

目前HD地图构建的四种主流方案的优势与不足对比
描述
高精度(High-Definition, HD)语义地图是目前自动驾驶领域的一个重要研究方向,近年随着Transformer和BEV的大火,很多大佬团队都开展了HD语义地图构建相关的工作。2021年7月,清华大学MARS实验室提出了HDMapNet。紧随其后,同一团队又在今年6月公开了后续工作VectorMapNet。同时,MIT和上海交通大学也在今年5月提出了BEVFusion。今年11月底的时候,苏黎世联邦理工学院、毫末、国防科大、阿尔托大学又联合开发了SuperFusion。这四种方案基本上就是目前HD地图构建的主流方案。
本文将带领读者深入探讨这四种方案的优势与不足,通过对比方案来思考HD地图构建的重点与难点。当然笔者水平有限,如果有理解错误的地方欢迎大家一起讨论,共同学习。 温馨提示,本文讨论的方案都是开源的,各位读者可以在这些工作的基础上开展自己的研究!文末附原文链接和代码链接!
1. 为什么自动驾驶都要做BEV感知?
先说答案:因为自动驾驶要求的是空间感知单纯的前视摄像头输入,看到的只是有限视角内的画面。而自动驾驶任务要求的是对车辆周围整体空间范围内的感知,因此往往需要对输入的环视相机/激光雷达进行投影,转到BEV视角下进行HD地图的构建。 那么BEV感知的难点是什么呢? 在自动驾驶的车道线检测、可行驶区域检测等任务中,都是针对前视摄像头输入进行逐像素的分割/检测,每个输入像素都对应一个输出类别。这种一一对应的关系使得我们可以很容易得应用CNN/Transformer模型进行分割/检测。 但自动驾驶BEV感知已经不仅仅是2D感知问题,在空间变换的过程中像素很有可能发生畸变!比如,前视摄像头中的车辆,转换到BEV视角下可能已经不是车辆的形状了!再比如,前视摄像头中相邻很近的两个物体,转换到BEV视角下变得相隔很远。
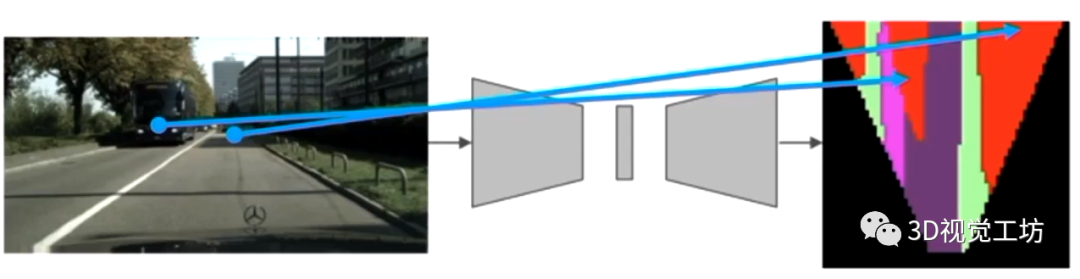
既然如此,可不可以先针对图像进行分割处理,然后再投影到BEV视角呢? 理论上来说这是一个很好的解决思路,避免了三维物体在投影过程中产生的畸变,但在实际操作过程中,会发现很容易造成多相机之间的不一致问题!

因此,需要直接针对BEV空间进行处理以构建HD地图!此外,BEV空间也使得相机和雷达的融合变得简单。
2. 传统的HD语义地图构建有什么问题?
