

类脑计算芯片与应用、趋势与展望
描述
类脑计算芯片结合微电子技术和新型神经形态器件,模仿人脑神经系统计算原理进行设计,旨在突破“冯·诺依曼瓶颈”,实现类似人脑的超低功耗和并行信息处理能力。
在今日举办的创新智能芯片,共筑未来航天学术会议当中,北京大学集成电路学院教授王源做了题为《类脑芯片与应用技术》的报告。王源教授主要介绍了类脑计算概述、类脑计算关键技术、类脑计算芯片与应用、趋势与展望。
类脑计算概述
类脑计算(Brain-inspired Computing)又被称为神经形态计算(Neuromorphic Computing)。是借鉴生物神经系统信息处理模式和结构的计算理论、体系结构、芯片设计以及应用模型与算法的总称。王源教授表示人工神经网络(ANN)是对神经网络连接性的模拟而脉冲神经网络(SNN)是对生物神经系统的仿生模拟,并展示了ANN与SNN的区别。
ANN的原理为计算机科学、数学;编码方式为电平高低;神经元是非线性激活函数;学习规划通过BP等全局学习算法;应用场景主要是图像分类、语音识别、自然语言处理等。
SNN的原理为神经科学原理;编码方式为脉冲时间或频率;神经元包含内在动力学;学习规则主要是生物启发学习算法;应用场景主要是物体追踪等低延时应用,超低功耗应用以及类脑智能。
类脑计算关键技术
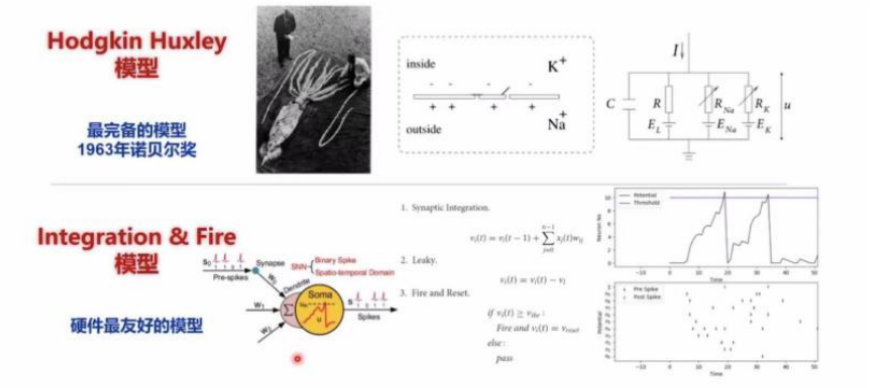
神经元:对从树突接收到的时空信息进行整合,并在超过特定阈值时发放新的脉冲,通过轴突传递到其他神经元。准确但复杂度高的神经元模型:HH模型;较为简化神经元模型:累积释放(I&F)模型。
突触:突触是不同神经元之间的连接,支撑记忆、学习功能;记忆以突触连接强度的形式存储在神经网络中。突触连接强度能够变化,体现为不同类型的可塑性包括短时程、长时程可塑性等,从而实现神经网络的学习功能。
神经网络:由神经元与突触组成的高度互连网络,包含约1011神经元,1015突触。信息以脉冲形式(二值型)在生物神经网络中传递,并以局域模拟的形式进行处理;支撑人脑复杂的感知、认知等功能。
发射率编码:信息编码在发射率r=N/T中,即在一定时间T内发放了N个脉冲。
时间编码:信息编码在发放脉冲的具体时间或时间间隔中。
群编码:信息编码在某一组神经元的行为模式中。
关键技术:片上网络、片上网络拓扑、片上网络路由
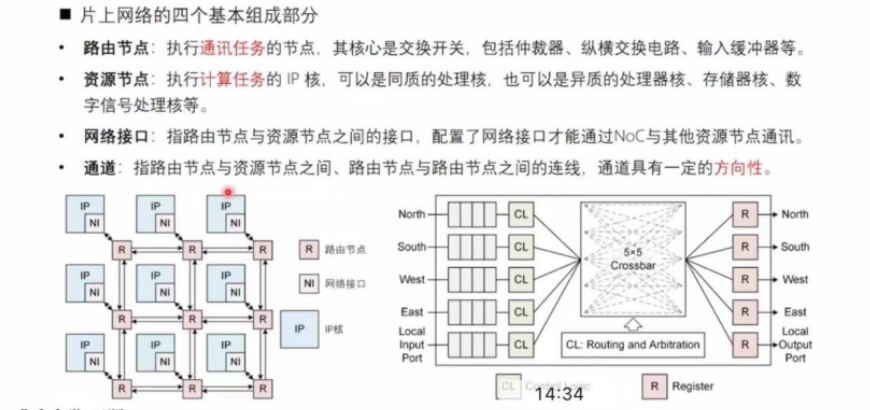
片上网络的四个基本组成部分:
路由节点:执行通讯任务的节点,其核心是交换开关,包括仲裁器、纵横交换电路、输入缓冲器等。
资源节点:执行计算任务的 IP 核,可以是同质的处理核,也可以是异质的处理器核、存储器核、数字信号处理核等。
网络接口:指路由节点与资源节点之间的接口,配置了网络接口才能通过NOC与其他资源节点通讯。
通道:指路由节点与资源节点之间、路由节点与路由节点之间的连线,通道具有一定的方向性。
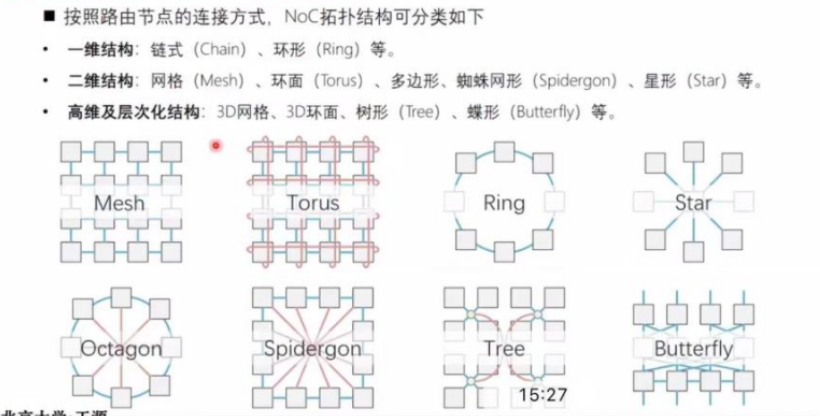
按照路由节点的连接方式,NoC拓扑结构可分类如下:
一维结构:链式(Chain)、环形(Ring)等。
