

OpenVINO模型优化实测:PC/NB当AI辨识引擎没问题!
电子说
描述
之前我们谈到在Intel OpenVINO架构下,当需要进行AI运算时利用Intel GPU加速一样可获得不错的效能,并且使用YOLO v3进行测试。
这次我们将会自制一个CNN分类器,并透过OpenVINO的模型转换程序转换成IR模型,并进行模型效能与正确率分析。依据Intel官方网站的说明,OpenVINO可以针对不同模型进行优化,目前支持包括Tensorflow、Keras、Caffe、ONNX、PyTorch、mxnet等多种模型。
也就是说,当使用者透过其他框架训练完成的模型文件,例如Keras的model.h5檔,或者TensorFlow的model.pb档,只要经过转换就可以在OpenVINO中以最高效能来执行。
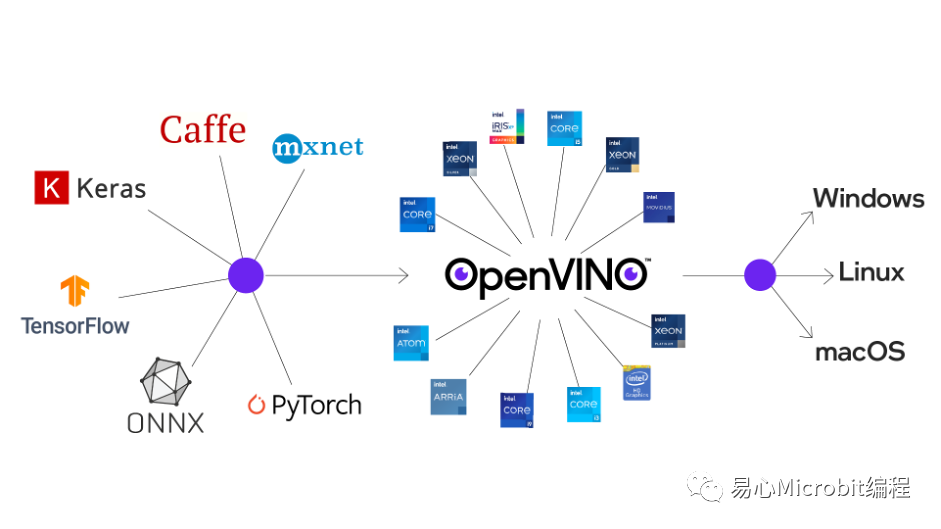
不过读者可能会比较在意的就是透过OpenVINO加速后,效能是能提升多少、正确率会不会发生变化?还有就是若我已经有一个训练好的Model,我要如何转换为OpenVINO可以读取的模型呢?
本文将分为两个部份来说明,第一个部份就是如何进行模型转换,第二部份则来评测转换前后的执行效能差异,除了模型比较之外,读者一定会想了解Intel OpenVINO GPU与NVIDIA CUDA的差异,这部份也在本文中进行比较,我相信会让读者大开眼界。
OpenVINO模型转换
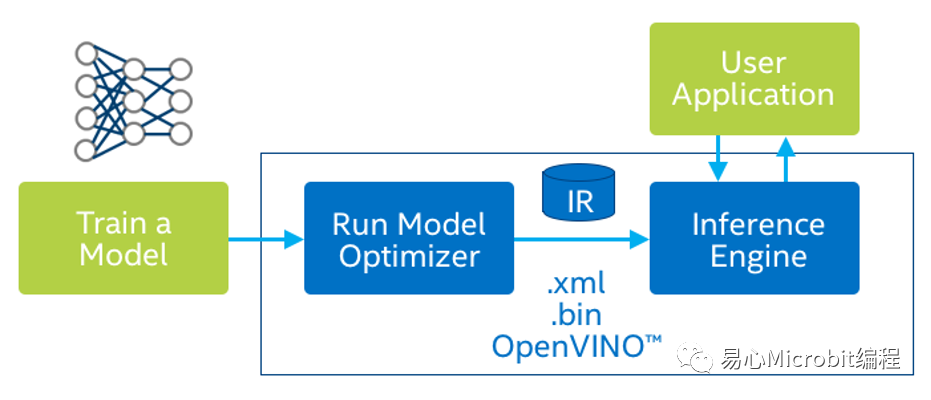
以目前官方文件所述,OpenVINO架构执行效能最佳的为IR(Intermediate Representations) 格式模型,所谓的IR模型是「中间表达层」,IR模型包含一个bin及xml,bin包含实际权重的网络权重weight及误差bais数据,而xml则是记载网络结构。
后续当OpenVINO要加载模型时,只要读取这两个档案即可,虽然这样转换须多经过一道手续,但是却可大幅提高执行效能,在此我们介绍如何转换模型。
