

高算力芯片未来技术发展途径
电子说
描述
面向未来高算力芯片需求,分析了国内外高算力芯片发展趋势,提出由数据互连、单位晶体管提供的算力、晶体管密度和芯片面积构成的芯片算力表达式。介绍了未来高算力芯片发展的关键技术,并结合算力表达式论述相关技术如何发挥作用。从新材料、新器件、先进工艺、新架构、集成封装等角度出发,探讨了集成电路先进制造工艺、单片三维集成技术、领域专用架构、粗粒度可重构架构、存算一体技术、芯粒(Chiplet)技术和晶圆级集成等国内外发展现状及其对芯片算力的提升效果,并深入分析了各项技术的发展和挑战。结合中国高算力芯片现状和集成电路先进制程发展受限,提出从“架构+集成+系统”出发,探索实现高算力芯片的一体化自主可控创新路径,可以采用成熟制程,结合粗粒度可重构和存算一体新型架构,采用基于先进集成的芯粒技术实现总算力突破。 随着信息社会数字化、智能化水平的不断提高,人类社会已进入算力时代。当前算力基础设施主要以数据中心的形式实现高性能算力供应,其中,高算力芯片是算力的具体载体——提供超算算力、通用算力、智能算力和边缘算力。数字经济时代,算力高低成为综合国力强弱的重要指标之一,高算力芯片技术是国家核心竞争力的重要体现。本文将探讨高算力芯片未来技术发展途径。
数据是信息时代的“石油”,算力则将数据转化为动能,驱动经济和科技的发展,是数字经济时代的引擎。数字经济转型和新基建、“东数西算”等战略工程驱动中国实现算力基础设施化。高算力芯片是算力载体,通过其提供的计算能力,支撑互联网、金融、科技、制造业等各个行业的发展和数字化转型,赋能人工智能、自动驾驶、智能物联网、高性能计算和元宇宙等应用场景。现阶段,5G、云计算、大数据、物联网、人工智能等技术高速发展,数据爆炸式增长,算法复杂度不断提高,加快高算力芯片发展,是中国打造数字经济新优势、提升国家整体竞争力和国防安全的重要保障。
01 高算力芯片国内外发展态势
1.1 科技发展对芯片算力的需求爆发式增长
当前,高算力芯片在典型应用场景中呈现如下分布:以云端部署为主,并逐渐向边缘端扩散,最终在云、边、端侧形成分布式高算力网络。在不同应用场景中,衡量芯片算力的具体指标会有相应差异。对于高性能计算任务,单位时间内的高精度浮点计算峰值是重要指标,如64位双精度浮点;对于人工智能训练及推理任务,只需关注较低精度数据的处理速度,如16位浮点或者8位整型精度;对于图像处理任务,系统运行的帧率是关键指标。但是,差异化任务场景背后的高算力技术是共性、通用的。本文采用TOPS(Tera Operations Per Second,万亿次运算每秒)作为算力指标,衡量典型高算力场景下的芯片算力需求。当前,技术路线发展和多项应用场景都提出了至少高于1000 TOPS的高算力芯片需求。
(1)数据中心和超算需要高于1000 TOPS的高算力芯片。当前,超算中心算力已经进入E级算力(百亿亿次运算每秒)时代,并正在向Z(千E)级算力发展。2022年5月登顶世界超算500强榜单的美国国防部橡树岭国家实验室Frontier超算中心,采用AMD公司MI250X高算力芯片(可提供383 TOPS算力),达到了1.1 EOPS双精度浮点算力。
(2)新一代人工智能任务需要高于1000 TOPS的高算力芯片。深度学习兴起带来了人工智能的新一轮繁荣。当前,深度学习发展逐步进入大模型、大数据阶段,模型参数和数据量呈爆发式增长,引发的算力需求平均每2年超过算力实际增长速度的375倍,因此底层硬件算力难以满足算法需求。以2020年发布的GPT3预训练语言模型为例,其拥有1750亿个参数,使用1000亿个词汇的语料库训练,采用1000块当时最先进的英伟达A100 GPU(图形处理器,624 TOPS)训练仍需要1个月。
(3)高性能移动端应用,如自动驾驶任务需要高于1000 TOPS的高算力芯片。追求更高算力是当下自动驾驶领域发展的一大趋势,高阶自动驾驶对算力需求呈指数级上升。L2、L3、L4和L5级自动驾驶至少需要10、100、400、3000 TOPS的算力。中国智己L7整车达到1070 TOPS,蔚来ET7整车达到1016 TOPS,背后均搭载了254 TOPS的英伟达Orin X高算力芯片。预计2025年,英伟达公司将发布1000 TOPS的Atlan高算力芯片。
