

基于视觉transformer的高效时空特征学习算法
描述
二、背景
高效的时空建模(Spatiotemporal modeling)是视频理解和动作识别的核心问题。相较于图像的Transformer网络,视频由于增加了时间维度,如果将Transformer中的自注意力机制(Self-Attention)简单扩展到时空维度,将会导致时空自注意力高昂的计算复杂度和空间复杂度。许多工作尝试对时空自注意力进行分解,例如ViViT和Timesformer。这些方法虽然减小了计算复杂度,但会引入额外的参数量。本文提出了一种简单高效的时空自注意力Transformer,在对比2D Transformer网络不增加计算量和参数量情况下,实现了时空自注意力机制。并且在Sthv1&Sthv2, Kinetics400, Diving48取得了很好的性能。
三、方法
视觉Transofrmer通常将图像分割为不重叠的块(patch),patch之间通过自注意力机制(Self-Attention)进行特征聚合,patch内部通过全连接层(FFN)进行特征映射。每个Transformer block中,包含Self-Attention和FFN,通过堆叠Transformer block的方式达到学习图像特征的目的。
在视频动作识别领域,输入的数据是连续采样的多帧图像(常用8帧、16帧、32帧等)学习视频的时空特征,不仅要学习单帧图像的空间视觉特征,更要建模帧之间的时域特征。本文提出一种基于视觉transformer的高效时空特征学习算法,具体来说,我们通过将patch按照一定的规则进行移动(patch shift),把当前帧中的一部分patch移动到其他帧,同时其他帧也会有一部分patch移动到当前帧。经过patch移动之后,对每一帧图像的patch分别做Self-Attention,这一步学习的特征就同时包含了时空特征。具体思想可以由下图所示:
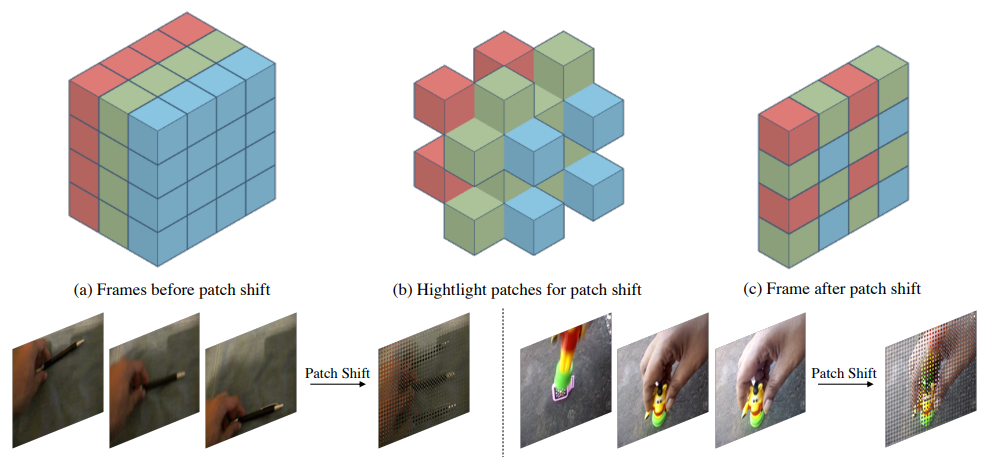
在常用的2D图像视觉Transformer网络结构上,将上述patch shift操作插入到self-attention操作之前即可,无需额外操作,下图是patch shift transformer block,相比其他视频transformer的结构,我们的操作不增加额外的计算量,仅需进行内存数据移动操作即可。对于patch shift的移动规则,我们提出几种设计原则:1. 不同帧的块尽可能均匀地分布。2.合适的时域感受野。3.保持一定的移动块比例。具体的分析,读者可以参考正文。
我们对通道移动(Channel shift) 与 块移动(patch shift)进行了详尽的分析和讨论,这两种方法的可视化如下:

通道移动(Channel shift) 与 块移动(patch shift)都使用了shift操作,但channel shift是通过移动所有patch的部分channel的特征来实现时域特征的建模,而patch shift是通过移动部分patch的全部channel与Self-attention来实现时域特征的学习。可以认为channel shift的时空建模在空域是稠密的,但在channel上是稀疏的。而patch shift在空域稀疏,在channel上是稠密的。因此两种方法具有一定的互补性。基于此,我们提出交替循环使用 patchshift和channel shift。网络结构如下图所示:

四、实验结果
1. 消融实验

2. 与SOTA方法进行对比



3. 运行速度
可以看到,PST的实际推理速度和2D的Swin网络接近,但具有时空建模能力,性能显著优于2D Swin。和Video-Swin网络相比,则具有明显的速度和显存优势。

4. 可视化结果
图中从上到下依次为Kinetics400, Diving48, Sthv1的可视化效果。PST通过学习关联区域的相关性,并且特征图能够反映出视频当中动作的轨迹。
审核编辑:郭婷
- 相关推荐
- 热点推荐
- 内存
-
全面拥抱Transformer:NLP三大特征抽取器(CNNRNNTF)比较2020-05-29 2823
-
基于时空模式的轨迹数据聚类算法2017-12-05 918
-
基于低秩重检测的多特征时空上下文的视觉跟踪2017-12-15 986
-
基于HTM架构的时空特征提取方法2018-01-17 1339
-
如何使用稀疏卷积特征和相关滤波进行实时视觉跟踪算法2019-01-17 1351
-
Transformer模型的多模态学习应用2021-03-25 12241
-
包含时空信息特征的视频指纹算法2021-06-10 1062
-
基于WordNet模型的迁移学习文本特征对齐算法2021-06-27 1005
-
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果2021-12-28 2833
-
基于深度学习的视觉检测系统的特点及应用2022-11-24 2926
-
利用视觉+语言数据增强视觉特征2023-02-13 1935
-
机器学习算法学习之特征工程12023-04-19 1919
-
CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据2023-06-18 1209
-
一个通用的时空预测学习框架2023-06-19 3084
-
基于Transformer的目标检测算法2023-08-16 1235
全部0条评论

快来发表一下你的评论吧 !