本次就以较常用的个案「玩猜拳」为例,利用卷积类神经CNN模型制作一个图形分类器,可以对「剪、石、布」以及「无」(代表使用者还没有出拳)的四种图形进行判断。模型采用[224x224x3]的图片格式,本文以Tensorflow为例演练转换过程,其他模型转换方式类似,读者可以参考本例作法进行转换测试。

无(N)

布(P)

石(P)

剪(S)
1. TensorFlow模型转换
一般来说以TensorFlow训练模型的话,那么我们可能会得到两种格式的档案,一种为使用Keras的h5档,另外一种则是TensorFlow的pb檔,h5档案可以透过python转换成pb档,因此本文仅介绍pb文件的模型转换。
另外为了后续测试能有一致的标准,本文的模型使用Google的Teachable Machine(简称TM)进行训练,这样可以让读者在与自己的计算机进行效能比较时,能有较公平的比较基准,若读者有自行训练的类神经模型,一样可以参考下面的方式进行转换。
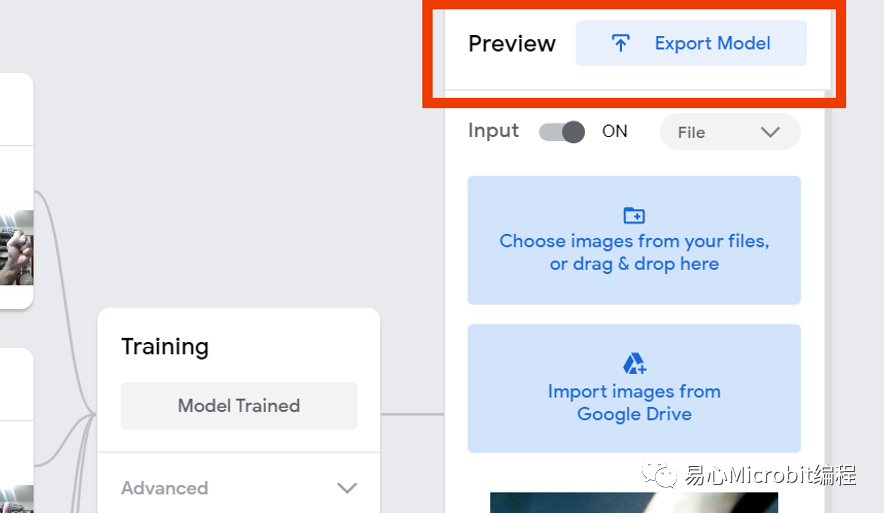
关于TM的训练过程,请自行参考其他教程,本文仅针对最后的模型下载过程进行说明。也就是说,当TM已经训练好模型之后,就可以点选右上角的「Export Model」导出模型。
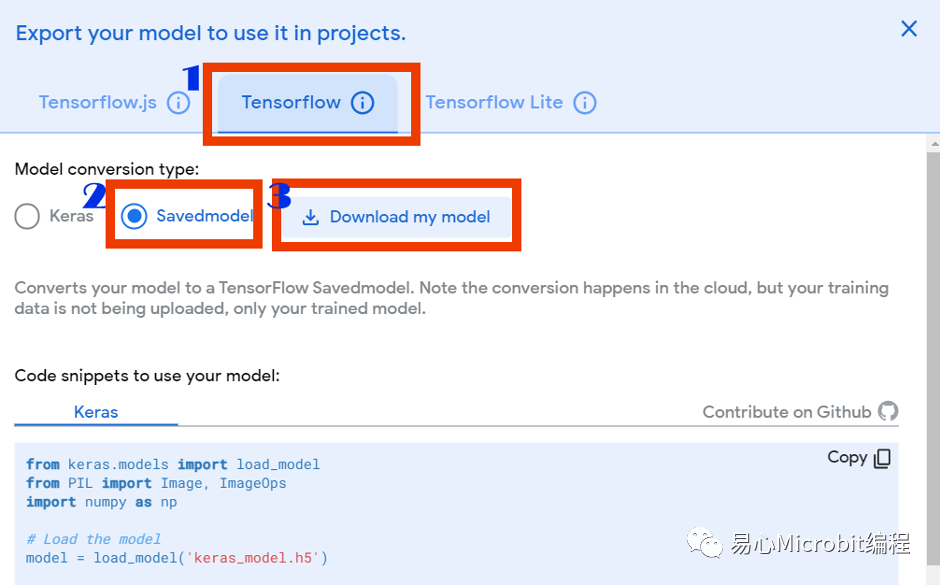
开启导出模型窗口后,点选:1.Tensorflow,然后点选单元格式为2.Savemodel,最后选3.Download my model。
此时下载的档案内容包含一个文本文件「labels.txt」及文件夹「model.savedmodel」,而在文件夹内则包含「saved_model.pb」及文件夹「assets」及「variables」,接下来我们就可以将此档案转换为IR格式。
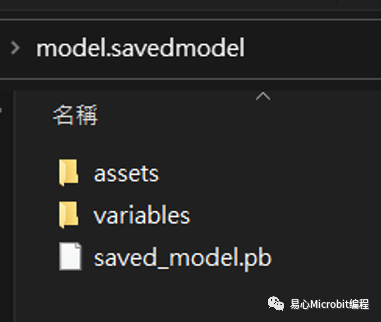