综合考虑集成电路技术发展下的芯片算力现状和未来人工智能、数据中心、自动驾驶等领域的发展趋势,未来高算力芯片需要不低于1000 TOPS的算力水平。
1.2 中国高算力芯片发展仍落后于算力产业发展
根据2022年《中国算力白皮书》,2022年中国整体算力达到150 EOPS,占全球总算力的31%,在全世界仅落后于美国(36%),中国算力产业发展对高算力芯片需求强劲。一方面,高算力芯片作为底层算力池,赋能万千行业和新兴产业,市场发展造成了对高算力芯片的强劲需求;另一方面,国家布局和政策引导也推动了高算力芯片的需求。除了“东数西算”工程外,“十四五”规划和2035年远景目标纲要明确提出要“建设若干国家枢纽节点和大数据中心集群,建设E级和10E级超算计算中心”,国家发展和改革委员会也出台了一系列政策文件,全国多个地区进行数据中心建设和布局。市场发展和政策实施都对大力发展高算力芯片技术提出需求。
然而,中国高算力芯片的发展从知识产权、市场占有率与自主制造角度依然面临严峻挑战。浪潮、华为、新华三、联想等国产服务器品牌位居中国服务器市场前5名,整体份额达到74%,然而底层的通用高算力芯片却严重依赖进口。在以中央处理器(CPU)为核心的通用数据中心产业,仍以美国英特尔和AMD主导的x86架构CPU主导,市场占比超过96%。华为鲲鹏系列服务器芯片是中国自主研发的基于ARM指令集的高性能芯片,但是高度依赖先进制造工艺。在智能芯片领域,GPU仍是智能数据中心的主流算力芯片,2020年中国智能数据中心约95%的市场份额由美国英伟达的芯片占据。近年来,中国涌现了壁仞、天数智芯、沐曦、摩尔线程等国产GPU产品以及华为昇腾、寒武纪思元、百度昆仑芯、燧原等自主人工智能(Artificial Intelligence, AI)芯片产品,但都过度依靠国内尚无法自主可控的先进制造工艺。
因此,亟须探索符合国情的高算力芯片的创新发展途径,保障中国产业战略布局实施,助推数字经济发展。
1.3 高算力芯片技术发展途径
芯片算力由数据互连、单位晶体管提供的算力(通常由架构决定)、晶体管密度和芯片面积共同决定。
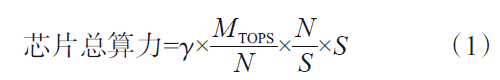
式中,γ为互连系数,既包括存储和计算单元之间的互连带宽,也包括计算单元之间的互连带宽,取值为0~1。MTOPS为以TOPS为单位的算力,N为晶体管数目,S为芯片面积。
自集成电路兴起的60多年来,算力芯片的发展主要依赖于摩尔定律指引下的工艺制程进步和体系架构改进。然而,随着器件尺寸逼近物理极限,芯片集成度遵循摩尔定律发展的趋势逐渐变缓,先进工艺成本增加,同时单片芯片的面积有限,这些因素共同导致很难继续通过提升芯片面积和晶体管集成度来增加算力。现有计算平台主要基于冯·诺依曼架构,存储单元和计算单元彼此分离,任务处理需要数据频繁在存储单元和数据单元间搬移,消耗在搬移过程中的延时和功耗成为系统性能瓶颈,造成“存储墙”和“功耗墙”。同时芯片的I/O引脚有限,I/O数据传输速度匹配不上计算速度,也会造成“I/O墙”,和“存储墙”一起限制了互连系数γ的提高。这些挑战制约了计算芯片算力的进一步提升。
本文将从算力表达式出发,通过分析新型材料器件、架构、工艺和集成方案,探讨有望打破算力瓶颈的新兴高算力芯片技术。
02 后摩尔时代的晶体管密度提升途径
2.1 先进制造工艺带来的算力提升
按照摩尔定律经验,集成电路上可以容纳的晶体管数目每18个月便会提升1倍。集成电路制造工艺按照摩尔定律不断发展,目前先进制程已进入3 nm节点。摩尔定律下的集成电路尺寸微缩能带来单位面积算力的指数提升,不仅可以提升单位面积的晶体管数目,还能通过提升时钟频率来提升单位晶体管算力,从而提高芯片总算力(式(1))。图1统计了英伟达GPU算力与工艺制程的关系。图1(a)显示GPU单位面积芯片算力随工艺节点的进步而提升,横坐标为不同工艺制程节点,纵坐标为对数坐标下的归一化单位面积算力。图1(a)内表格对比了65 nm和90 nm制程下的帕斯卡(Pascal)架构GPU,可以看到,先进工艺节点晶体管密度和工作频率均显著提高,从而带来芯片整体算力的提升。图1(b)对应总结了GPU归一化芯片算力与归一化晶体管数目和时钟频率乘积的关系,表明先进工艺是芯片算力提升的关键推动力。近年来,英伟达、超威、苹果的高算力芯片均采用7、5 nm先进制程实现。