二维结构:网格 (Mesh)、环面 (Torus) 、多边形、蜘蛛网形 (Spidergon) 、星形(Star)等。
高维及层次化结构:3D网格、3D环面、树形 (Tree)、蝶形 (Butterfly) 等。
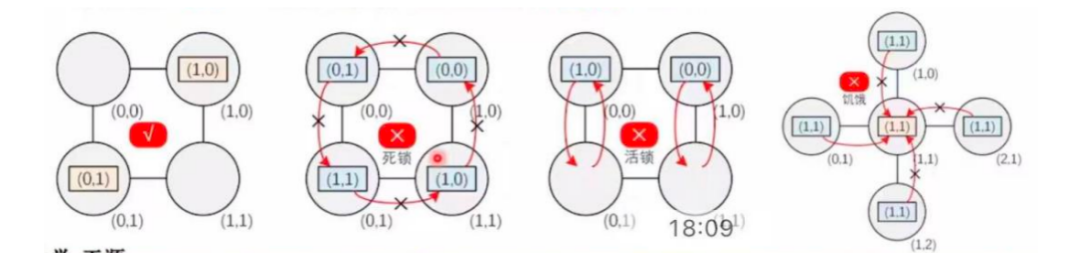
路由设计的功能考量多种不利现象:
死锁:数据包等待前级清空,前级又在等待更前级,依赖关系形成闭环,数据包无法路由。
活锁:数据包持续进行路由,但就是无法到达目标地址。只出现在自适应的非最短路径中。
饥饿:多个方向的数据包竞争输入,优先级固定只处理一个方向,其他方向被完全堵死。
解决活锁:仅使用最短路径路由方案,限制错误路由操作数量。
解决饥饿:采用需求跟踪的循环优先级,为低优先级适当保留带宽。
解决死锁:一般有死锁预防、死锁恢复和死锁避免方案。
关键技术:SNN学习算法
脉冲神经网络学习算法分类:
ANN转SNN离线学习: 任何在ANN中能实现学习的算法,只要求能转换到SNN。
无监督在线学习: 主要包含Hebb、STDP、BCM等与突触可塑性相关的仿生学习算法。
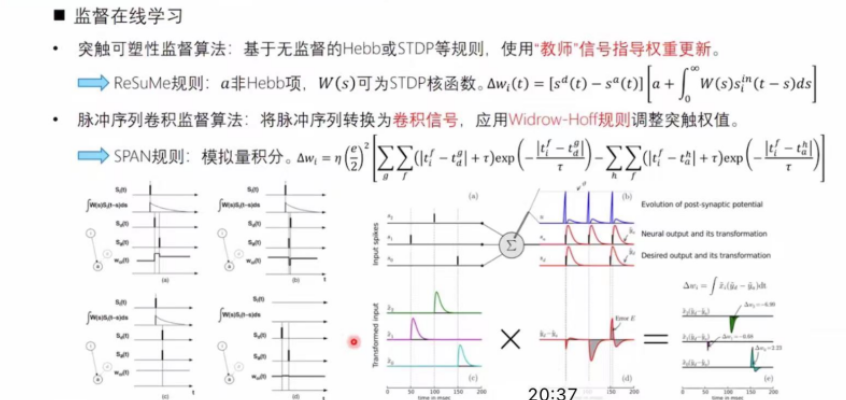
监督在线学习: 依赖于梯度下降、突触可塑性、脉冲卷积序列、时空反向传播的浅层/深层学习算法。
其他在线学习: 基于SNN的强化学习、半监督学习、液体状态机学习、深度信念网络学习等。
其中,无监督在线学习的实现方式包括:
突触可塑性:无监督学习的理论基础,生物可信,表征为突触连接强度增强或抑制。
长时程增强 (LTP):NMDA受体强烈兴奋,Ca2+大量内流,形成新的AMPA受体。(海马体)
长时程抑制(LTD):NMDA受体活动处于低水平,Ca2+流量低下,AMPA受体消亡。(纹状体)
STDP学习规则: 对Hebb学习在突触前后脉冲时间依赖可塑性上的拓展。
类脑计算芯片与应用
IBM TrueNorth芯片
规格指标:4096核众核架构(64x64),每核256神经元、64K突触(256x256)。
NoC拓扑:片内及片间扩展均为2D Mesh结构,片间传输速度显著慢于片内。
路由算法: 片内外均为X-Y维序路由,片内采用异步双轨四相、片间采用异步单轨两相协议。
近存计算:非冯·诺依曼架构,存储与计算单元邻近分布在各处理核,高度并行,事件驱动。路由节点:需要处理东/西/南/北/本地五个方向的数据出入,首先处理东西向,再处理南北向。路由节点内置FIFO缓存缓解拥堵饥饿,最短路径算法避免活锁,支持一对一发射(同时避免死锁)
Intel Loihi芯片
规格指标:128核众核架构 (16x8),每核含1K神经元,1M突触,此外有3(6)个x86嵌入式处理核心。
NoC拓扑:四个核与一个路由节点构成四叉树,路由节点之间构成2D Mesh结构,片间也是2D Mesh。
路由算法:片内及片间X-Y维序算法,纯异步路由握手设计。
框架本身仅支持一对一发射,但可在源神经元处,通过复制多个一对一实现一对多发射。
Loihi芯片每个核都包含一个基于微码操作的学习引擎,可以编程在线学习算法。
神经元模型:采用基于电流的LIF模型。
