

基于忆阻器存算一体芯片的研究进展
描述
基于忆阻器的存算一体变革性技术正成为学术界和产业界关注的前沿热点。
在今日举办的创新智能芯片,共筑未来航天学术会议当中,清华大学集成电路学院院长吴华强教授做了题为《基于忆阻器存算一体芯片的研究进展》的报告。
吴华强院长以计算驱动集成电路技术的发展、基于忆阻器存算一体芯片研究进展、总结与展望三个角度展开。
计算驱动集成电路技术的发展
吴华强院长提出集成电路有两个核心特征:信息元和信息元的超大规模集成,同时提出在集成电路的发展中有“三座大山”难以翻越,分别为“存储墙”、“功耗墙”、“面积墙”。存算分离的传统架构的问题带来了“存储墙”;“存储墙” 导致延迟长、大量晶体管发热的问题,引来“功耗墙”;“功耗墙”功耗高、供电和散热复杂、曝光场大小限制芯片面积的问题,导致“面积墙”;最后“面积墙”的问题导致良率急剧降低。另外伴随着人工智能的算法模型变得越来越复杂,模型参数量急剧增长,对计算芯片提出了巨大挑战。美国半导体行业协会SIA在《半导体十年计划》中指出当前计算耗能的增长速度远超全球总能量的增长速度极大限制了算力的持续增长,未来亟需新的计算范式。
未来集成电路将通过计算范式、芯片架构和集成方法等创新,突破高算力发展瓶颈。具体创新方法为:Chiplet异质集成提高晶体管数量、存算一体技术提高每单位器件的算力、可重构异构计算架构提高算力扩展性。
计算新范式
忆阻器开启高性能计算新范式—存算一体 + 模拟计算。
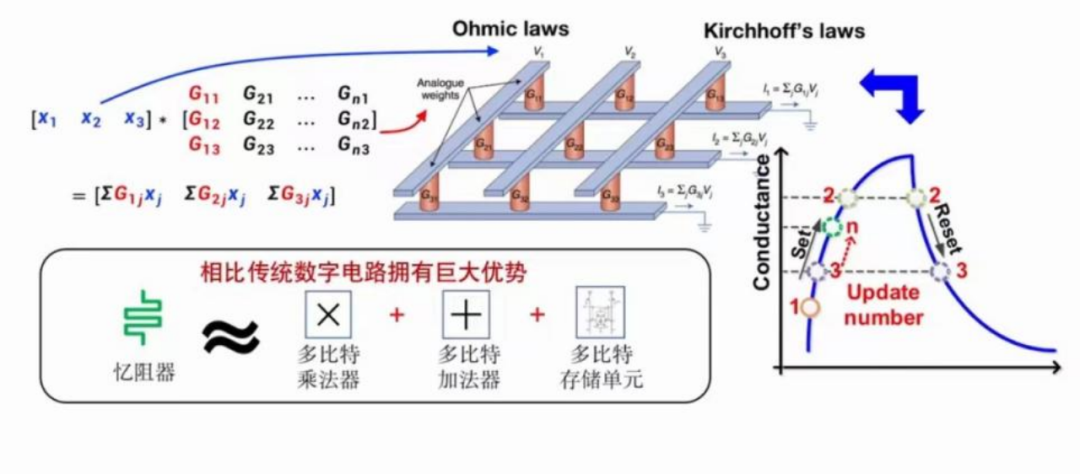
忆阻器存算一体芯片由冯诺依曼架构转向存算一体架构。
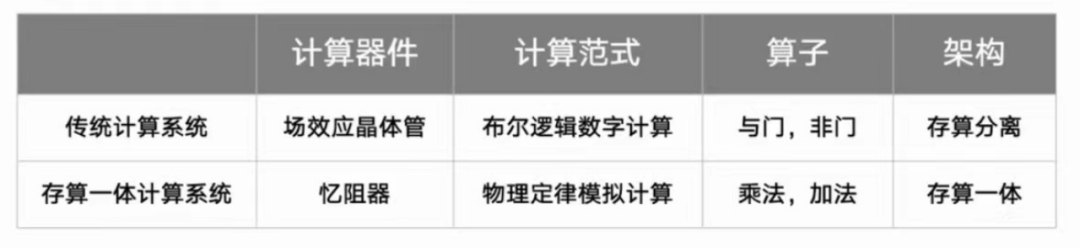
AI算力需求驱动下的模拟计算发展
AI算法对算力的需求呈爆炸式增长,数字芯片的算力已不能满足需求。
对于AI算法,“存储墙”成为主要的计算瓶颈,需要把大量参数配置在计算本地,不能频繁的从DRAM搬运数据。
AI算法的算子比较集中,与忆阻器阵列的契合度很好。
AI算法中,比特精确≠系统精确,为忆阻器模拟计算提供了重要的契机。
近十年来,忆阻器存算一体技术研究已从器件与阵列演示发展到原型芯片与系统,国际竞争激烈,备受学术界与产业界关注。
基于忆阻器存算一体芯片研究进展
忆阻器的特点:电阻连续、可逆转变,是一种新型纳米器件;具有生物可信性,可作为“神经形态器件”模拟神经元、突触功能;具备存算一体特性,可大幅提升算力和能效。
忆阻器存算一体芯片的新挑战及解决思路
如何真正克服比特误差对系统误差的影响?
