

CPU Cache伪共享问题
描述
先看下这两段代码:
代码段1:
const int row = 10240;
const int col = 10240;
int matrix[row][col];
int TestRow() {
//按行遍历
int sum_row = 0;
for (int r = 0; r < row; r++) {
for (int c = 0; c < col; c++) {
sum_row += matrix[r][c];
}
}
return sum_row;
}
代码段2:
int TestCol() {
//按列遍历
int sum_col = 0;
for (int c = 0; c < col; c++) {
for (int r = 0; r < row; r++) {
sum_col += matrix[r][c];
}
}
return sum_col;
}
两段代码的目的相同,都是为了计算矩阵中所有元素的总和。
但有些区别:一个是按行遍历元素做计算,一个是按列遍历元素做计算。
它俩的运行速度有什么区别吗?
如图:
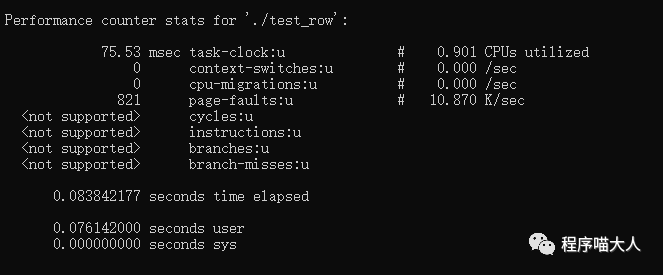
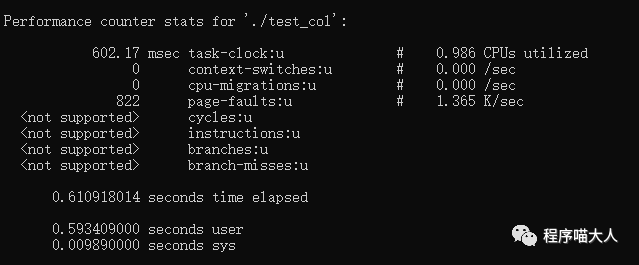
图中可以看到,行遍历的代码速度比列遍历的代码速度快很多。
为什么按行遍历的代码比按列遍历的代码速度快?这里就是CPU Cache在起作用。
什么是CPU Cache?
可以先看下这个存储器相关的金字塔图:
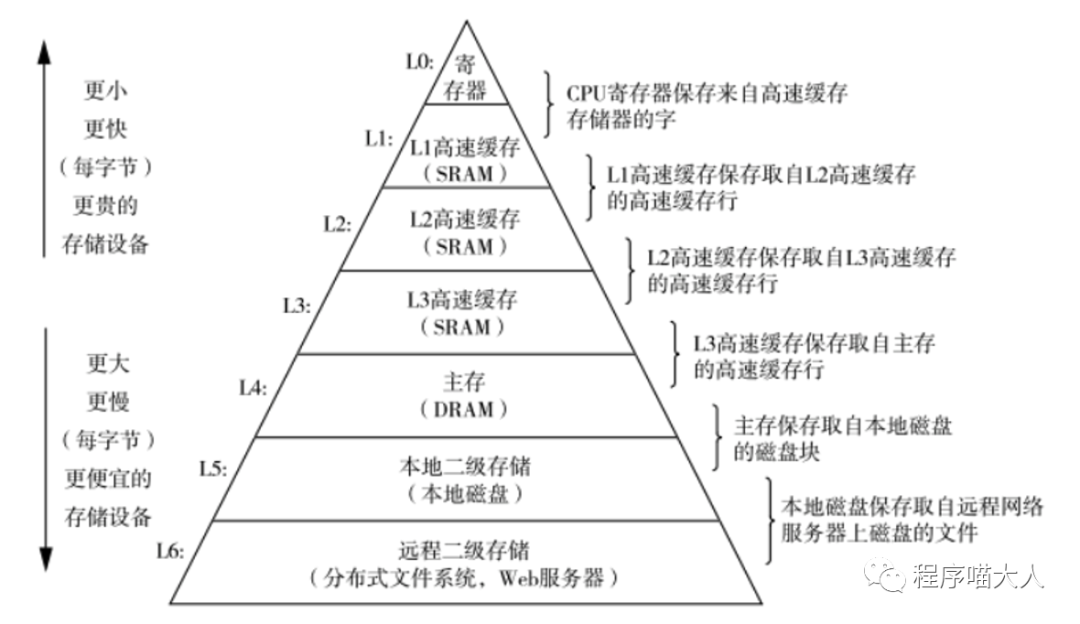
从下到上,空间虽然越来越小,但是处理速度越来越快,相应的,设备价格也越来越贵。
图中的寄存器和主存估计大家都知道,那中间的L1 、L2、L3是什么?它们起到了什么作用?