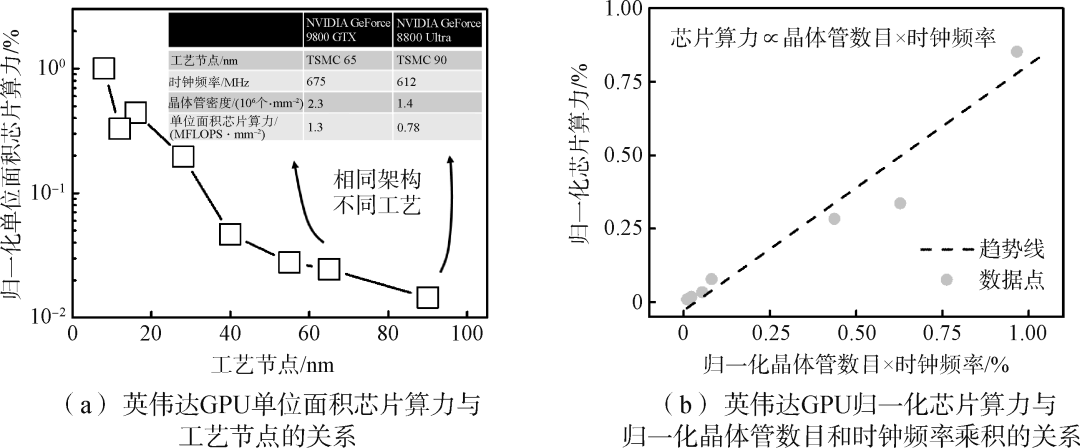
图1 英伟达GPU算力与工艺制程的关系
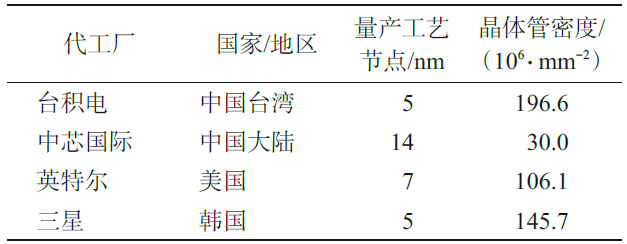
中国集成电路制造起步较晚,且受出口管制影响,虽然制程发展迅速,但整体水平相对落后。表1展示了全球主要集成电路制造厂的量产工艺节点及晶体管密度。中国台湾积体电路制造股份有限公司(简称台积电)和三星均已量产5 nm工艺节点,英特尔也量产了7 nm工艺节点,晶体管密度均超过了1亿个/mm2,大陆代工厂中芯国际打通了14 nm工艺节点,晶体管密度达到3000万个/mm2。
表1 全球主要集成电路制造厂的量产工艺节点及晶体管密度
2.2 摩尔定律发展的挑战与机遇
随着集成电路工艺节点的不断进步,摩尔定律发展受到非理想物理效应和工艺成本等诸多限制,其中主要的挑战一方面在于光刻技术,另一方面在于器件的短沟道效应。
光刻是集成电路制造的核心工艺,决定了器件的空间尺度。为满足先进制程需求,将采用极紫外(Extreme Ultra-Violet, EUV)光刻机。EUV直接将光源波长从193 nm缩短至13.5 nm,通过将整个光路放置在真空环境下,把透镜组变成反射镜组等方式,减小了短波长光在光路中的损耗。采用EUV结合各种先进工艺技术,实现3 nm工艺节点没有障碍,但面临成本控制、光源波长缩短和光源稳定性问题。
短沟道效应是指随器件尺寸微缩达到物理极限,量子效应和非理想因素将逐渐显现,影响器件性能,包括阈值电压降低、漏致势垒降低、载流子表面散射和热电子效应等。增加栅控能力是抑制短沟道效应的关键,为此,集成电路制造已从平面工艺发展为鳍式场效应晶体管(Fin Field-Effect Transistor, FinFET)工艺,通过增加栅极维度改善栅控效果。随着工艺节点往3、2 nm发展,将需要全新器件结构实现更强的栅控,基于环栅场效应晶体管(Gate-All-Around Field-Effect Transistor, GAAFET)和多桥通道场效应晶体管(Multi-Bridge-Channel Field-Effect Transistor, MBCFET)器件结构的制造流程将成为主流(图2)。
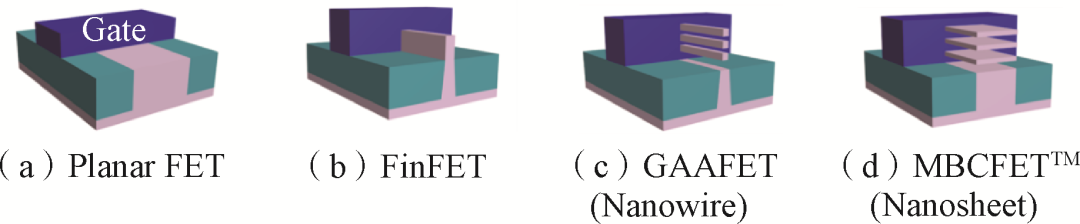
图2 工艺制程发展中的不同器件结构
2.3 单片三维集成技术
在二维空间实现高密度晶体管集成的手段已经逐步逼近极限,未来摩尔定律的发展可通过单片三维集成实现。通过在垂直方向堆叠晶体管和其他逻辑、存储器件,进一步提升单位面积的晶体管数目和数据通信效率,实现提高芯片算力。斯坦福大学教授Phillip Wong团队通过评估表明,单片三维集成芯片相对于传统二维芯片,具有1000倍以上的功耗延时乘积优势。该技术发展需要克服工艺兼容、散热、良率和可靠性问题。异质单片三维集成技术是现在研究的前沿热点,斯坦福大学、麻省理工学院和清华大学、北京大学都在进行深入研究。2021年国际电子器件会议(IEDM)上,清华大学钱鹤、吴华强研究团队展示了一个集内容寻址和存算单元核心于一体的单片三维集成系统,该系统与传统芯片相比拥有2个量级的能耗优势(图3)。
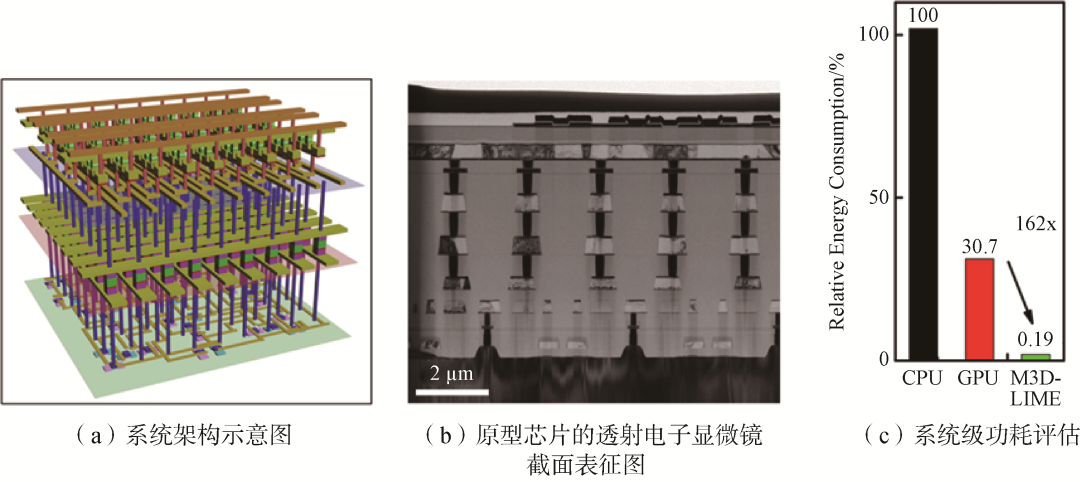
图3 碳、硅和忆阻器单片三维异质集成系统
03 基于新型计算架构的算力提升途径
计算架构的好坏影响了芯片单位晶体管能提供的算力水平,是决定芯片算力的本质因素。架构设计需要在通用性和高效性间平衡,以适应不同的应用场景。图4展示了传统计算芯片的架构特点。传统计算硬件以CPU和通用图形处理器(GPGPU)为代表,基于冯·诺依曼架构完成通用计算。CPU使用了复杂的流水线和控制逻辑,并依托指令集实现硬件开发和软件编程解耦,具有高度可编程性,是最通用、最灵活的计算芯片。虽然软件生态成熟,但无法兼顾高算力,因此性能受到限制。GPGPU则采用众核架构,由众多简单的并行计算单元提供算力支持,更加注重众核的高性能,一般作为对高并行度任务的加速处理单元使用。此外,还有依托于现场可编程逻辑门阵列(Field-Programmable Gate Array, FPGA)和专用集成电路(Application Specific Integrated Circuit, ASIC)的计算芯片:ASIC是专用计算芯片,一般针对具体的应用场景和算法,通过高度定制化来高效解决特定问题,能实现较高的性能,但可编程性和通用性较差;FPGA是一类基于现场可编程逻辑阵列的计算芯片,虽然不能做到GPU级别的并行加速或ASIC级别的能效比,但是可以提供硬件编程能力。