混合训练框架。
如何高效、低成本的设计并制造出忆阻器存算一体芯片?
CMOS嵌入式集成 + EDA工具链。
如何提升存算一体架构的通用性,使其适配更多的神经网络算法?
发展面向存算一体芯片的软件工具链。
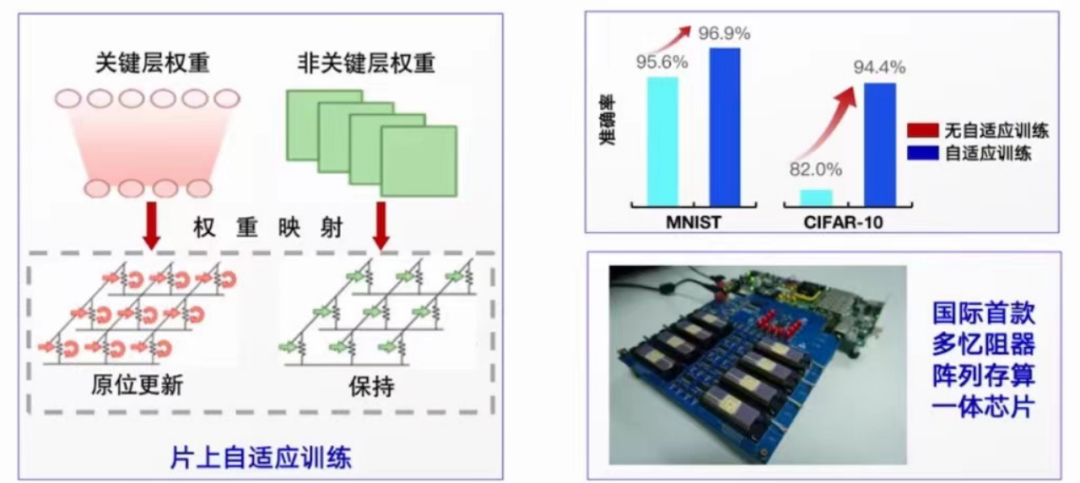
混合训练框架
由片外压力训练和片上自适应训练组成的混合训练框架。在片外压力训练中引入系统误差模型,构建具有误差耐受性的网络模型,提升实际硬件系统中的精度。在权重映射到芯片后,通过原位更新关键层权重进行自适应训练,进一步提升精度。
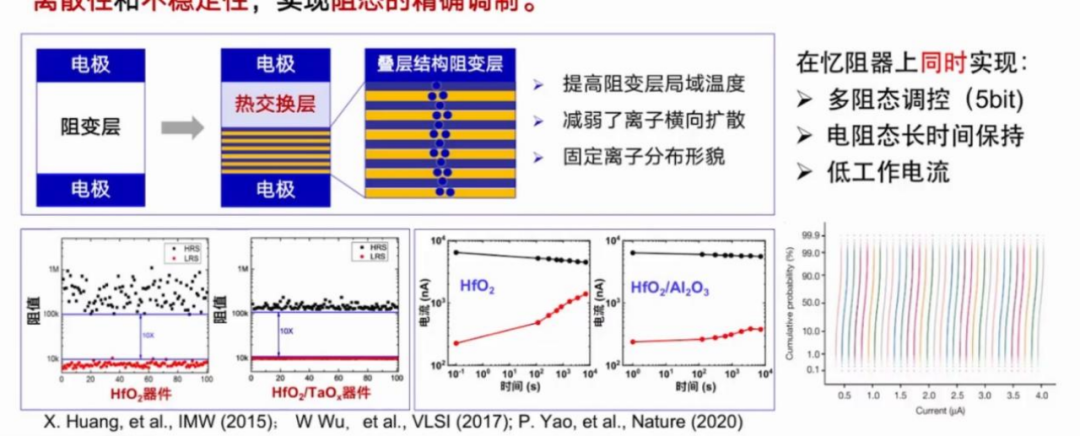
高性能忆阻器件
基于主流HfO2阻变材料,设计热交换层和叠层结构的新器件结构,有效抑制了忆阻器离散性和不稳定性,实现阻态的精确调制。
EDA工具链
研发从器件工艺仿真到电路模块设计,再到系统架构设计的EDA工具链。
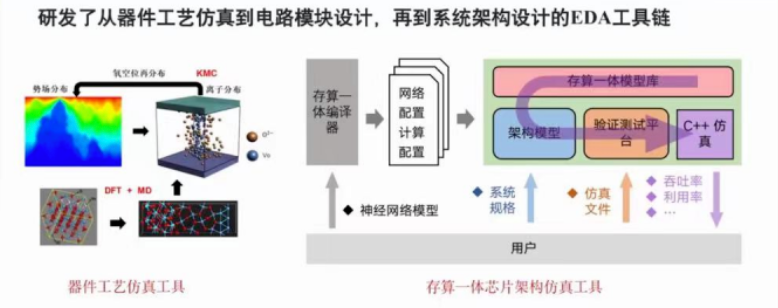
存算一体芯片软件工具链
编译器:对接算法层,实现向存算一体计算单元上高效部署神经网络算法以及生成可执行程序的功能。
软件模拟:对接编译器/算法层,集成底层硬件模型,考虑真实器件的非理想因素,实现对真实硬件功能与性能的评估与探索。
硬件模拟器:对接编译器,功能完整的计算单元模块,模拟存算一体SoC工作过程中的数据信号与控制信号变化情况。
研究进展
吴华强教授分享了清华大学在忆阻器存算一体方面的诸多进展:
1.国际首颗全系统集成的忆阻器存算一体芯片:清华大学与华为合作研发存算一体边缘智能芯片,是国际第一个全集成芯片。芯片的成功测试和演示有力地证明了基于忆阻器存算一体架构的可行性,130nm工艺存算一体芯片的能效相比14nm节点CPU提升了一个数量级,未来还有很大的提升潜力。
2.国际首款多阵列忆阻器存算一体系统:清华大学提出了提高系统精度的混合训练框架,完成多层卷积神经网络,能效比英伟达GPU高110倍,证明多阵列存算一体技术的可行性和能效、算力优势。