先说说传统的HD地图构建方案: 基本上目前SLAM的落地方案都是分成两部分,一个是配备高精度传感器的地图采集车,用于对环境信息进行高精度的采集和处理,一个是乘用车,也就是大家所熟知的SLAM中的仅定位。 具体思路是,首先利用高精度传感器(雷达/IMU/相机/GPS/轮速计)在园区上来回往复运行,得到带有回环的轨迹以后基于SLAM方法获得全局一致性地图,后面交友标注员进行手工处理,得到静态HD地图。后面的乘用车就是将自身提取到的特征和前面构建的HD地图进行特征匹配,进行仅定位。这么做有什么问题呢?(1) 整体的Pipeline非常长,导致工艺流程非常繁琐。 (2) 手工标注需要消耗大量人力。不知道大家有没有手动打深度学习标签的经历,真的是非常痛苦。 (3) 需要在实际运行过程中更新地图。我认为这也是最重要的一点,上述基于手工方法构建的HD地图是完全的静态地图,但实际运行场景必然与之前构建的地图有所区别(比如某个车移动了位置,某个箱子转运到了其他位置)。所以乘用车在实际运行过程中需要实时更新并存储HD地图,这也是个非常繁琐的课题。但基于学习的端到端的方案是可以解决这一问题的,虽然从目前来看基于学习的方案在精度上还稍有不足,但相信这一问题可以很快被解决。
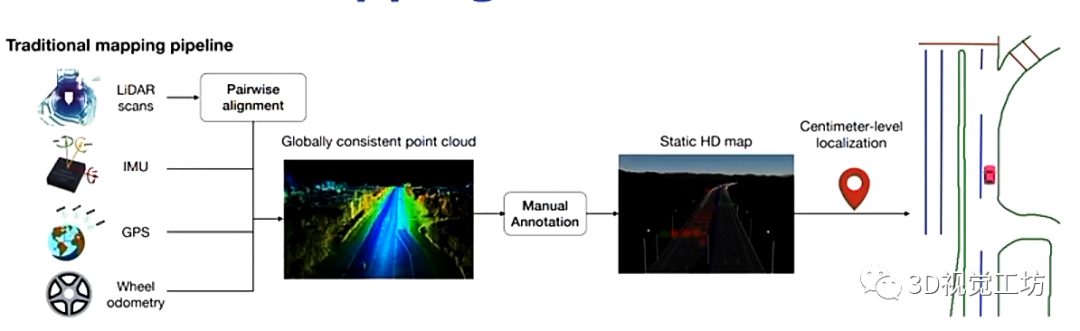
我们希望实现什么效果呢?(1) 简单,最好是端到端的网络架构。 (2) 自动、在线得构建HD地图。 (3) 能够不受动态环境影响,直接构建HD地图。
3. 清华大学开源HDMapNet
清华大学2021年7月开源的HDMapNet,其主要思路是输入环视相机和雷达点云,将相机和雷达点云分别进行特征提取后投影到BEV空间,在BEV空间里进行特征融合。注意,在BEV空间里进行特征融合是非常有优势的!之后,便是在BEV空间内进行解码。解码器共有三个输出,第一是地图的语义分割结果,里面包含了地图里哪个是车道线、哪个是路标、哪个是人行横道线。第二是实例Embedding,里面包含了实例信息,主要表达车道线和车道线直接、路标和路标之间的实例区分。第三是方向信息,主要表达了HD地图中每条线的方向。最后,语义分割HD地图首先和实例Embedding进行融合,得到实例化的HD地图,并融合方向信息以及NMS得到矢量化的HD地图。
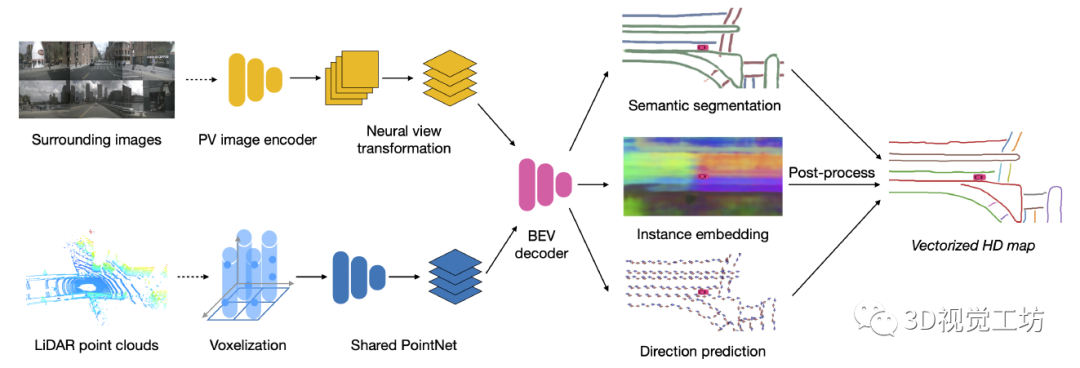
需要特别注意的是,HDMapNet并不一定需要做多传感器融合,纯相机或者纯雷达也是可以基于HDMapNet构建HD地图,只是效果相对要弱一些。HDMapNet的结果显示,相机对于车道线、人行横道线这种视觉纹理丰富的特征识别的较好,雷达对于路沿这种物理边界的效果更好。 但纯相机或纯雷达的操作真的给一些经费受限的小伙伴带来了福音!

