

全球首个面向遥感任务设计的亿级视觉Transformer大模型
描述
大规模视觉基础模型在基于自然图像的视觉任务中取得了重大进展。得益于良好的可扩展性和表征能力,基于视觉Transformer (Vision Transformer, ViT) 的大规模视觉基础模型吸引了研究社区的广泛关注,并在多种视觉感知任务中广泛应用。然而,在遥感图像感知领域,大规模视觉模型的潜力尚未得到充分的探索。为此,我们首次提出面向遥感任务设计的大规模视觉基础模型[1],针对具有1亿参数的一般结构的ViT (Plain ViT),设计符合遥感图像特点的新型注意力机制,并据此研究大模型在遥感图像理解任务上的性能,包括图像分类、目标检测、语义分割等。
简单来说,为了更好地应对遥感图像所具有的大尺寸特性以及图像中的目标物体的朝向任意性,我们提出了一种新的旋转可变尺寸窗口的注意力(Rotated Varied-Size Window Attention, RVSA)来代替Transformer中的原始完全注意力(Vanilla Full Self-Attention),它可以从生成的不同窗口中提取丰富的上下文信息来学习更好的目标表征,并显著降低计算成本和内存占用。
实验表明,在检测任务上,我们提出的模型优于目前为止所有最先进的模型,其在DOTA-V1.0数据集上取得了81.24% mAP的最高精度。在下游分类和分割任务上,所提出的模型与现有先进方法相比性能具有很好的竞争力。进一步的分析实验表明该模型在计算复杂度、迁移学习的样本效率、可解释性等方面具有明显优势。
本工作由京东探索研究院、武汉大学以及悉尼大学联合完成,已被IEEE TGRS接收。

01
研究背景
在遥感图像感知领域中,卷积神经网络(Convolutional Neural Network, CNN)是提取多尺度视觉特征最常用的模型。然而,卷积操作的感受野受限,这使得CNN很难关注长距离像素并提取全局上下文信息。为了解决这一问题,研究者提出使用自注意力(Self-Attention, SA)机制,通过计算图像中任意像素(特征)之间的相似性来灵活地建模特征之间的长距依赖关系。这一技术在计算机视觉领域的诸多任务上取得了良好的表现。其中,视觉Transformer模型采用了多头自注意力(Multi-Head Self-Attention, MHSA)的设计,在多个投影子空间中同时计算自注意力,使得提取的上下文信息更加多样化,从而进一步提高了特征的表征能力。