它们就是CPU 的Cache,如下图:
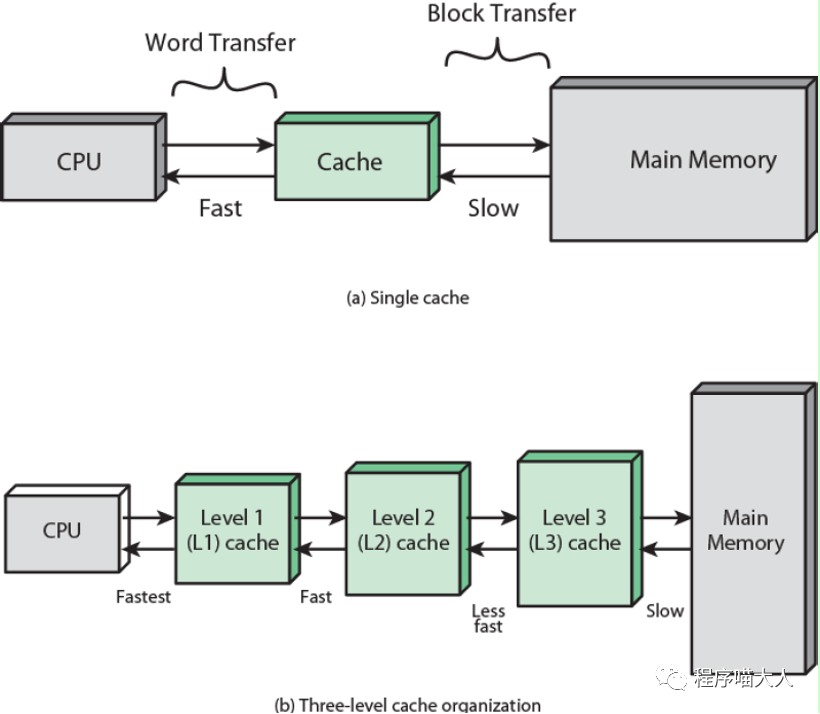
可以理解为CPU Cache就是CPU与主存之间的桥梁。
当CPU想要访问主存中的元素时,会先查看Cache中是否存在,如果存在(称为Cache Hit),直接从Cache中获取,如果不存在(称为Cache Miss),才会从主存中获取。Cache的处理速度比主存快得多。
所以,如果每次访问数据时,都能直接从Cache中获取,整个程序的性能肯定会更高。
那,如何提高CPU Cache的命中率?
这里我不多介绍,感兴趣的直接移步到我这篇文章:https://mp.weixin.qq.com/s/iKWQZxn6XYKU9KnlBRynfg
但CPU Cache这里还有个小问题,看下这两段代码:
代码段1:
struct Point {
std::atomic<int> x;
// char a[128];
std::atomic<int> y;
};
void Test() {
Point point;
std::thread t1(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->x += 1;
}
},
&point);
std::thread t2(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->y += 1;
}
},
&point);
t1.join();
t2.join();
}
代码段2:
struct Point {
std::atomic<int> x;
char a[128];
std::atomic<int> y;
};
void Test() {
Point point;
std::thread t1(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->x += 1;
}
},
&point);
std::thread t2(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->y += 1;
}
},
&point);
t1.join();
t2.join();
}
两端代码的核心逻辑都是对Point结构体中的x和y不停+1。只有一点区别就是在中间塞了128字节的数组。
它们的执行速度却相差很大。

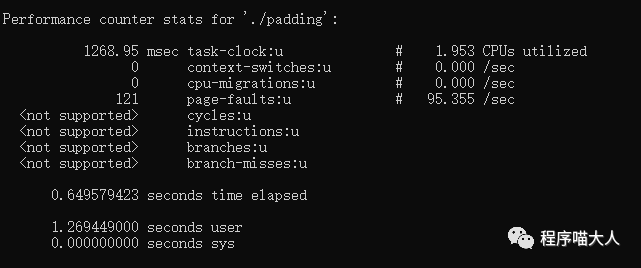
带128的比不带128的代码,执行速度快很多。
为什么?