下载的tensorflow pb档案。
下一步我们则可以利用OpenVINO内建的「model_optimizer」模块进行优化及模型转换,一般是在「/opt/intel/openvino_安装版本/deployment_tools/model_optimizer/」文件夹内,我们将会选用的转换程序为mo_tf.py,而语法如下
python3 mo_tf.py --saved_model_dir <<模型档案存放文件夹路径>>--output_dir <
举例来说,假设我的pb模型文件存放在「Tensorflow/SaveModel」文件夹内,而要输出到「IR」文件夹,而第一层架构为[1,224,224,3](此代表输入1张图,长宽为224×224,有RGB三色),选用FP32(默认值)为数据格式,此时语法为
python3 mo_tf.py --saved_model_dirTensorflow/SaveModel --output_dir IR --input_shape [1,224,224,3] --data_typeFP32
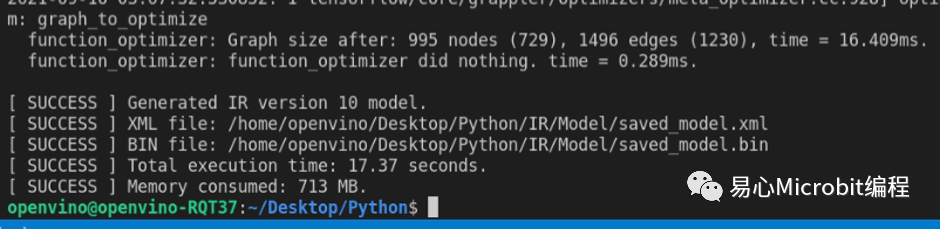
转换完成会出现的讯息。
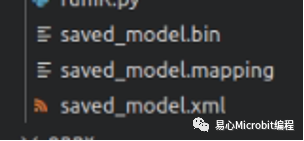
转换完成的IR模型档案。
当转换完成的讯息出现后,就可以在IR文件夹中看到三个档案「saved_model.bin」、「saved_model.mapping」、「saved_model.xml」,这样就代表转换完成了。
若您原本是使用Keras的h5 model档案的话那该怎么办,先转成pb文件结构,再转换成IR即可,以下为h5转换pb的python语法。
import tensorflow as tf
model =tf.keras.models.load_model('saved_model.h5') #h5的档案路径