最早提出的视觉Transformer模型ViT [2]的结构采用了非层次化的一般结构设计,即在特征嵌入层之后重复堆叠Transformer编码器模块,其中每个模块输出的空间尺度、特征维度均相同。为了更好地使ViT适应下游任务,研究人员借用了CNN中的分层设计思想,并相应地设计了层次化视觉Transformer[3, 4]。这些模型通常使用大规模数据集并以有监督的方式进行预训练,然后再在下游任务的训练集上进行微调。最近,探索研究院通过比较不同的预训练方法和模型,将层次化视觉Transformer应用于遥感图像上并对其性能进行了详细的实证研究[5],验证了层次化视觉Transformer相比于CNN的优势以及使用大规模遥感场景标注数据集进行预训练的有效性。然而,是否一定要采用层次化结构的模型才能在遥感图像上获得较好性能呢?在本项研究中,我们首次尝试采用非层次化结构的模型并验证了其在一系列遥感图像感知任务上的优势和潜力。
具体来说,我们首先使用具有约一亿参数的Plain ViT模型和研究院最近提出的更先进的ViTAE 模型[6],并采用掩码图像建模算法MAE [7]在大规模遥感数据集MillionAID [8]上对其进行预训练,从而得到很好的初始化参数。
在预训练完成后,我们通过在下游任务相关数据集上进行微调,从而完成相应任务。由于下游任务的图像分辨率较大,为了降低视觉Transformer在下游任务上的计算成本和内存占用,研究者通常采用窗口注意力(Window-based Attention)机制来代替原始的完全注意力机制。然而,窗口注意力采用的固定窗口大小和位置会限制模型提取上下文信息的范围以及跨窗信息交互,从而影响模型的表征能力。
为此,探索研究院提出了一种名为可变大小窗口的注意力机制(Varied-Size Window Attention, VSA) [9]。它通过学习窗口的缩放和偏移因子,以使窗口的大小、形状和位置适应不同的图像内容,从而提高特征的表征能力,在多个视觉感知任务中获得了更好的性能。不同于自然图像中目标主要呈现上下方向的特点,遥感图像中的目标具有任意朝向,如图1所示。为了处理这种差异,我们进一步引入了一种可学习的旋转框机制,从而获得具有不同角度、大小、形状和位置的窗口,实现了提取更丰富的上下文新型的目标。

图1:两种常见类别(桥梁和飞机)的自然图像(a)与遥感图像(b)的区别
基于ViT和ViTAE模型,我们将上述自注意力方法应用于三种遥感感知任务(场景分类、语义分割和目标检测),并开展了详细的实验评估,取得了很好的效果。我们希望这项研究能够填补遥感大模型领域的空白,并为遥感社区发展更大规模的Plain ViT模型提供有益的参考。
02
方法介绍
2.1 MillionAID
MillionAID [8]是一个具有遥感场景图像和标签的大型数据集。它包含1,000,848个RGB格式的非重叠遥感场景,非常适合用于深度神经网络模型预训练。该数据集包含51类,每类有大约2,000-45,000个图像。该数据集中的图片是从包含各种传感器和不同分辨率数据的谷歌地球上收集得到的。图像尺寸分布广泛,覆盖了110*110到31,672*31,672个像素的多种情况。应该注意的是,尽管该数据集同时包含图像和标签,但在本项研究中,我们只采用图像数据进行无监督预训练。