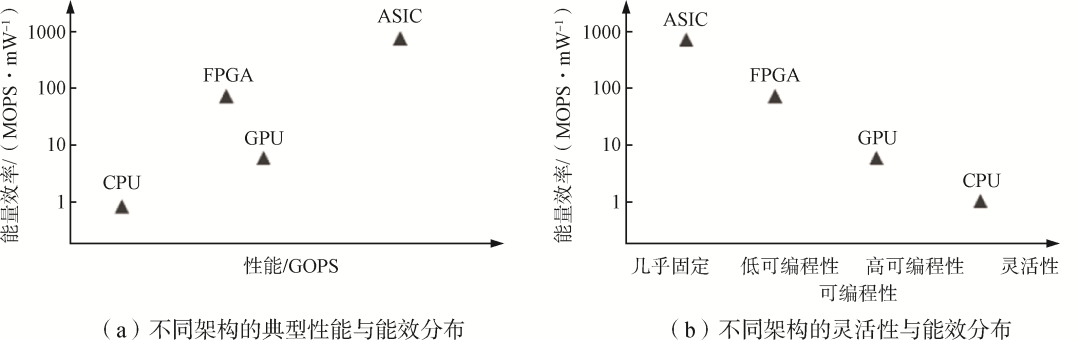
图4 传统计算芯片的架构特点
传统架构无法满足未来高算力芯片的需求,设计具有通用性、灵活性的高算力芯片需要全新的架构。为此,国内外高校和企业持续进行芯片架构的研究与开发。英伟达在GPGPU上迭代形成集成了张量核心(Tensor Core)的领域定制架构,2022年最新发布的H100 GPU基于4 nm工艺,可以提供2000 TFLOPS(万亿次浮点运算每秒)的算力。清华大学尹首一研究团队提出了多尺度可编程的粗粒度可重构架构和忆阻器存算一体架构,解决了硬件灵活性与利用率之间的固有矛盾。以下面向未来大算力应用场景探索芯片新型架构,深入分析架构设计思路与特性,总结未来高算力芯片架构的发展趋势。
3.1 领域专用架构
领域专用架构(Domain-Specific Architecture, DSA)是指为特定领域的一类任务定制化设计的芯片架构,在解决该类问题时兼顾通用性和高性能。通常,DSA架构进行以下优化:①定制化设计运算电路和支持的数据类型;②设计支持高并行度操作的硬件结构,用并行的方式接近线性地提升性能;③对存储结构进行优化,可以定制化片上静态随机存取存储器(SRAM)存储;④往往会有强大的领域特定语言(Domian-Specific Language, DSL)编程语言支持,在应用层面进一步发挥硬件性能。DSA通用性大于ASIC芯片,并且在开发成本上解决了ASIC芯片的一次性工程费用(Non-Recurring Engineering, NRE)无法平摊、编程性差等缺点,同时提供高算力和高能效。
3.1.1 粗粒度可重构架构
可重构计算(Coarse-Grained Reconfigurable Architecture, CGRA)架构是一种兼顾灵活性和高能效的高算力架构。CGRA在硬件运行时通过软件定义来配置处理元素(Processing Element, PE)的功能和互联,使得芯片制造后仍然可以定制功能,提高灵活性。CGRA设计结合空域和时域——空域上通过PE的部署分配计算资源并构建合理的互联方式,避免了深度流水线和集中通信带来的开销;时域上通过时分复用充分利用计算资源,提高了面积效率。在编程模型上CGRA支持命令式编程、并行编程、透明编程等多种编程模式,通过编译器产生配置控制/数据流图,由配置和数据同时驱动执行。
CGRA架构有效解决了ASIC的高NRE问题,在实现高算力的同时,兼顾灵活性、高精度和高能效。清华大学研究团队2022年在国际固态电路年度会议(ISSCC)上发表了面向云端深度学习任务的可重构存算一体加速器——ReCIM,解决了浮点运算中的功耗、数据类型种类、面积效率等问题;清微智能的Thinker系列可重构计算芯片产品在语音识别、图像识别等多种应用场景展现了性能和功耗优势,即将推出的云端训练芯片TX8系列,单芯片能够实现256 TFLOPS算力,其基于粗粒度数据流架构具有较强的横向扩展能力,单服务器可实现8 POPS算力。
3.1.2 基于张量核心的GPGPU架构
英伟达GPGPU是传统高算力芯片,为满足后摩尔时代更高的算力需求,在兼顾通用性和编程性的同时,英伟达引入了基于张量核心的新型GPGPU架构。2017年发布的V100 GPU搭载640个张量核心,实现了125 TFLOPS的算力;2020年发布的A100 GPU搭载432个张量核心,算力达到312 TFLOPS。高算力GPGPU芯片广泛应用于阿里、百度、腾讯等众多国内互联网公司的云服务器中。
张量核心作为核心算力单元,针对张量运算定制的高并行度计算单元和控制逻辑,定制化的数据类型和运算规模,以及关键算法的硬件化(如结构化稀疏),是其设计的核心理念。在Volta架构中,张量核心每个周期完成一个4×4×4的矩阵乘法操作(A×B+C=D)。张量核心的具体行为由指令控制,数据总线将操作数送入张量核心,在其中分组并行通过浮点乘加单元进行矩阵运算,再通过总线写回。张量核心架构自身也在不断迭代和改进,Ampere架构中,根据实际神经网络应用场景,引入对TF32和BF16数据类型以及结构化稀疏的支持。