一句话总结:HDMapNet实现了多模态BEV视角下的HD地图构建!
4. 清华大学后续工作VectorMapNet
我们可以发现,HDMapNet的重点在于BEV空间下的特征提取。 但问题是,这个Pipeline仍然有点长了,有没有更加端到端的方案?也就是说,直接输入图像和雷达,经过某个深度神经网络,直接输出HD地图。为解决这个问题,清华大学MARS实验室今年6月又开源了新的工作VectorMapNet。他们的思路是啥? (1) 需要找到一种更合适的图形来表示HD地图,MARS实验室认为折线更有利于HD地图的表达。此外,谷歌2020年的CVPR论文VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation也提出了这种用折线来表达HD地图的方案,谷歌官方没有开源,但Github上有Pytorch实现https://github.com/Henry1iu/TNT-Trajectory-Prediction,感兴趣的小伙伴可以复现一下,但目前该网络仍然需要非常大的显存(128G+)。 (2) 之前的HDMapNet还是处理的分割问题,但如果将分割问题转换为检测问题,会更有利于矢量地图的构建。 (3) 基于DETR进行开发有利于HD地图的构建。
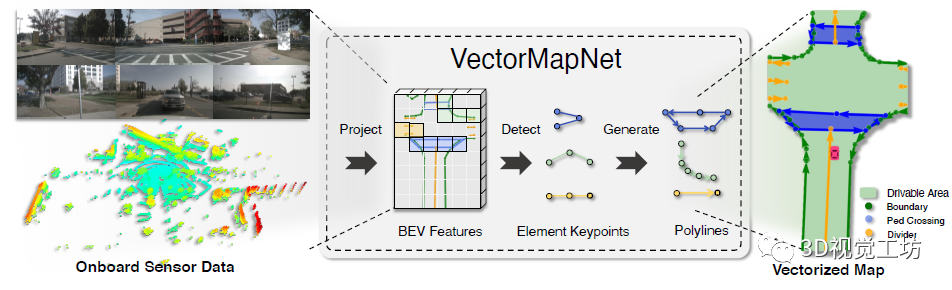
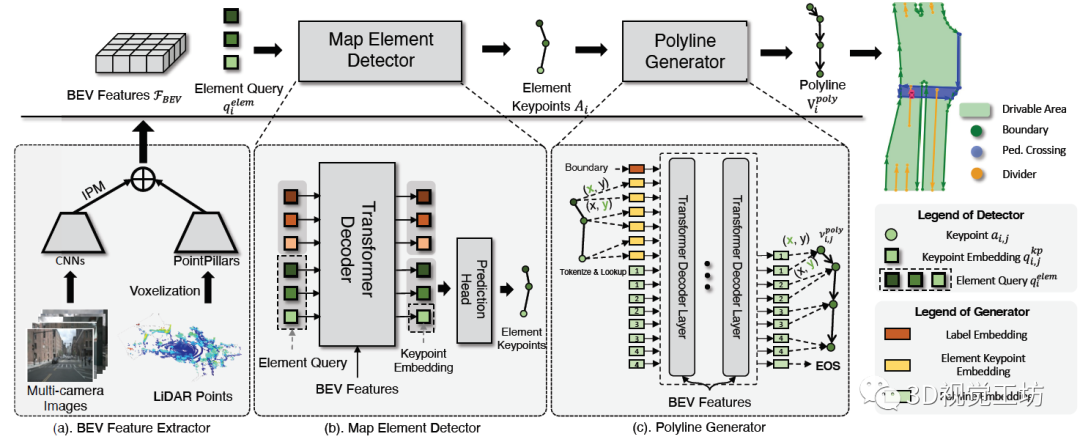