2.2 MAE
MAE [7]是一种生成式自监督预训练方法,采用了非对称的网络结构提取非掩码区域的图像特征并预测掩码区域的图像内容,具有很高的计算效率。它首先将图像分割成不重叠的图像块,然后通过特征嵌入层将每个图像块映射为视觉Token。按照一定掩码比率,一些Token被删除并被作为要预测的掩码区域。剩余的Token被馈送到Transformer编码器网络进行特征提取。然后,解码器部分利用编码器提取到的可见区域Token的特征和可学习的掩码区域的Token来恢复掩码区域图像内容。在训练过程中,通过最小化像素空间或特征空间中掩码区域的预测和图像真值之间的差异来训练模型。我们遵循原始MAE文献中的设置并在归一化像素空间中计算训练损失。
2.3 MAE无监督预训练
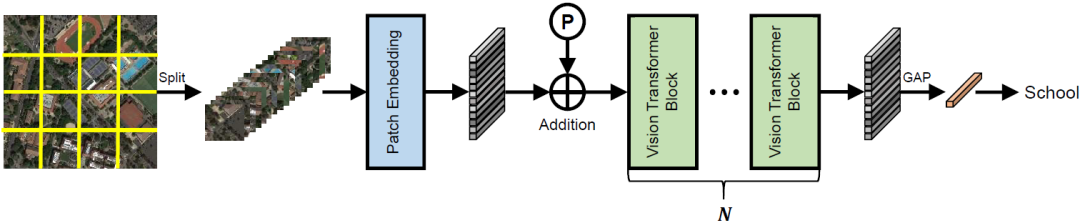
图2:预训练阶段的视觉Transformer的网络结构
图2展示了所采用的Plain ViT模型的基本结构。具体来说,我们采用两种骨干网络ViT和ViTAE进行预训练。前者由具有完全自注意力的Plain ViT编码器组成。这种简单的结构能够使其无缝地采用MAE方法进行预训练。相比之下,ViTAE引入了卷积结构从而让网络获取局部性归纳偏置,即采用与MHSA并列的平行卷积分支PCM。在预训练时,因为MAE中的随机掩蔽策略破坏了空间关系,我们将PCM的卷积和从3*3改为1*1,以避免其学习到错误的空间特征。然后,在对特定的下游任务进行微调时,我们将卷积核重新填充为3*3大小。假设第i卷积层的预训练中的权重为 (忽略通道维),填充内核如下
其中 是MAE预训练学习到的值, 初始化为0。此外,我们在ViTAE模型中采用一种浅层PCM的设计,其依次为卷积层、批归一化层、SiLU层和卷积层,以节省内存占用。图3显示了用于MAE预训练的ViT和ViTAE网络中的基本模块。
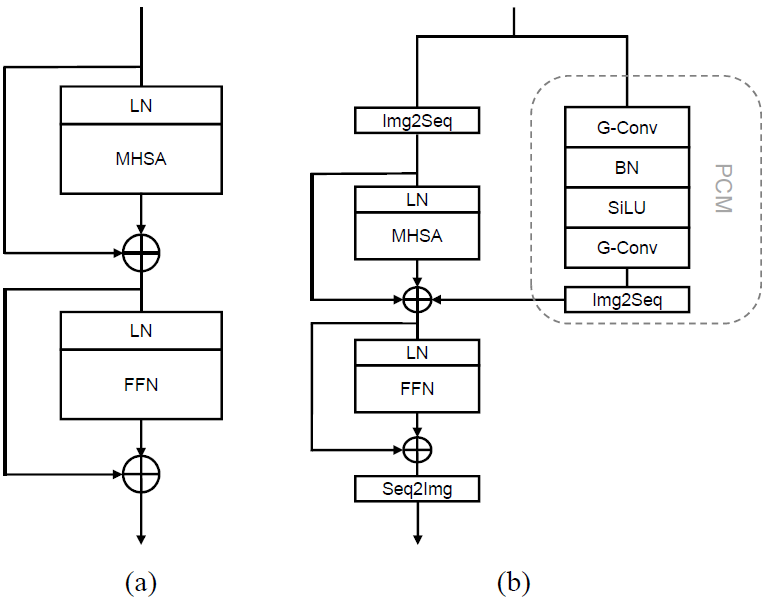
图3:MAE编码器中采用的块结构
(a) ViT的基本模块,(b) 改进后的ViTAE Normal Cell
我们使用“Base”版本的ViT和ViTAE,它们都具有约一亿参数。这两种网络被分别表示为“ViT-B”和“ViTAE-B”。其详细结构见表1,其中“Patch Size”表示特征嵌入层的图像块尺寸,“Embedding Dim”表示Token的维度,“Head”表示MHSA中SA的个数,“Group”表示PCM中分组卷积的组数,“Ratio”指FFN的特征维膨胀率, “Depth”表示两种网络中堆积模块的数量。