3.1.3 数据中心处理单元
数据中心对于高算力的应用场景,数据处理的流程往往是庞大且复杂的,数据通信也逐渐成为实现高算力系统的瓶颈。基于异构多核架构的新一代智能高算力数据处理单元(Data Processing Units, DPU)应运而生。传统网络接口控制器(Network Interface Controller, NIC)负责进行数据交互,将用户传输的数据格式转换成网络设备能够识别的格式;智能网卡在此基础上融合了可编程、可加速的功能,实现部分任务卸载(如虚拟化等网络服务、远程存储等存储服务、加解密安全服务等);DPU作为下一代智能网卡,采用异构多核集成和软硬件结合的方式,搭载CPU和多种加速处理单元。英伟达发布的第三代DPU产品BlueField-3支持InfiniBand,带宽达到400 Gb/s。该架构包含16个Arm A78核心,多个高速外围接口、数据通路加速模块和AI/HPC任务加速模块。
3.2 近存计算和存算一体
传统冯·诺依曼架构中,存算分离的方式使得数据搬运成为系统性能的瓶颈,不适合大数据场景下的高算力应用。近存计算架构和存算一体架构将从减少数据访存开销出发,实现高算力、高能效芯片。
3.2.1 近存计算
近存计算通过缩短计算单元和存储单元的距离,从而缓解访存带宽瓶颈,提升数据的互连系数,有效提高受限于带宽的芯片算力。近存计算往往通过在计算芯片内部集成更多的存储单元,或者增加存储单元和计算单元的带宽,来降低数据搬移的开销。英伟达和AMD的高性能GPGPU均采用高带宽内存(High Bandwidth Memory, HBM)技术,通过堆叠高带宽内存,实现高效数据传输;新型高算力AI芯片,如Graphcore和Cerebras WSE(Wafer Scale Engine),通过片上集成更多SRAM单元实现高算力人工智能加速器;三星通过在动态随机存取存储器(DRAM)存储单元内部集成计算逻辑来实现近存计算;阿里达摩院和紫光同芯合作,通过3D混合键合的方式将计算逻辑和存储单元垂直集成在一起,实现高算力。
3.2.2 存算一体
存算一体,特别是基于忆阻器的存算一体技术,能在近存计算的基础上更进一步实现计算和存储的器件级融合,存储单元同时也是执行单元。构成存算一体的底层器件包括阻变式随机存取存储器(RRAM)、SRAM、相变随机存取存储器(PCRAM)、磁性随机存取存储器(MRAM)等多种存储器件,其中RRAM具有非易失、高存储密度、功耗低以及互补金属氧化物半导体(Complementary Metal-Oxide-Semiconductor, CMOS)工艺兼容等优势,基于RRAM构建交叉阵列,在本地完成高并行的模拟计算(图5),实现算力突破。清华大学钱鹤、吴华强团队积极布局,研发28 nm忆阻器产线,发布了首颗全系统集成的忆阻器存算一体原型芯片和软件工具栈,能效比GPGPU提高2个数量级;北京大学、中国科学院、复旦大学、浙江大学等也在器件、算法和模型等方面有所突破。国外国际商业机器公司(IBM)、惠普和英特尔等公司,以及麻省理工学院、斯坦福大学、加州大学伯克利分校等高校,从器件、架构和工具链出发,布局存算一体高算力芯片研究。
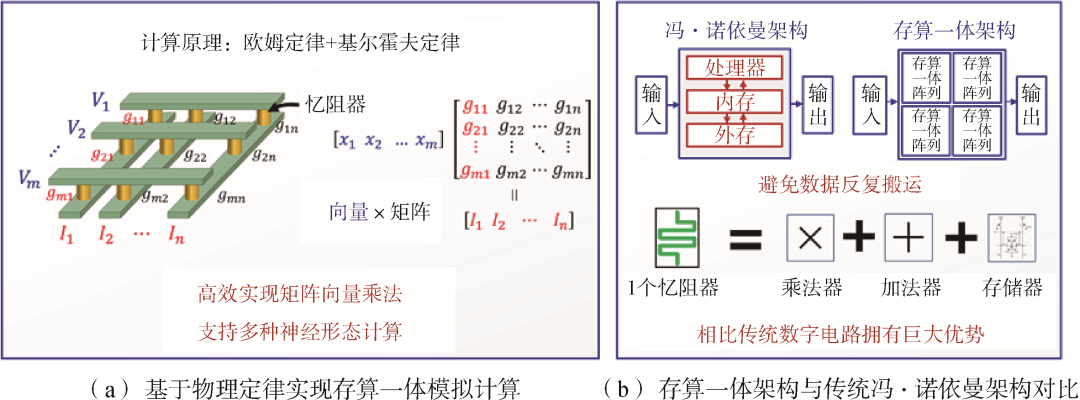
图5 基于忆阻器的存算一体技术原理
04 基于芯粒技术的
晶体管数目持续提升途径
4.1 芯粒技术及其现状
Chiplet通常译作芯粒或小芯片,美国国防部高级研究计划局(DARPA)在2017年的“通用异构集成和知识产权复用策略”项目(CHIPS)中明确提到,“旨在开发模块化芯片设计,通过集成知识产权(Intellectual Property, IP)模块,以预制芯粒的形式进行快速组装和重新配置”。芯粒通过把不同功能芯片模块化,利用新的设计、互连、封装等技术,在1颗芯片产片中使用来自不同技术、不同制程甚至不同工厂的芯片(图6)。

图6 芯粒系统芯片分解图