片上学习:学习引擎针对过滤的脉冲轨迹进行操作,根据历史脉冲活动情况,随着时间的推移改变突触状态变量。为适配包括STDP在内的高级学习规则,Loihi定义了多种微码操作来满足不同算法需求。
清华大学:Tianjic芯片
规格指标:156核众核架构 (12x13),每核256神经元、64K突触 (256x256)。
NoC拓扑:片内及片间扩展均为2D Mesh结构,片间采用LVDS协议进行高速传输 (1.05Gb/s)。
路由算法:片内外均为X-Y维序路由,片内采用异步握手协议。
可使用额外的广播神经元和复制神经元来实现一对多发射,也可在核内执行多播判断
北京大学:PAICore芯片
规格指标:64核众核架构 (8x8),每核1K神经元、1M突触 (1024x1024)。
NoC拓扑: 片内及片间扩展均为2D Mesh结构,片间采用8:1Merge/Split合并或分流8个核心的数据。
路由算法:片内外均为Y-X维序路由,采用基于异步FIFO的异步握手协议。
路由地址采用绝对地址表示,比对目标地址与当前核地址是否一致。
智能芯片的发展趋势
人脑的优势:
超低功耗
在处理同样复杂任务时,没有任何人工系统能够媲美人脑的高能效性。
学习能力
没有任何自然/人工系统能够像人脑一样,具有对新环境的自适应能力、对新信息与新技能的自动获取能力。
存算融合
神经元实现信息整合,突触完成存储和学习,每个神经元通过上万突触与其他神经元互联,高度并行、存算一体。
高鲁棒性
没有任何系统能够像人脑一样,在复杂环境下有效决策并稳定工作、能够在多处损伤情况下依然具有很好鲁棒性。
智能芯片的未来发展:
计算驱动:算力和能效的持续提升推进军事智能应用。
ANN深度学习处理器:高性能计算稠密性数据、高算力。
SNN类脑计算芯片:事件驱动型稀疏性数据、低功耗。
生物启发:持续提升规模、复杂度探索通用智能实现方法。
审核编辑:郭婷
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+神经形态计算、类脑芯片2025-09-17 2952
-
基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统2024-06-25 951
-
世界首款!又是清华:类脑互补视觉芯片“天眸芯”2024-06-04 1292
-
国内外典型类脑计算芯片介绍2023-12-21 2346
-
类脑芯片的商用梦2022-02-08 4834
-
什么是类脑计算_中国的类脑计算发展2020-10-20 8623
-
浙江大学实验室发布国内首台类脑计算机2020-10-19 4217
-
清华大学研发类脑计算机2020-10-16 5334
-
我国首台基于自主知识产权类脑芯片的类脑计算机研制成功2020-09-09 1104
-
中国首台基于自主知识产权类脑芯片的类脑计算机研制成功2020-09-06 4162
-
新里程碑!全球神经元规模最大的类脑计算机研发成功2020-09-03 2897
-
浙江大学成功研发我国首台基于自主知识产权类脑芯片的类脑计算机2020-09-02 3325
-
类脑芯片会是AI的终极答案吗2019-11-05 1409
全部0条评论

快来发表一下你的评论吧 !