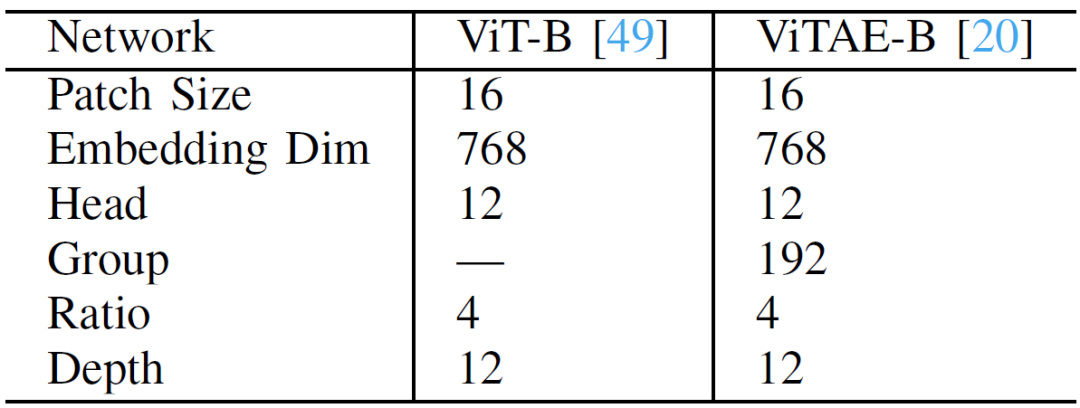
表1 :ViT-B和ViTAE-B的超参数设置
2.4 采用RVSA进行微调
与自然图像相比,遥感图像通常尺寸更大。由于完全自注意力具有和图片分辨率呈平方关系的计算复杂度,直接将采用完全自注意力的预训练模型应用于下游任务时会显著增加训练成本。为此,我们在微调阶段采用窗口自注意力替换原始的完全自注意力,这将计算代价降低到与图像大小线性相关的复杂度。因为这种替换只改变了参与自注意力计算的Token范围,而不引入新的参数,因此可以在预训练-微调范式中直接转换。然而,原始的窗口自注意力在固定水平和垂直方向上采用固定大小的窗口,这与遥感图像中目标的任意朝向特点不符,导致使用固定方向固定大小的窗口可能并非最优。为此,我们设计了RVSA。
具体来说,我们引入了一系列变换参数来学习可变方向、大小和位置的窗口,包括相对参考窗口的偏移量、尺度缩放因子以及旋转角度。具体地,给定输入特征 ,首先将其划分为几个不重叠的参考窗口,即每个窗口的特征为 (其中 表示窗口大小),总共得到 个窗口。然后,我们通过三个线性层去获得查询特征 ,初始的键特征 和值特征 。我们用 去预测目标窗口在水平和竖直方向上的偏移 和缩放 ,以及旋转角度
GAP是全局平均池化操作的缩写。以窗口的角点为例
上式中, 表示初始窗口左上角和右下角的坐标, 表示窗口的中心坐标, 分别是角点与中心在水平和垂直方向上的距离。我们用估计到的参数来对窗口进行变换,
是变换后窗口的角点坐标。然后,从变换后的窗口中采样键特征 ,从而和查询特征一起计算自注意力。采样的键特征和值特征中Token的数量与查询特征中Token的数量相同,从而保证RVSA与原始窗口自注意力机制具有相同的计算复杂度。
这里, 是一个窗口中一个SA的输出特征, , 是SA的个数。然后,沿着通道维度连接来自不同SA的特征,并且沿着空间维度连接来自不同窗口的特征,以恢复输入特征的形状,最终获得RVSA的输出特征 ,图4展示了RVSA的示意图。
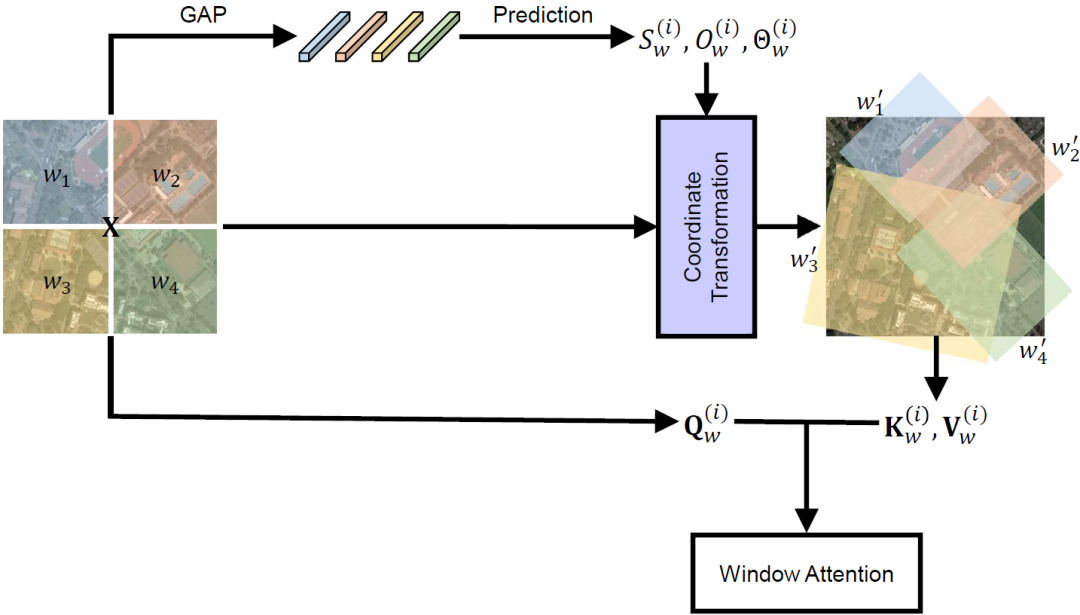
图4:第 个SA上所提出RVSA的完整流程
RVSA的变体:我们还提出了RVSA的一种变体,此时键特征和值特征可以来自不同窗口,即我们分别预测键特征和值特征窗口的偏移,缩放和旋转因子
这个更灵活的架构被称为 RVSA 。