后摩尔时代,先进工艺流片成本不降反升,传统冯·诺依曼架构瓶颈下,计算系统算力同时受“功耗墙”“存储墙”和“I/O墙”制约(图7),集成电路发展需要新思路和新动力。芯粒技术成为学术界和产业界普遍看好的关键突破方向之一。通过将芯片设计中不同功能模块切割划分为多颗芯粒,采用各自最适合的工艺节点生产制备,而不必统一采用先进制程,实现有效降低流片开销;各颗芯粒面积较小,有利于良率提升,进一步降低成本。芯粒通过像“乐高积木”一样搭建芯片系统,复用设计缩短开发周期,促进集成电路形成全新的设计流程和产业模式。
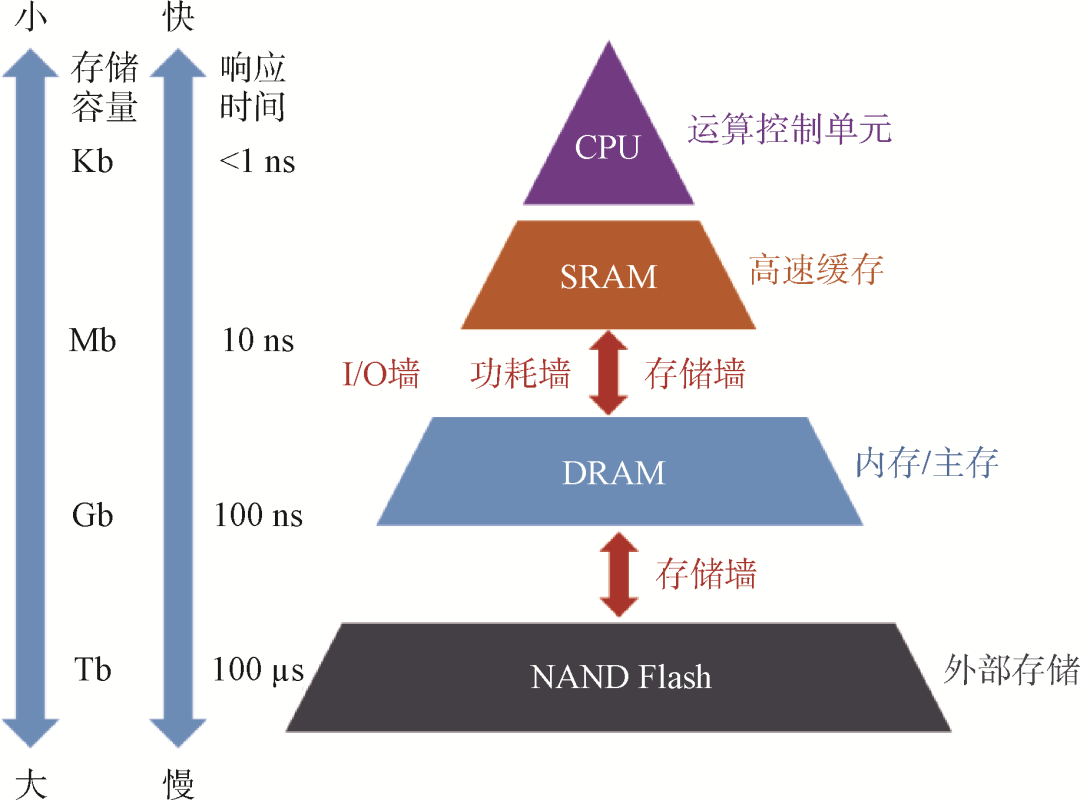
图7 冯·诺依曼架构瓶颈和“三墙”问题
芯粒技术是未来高算力芯片的关键支撑。当前,单芯片受步进式光刻机单次曝光区域限制,极限面积通常为800~900 mm2,制约了芯片总算力的提升。采用芯粒技术,将多颗芯粒通过封装技术在基板上进行2.5D/3D集成,将突破单芯片的面积限制,形成高算力芯片系统。芯粒核心是封装、互连技术以及全新的系统设计方法学,采用高密度、高速的封装和互连设计,还可以提升计算和存储、计算和计算之间的通信带宽,进一步提升芯片算力。
英特尔在2022年发布Ponte Vecchio (PVC),算力达到1468 TOPS,它通过嵌入式多芯片互连桥接(Embedded Multi-die Interconnect Bridge, EMIB)技术与Foveros 3D技术实现了分属于5个工艺节点的47颗功能芯粒的集成——包括16颗Xe-HPC架构的计算芯粒、8颗兰博缓存(Rambo Cache芯粒、8颗HBM芯粒、2颗英特尔7 nm节点的Xe基础芯粒、以及11颗EMIB互连芯粒和2颗Xe-Link I/O芯粒。同年,苹果发布M1 Ultra,基于台积电3D Fabric平台将2颗完全一致的M1 Max芯片集成在统一封装体内,并通过集成扇出型封装-局部硅互连(InFO Local Silicon Interconnect, InFO-LSI)技术在2颗M1 Max芯片间实现了2.5 TB/s的高带宽互连。
4.2 芯粒支撑技术:封装与互连
4.2.1 先进封装技术
芯粒封装技术中,按照封装结构可以分为2D、2.5D和3D。不通过额外中介层,直接在有机基板上互连芯片的形式称为2D封装,该方案成本低,但互连线的密度不高,采用高速串行互连技术一定程度上可以弥补低带宽问题。
台积电的基板上晶圆上的芯片(Chip on Wafer on Substrate, CoWoS)技术是典型的2.5D封装技术,即通过硅转接板实现多颗芯片的互连和集成(图8)。封装体内多颗芯片水平排布通过倒装互连在硅转接板上,并在硅转接板上完成高密度金属互连线,随后通过硅通孔(Through Silicon Via, TSV)将信号引出至封装基板。目前主流的2.5D先进封装技术还包括以英特尔的EMIB技术为代表的硅桥衍生技术等。2.5D封装中,硅转接板上互连线密度更高,距离更短,速度更快,但是成本也较高,且存在应力问题。
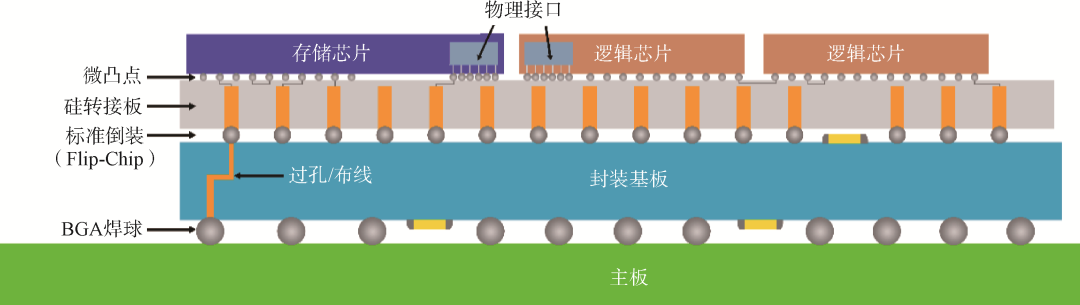
图8 2.5D封装示意图
3D封装是指2颗或多颗芯粒通过硅通孔、以面对背(Face-to-Back)的形式,或通过微凸点或混合键合技术、以面对面(Face-to-Face)的形式,在垂直方向直接堆叠,并实现芯粒间和对外界的信号连接的技术(图9)。目前主流的3D封装技术主要包括台积电的系统整合芯片(System on Integrated Chip, SoIC)技术和英特尔的Foveros 3D封装技术等。3D封装互连密度更高,距离更短,速度更快,但是成本更高且存在散热和应力等问题。
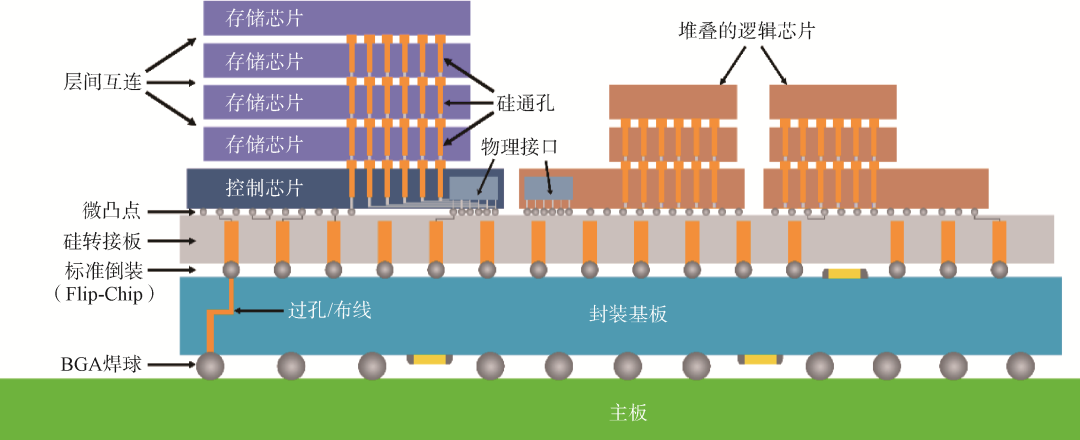
图9 3D封装示意图
基于芯粒技术实现有竞争力的高算力芯片,离不开先进封装技术的支持。在不改变软件和芯片内核的情况下,Graphcore发布的新一代智能处理单元(Intelligence Processing Unit, IPU)产品Bow通过采用SoIC-WoW 3D封装技术即可实现40%的性能提升。当前,台积电、英特尔、三星是先进封装领域的核心竞争者。
4.2.2 互连和通信