tf.saved_model.save(model,'modelSavePath')#'modelSavePath'为pb模型档案输出路径
将h5转换成pb档案后,就可以依照前述方式将再将pb转换成IR档案。除了TensorFlow之外,其他模型的转换方式,可以参考OpenVINO官方网页说明。
https://docs.openvinotoolkit.org/latest/openvino_docs_MO_DG_prepare_model_Config_Model_Optimizer.html
模型转换效率比较
当使用OpenVINO进行模型转换时,并非单纯转换而已,事实上OpenVINO在转换过程会对模型进行优化(算是偷吃步吗?哈哈),优化部份包括以下两种:
1.修剪:剪除训练过程中的网络架构,保留推理过程需要的网络,例如说剪除DropOut网络层就是这种一个例子。
2.融合:有些时候多步操作可以融合成一步,模型优化器检测到这种就会进行必要的融合。
如果要比较优化后的类神经网络差异,我们可以透过在线模型可视化工具,开启两个不同模型档案来查看前后的变化。下图为利用netron分别开启原始pb模型及转换后的IR模型的网络架构图,读者可以发现经过转换后的模型与原始TensorFlow模型有很大的差别,IR模型会将多个网络进行剪除及融合,减少网络层数提升运算效能。
https://netron.app/
以下图为例,左侧为IR模型,右侧为TF模型,两者比较后可以发现,原先使用的Dropout层已经在IR中被删除。

模型转后前后比较图左图为IR模型,右图为原始TensorFlow模型(由于模型都相当大,此处仅呈现差异的一小部份)
在OpenVINO转换工作结束后,就会告知优化前后所造成的差异,以本例而言,原本995个节点、1496个路径的类神经网络就被优化为729个节点、1230个路径,因此能提升运算效率。

解模型转换过程之后,接下来就是测试OpenVINO在执行上是否有效能上的优势。以下会有二个测试,测试项目包括效能及正确率,以了解OpenVINO是否能具有实用性,也就是说在获得效能的同时,是否能保有相同的正确性,让读者对于后续是否采购支持OpenVINO机器有比较的依据:
•在RQP-T37上测试IR模型及TensorFlow Keras h5模型效能比较
•OpenVINO iGPU及Colab的 GPU效能比较
1.在RQP-T37上测试IR模型及Tensorflow上的差异
本测试是同一台机器(RQP-T37)及环境(Ubuntu 20.04.2 LTS)之下进行,模型则采用Google TeachableMachine所制作的手势分类器(猜拳游戏:剪刀石头布),辨识对象为800张224x224x3的手势照片,模型采用FP32进行分析辨识总时间及正确率。
为了避免单次测试可能造成的误差,测试取100次的平均及标准偏差,并绘制盒型图(Box plot),本测试并不使用其他测试常采用的fps(Frame per second),而仅计算的是辨识(inference)总时间,不计算档案读取、数据转换过程所耗费的时间。因为本测试主要要了解模型转换后的差异,避免受到其他因素的影响因此不使用fps。
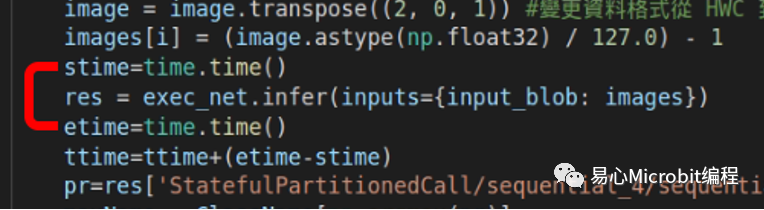
(a) IR模型代码段,显示仅计算推论时间。(评估标准为Inference总时间)
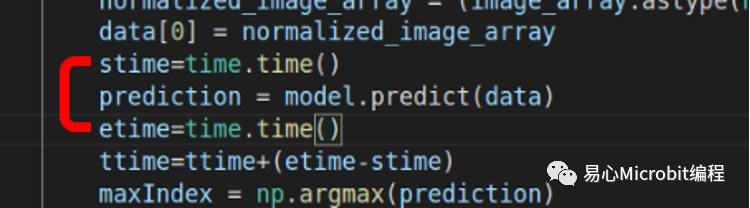
(b) TensorFlow模型程序片段,显示仅计算推论时间。(评估标准为Inference总时间)
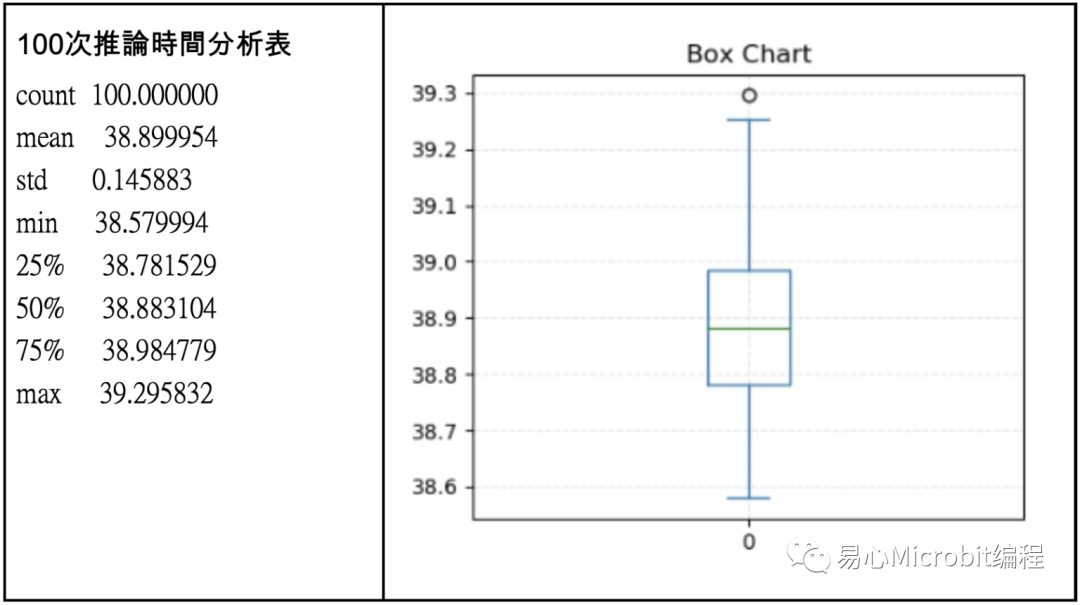
在完成100次执行之后,我们先看原始TensorFlow模型的执行状况如下表,做完800张照片的手势推论,平均时间为38.941,换算辨识一张的时间约0.04秒,而标准偏差0.103,大致换算fps的上限约25,这样的结果算是中规中矩。
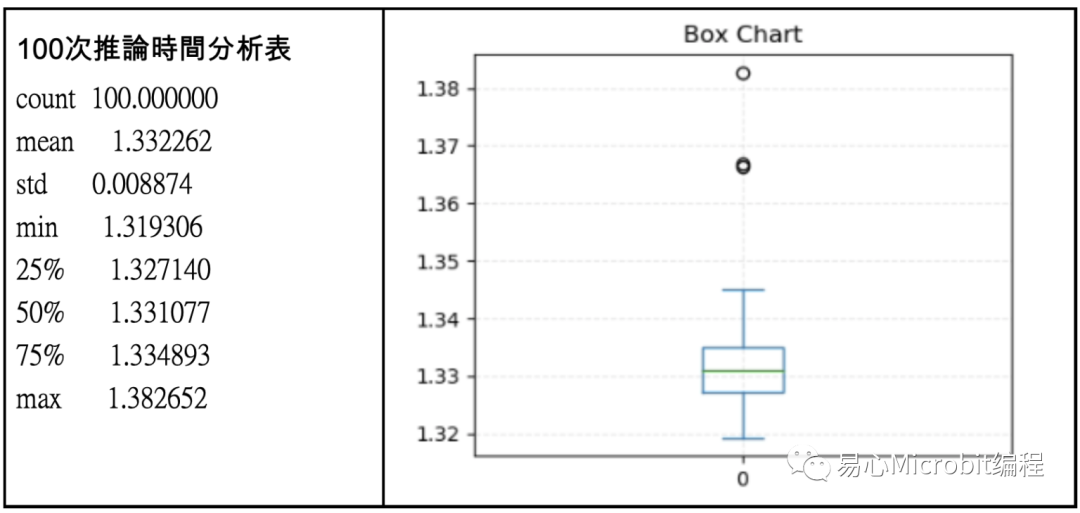