其实,VectorMapNet的网络架构就是三个部分:投影、检测、生成。投影就类似HDMapNet,将输入的相机和雷达转换到BEV视角,得到BEV特征图。检测就是提取HD地图元素,具体来说就是基于Query来提取关键点,这里的关键点可以是车道线的起点、终点、中间点。这个检测的思想其实非常巧妙,它没有在中间过程就得到非常多的输出点,而是选取了更简洁更统一化的表示!生成就是指得到折线化矢量化的HD地图,也是一个自回归模型,具体思路也是基于Transformer回归每个顶点坐标。 虽然整体来看架构有些复杂,但这个网络是直接端到端的,有利于训练和应用。笔者个人感觉,VectorMapNet的一个更有意思的点在于,它是一个端到端的多阶段网络。也就是说,网络不再是一个完全的黑盒子。如果网络的输出结果出现漏检/误检,那么我们可以打印出中间的关键点,看看具体是哪一个阶段出现了问题。
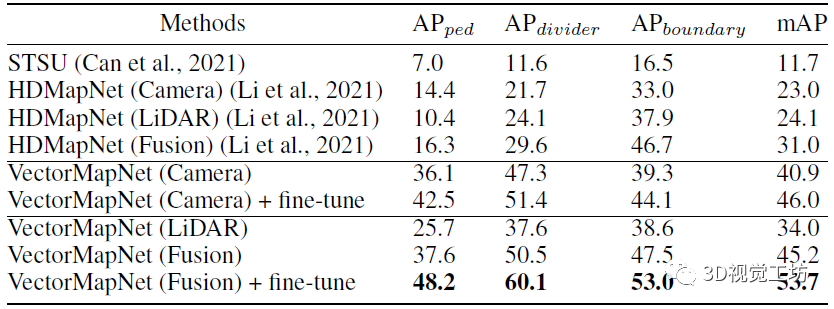
结果显示,VectorMapNet这种基于检测的方案性能远超HDMapNet。例如在人行横道上的预测AP提升了几乎32个点,在整体的mAP上也提升了22.7个点。
从定性结果也可以看出,VectorMapNet对于细节的把握是非常好的。HDMapNet和STSU经常出现漏检,但VectorMapNet很少。在Ground Truth上的车道线有时会出现一些细小的波折,HDMapNet和STSU很难检测出来,但VectorMapNet提取的HD地图轮廓与真值更吻合。 说到这里,也肯定有小伙伴关心VectorMapNet端到端方案和HDMapNet后处理方案之间的优劣。可以发现的是,HDMapNet在进行一些后处理时,很容易将一条检测线检测为两条,这主要是由于分割过程中对于车道线的分割结果过宽导致的。在实际使用中,这种将一条车道线检测为两条的结果会导致很严重的问题。这也说明了基于检测的HD地图方案要优于基于分割的HD地图方案。