芯粒之间互连通信可分为2类:串行互连和并行互连。互连性能指标通常包括传输距离、传输能耗、传输带宽及带宽密度等。串行接口包括长/中/短距离的SerDes(LR/MR/VSR SerDes),超短距离(Extra Short Reach, XSR)SerDes和极短距离(Ultra Short Reach, USR)SerDes,其中USR Serdes的设计主要用于实现多芯粒系统内裸片到裸片的极短距离高速通信。由于通信距离短,USR可以利用高级编码、多比特传输等先进技术提供更高效的解决方案,实现更好的性能功耗比和可扩展性。
与使用XSR SerDes的串行互连相比,并行互连技术设计复杂度低,每比特能耗更低(1/6~1/10),带宽可高10倍以上,且延迟更小。目前可用于芯粒裸片互连的通用并行接口协议主要有英特尔的AIB/MDIO、OCP的BoW、台积电的LIPINCON等。并行互连技术适合应用在对访问延时要求较高的存储类接口上,如HBM系列接口即为典型的并行接口。
各种互连接口相互之间并不兼容,缺乏一个被广泛接受的接口总线标准。2022年3月,英特尔、高通、台积电等10家半导体产业上下游企业组成通用芯粒高速互连(Universal Chiplet Interconnect Express, UCIe)联盟,意欲推动芯粒互连标准规范化、共建开放生态。UCIe是一种分层协议,物理层负责电信号、时钟、链路训练、边带等。晶粒到晶粒(Die-to-Die)适配器为芯粒提供链路状态管理和参数协商,当支持多种协议时,它定义了底层的仲裁机制。
4.3 芯粒技术未来发展
基于芯粒搭建高算力计算系统,是一种全新的设计模式,需要上下游产业链共同努力形成生态。当前芯粒面临设计工具、制造材料、成本等多方面挑战。芯粒技术需要基于成本考虑选择合适的集成工艺方案,整体所获得的收益一定要大于额外代价。未来,需要上下游产业和电子设计自动化(Electronic Design Automation, EDA)厂商、代工厂等深度合作,制定互连标准来推动该技术的普及应用;同时,引入新的工具和设计、验证、测试方法。随着封装技术的发展和互连方案的统一,芯粒技术有望形成全新的集成电路商业模式,彻底变革计算领域。
05 基于晶圆级集成技术的
超高算力实现途径
根据芯片算力表达式,芯片的算力提升除了架构优化、采用先进制程外,增大芯片面积也是重要手段。根据近40年来芯片面积的变化趋势,可以看出随着高算力芯片的不断发展,面积也持续增大,当前已接近单片集成的面积极限。晶圆级集成技术即是一种新兴扩大集成面积,实现高算力芯片的途径。
基于常规芯片进行集群式算力扩展的方式已无法弥合常规芯片尺寸受限带来的天然性能鸿沟。近期出现的晶圆级(Wafer-scale)AI芯片及计算系统,通过打破光刻工艺中的光罩限制,探索超越光罩面积的计算架构,在硅晶圆上构建跨越光刻机光罩单次曝光区域的高密度金属互连线,将多个管芯组合成为硅晶圆尺寸的超大计算系统,实现晶体管与互连资源2个数量级以上的提升。
目前工业界最主要的晶圆级集成产品以Cerebras的WSE(Wafer Scale Engine)系列芯片为代表。WSE第一代芯片采用台积电16 nm工艺制程,裸片尺寸达46225 mm2,包含超过1.2万亿个晶体管,拥有高达18 GB的片上内存和9 PB/s的内存带宽。单颗芯片上集成了40万个稀疏线性代数内核,相当于数百个GPU集群的算力。WSE第二代芯片采用台积电7 nm工艺制程,得益于工艺的进步,单片集成晶体管数目达到2.6万亿个,单芯片集成了40 GB SRAM,存储带宽达到20 PB/s。
晶圆级集成涉及芯片设计、制造、封装和散热等众多技术。设计方面,将整个晶圆看作1颗芯片,必然要考虑制造良率问题,因此需要在架构和电路上进行冗余设计和容错设计。制造方面,如何实现相邻光刻区域的金属互连线的精确连接且电连通也是一个需要解决的工程问题。封装方面,由于晶圆级芯片面积远远大于普通芯片,需要开发配套专用的先进封装技术。此外,晶圆级集成的芯片功耗往往非常大,对散热提出了重大考验,需要设计专门的散热模块,例如使用金属导热加水冷等方式进行散热。
作为人工智能新时代颠覆性的算力解决方案,晶圆级芯片已经得到了美国科技公司巨头及国家实验室的重视。该领域处于起步阶段,且晶圆级芯片可以不依赖于传统先进光刻工艺,而是基于对高端光刻机不敏感的先进封装集成工艺进行实现,可以基于国内较完善的封装集成产业基础进行全自主技术攻关。
06 基于新材料和新器件的算力提升途径