另一方面IR模型进行推论结果则呈现在下图,可以发现效能非常高,分析800张照片平均只要1.332秒,也就是一张224×224的照片仅需要0.00166秒,非常不可思议,换算fps上限约为602,若看标准偏差也只有0.008,代表耗费时间也相当稳定,并无太大起伏。
相对于原始的Tensorflow pb模型来说,效能大约提升了30倍,相当令人惊艳。
虽然效能提升如此之多,读者应该会觉得OpenVINO的Inference引擎可能会在「效能」与「正确性」之间进行trade off,是否在大幅提升效能后,却丧失了最重要的推论正确性?此时观察两次测试时的混淆矩阵可以发现,在TensorFlow模型时800次只有3次将布看成剪刀,正确率为797/800大约0.996。
而在IR模型时,800次辨识有9次将石头看成剪刀,所以其正确率为793/800=0.991,事实上两者相差无几,不过有趣的是两个模型所辨识错误的项目不太一样,值得后续再深入讨论。
笔者在此必须强调,OpenVINO架构的效能提升如此之多,个人认为主要在于模型优化(model_optimizer)的过程,虽然Intel CPU及GPU虽然有所帮助,但不可能把效能提升到30倍之多。
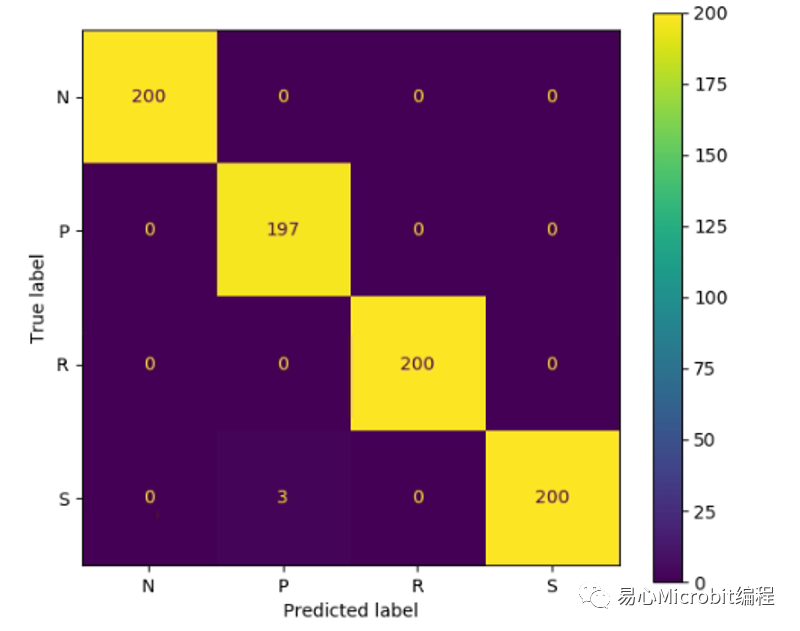
TensorFlow模型辨识混淆矩阵
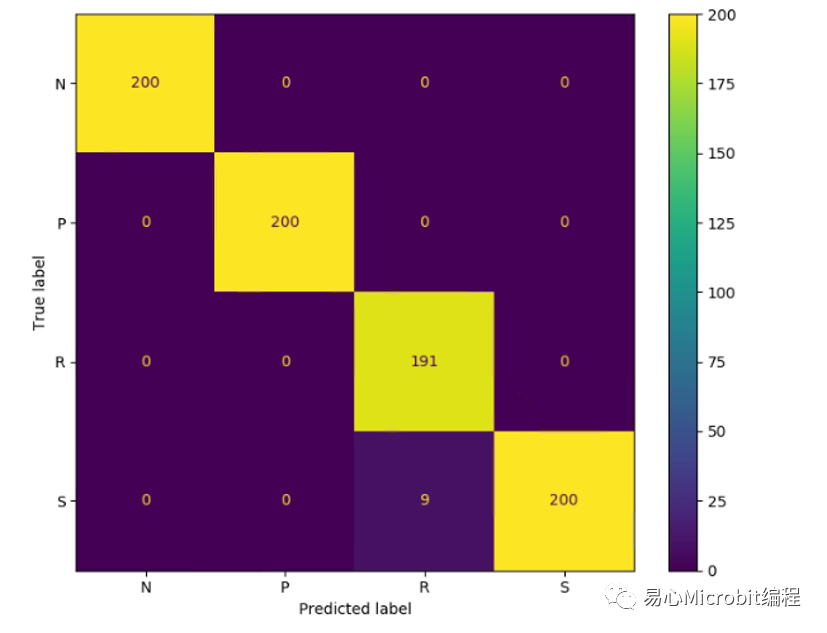
IR模型辨识混淆矩阵
测试小结:
•经过优化的IR比TensorFlow模型效能上大幅提升,差异约30倍
•经过优化的IR与TensorFlow模型正确率几乎相当
2.比较OpenVINO iGPU及Colab的 GPU
本测试则是使用Colab上的GPU进行加速运算,Google Colab可以说是近几年来最受欢迎的程序开发平台了,尤其是提供免费的GPU加速,可以让使用者在AI运算上获得相当好的效能。因此本次也针对Colab平台进行测试,测试之前查询Colab所提供的GPU规格为Tesla T4。