为了使MAE预训练模型适应遥感下游任务,我们将原始Plain ViT中的MHSA模块替换为RVSA。按照ViTDet [10]中的策略,我们在每1/4个深度层采用完全自注意力。由于ViT-B 和 ViTAE-B有12 层,因此我们在第3、6、9和12层使用完全自注意力,并在所有其他层采用RVSA。修改后的网络分别表示为“ViT-B + RVSA”和“ViTAE-B + RVSA”。图5展示了 ViT-B + RVSA和ViTAE-B + RVSA中替换注意力后模块的结构。我们也对比了采用普通窗口自注意力、VSA和RVSA 的变体。它们被分别表示为“ViT-B-Win”、“ViT-B + VSA”、 “ViT-B + RVSA ”、“ViTAE-B-Win”、“ViTAE-B + VSA”和“ViTAE-B + RVSA ”。
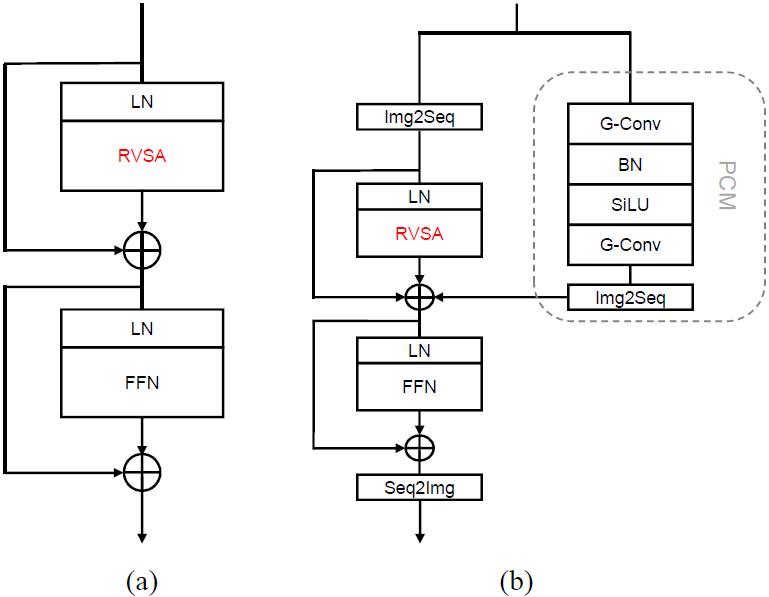
图5:修改注意力后模块的结构(a)ViT-B+RVSA。(b)ViTAE-B+RVSA
最后,我们在图6中展示了上述预训练和微调过程的完整框架,以便于读者理解所提出的方法。
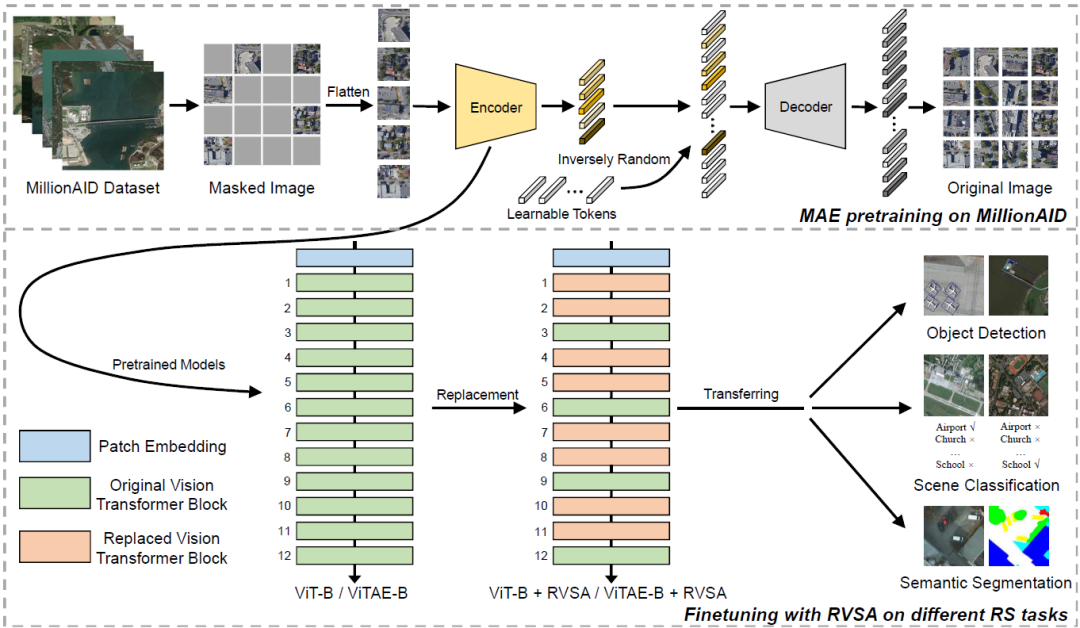
图6:预训练和微调的流程(以RVSA为例)
03
实验结果
我们将所提出的模型在包括场景分类、对象检测和语义分割等多个遥感任务上进行实验,并且还进一步展示了其在计算复杂度、迁移学习的数据效率以及可解释性等方面的优势。
3.1 目标检测
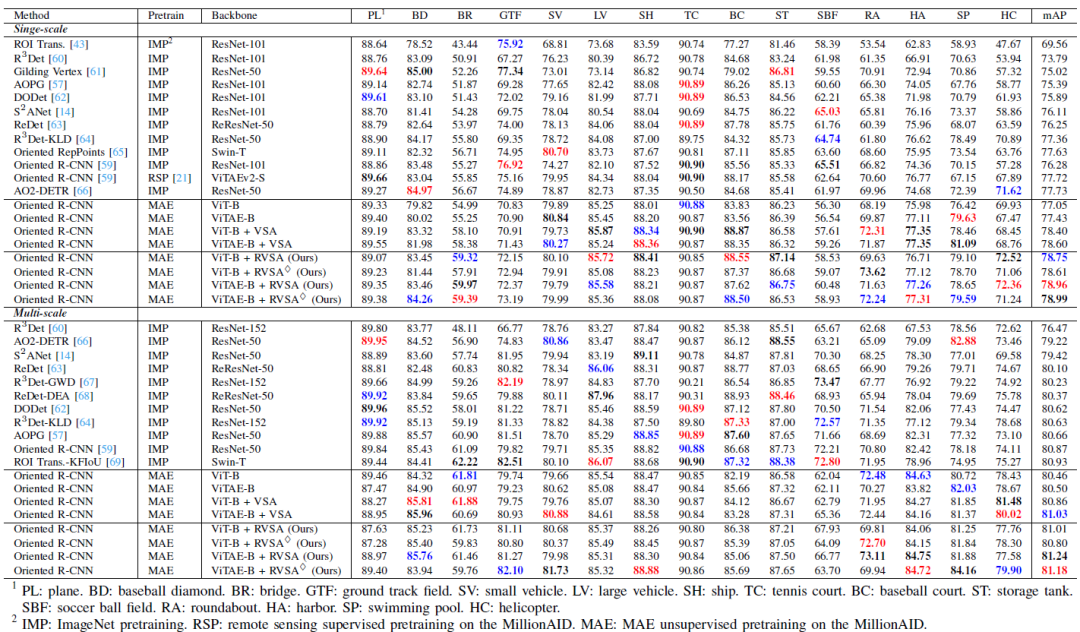
表2:不同先进方法在DOTA-V1.0数据集上的精度。

表3:不同先进方法在DIOR-R数据集上的精度
我们将所提出的方法与迄今为止最先进的一些方法进行了比较,结果列于表2和表3中。每列精度前三分别用粗体,红色和蓝色标记。在DOTA-V1.0数据集上,我们分别列出了单尺度训练和多尺度训练的结果。在单尺度训练设置上,我们的模型在五个类中表现最好,超过了以前的最佳方法约1%的mAP。在竞争更激烈的多尺度训练中,我们的模型在总共四个类别中获得第一。特别的,我们的方法在一些具有挑战性的类别(如环岛和港口)中的检测结果显著优于之前的方法,从而在DOTA-V1.0上取得了新的精度记录,即81.24%的mAP。在更具挑战性的DIOR-R数据集上,我们的模型在11个类别中表现最好。与现有方法相比,其检测性能提高了10%以上,并以5% mAP的优势显著超过第二名。值得注意的是,我们成功地证明了建立强大的Plain ViT基线的可能性:事实上,ViT-B+VSA和ViTAE-B+VSA在DOTA-V.1.0和DIOR-R数据集上已经超过了之前的方法并取得了很好的检测性能。当进一步引入旋转机制后,它们的性能仍然能被进一步提高。
3.2 场景分类
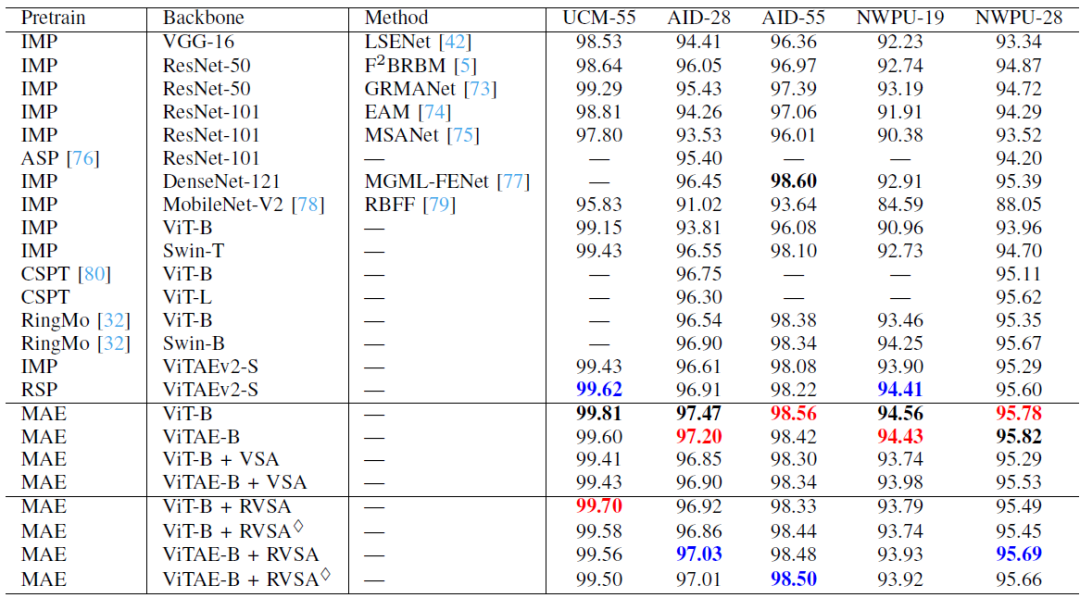
表4:不同方法在场景分类任务上的精度