除了架构改进,通过提高晶体管的工作速度提升“TOPS/晶体管数”,是实现高算力芯片的重要方法。在商用CMOS工艺节点进入深亚微米后,各种非理想效应——短沟道效应、热载流子效应等严重影响了小尺寸CMOS器件的工作状态,晶体管速度提升受限。基于新材料构建新晶体管器件,有望打破传统限制。
目前,比较有代表性的路线,一条是使用具有高迁移率的材料替代传统的单晶硅材料,以保证晶体管具有足够的驱动能力。2020年,来自美国加利福尼亚大学洛杉矶分校(UCLA)的研究人员制备了沟道长度为67 nm的石墨烯晶体管,其迁移率高于1000 cm2/Vs,大约是传统单晶硅材料的15倍,同时其截止频率可达427 GHz。另一条是使用对短沟道非理想效应具有一定抗性的材料,缓解晶体管尺寸微缩过程中由于非理想因素导致的速度下降,例如采用MoS2等金属硫化物作为沟道材料。基于石墨烯、MoS2等沟道材料的晶体管在学界已有长足发展,但仍然需要继续研发、改进大规模生产工艺,例如均一化生长工艺、钝化工艺等,使其可以尽快落地。
另外,兼具高迁移率和对非理想效应抗性的碳纳米管晶体管(Carbon Nanotube Transistor, CNT)也备受关注。北京大学彭练矛团队制备了迁移率为1600 cm2/Vs的CNT晶体管;斯坦福大学与台积电合作制备了沟道长度为15 nm的CNT晶体管,亚阈值摆幅接近60 mV/dec,表现出对短沟道效应的强抗性。
07 结束语
算力在国家数字化转型和经济发展中起到越来越重要的作用,作为算力载体和依托,必须重视高算力芯片的发展。通过分解芯片算力构成,指出提升互连带宽、单位晶体管算力、晶体管密度和芯片面积均可提升算力水平。在后摩尔时代,进一步分析了未来提升芯片算力的关键技术,探讨了实现大于1000 TOPS以及更高算力芯片的发展路径——应继续投入先进制程实现尺寸微缩、布局芯粒技术和晶圆级集成、发力存算一体等新型计算架构等,这些技术相对比较成熟,容易实现;探究超越CMOS技术的新器件、新材料,也有望另辟蹊径,推动高算力芯片的发展(图10)。除此之外,还有一些蓬勃发展的技术,试图通过探索新型计算范式实现算力飞跃,如类脑计算、光计算和量子计算等,这些技术通过模仿人脑、设计光学结构、实现量子逻辑等手段形成全新的计算系统。这类新兴的计算范式尚处于起步阶段,与高算力芯片、系统的关系尚不明确,随着技术的不断成熟,有望在未来成为现有技术的重要补充。

图10 高算力芯片突破路径
另外,现阶段大国博弈加剧全球产业链、供应链重构,同时中国集成电路先进工艺的开发受到制约,单纯依靠先进制程等技术的单点突破成本高、周期长。因此,在补全产业链短板、攻坚关键技术的同时,还应充分利用现有产业链和研究基础,从系统层次布局多途径协同方案,采用国内成熟、领先的技术和计算架构,摸索更加高效可行的技术路径。为实现高算力芯片不断突破,需要扎根于中国现有产业基础,探寻底层计算架构的变革性方法,探索“架构+集成+系统”协同一体的自主可控创新路径。采用成熟制程和先进集成,结合CGRA和存算一体等国内领先的新型架构,在芯粒技术基础上实现晶圆级的高算力芯片是一条可行的突破路径,该路径能够利用现有优势技术,在更低的成本投入下,更快地提升芯片算力。
审核编辑 :李倩
-
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析2024-09-02 3574
-
《AI芯片:科技探索与AGI愿景》—— 勾勒计算未来的战略罗盘2025-09-17 2059
-
浅谈LED驱动芯片行业的处境和未来发展2014-09-18 6051
-
新兴的半导体技术发展趋势2019-07-24 2936
-
芯片未来技术 移动小设备无线投影大屏幕2008-08-23 775
-
李彦宏:AI将成未来技术发展方向2016-12-26 834
-
AGM推出基于ASIC的MCU算力加速芯片,将是车载计算平台未来发展趋势2018-09-03 8391
-
华为Atlas 900 AI集群获GSMA GLOMO未来技术大奖2020-02-27 2172
-
配电网未来技术发展趋势展望2021-01-15 4122
-
存算一体大算力AI芯片的发展与未来前景2022-10-13 3340
-
高算力芯片:未来科技的加速器?2024-02-27 1621
-
华为发布数据通信未来技术趋势报告2024-11-18 1473
全部0条评论

快来发表一下你的评论吧 !