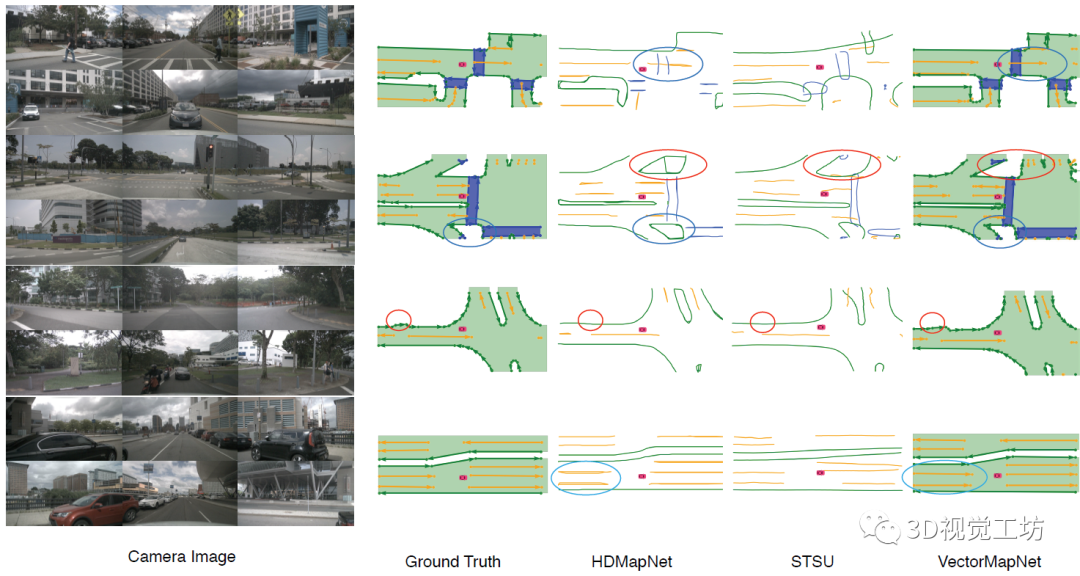
不仅如此,VectorMapNet更强大的地方在于,它甚至可以检测出来未标注的车道线!从下图可以看出,在原始的数据集中漏标了一条车道线,HDMapNet无法检测出来,但VectorMapNet却输出了这一结果。
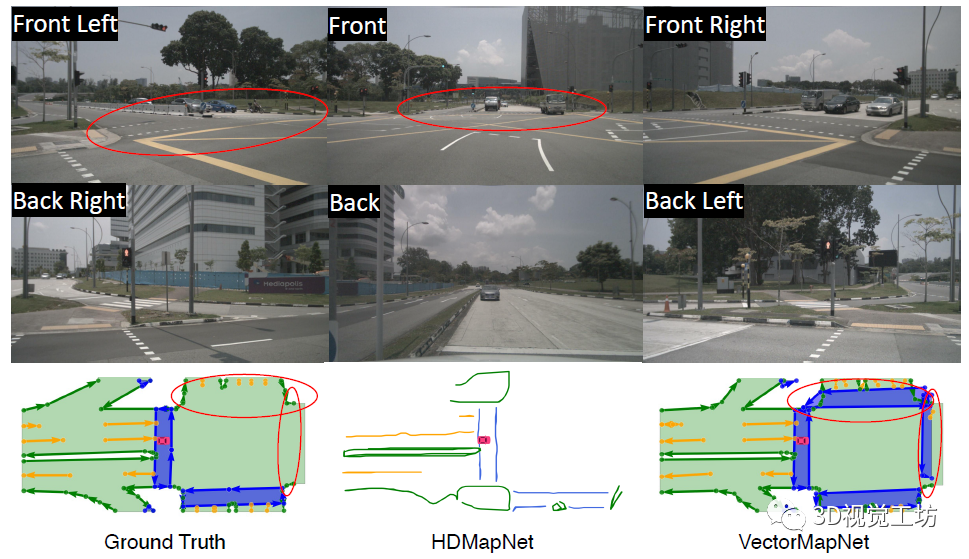
一句话总结:VectorMapNet基于检测思路优化了HDMapNet!
5. MIT&上交&OmniML开源BEVFusion
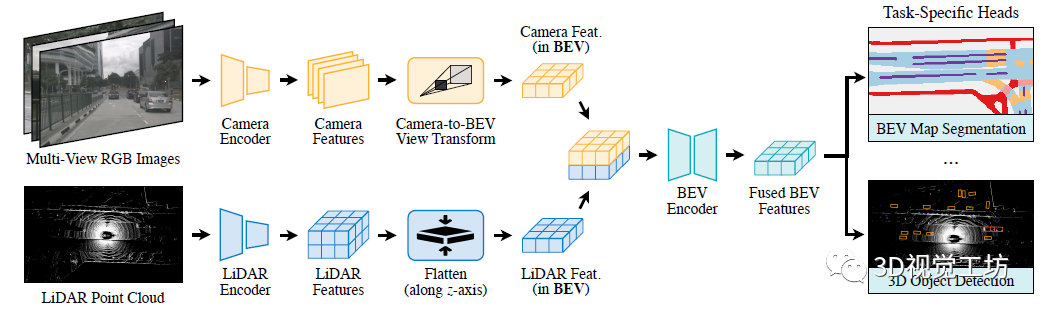
这篇文章大家就都比较熟悉了, MIT韩松团队开源的BEVFusion,文章题目是BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation。注意和NeurIPS 2022论文BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework要区分开。 单从网络架构上来看,感觉和HDMapNet原理非常类似,都是先从相机、雷达输入分别提取特征并投影到BEV空间,然后做BEV视角下的解码,输出结果不太相同,BEVFusion除了HD地图外还输出了3D目标检测的结果。 这篇文章其实解答了困惑我很久的一个问题,就是为什么不先把图像投影到雷达,或者雷达投影到图像,然后再一起转到BEV空间下,而是要分别提取特征再到BEV空间下进行特征融合。这是因为相机到激光雷达的投影丢掉了相机特征的语义密度,对于面向语义的任务(如三维场景分割)有非常大的影响。