表4展示了不同模型在场景分类任务上的结果。在此任务中,MAE 预训练的ViT-B在大多数设置上获得最佳效果,因为所有Token都参加了MHSA计算 ,这种方式提取的全局上下信息有利于场景识别。我们的 RVSA 模型在三个设置(包括 UCM-55、AID-28 和 NWPU-28)中优于以前的方法。而在其他设置中,我们的模型可以与探索研究院先前提出的当前最先进的模型:即在 MillionAID上采用有监督预训练的层次化模型RSP-ViTAEv2-S [5]相媲美。与VSA 方法相比,我们所提出的模型主要在NWPU-19设置中表现较差。这是因为相比VSA,RVSA 需要相对更多的训练数据来学习最佳窗口配置,而NWPU-19 的训练数据规模相对较小。当采用较大规模数据集,如NWPU-28 的设置时,我们的模型超越了ViT-B + VSA,ViTAE-B + VSA和RSP-ViTAEv2-S等先进模型。
3.3 语义分割
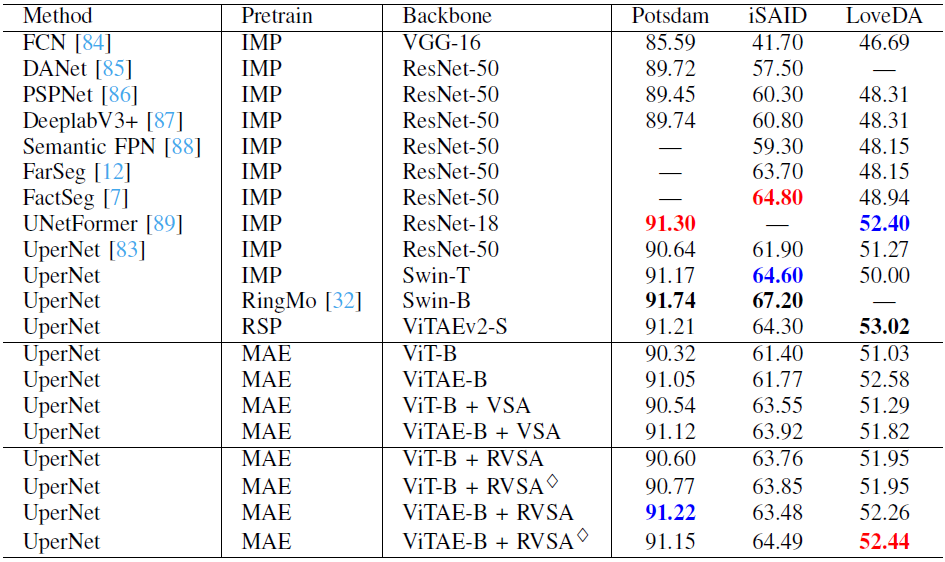
表5:不同方法在语义分割任务上的精度
表5显示了不同分割方法的结果。我们的模型获得了与当前最佳方法相当的性能。尽管如此, 我们也必须承认其在分割任务上的性能不如在检测和场景分类任务上令人印象深刻。我们认为这有两个原因。首先,我们使用经典但简单的分割框架 UperNet,它不能有效地将高级语义信息传播到高分辨率特征图上。另一个原因是我们采用的视觉Transformer 骨干网络直接通过 的图像块来嵌入编码网络特征,并且特征图分辨率始终保持输入大小的1/16,这可能会丢失细节,不利于像素级语义分割任务。尽管如此,我们提出的RVSA仍然可以提升Plain ViT的性能并达到与层次化模型RSP-ViTAEv2-S相当的性能,且优于ViT-B、ViTAE-B 和 VSA等模型,证明了其从可变窗口中学习有用上下文信息的强大能力。
3.4 计算复杂度
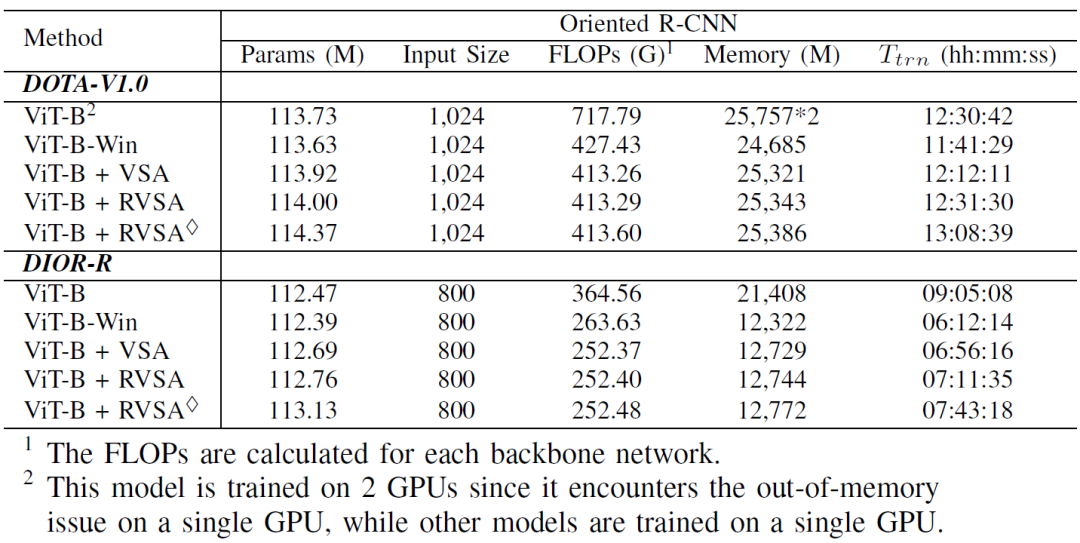
表6:不同模型的复杂度和训练代价
我们以ViT为例,在DIOR-R检测数据集上比较了不同模型的复杂度和训练代价。表6列出了包括参数数量 (Params)、计算量 (FLOPs)、GPU 内存在内的多种评估指标,所有模型参数量均超过1亿。由于完全自注意力的二次复杂度,ViT-B具有最大的内存占用,最大的FLOPs以及最长的训练时间,因此需要使用两个GPU才能在相当的时间完成训练。ViT-B-Win通过采用窗口自注意力缓解了这些问题。需要注意的是,ViT-B + VSA的FLOP比ViT-B-Win小,这是因为填充(padding)操作是在生成查询特征、键特征和值特征之后实现的。由于可学习的缩放和偏移因子,ViT-B + VSA比ViT-B-Win略多一些内存占用。与ViT-B+VSA相比,ViT-B+RVSA具有相似的复杂度,而ViT-B+RVSA 略微增加了参数和计算开销,因为它对键特征和值特征分别预测窗口。与ViT-B相比,所提出的ViT-B + RVSA和ViT-B + RVSA 可以节省大约一半的内存并加快训练速度,同时还具有更好的性能。