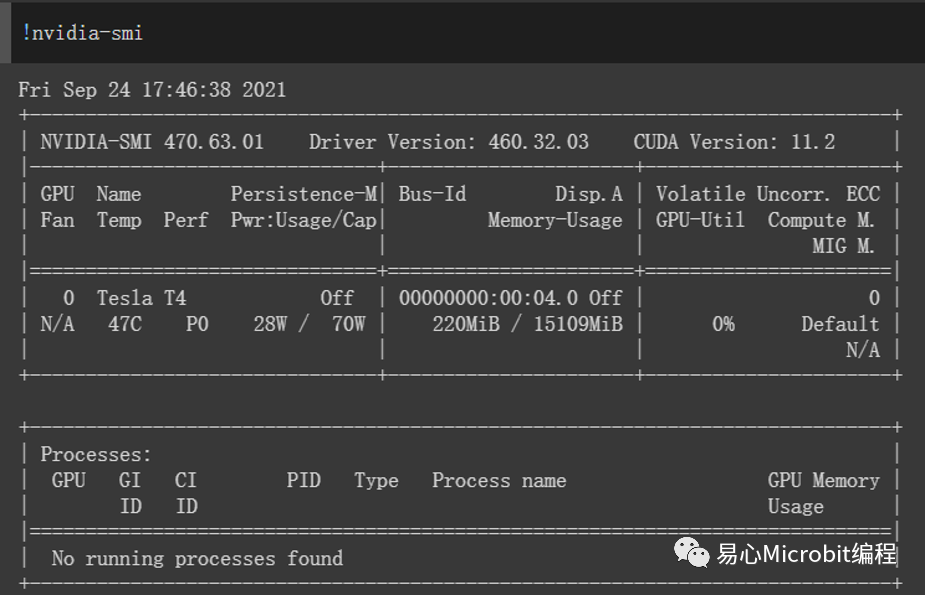
而根据NVIDIA的规格表,T4具有2,560个CUDA核心,FP32的算力为8.1 TFLOPS。

NVIDIA T4规格
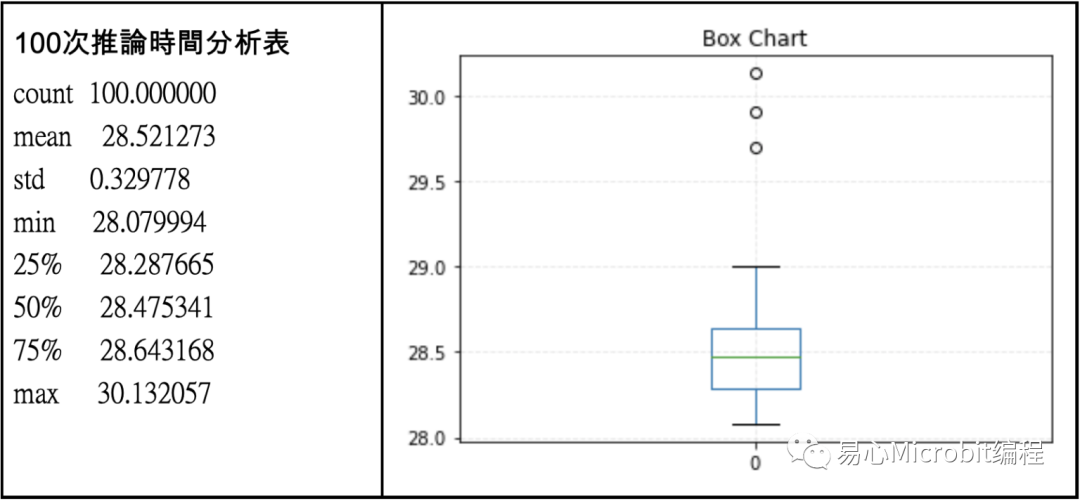
与前次测试相同,推论对象为800张224x224x3的图片,采用原始的TensorFlow pb模型,且确认有开启GPU加速。
经过100次分析后,获得上表可以得知,Colab的指令周期比本次测试用的计算机采用的Intel CPU时效能高,平均一次约28.52秒,相当于分类1张照片只花0.035秒,换算fps上限28.05,这个效能符合Colab 所提供的GPU规格。
读者可能会想到在Colab上的照片读取效能比Local端差多了,这样评估不公平,这里要注意的是,我们测试都仅加总推论时间,并没有计算档案读取的时间。此次测试比较后,OpenVINO效能还是明显较好。不过一样的,笔者认为效能提升是来自于OpenVINO的模型优化。
测试小结:
•同样在pb模型下,Colab采用的GPU加速后,效能大于Intel CPU
•IR模型在OpenVINO模型优化及加速后,效能超过NVIDIA CUDA
结论
本次文章主要让读者了解OpenVINO架构的效能与正确性的比较,另外也说明自制模型的转换过程。测试时虽硬件上有明显差距,以及并未使用TensorRT做模型优化,但本测试还是有一定的代表性,也就是说当读者拥有一台Intel计算机时,透过安装OpenVINO ToolKit来进行模型优化,一样可以获得性能相当好的AI辨识引擎,不一定要购买超高等级的显示适配器才能进行AI项目开发。
毕竟一般读者购买计算机一定有CPU,却不一定会购买独立GPU显示适配器,或者像是无法加装显示适配器的笔记本电脑,以往没有独立显卡的计算机以CPU进行AI推论时都会花费大量时间,系统无法实时反应,因此缺乏实用性。而本次测试则是证明在OpenVINO架构下,就可以透过模型优化程序及Intel GPU加速,进而在几乎不影响正确率的结果下得到非常好的效能,这个效能甚至超越 NVIDIA架构。
不过笔者必须提醒读者,目前OpenVINO只有提供Inferencing,尚不提供Training的功能,所以读者必须先透过其他方式进行训练获得模型后,才可以在OpenVINO中进行实地推论。虽然如此,无论是采用Intel的计算机,还是标榜低价的文书计算机,都可以快速进行AI运算,可以说是实做AI系统非常好的工具。
-
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?2025-07-11 445
-
OpenVINO™ Toolkit中如何保持模型稀疏性?2025-03-06 353
-
为什么Caffe模型可以直接与OpenVINO™工具套件推断引擎API一起使用,而无法转换为中间表示 (IR)?2025-03-05 437
-
C#集成OpenVINO™:简化AI模型部署2025-02-17 3139
-
C#中使用OpenVINO™:轻松集成AI模型!2025-02-07 2187
-
如何快速下载OpenVINO Notebooks中的AI大模型2023-12-12 2690
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 2986
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-30 3261
-
自训练Pytorch模型使用OpenVINO™优化并部署在AI爱克斯开发板2023-05-26 1918
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2850
-
优化OpenVINO模型效能:参数设定影响实测2022-11-04 2727
全部0条评论

快来发表一下你的评论吧 !