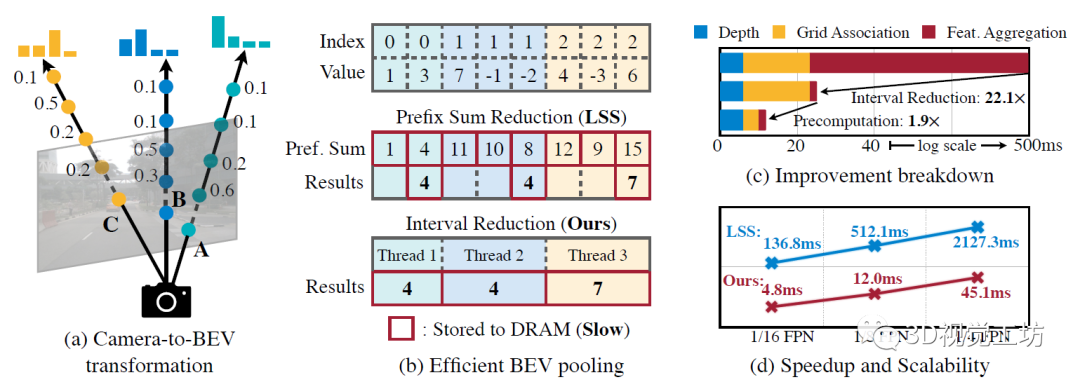
感觉BEVFusion的主要创新点还是基于BEV池化提出了两个效率优化方法:预计算与间歇降低。预计算:BEV池化的第一步是将摄像头特征点云的每个点与BEV网格相关联。与激光雷达点云不同,摄像头特征点云的坐标是固定的。基于此,预计算每个点的3D坐标和BEV网格索引。还有根据网格索引对所有点进行排序,并记录每个点排名。在推理过程中,只需要根据预计算的排序对所有特征点重排序。这种缓存机制可以将网格关联的延迟从17ms减少到4ms。间歇降低: 网格关联后,同一BEV网格的所有点将在张量表征中连续。BEV池化的下一步是通过一些对称函数(例如,平均值、最大值和求和)聚合每个BEV网格内的特征。现有的实现方法首先计算所有点的前缀和,然后减去索引发生变化的边界值。然而,前缀和操作,需要在GPU进行树缩减(tree reduction),并生成许多未使用的部分和(因为只需要边界值),这两种操作都是低效的。为了加速特征聚合,BEVFusion里实现一个专门的GPU内核,直接在BEV网格并行化:为每个网格分配一个GPU线程,该线程计算其间歇和(interval sum)并将结果写回。该内核消除输出之间的依赖关系(因此不需要多级树缩减),并避免将部分和写入DRAM,从而将特征聚合的延迟从500ms减少到2ms。 通过优化的BEV池化,摄像头到BEV的转换速度提高了40倍:延迟从500ms减少到12ms(仅为模型端到端运行时间的10%),并且可以在不同的分特征辨率之间很好地扩展。
输出结果也很漂亮:联合实现了3D目标检测和语义地图构建。

一句话总结:BEVFusion大幅降低了计算量!