3.5 迁移学习的训练数据效率
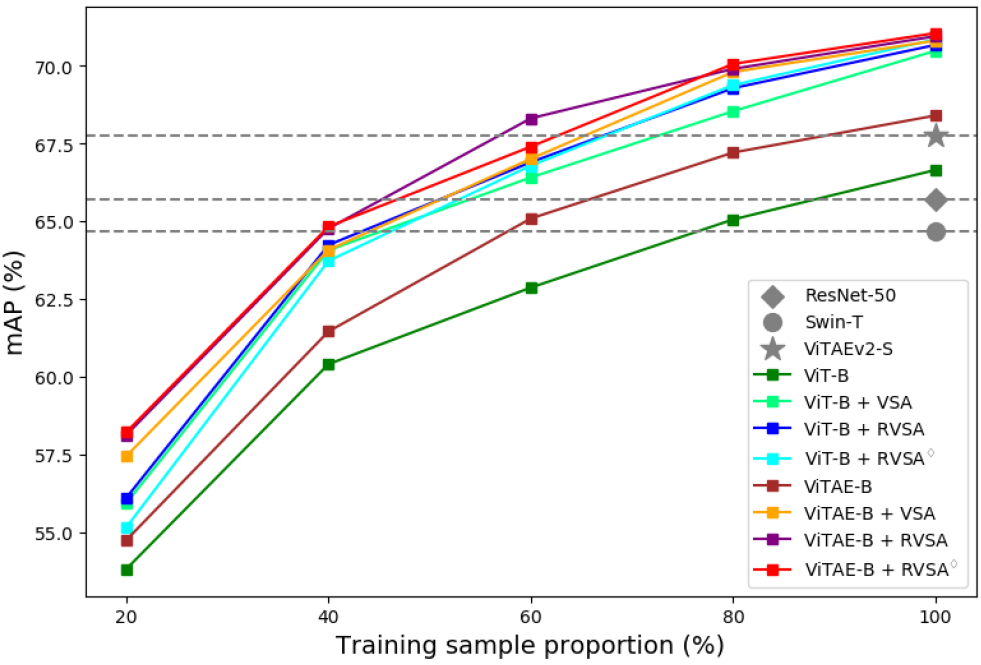
图7:不同的模型在DIOR-R数据集上采用不同比例的训练集进行训练的结果
迁移学习的训练数据效率是衡量基础模型的一项重要能力。在这里,我们在DIOR-R 数据集上,使用不同数量的训练数据进行实验。我们通过分别随机选择原始训练集的 20%、40%、60% 和 80% 的图像来获得一系列较小的训练集。然后,我们分别在这些数据集上微调预训练模型,并在原始测试集上对其进行评估。为了便于比较,我们也训练了一些小规模模型,例如 RSP-ResNet-50、RSP-Swin-T和RSP-ViTAEv2-S,它们采用训练集中所有的数据进行训练。图7显示了相关结果。可以看出,无论训练样本的数量如何,所提出的模型都优于相应的ViT-B和ViTAE-B基线模型。由于我们考虑了遥感图像中任意方向的对象,所提出的具有可学习旋转机制的RVSA在大多数情况下都可以超越VSA。此外,它们仅使用40%的训练样本就达到了与Swin-T相当的性能,当使用60%的训练样本时,它们的性能优于ResNet-50和Swin-T。当采用80%的训练样本时,它们超过了强大的骨干网络ViTAEv2-S。上述结果表明我们的模型在迁移学习时具有良好的训练数据效率。
3.6 窗口可视化
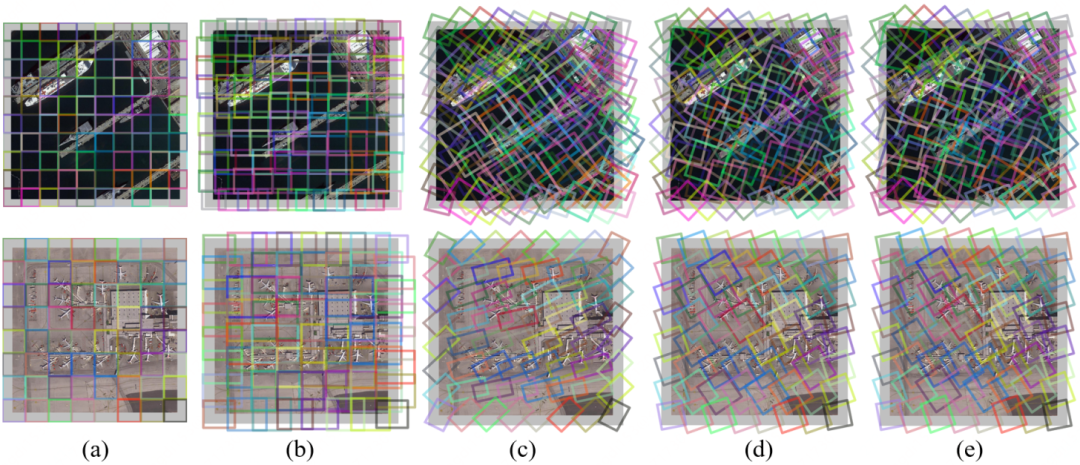
图8:不同注意力方法生成窗口的可视化。(a) 窗口自注意力。(b) VSA。(c) RVSA。(d)和(e)分别是RVSA 为键特征和值特征生成的窗口
以ViT为例,图8 可视化了不同的网络在倒数第二个模块中的注意力层生成的窗口。可以看出,VSA生成的窗口可以缩放和移动以匹配不同的对象。然而,VSA 无法有效处理遥感图像中任意方向的目标,例如图8第二行中倾斜的飞机。相比之下,我们的RVSA引入了旋转因子来解决这个问题,获得更多样化的窗口并有利于提取更丰富的上下文信息。同样值得注意的是,每个头可以产生不同方向和位置的窗口,并来覆盖特定角度和位置的飞机。因此,通过使用多头注意力的方式,图片中不同方向的飞机可以被不同头的窗口覆盖,这意味着RVSA可以更好地处理任意方向的物体。与RVSA相比, RVSA 进一步提高了生成窗口的灵活性。通过将 (d) 和 (e) 与 (c) 进行比较,我们可以发现键特征和值特征的窗口形状略有变化,这在拥有大量可用的训练数据和处理具有挑战性的样本时比较有用。通过将学习到的窗口进行可视化,我们提供了一种分析所提出的模型的工作机制的手段,可以增强其学习过程和学习结果的可解释性。