3.多核、可重构的忆阻器存算一体芯片:清华大学与斯坦福大学等合作,通过软硬件跨层次协同优化,实现通用、高能效存算一体芯片。
总结与展望
最后,吴华强教授提到,基于忆阻器的存算一体变革性技术将带来很多变化:其一,从底层器件到编译器等层面的改变,实现新计算机系统,但不改变现有编程语言;其二,新计算系统能效将提高102-103倍以上,达到1POPs/W;其三,单芯片算力可以得到有效提升,达到500TOPs或者1POPs。
审核编辑 :李倩
-
忆阻器到底是什么?它是如何实现存算一体的#芯片 #电脑 #GPU #忆阻器 #AI #类脑计算 #显卡安泰小课堂 2023-11-15
-
领跑芯片圈、高效类脑计算|忆阻器是如何发展至今的?#芯片 #电脑 #显卡 #忆阻器 #AI #存算一体安泰小课堂 2023-11-16
-
我们在测试忆阻器时到底在测试什么?#忆阻器 #类脑计算 #存算一体 #芯片 #GPU安泰小课堂 2024-05-15
-
清华大学的存算一体化架构和并行加速方法专利2020-03-14 5385
-
中国制造的全球首款多阵列忆阻器存算一体系统问市2020-04-27 1897
-
这家基于忆阻器的存算一体AI芯片供应商 完成过亿元融资2021-12-09 9749
-
存算一体大算力AI芯片将逐渐走向落地应用2022-05-31 6806
-
存算一体技术路线如何选2022-06-21 11423
-
基于忆阻器存算一体芯片研究进展、总结与展望2022-12-23 3615
-
存算一体芯片新突破!清华大学研制出首颗存算一体芯片2023-10-11 2349
-
清华团队研制成功,全球首颗支持片上学习忆阻器存算一体芯片2023-10-13 1887
-
忆阻器存算一体芯片新突破!有望促进人工智能、自动驾驶等领域发展2023-10-20 7747
-
全球首颗清华忆阻器存算一体芯片究竟是个啥?2023-10-22 1838
-
忆阻器(RRAM)存算一体路线再次被肯定2023-10-26 3552
-
SRAM存算一体芯片的研究现状和发展趋势2024-01-02 5484
全部0条评论

快来发表一下你的评论吧 !