看过我上面文章的同学应该就知道,每个CPU都有自己的L1和L2 Cache,而Cache line的大小一般是64字节,如果x和y之间没有128字节的填充,它俩就会在同一个Cache line上。
代码中开了两个线程,两个线程大概率会运行在不同的CPU上,每个CPU有自己的Cache。
当CPU1操作x时,会把y装载到Cache中,其他CPU对应的的Cache line失效。
然后CPU2加载y,会触发Cache Miss,它后面又把x装载到了自己的Cache中,其他CPU对应的Cache line失效。
然后CPU1操作x时,又触发Cache Miss。
它俩就会是大体这个流程:
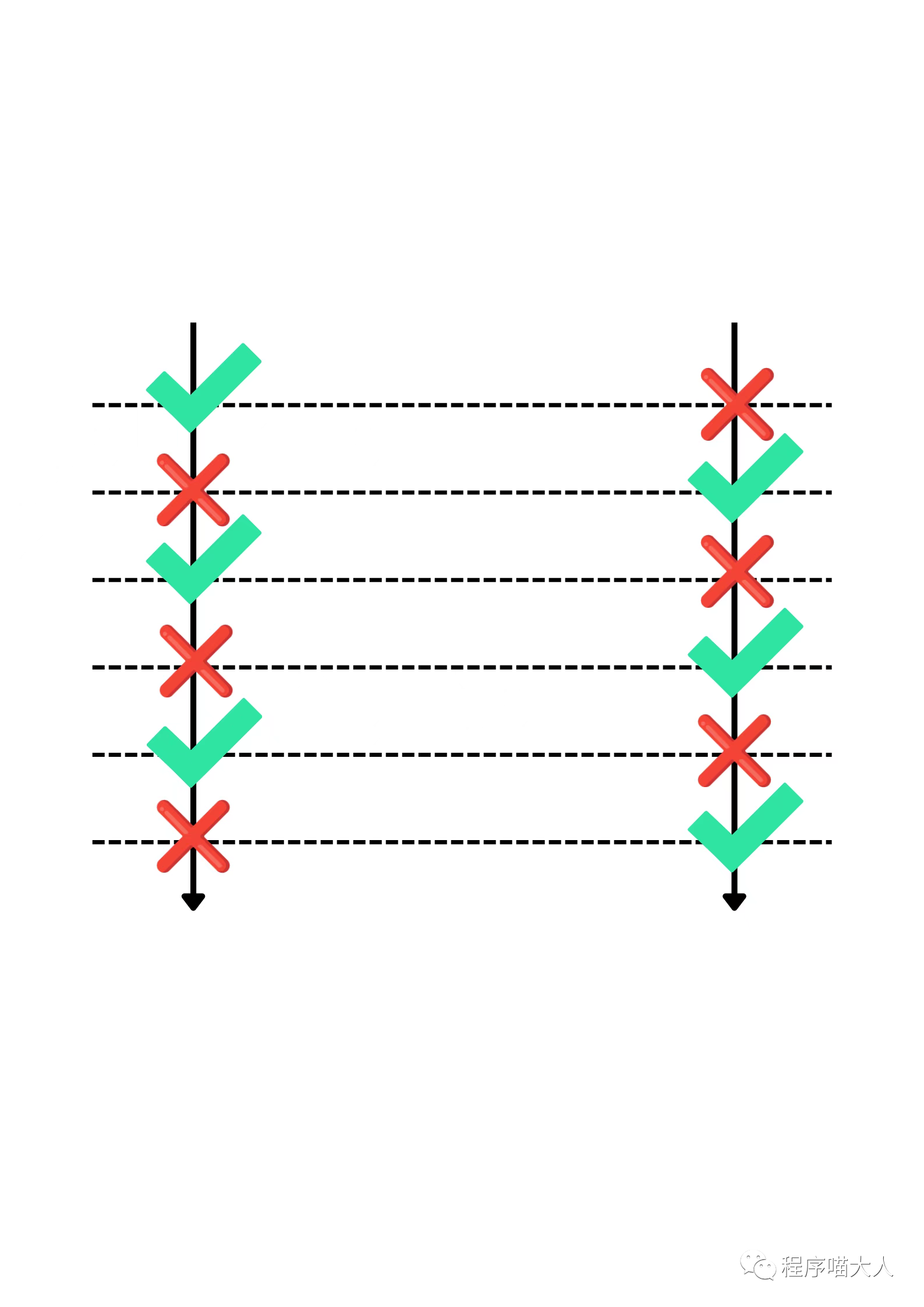
频繁的触发Cache Miss,导致程序的性能相当差。
而如果x和y中间加了128字节的填充,x和y不在同一个Cache line上,不同CPU之前不会影响,它俩都会频繁的命中自己的Cache,整个程序性能就会很高,这就是传说中的False Sharing问题。
所以我们写代码时,可以基于此做深一层思考,如果我们写单线程程序,最好保证访问的数据能够相邻,在一个Cache line上,可以尽可能的命中Cache。
如果写多线程程序,最好保证访问的数据有间隔,让它们不在一个Cache line上,减少False Sharing的频率。
上述内容源于前一段的技术分享,完整PPT在 一个优质的C++学习圈 里,来一起钻研C++吧。
审核编辑 :李倩
-
高性能缓存设计:如何解决缓存伪共享问题2025-07-01 987
-
CPU Cache是如何保证缓存一致性的?2023-12-04 3000
-
多个CPU各自的cache同步问题2023-06-17 4104
-
CPU CACHE策略的初始化2023-06-05 2566
-
CPU设计之Cache存储器2023-03-21 2560
-
CPU Cache伪共享问题2022-12-12 1172
-
cpu与cache内存交互的过程2022-10-21 3592
-
cache的排布与CPU的典型分布2022-10-18 3221
-
CPU Cache Line伪共享问题的总结和分析2019-04-10 7814
-
多核DSP共享空间CACHE问题2018-06-21 2380
-
Buffer和Cache之间区别是什么?2018-04-02 7302
-
高速缓存(Cache),高速缓存(Cache)原理是什么?2010-03-26 7252
-
什么是Cache/SIMD?2010-02-04 628
-
嵌入式CPU指令Cache的设计与实现2009-08-05 910
全部0条评论

快来发表一下你的评论吧 !