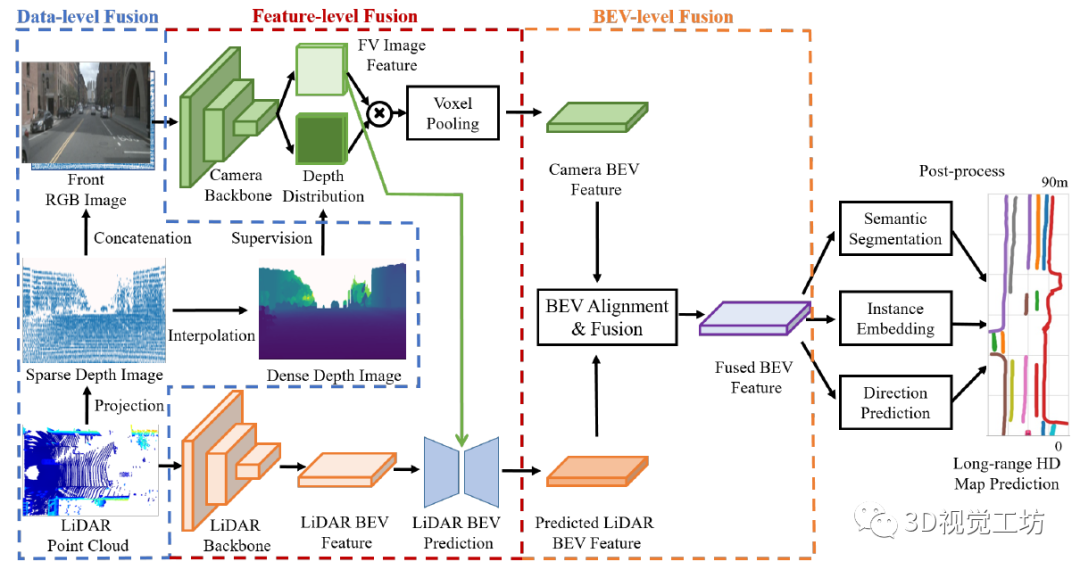
6. 苏黎世联邦理工开源SuperFusion
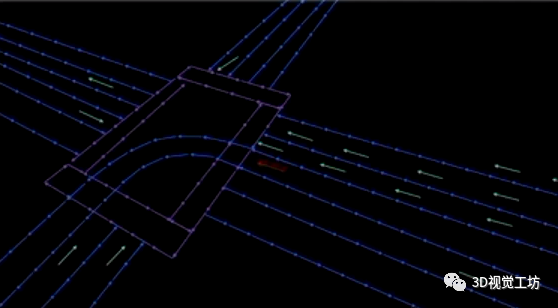
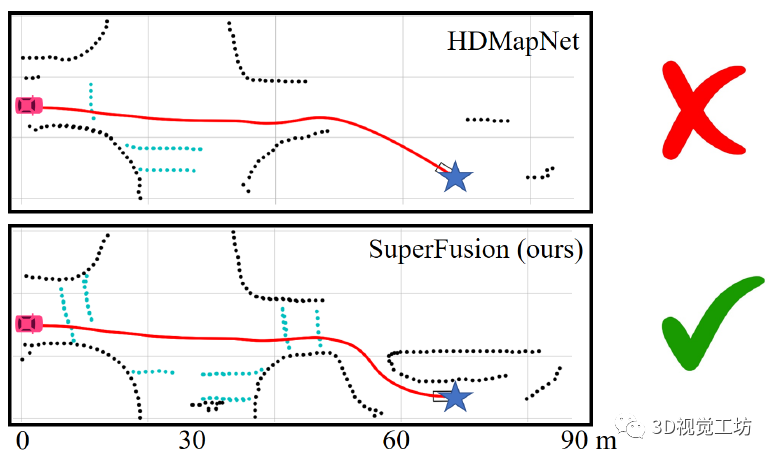
说实话,这项工作感觉非常惊艳! HDMapNet和VectorMapNet的指导老师赵行教授也表示过,现有的基于学习的HD地图构建方案的主要问题在于,所构建的HD地图仍然是短距离地图,对于长距离表达还有一些不足。而SuperFusion这项工作就专门解决了这个长距离HD建模问题,它可以构建90m左右的HD地图,而同年提出的HDMapNet建模长度也不过30m。 如下图所示,红色汽车代表汽车当前的位置,蓝色星星代表目标。结果显示,SuperFusion在生成短程(30 m)的HD语义地图基础上,预测高达90 m距离的远程HD语义地图。这给自动驾驶下游路径规划和控制模块提供了更强平稳性和安全性。
SuperFusion整体的网络结构是利用雷达和相机数据在多个层面的融合。在SuperFusion中体现了三种融合策略: 数据层融合:融合雷达的深度信息以提高图像深度估计的精度。 特征层融合:使用交叉注意力进行远距离的融合,在特征引导下进行BEV特征预测。 BEV级融合:对齐两个分支,生成高质量的融合BEV特征。 最后,融合后的BEV特征可以支持不同的头部,包括语义分割、实例嵌入和方向预测,进行后处理生成高清地图预测。
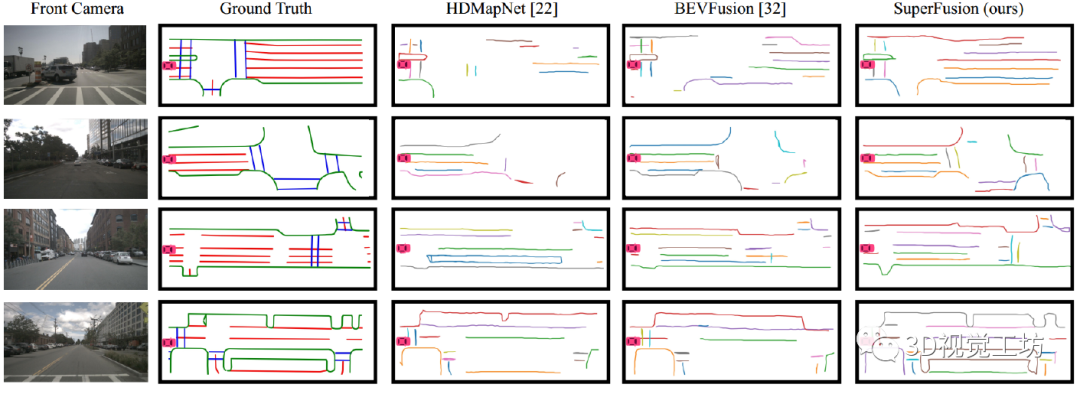
定性和定量结果也表明,SuperFusion相较于其他HD语义地图构建方案来说,性能提升很明显,尤其是长距离建模。这种长距离建模能力使得SuperFusion更有利于自动驾驶下游任务。

一句话总结:SuperFusion实现了长距离HD语义地图构建!
7. 结论