04
总结
本工作提出了全球首个面向遥感任务设计的亿级视觉Transformer大模型。具体来说,我们首先基于具有代表性的无监督掩码图像建模方法MAE对网络进行预训练来研究Plain ViT作为基础模型的潜力。我们提出了一种新颖的旋转可变大小窗口注意力方法来提高Plain ViT的性能。它可以生成具有不同角度、大小、形状和位置的窗口,以适应遥感图像中任意方向、任意大小的目标,并能够从生成的窗口中提取丰富的上下文信息,从而学习到更好的物体表征。我们在典型的遥感任务上对所提出的模型进行实验,结果证明了Plain ViT作为遥感基础模型方面的优越性和有效性。我们希望这项研究可以为社区提供有价值的见解,并激发未来对开发遥感基础模型的探索,尤其是基于Plain ViT的研究。
审核编辑 :李倩
- 相关推荐
- 热点推荐
- 视觉
- 数据集
- Transformer
- 大模型
-
阿里平头哥发布首个 RISC-V AI 软硬全栈平台2023-08-26 853
-
预计2022年全球遥感服务市场规模将达216.2亿美元2020-06-17 8174
-
如何让Transformer在多种模态下处理不同领域的广泛应用?2021-03-08 3584
-
Transformer模型的多模态学习应用2021-03-25 12259
-
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果2021-12-28 2846
-
轻量级视觉模型设计的新启发2022-07-28 2176
-
CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据2023-06-18 1220
-
transformer模型详解:Transformer 模型的压缩方法2023-07-17 3964
-
基于Transformer模型的压缩方法2024-02-22 1740
-
蚂蚁推出20亿参数多模态遥感模型SkySense2024-02-28 1800
-
蚂蚁集团推出20亿参数多模态遥感基础模型SkySense2024-03-04 1953
-
使用PyTorch搭建Transformer模型2024-07-02 3779
-
Transformer语言模型简介与实现过程2024-07-10 4340
-
如何使用MATLAB构建Transformer模型2025-02-06 6980
-
VLM(视觉语言模型)详细解析2025-03-17 10420
全部0条评论

快来发表一下你的评论吧 !
