将均值从高斯分布等概率划分为三块区域,位于每个区域的系数分别用 a,b,c 表示,此时序列已转化为字符串。
审核编辑:郭婷
-
【「时间序列与机器学习」阅读体验】全书概览与时间序列概述2024-08-07 2863
-
【AIOps】一种全新的日志异常检测评估框架:LightAD,相关成果已被软工顶会ICSE 2024录用2023-11-29 1679
-
智能电网时间序列异常检测:a survey2023-04-04 795
-
如何选择异常检测算法2021-10-25 2520
-
虚拟机迁移的物理主机异常状态检测算法2021-06-30 996
-
基于离群点检测算法的电力市场异常行为辨识2021-06-01 971
-
一种多维时间序列汽车驾驶异常点检测模型2021-05-26 1022
-
基于时间卷积网络的通用日志序列异常检测框架2021-03-30 1575
-
机器学习算法概览:异常检测算法/常见算法/深度学习2018-04-11 21255
-
基于角度方差的数据流异常检测算法2018-01-17 1362
-
基于概率图模型的时空异常事件检测算法2017-12-28 762
-
密度偏倚抽样的局部距离异常检测算法2017-12-25 985
-
基于树结构的回溯异常检测算法2017-12-07 909
-
基于粒子群优化算法的属性异常检测算法2017-11-20 775
全部0条评论

快来发表一下你的评论吧 !