本文带领读者探讨了自动驾驶任务中的HD语义地图构建的主要问题,并介绍了4种主流的HD语义地图构建方案,分别是清华大学开源的HDMapNet和VectorMapNet、MIT&上交开源的BEVFusion、苏黎世联邦理工&毫末&国防科大&阿尔托开源的SuperFusion。四种方案主要都是在nuScenes上进行评估的,其中HDMapNet和VectorMapNet主要解决的是如何端到端的实现HD地图构建问题,BEVFusion主要解决的是计算效率问题,SuperFusion主要解决的是长距离HD地图构建问题。四种方案的底层架构其实都是Transformer,这也说明了Transformer在多模态和CV领域的影响力越来越大了。其实,现有的HD语义地图中表达的语义信息也都是像车道线、人行横道线的这种低级语义。作者个人认为,在未来,HD语义地图的发展趋势是提取更高级别的语义,比如车辆识别到了一个正在横穿马路的行人,我们想知道的不仅仅是马路上有个人,我们更想让自动驾驶车辆理解的是,这个人的具体意图是什么。
审核编辑:郭婷
-
RDMA简介3之四种子协议对比2025-06-04 1343
-
FPGA 设计的四种常用思想与技巧2012-08-11 6849
-
四种不同供电模式的LED拓扑介绍2018-10-10 2577
-
四种主要的负电源轨生成方案如何选择2021-03-11 3130
-
主流的三种RF方案及其优缺点对比分析2021-05-25 6747
-
四种LED路灯的电源设计方案2010-04-02 2110
-
个人局域网四种核心技术分析对比2014-09-30 3722
-
FPGA设计的四种常用思想与技巧2016-12-17 944
-
基于四种经典的DOA估计算法对比研究2017-11-06 1839
-
详谈企业的四种业务分析2020-12-09 6875
-
四种门电路符号的详细对比2021-02-09 14471
-
线缆敷设的四种方式与注意事项2022-07-18 13998
-
汽车四种主流的车用总线技术详解2022-11-18 5631
-
四种方式实现led点亮2023-01-04 1118
-
SD-WAN组网的四种方案及其差异2023-07-14 3647
全部0条评论

快来发表一下你的评论吧 !
